本文主要是介绍python爬虫获取豆瓣前top250的标题(简单),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
今天是简略的一篇,简单小实验
import requests
from bs4 import BeautifulSoup# 模拟浏览器的构成(请求头)
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Safari/537.36 Edg/123.0.0.0"
}for start_num in range(0,250,25):# 获取豆瓣top榜上前250部电影的响应内容response = requests.get(f"https://movie.douban.com/top250?start={start_num}", headers=headers)html = response.text# 传入方法,指定解析器为html.parser"soup = BeautifulSoup(html, "html.parser")all_titles=soup.findAll("span",attrs={"class":"title"})for title in all_titles:title_string=title.stringif "/" not in title_string:print(title_string)
读取:
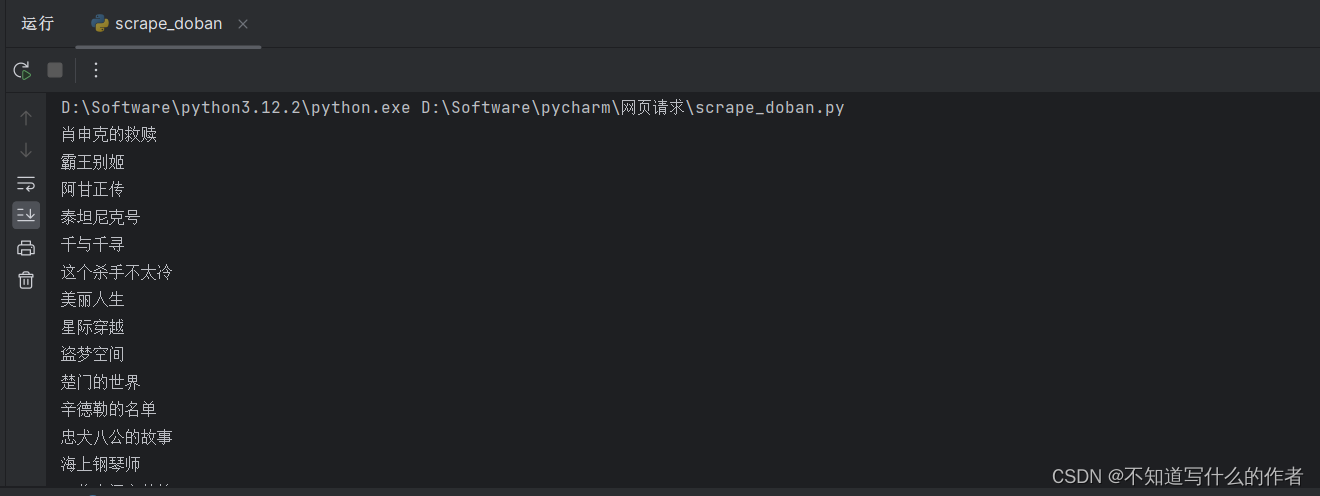
这篇关于python爬虫获取豆瓣前top250的标题(简单)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




