本文主要是介绍【Python 爬虫案例】爬取豆瓣读书Top250书籍信息,并保存到表格,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
获取数据请求
网页地址:豆瓣读书 Top 250 (douban.com)
进入网页——打开浏览器开发者模式——刷新网页——过滤数据
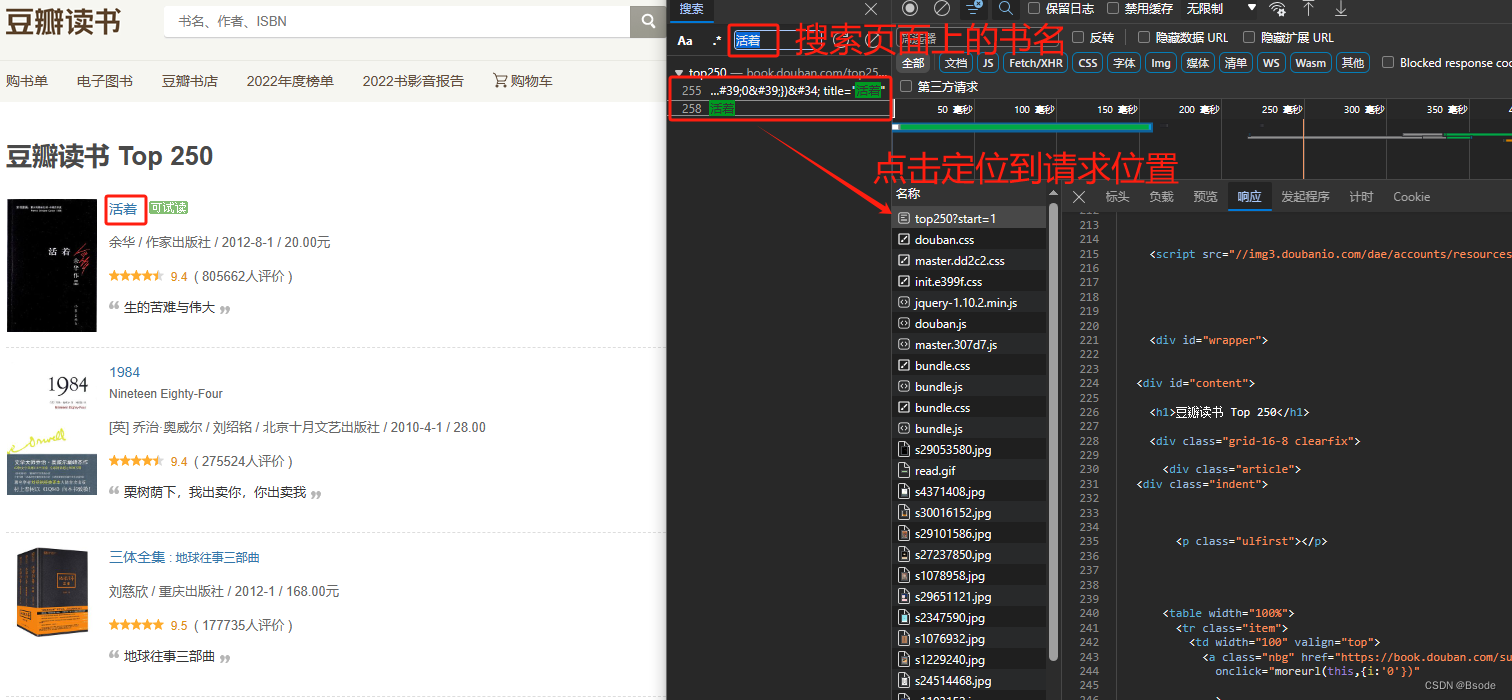
复制curl格式请求
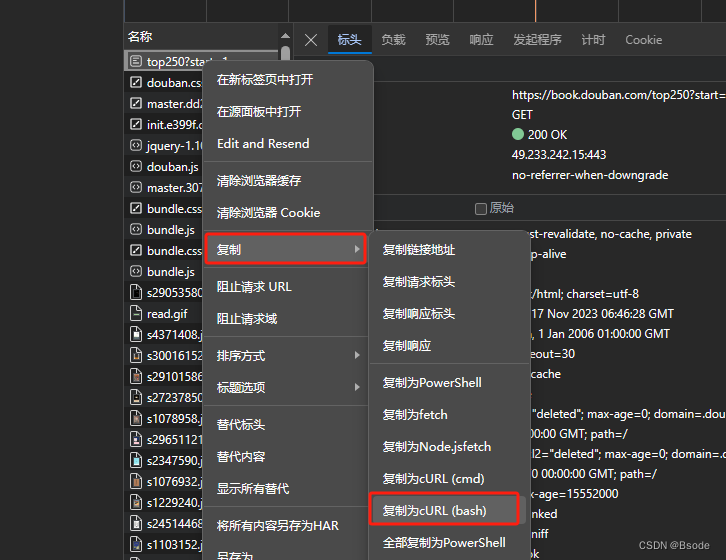
使用在线工具转换请求
链接:curl命令转代码 - 在线工具 (tool.lu)

至此req中的请求内容已获取完成,下面是完整代码。
import requests
import xlsxwriter.exceptions
from lxml import etree
import xlsxwriter as xw# 发送请求,获取网页数据
def req(page):cookies = {'bid': 'I1nispKul7Y','_ga': 'GA1.1.1064628979.1692867437','_ga_RXNMP372GL': 'GS1.1.1695870809.1.1.1695870817.52.0.0','ap_v': '0,6.0','_pk_ref.100001.3ac3': '%5B%22%22%2C%22%22%2C1700111999%2C%22https%3A%2F%2Flink.zhihu.com%2F%3Ftarget%3Dhttps%253A%2F%2Fbook.douban.com%2Ftop250%253Fstart%253D1%22%5D','_pk_id.100001.3ac3': '51de77c6f16bde0f.1700111999.1.1700111999.1700111999.','_pk_ses.100001.3ac3': '*','__utma': '30149280.1064628979.1692867437.1692867437.1700111999.2','__utmc': '30149280','__utmz': '30149280.1700111999.2.2.utmcsr=link.zhihu.com|utmccn=(referral)|utmcmd=referral|utmcct=/','__utmt_douban': '1','__utmb': '30149280.1.10.1700111999','__utma': '81379588.1064628979.1692867437.1700111999.1700111999.1','__utmc': '81379588','__utmz': '81379588.1700111999.1.1.utmcsr=link.zhihu.com|utmccn=(referral)|utmcmd=referral|utmcct=/','__utmt': '1','__utmb': '81379588.1.10.1700111999',}headers = {'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7','Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6','Cache-Control': 'max-age=0','Connection': 'keep-alive',# 'Cookie': 'bid=I1nispKul7Y; _ga=GA1.1.1064628979.1692867437; _ga_RXNMP372GL=GS1.1.1695870809.1.1.1695870817.52.0.0; ap_v=0,6.0; _pk_ref.100001.3ac3=%5B%22%22%2C%22%22%2C1700111999%2C%22https%3A%2F%2Flink.zhihu.com%2F%3Ftarget%3Dhttps%253A%2F%2Fbook.douban.com%2Ftop250%253Fstart%253D1%22%5D; _pk_id.100001.3ac3=51de77c6f16bde0f.1700111999.1.1700111999.1700111999.; _pk_ses.100001.3ac3=*; __utma=30149280.1064628979.1692867437.1692867437.1700111999.2; __utmc=30149280; __utmz=30149280.1700111999.2.2.utmcsr=link.zhihu.com|utmccn=(referral)|utmcmd=referral|utmcct=/; __utmt_douban=1; __utmb=30149280.1.10.1700111999; __utma=81379588.1064628979.1692867437.1700111999.1700111999.1; __utmc=81379588; __utmz=81379588.1700111999.1.1.utmcsr=link.zhihu.com|utmccn=(referral)|utmcmd=referral|utmcct=/; __utmt=1; __utmb=81379588.1.10.1700111999','Referer': 