抓取专题

PHP抓取网站图片脚本
方法一: <?phpheader("Content-type:image/jpeg"); class download_image{function read_url($str) { $file=fopen($str,"r");$result = ''; while(!feof($file)) { $result.=fgets($file,9999); } fclose($file); re
用Java抓取CSDN主页上的图片
一,步骤一:获取网页源码 1,定义要爬取的页面的URL对象 //定义即将访问的链接String url="http://www.csdn.net";//获取CSDN的URL对象URL realURL = new URL(url); 2,获得这个链接的一个连接对象 URLConnection connection = realURL.openConnection();
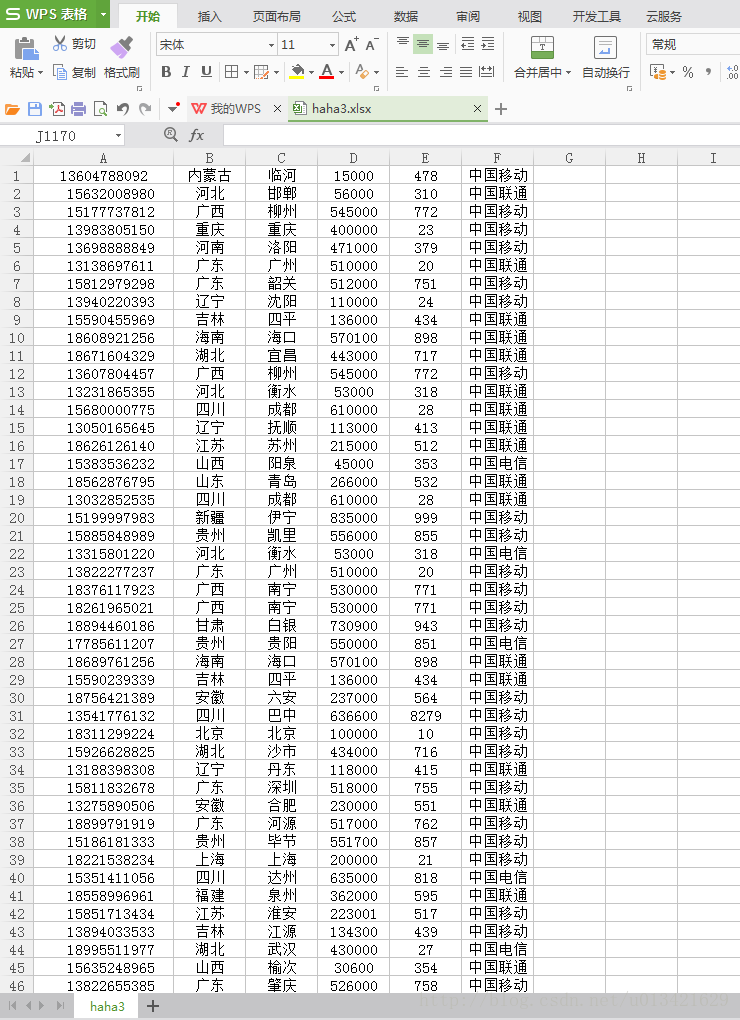
【go语言爬虫】go语言高性能抓取手机号码归属地、所属运营商
一、需求分析 根据手机号码获取手机号码的归属地和所属运营商类型 类似:四川 18683339513 乐山 614000 0833 中国联通 二、运行效果 三、实现源代码 package main//网址:https://github.com/M2shad0w/phone-go//安装包:go get github.com/M2shad0w/phone-goimport ("fmt
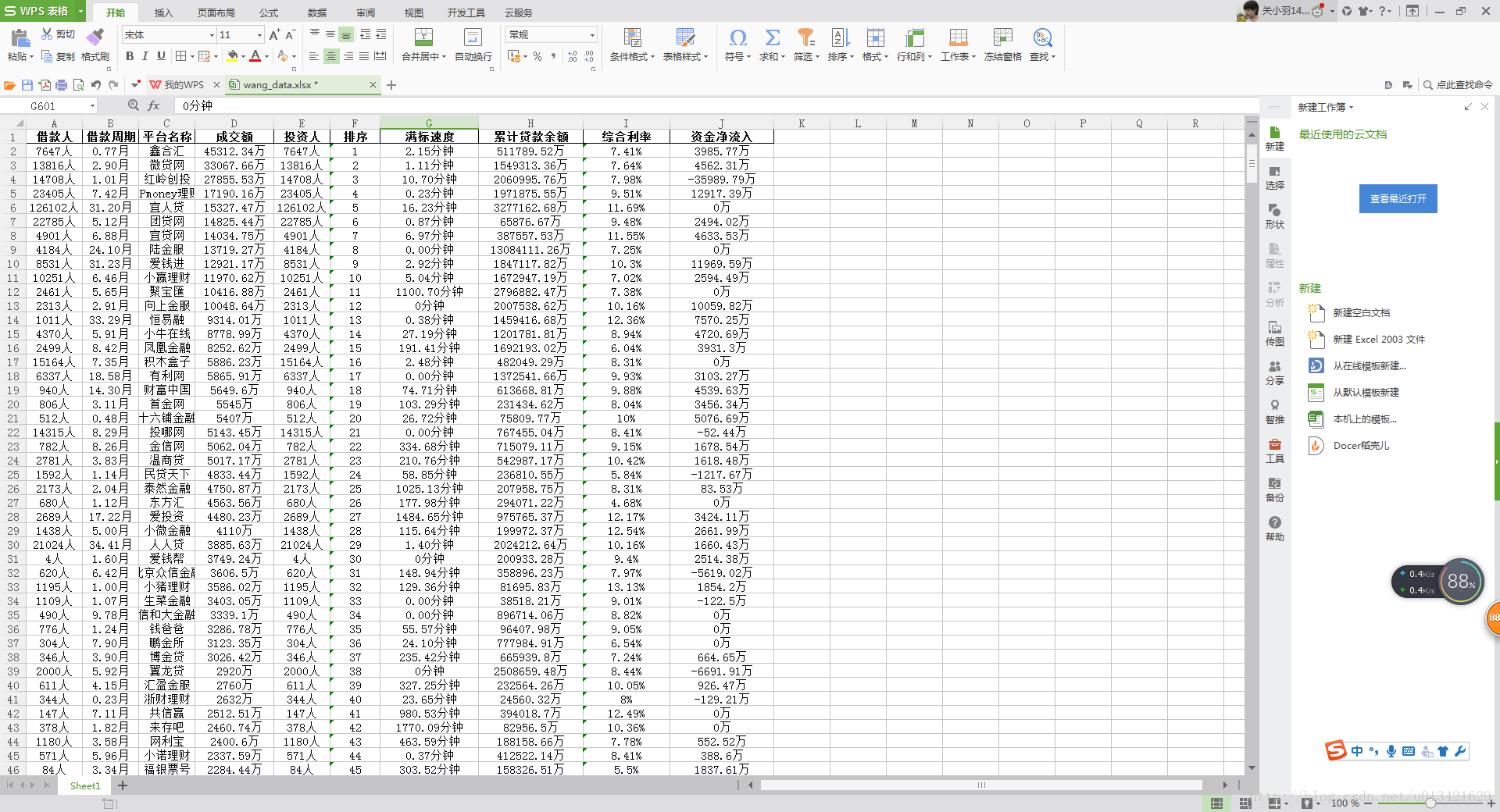
【python爬虫】网贷天眼平台表格数据抓取
一、需求分析 抓取url: http://www.p2peye.com/shuju/ptsj/ 抓取字段: 昨日数据 排序 平台名称 成交额 综合利率 投资人 借款周期 借款人 满标速度 累计贷款余额 资金净流入 二、python爬虫源代码 # -*- coding:utf-8*-import sysreload(sys)sys.setdefaultencoding('utf-

