本文主要是介绍Python爬虫学习--3--爬取豆瓣Top250电影,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
爬取链接
这个网页中每页有25条信息,共有10页 首先我们要做的获取每一页的连接,由第一页
https://movie.douban.com/top250 //第一页
https://movie.douban.com/top250?start=0&filter= //第一页
https://movie.douban.com/top250?start=25&filter= //第二页
··· ···
https://movie.douban.com/top250?start=225&filter= //第十页
每一页25条,可以获得上述链接 ,仅仅是start中的字段不相同
我们使用BeautifulSoup来获取网页代码中的信息
查看源代码
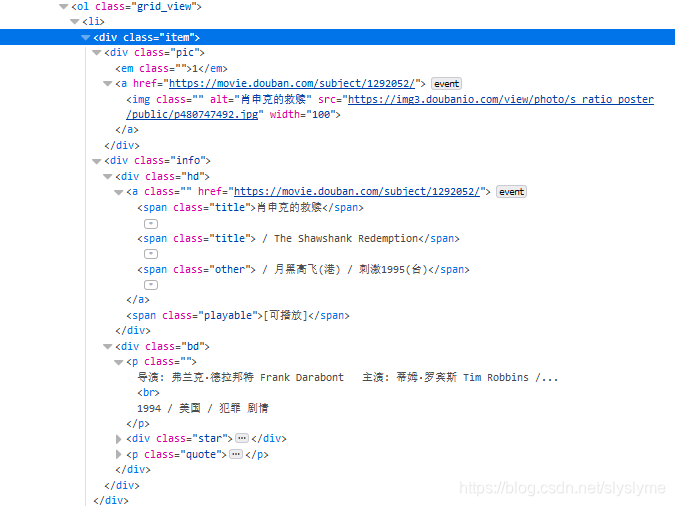
可以看出所有电影信息都在一个有序列表 ol 中, class="gird_view"
获取信息保存至txt文件
# -*- coding:utf-8 -*-
import requests
from bs4 import BeautifulSoup
import re
import time
import sysdef getHTMLText(url, k):try:if(k == 0):kw = {}else:kw = {'start':k,'filter':''}r = requests.get(url, params=kw, headers={'User-Agent':'Mozilla/4.0'})r.raise_for_status() # 仅针对错误4** 和 5**,将引发异常,停止程序r.encoding = r.apparent_encoding # 从内容中分析出的响应内容编码方式return r.textexcept:print("获取失败!")def getData(html):soup = BeautifulSoup(html, "html.parser")moviesList = soup.find('ol', attrs={'class':'grid_view'}) # 找到第一个属性值为gird_viewh=0for movieLi in moviesList.find_all('li'): # 找到所有li的标签# 得到电影的名字movieHd=movieLi.find('div',attrs={'class':'hd'})movieName=movieHd.find('span',attrs={'class':'title'}).getText()f.write(('电影名:'+movieName+' ').encode('utf-8'))print(movieName)# 得到电影链接movieUrl=movieHd.find('a', attrs={'class':''}).get('href')f.write(('链接:' + str(movieUrl)+ ' ').encode('utf-8'))# 得到影评movieBd = movieLi.find('div', attrs={'class': 'bd'})movieP = movieBd.find('p', attrs={'class': 'quote'})if(movieP):movieQuote = movieP.find('span', attrs={'class': 'inq'})f.write(('电影短评:' + movieQuote.getText()+ ' ').encode('utf-8'))else:f.write(('短评:没有短评'+ ' ').encode('utf-8'))# 得到评价人数movieEval=movieLi.find('div',attrs={'class':'star'})movieEvalNum=re.findall(r'\d+',str(movieEval))[-1]f.write(('评论数:' + movieEvalNum + ' ').encode('utf-8'))# 得到电影评分movieScore = movieBd.find('span', attrs={'class': 'rating_num'}).getText()f.write(('电影评分:' + movieScore + ' \n').encode('utf-8'))print(movieScore)# 获取电影导演主演movieSF=movieBd.find('p', attrs={'class':''}).getText()f.write(('导演主演:' + movieSF+ ' '+'\n\n').encode('utf-8'))print("")url='https://movie.douban.com/top250'
k=0
i=1
with open("top250.txt","wb") as f:f.write("豆瓣电影Top250\n".encode('utf-8'))while k <= 225:html=getHTMLText(url,k)time.sleep(1)getData(html)i += 1k += 25print("完成!")
这篇关于Python爬虫学习--3--爬取豆瓣Top250电影的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