'https://link.zhihu.com/?target=https%3A//book.douban.com/top250%3Fstart%3D1','Sec-Fetch-Dest': 'document','Sec-Fetch-Mode': 'navigate','Sec-Fetch-Site': 'cross-site','Sec-Fetch-User': '?1','Upgrade-Insecure-Requests': '1','User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36 Edg/119.0.0.0','sec-ch-ua': '"Microsoft Edge";v="119", "Chromium";v="119", "Not?A_Brand";v="24"','sec-ch-ua-mobile': '?0','sec-ch-ua-platform': '"Windows"',}if page == 0:params = {'start': '1',}else:params = {'start': page * 25 + 1}response = requests.get('https://book.douban.com/top250', params=params, cookies=cookies, headers=headers)return response# 截取数据,格式化数据
def bk_name(response):# 转换数据,转换为etree格式html = etree.HTML(response.text)# 过滤数据,使用xpath方法,过滤出所有的作者名book = html.xpath("//div[@class='indent']/table//div/a/text()")# 过滤出其他所有信息writer = html.xpath("//div[@class='indent']/table//p[@class='pl']/text()")book_name = []for i in book:i = i.split(" ")try:i = i[16].split("\n")book_name.append(i[0])except IndexError as err:continueall_data = []num = 0for i in writer:data = []i = i.split("/")if len(i) == 5:del i[1]if len(i) == 6:del i[5]del i[1]try:data.append(book_name[num])data.append(i[0])data.append(i[1])data.append(i[2])data.append(i[3])# 过滤缺失数据except IndexError as err:print('无效数据。。过滤')all_data.append(data)num += 1return all_data# 将数据存到表格文件
def save(all_data):workbook = xw.Workbook('豆瓣Top250.xlsx')worksheet1 = workbook.add_worksheet("豆瓣数据")worksheet1.activate()worksheet1.write_row("A1", ['书名', '作者', '出版社', '出版日期', '售价'])num = 1for i in all_data:num += 1row = "A" + str(num)try:worksheet1.write_row(row, [i[0], i[1], i[2], i[3], i[4]])except IndexError as err:continueworkbook.close()def main():num = input("需要爬取多少页数据:")all_data = []for i in range(0, int(num)):page_data = bk_name(req(i))for a in page_data:all_data.append(a)try:save(all_data)except xlsxwriter.exceptions.FileCreateError as err:print("文件正在编辑,请关闭文件后重试")if __name__ == '__main__':main()
这篇关于【Python 爬虫案例】爬取豆瓣读书Top250书籍信息,并保存到表格的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