【R语言爬虫】网贷天眼数据平台表格数据抓取2
一、需求分析 抓取url: http://www.p2peye.com/shuju/ptsj/ 昨日数据: 字段:排序 平台名称 成交额 综合利率 投资人 借款周期 借款人 满标速度 累计贷款余额 资金净流入 二、rvest爬虫实现源代码 rm(list=ls())gc()options(scipen = 200)library('rvest')timestart<-Sys

【python 百度指数抓取】python 模拟登陆百度指数,图像识别百度指数
一、算法思想 目的奔着去抓取百度指数的搜索指数,搜索指数的爬虫不像是其他爬虫,难度系数很高,分析之后发现是图片,坑爹的狠,想了下,由于之前做过身份证号码识别,验证码识别之类,豁然开朗,不就是图像识别麽,图像识别我不怕你,于是就有了思路,果然有异曲同工之妙,最后成功被我攻破了,大致思路如下: 1、首先得模拟登陆百度账号(用selenium+PhantomJS模拟登陆百度,获取cookie) 2

python scrapy爬虫框架 抓取BOSS直聘平台 数据可视化统计分析
使用python scrapy实现BOSS直聘数据抓取分析 前言 随着金秋九月的悄然而至,我们迎来了业界俗称的“金九银十”跳槽黄金季,周围的朋友圈中弥漫着探索新机遇的热烈氛围。然而,作为深耕技术领域的程序员群体,我们往往沉浸在代码的浩瀚宇宙中,享受着解决技术难题的乐趣,却也不经意间与职场外部的风云变幻保持了一定的距离,对行业动态或许仅有一鳞半爪的了解,甚至偶有盲区。 但正是这份对技术


