beautifulsoup专题

Python3 BeautifulSoup爬虫 POJ自动提交
POJ 提交代码采用Base64加密方式 import http.cookiejarimport loggingimport urllib.parseimport urllib.requestimport base64from bs4 import BeautifulSoupfrom submitcode import SubmitCodeclass SubmitPoj():de

第3章-04-Python库BeautifulSoup安装与讲解
🏆作者简介,黑夜开发者,CSDN领军人物,全栈领域优质创作者✌,CSDN博客专家,阿里云社区专家博主,2023年CSDN全站百大博主。 🏆数年电商行业从业经验,历任核心研发工程师,项目技术负责人。 🏆本文已收录于专栏:Web爬虫入门与实战精讲,后续完整更新内容如下。 文章目录 🚀一、BeautifulSoup简介🚀二、BeautifulSoup的安装🚀三、Beau

BeautifulSoup
BeautifulSoup是一个用于解析HTML和XML文档的python库。 查找一般使用find函数,find函数可以接受多种参数,包括标签名、属性名和值、子标签等。它返回的是第一个匹配的元素,如果没有找到匹配的元素,它将返回None。 例子如下 from bs4 import BeautifulSoup # 查找第一个<div>标签 first_div = soup.find('di

BeautifulSoup-爬虫实战