python爬虫: 抓取任意歌手的歌词,简直不要太骚
估计大家对歌词的抓取一般是通过抓取网页内容的方式来进行,今天,LZ就教大家一个简单的方法。对大家进行歌词分析来说,又多了一条捷径。 本篇文章是通过请求qq音乐的某一个文件来进行获取的,这个骚操作恐怕还没什么人发现吧,娃哈哈~ 看完过后你就会觉得,这简直不要太骚~ 二话不说, 先上代码: #!/usr/bin/python# -*- coding:utf-8 -*-import reque
网络数据抓取技术栈详解:从传统到现代的全面指南
在大数据和信息化时代,网络数据抓取已经成为获取数据的一个关键手段。Python 作为一门灵活且功能强大的语言,拥有丰富的库和框架来支持各种网络抓取需求。本文将为你详细介绍几种主流的 Python 抓取工具,从传统的静态网页抓取到现代的动态内容处理,希望能帮助你选择适合自己项目的最佳方案。 1. Requests Requests 是 Python 最流行的 HTTP 库之一,用于发送 HTTP

Fiddler 抓取Iphone / Android数据包
Fiddler 抓取Iphone / Android数据包 想要Fiddler抓取移动端设备的数据包,其实很简单,先来说说移动设备怎么去访问网络,看了下面这张图,就明白了。 可以看得出,移动端的数据包,都是要走wifi出去,所以我们可以把自己的电脑开启热点,将手机连上电脑,Fiddler开启代理后,让这些数据通过Fiddler,Fiddler就可以抓到这些包,然后发给路由器(如图)

Android平台抓取native crash log
转自:http://www.cnblogs.com/shakin/p/4268399.html Android开发中,在Java层可以方便的捕获crashlog,但对于 Native 层的 crashlog 通常无法直接获取,只能通过系统的logcat来分析crash日志。 做过 Linux 和 Win32 开发的都知道,在pc上程序crash时可以生成 core dump 文件通过相
抓取海外电商平台数据时,是否最好使用当地的IP?
在进行海外电商平台数据抓取时,使用合适的网络环境和IP地址是至关重要的。这不仅关乎数据的准确性和完整性,还直接影响到数据抓取的成功率和稳定性。本文将探讨在抓取海外电商平台数据时,是否最好使用当地的IP地址,并分析其背后的原因和优势。 一、为何选择当地IP? 降低被封禁风险: 海外电商平台通常对访问来源进行监控,以确保服务的稳定性和安全性。如果使用非本地IP地址频繁访问,很容易触发平台的安全机

基于多种机器学习的房价预测研究【数据抓取、预处理、可视化、预测】
文章目录 ==有需要本项目的代码或文档以及全部资源,或者部署调试可以私信博主==项目介绍 摘要Abstract1. 引言1.1 研究背景1.2 国内外研究现状1.3 研究目的1.4 研究意义 2. 关键技术理论介绍2.1 爬虫介绍2.2 数据分析2.3 随机森林2.4 Optuna 3. 数据采集及预处理3.1 数据采集3.2 数据预处理 4. 数据分析及可视化4.1 房价成交价格分布4.
opencv4从avi视频中提取图片/opencv4从摄像头抓取图像_C++版本
目录 1.从视频提取图像 2.从摄像头提取图像 3.之前的opencv2老代码 1.从视频提取图像 opencv4使用如下代码读取视频数据: cv::VideoCapture cap;cap.open(video_name);cv::Mat frame;cap >> frame;//读取方式1cap.read(frame); //读取方式2int video_fps = ca

java学习-GET方式抓取网页(UrlConnection和HttpClient) 参考
URL:http://www.cnblogs.com/gne-hwz/p/6952312.html 抓取网页其实就是模拟客户端(PC端,手机端。。。)发送请求,获得响应数据documentation,解析对应数据的过程。---自己理解,错误请告知 一般常用请求方式有GET,POST,HEAD三种 GET请求的数据是作为url的一部分,对于GET请求来说,附带数据长度有限制,数

使用 curl_cffi 解决 Web 抓取中的 TLS/JA3 指纹识别方法
在网站抓取过程中遇到反爬虫措施而苦苦挣扎?curl_cffi 是一个高级 Python 库,它包装了 cURL 工具,可以帮助您有效地绕过这些障碍。通过模拟浏览器行为并利用 cURL 的功能,curl_cffi 增强了您的抓取器避免检测并顺利执行的能力。在本指南中,我们将探讨 curl_cffi 的工作原理、如何将其用于各种任务以及其局限性。我们还将讨论克服这些局限性的潜在解决方案。 什么是

爬虫技术抓取网站数据被限制怎么处理
爬虫技术用于抓取网站数据时,可能会遇到一些限制,常见的包括反爬机制、速率限制、IP封禁等。以下是应对这些情况的一些策略: 尊重robots.txt:每个网站都有robots.txt文件,遵循其中的规定可以避免触犯网站的抓取规则。 设置合理频率:控制爬虫请求的速度,通过添加延迟或使用代理服务器,减少对目标网站的压力。 使用代理:获取并使用代理IP地址可以更换访问来源,降低被识别的可能性。
【Android】如何使用adb抓取Android系统的WiFi日志
🐚作者简介:花神庙码农(专注于Linux、WLAN、TCP/IP、Python等技术方向)🐳博客主页:花神庙码农 ,地址:https://blog.csdn.net/qxhgd🌐系列专栏:WLAN技术📰如觉得博主文章写的不错或对你有所帮助的话,还望大家三连支持一下呀!!! 👉关注✨、点赞👍、收藏📂、评论。如需转载请参考转载须知!! Android系统使用adb抓取WiF

【Python进阶】总结Python爬虫的10大高效数据抓取技巧
点击免费领取《CSDN大礼包》:Python入门到进阶资料 & 实战源码 & 兼职接单方法 安全链接免费领取 1. 使用高效的HTTP库 requests库:Python中最流行的HTTP库之一,支持多种HTTP请求方法,易于使用且性能优异。通过pip install requests安装。requests-html:在requests的基础上增加了对JavaScript渲染的支持,适合抓取需

QT 简易网页信息抓取程序模板基础代码
有些网页爬不了,只是一个简单的代码。 项目结构 NetBugBaseCode.pro #-------------------------------------------------## Project created by QtCreator 2024-08-26T15:13:10##---------------------------------------------
构建基于I2C与UART通信的智能嵌入式机械臂抓取系统,结合OpenCV技术进行高效物体识别与动作控制的综合解决方案(代码示例)
在现代工业和智能家居中,智能抓取系统的需求日益增长。本项目旨在设计一个能够识别和抓取不同形状和尺寸物体的机械臂。通过视觉识别、夹爪控制和嵌入式系统集成,智能抓取系统能够大幅提升物体处理的效率和准确性。 项目目标与用途 本项目的主要目标是开发一个智能机械臂,能够在复杂环境中自动识别并抓取各种物体。该系统可广泛应用于生产线自动化、仓储管理、智能家居等领域。 解决的问题与价值 传统的物体抓取方式
如何抓取网站页面内容
很多时候,我们想获取一些网页的内容,可以运用以下几种方法: HTTPCLIENT get方法: HttpClient httpClient = new HttpClient(); GetMethod getMethod = new GetMethod("http://www.baidu.com/"); try { int statusCode

不同搜索引擎蜘蛛的功能、抓取策略与技术实现差异探究
搜索引擎作为互联网信息检索的重要工具,其核心功能依赖于背后的“蜘蛛”程序。这些蜘蛛程序负责访问互联网上的各种内容,并建立索引数据库,以便用户能够快速准确地找到所需信息。然而,不同搜索引擎的蜘蛛在功能、抓取策略和技术实现上存在着显著差异。本文将重点探讨百度的蜘蛛(Baiduspider)、搜狐的蜘蛛以及不知名小网站的蜘蛛之间的差异,并分析这些差异对搜索引擎服务质量和用户体

UR机械臂的ROS驱动安装官方教程详解——机器人抓取系统基础系列(一)
UR机械臂的ROS驱动安装配置官方教程详解——机器人抓取系统基础系列(一) 前言1 准备工作2 电脑安装驱动3 机器人端设置4 电脑和机器人的通讯IP设置5 启动机械臂的ROS驱动6 MoveIt控制机械臂总结 前言 本文在官方Github教程的基础上,详细阐述了UR机械臂的ROS驱动安装的步骤,为广大从事机器人相关工作的人员作参考。 官方安装教程地址为:https:/
石墨文档数据:合法抓取指南
如何使用爬虫技术合法地抓取石墨文档数据 在当今数字化时代,在线协作工具如石墨文档已成为团队工作不可或缺的部分。 然而,在某些情况下,我们可能需要自动提取这些文档中的数据进行分析等。 本文介绍了如何在遵循服务条款的同时,利用爬虫技术从石墨文档中提取数据。 我们将详细讨论这一过程,确保您能够在遵守规则的基础上高效获取所需信息。 引言 介绍石墨文档及其在工作流程中的重要性。强调自动化抓取