BS4介绍BS4的官方文档教程安装BeautifulSoup包 Windows安装BeautifulSoup环境Ubuntu下安装BS4 Eclipse下配置Python环境 Windows下 Step1添加pydev插件Step2配置工程python编译器Step3Eclipse下创建Python工程 Ubuntu下 Step1添加pydev插件 安装BeautifulSo
如何解决 BeautifulSoup 安装问题:从 BeautifulSoup 3 到 BeautifulSoup 4
在使用 Python 的过程中,解析 HTML 和 XML 数据是一项常见任务。BeautifulSoup 是一个非常流行的解析库。然而,最近在安装 BeautifulSoup 时,遇到了一些问题。本文将介绍如何解决这些问题,并成功安装 BeautifulSoup 4。 问题描述 在尝试使用 pip install BeautifulSoup 命令安装 BeautifulSoup 时,遇

11.爬虫---BeautifulSoup安装并解析爬取数据
11.BeautifulSoup安装并解析爬取数据 1.简介2.安装3.基本使用3.1 获取第一个div标签的html代码3.2 获取第一个li标签3.3 获取第一个li标签内容3.4 返回第一个li的字典,里面是多个属性和值3.5 查看第一个li返回的数据类型3.6 根据属性,获取标签的属性值,返回值为列表 不存在就报错3.7 获取具体属性 获取最近的第一个属性 不存在就返回None3.8
python爬虫,抓取新浪科技的文章(beautifulsoup+mysql)
这几天的辛苦没有白费,总算完成了对新浪科技的文章抓取,除非没有新的内容了,否则会一直爬取新浪科技的文章。 想了解更多可以关注我的github:https://github.com/libp/WebSpider 如果想要数据库表结构可以留下邮箱~ # -*- coding: utf-8 -*-__author__ = 'Peng'from bs4 import BeautifulSoup
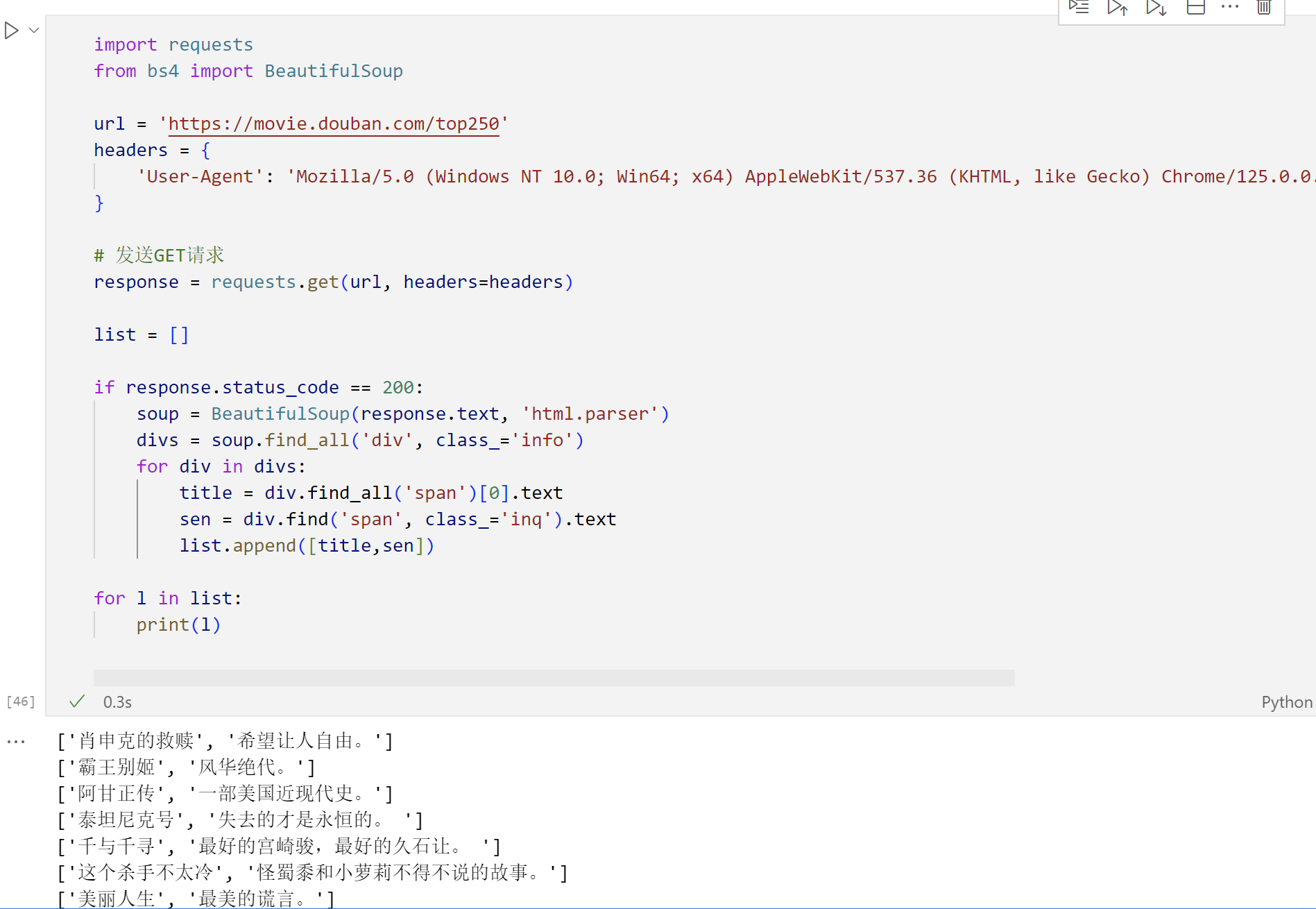
Python爬虫之简单学习BeautifulSoup库,学习获取的对象常用方法,实战豆瓣Top250
BeautifulSoup是一个非常流行的Python库,广泛应用于网络爬虫开发中,用于解析HTML和XML文档,以便于从中提取所需数据。它是进行网页内容抓取和数据挖掘的强大工具。 功能特性 易于使用: 提供简洁的API,使得即使是对网页结构不熟悉的开发者也能快速上手。文档解析: 支持多种解析器,包括Python标准库中的HTML解析器以及第三方的lxml解析器,后者速度更快且功能更强大。自动
Ubuntu下python的BeautifulSoup和rsa安装方法---信息检索project2部分:微博爬取所需python包
最近因为《信息检索》第二个project,需要爬取微博数据,然后再处理。师兄给了代码,让慢慢爬,但是在ubuntu下,少了很多python软件包。需要安装。 1.首先运行时,说少了python,BeautifulSoup包,用来解析html文件神奇,这么重要的包怎么能缺少呢,百度ubuntu python BeautifulSoup后,看博客后找到方法: 先安装easy_install工具:
python爬虫实战2-获取当当网近30日好评榜前500本书籍-使用BeautifulSoup
所有的一切都跟上一篇文章是一样的,不同的是不用写长长的正则表达式啦,上一期传送门https://blog.csdn.net/u010376229/article/details/114042780 这次我们需要用到BeautifulSoup,只需简单的学习一下就剋不用写正则表达式啦,而且更加清楚 def get_books_info_of_current_page(page):html = g
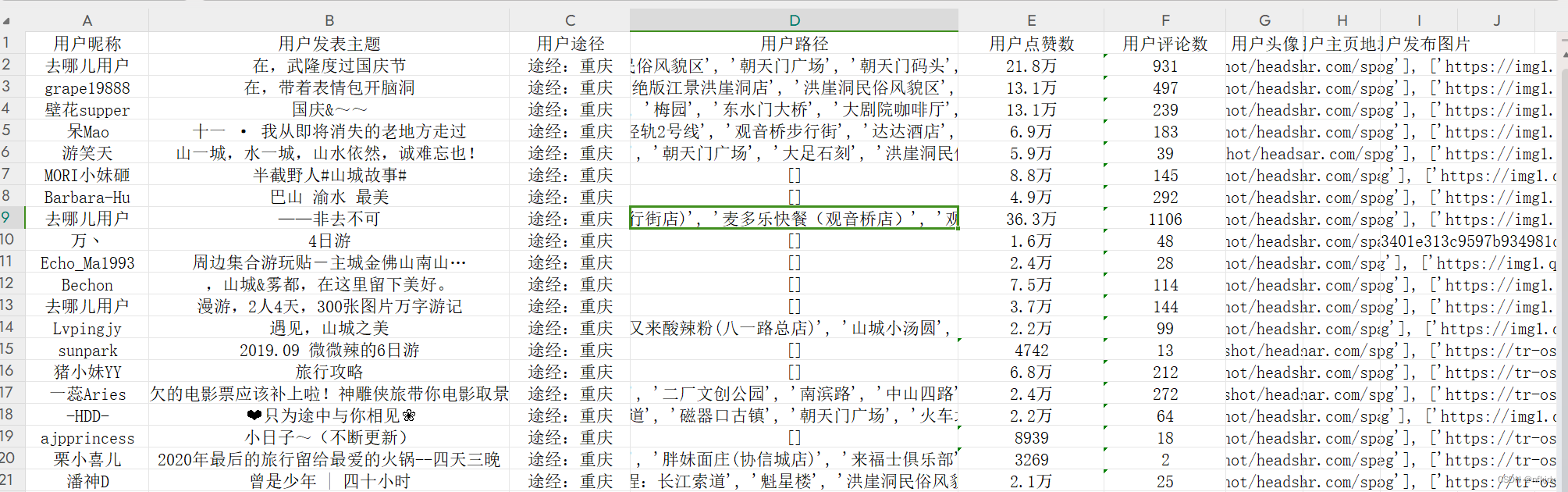
Python爬虫实战:爬取【某旅游交通出行类网站中国内热门景点】的评论数据,使用Re、BeautifulSoup与Xpath三种方式解析数据,代码完整
一、分析爬取网页: 1、网址 https://travel.qunar.com/ 2、 打开网站,找到要爬取的网页 https://travel.qunar.com/p-cs299979-chongqing 进来之后,找到评论界面,如下所示:在这里我选择驴友点评数据爬取 点击【驴友点评】,进入最终爬取的网址:https://travel.qunar.com/p-cs299

如何从yaml取值,如何处理编码,使用BeautifulSoup解析网页获取数据
import requestsfrom bs4 import BeautifulSoupimport yamlimport chardet#从doctor.yaml里面引入网址with open('doctor.yaml', 'r', encoding='utf-8') as file:urls_data = yaml.safe_load(file)#把查出的数据写入doctor_in
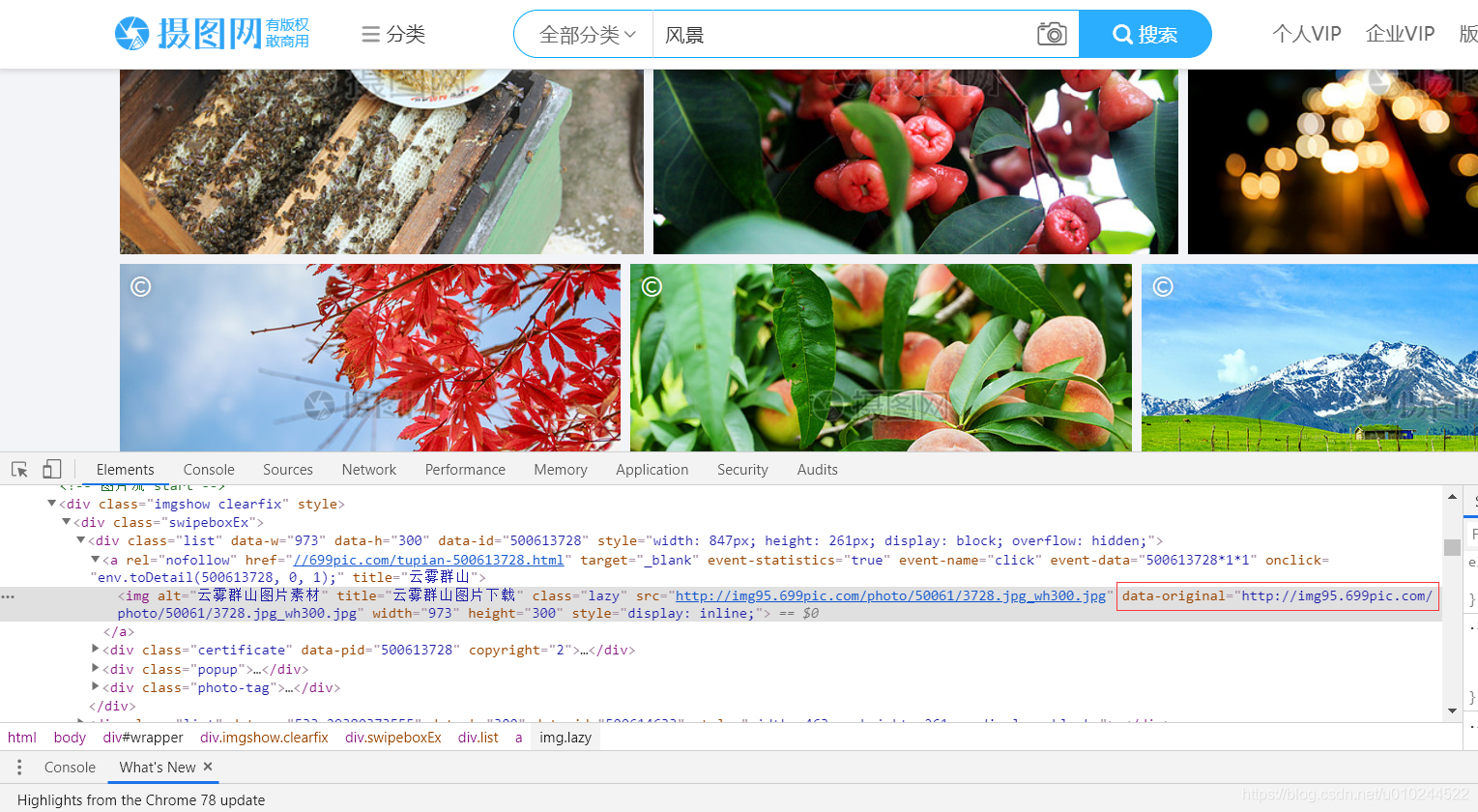
request+BeautifulSoup爬取网站内容
目标网站:http://699pic.com/sousuo-218808-13-1-0-0-0.html 如图,目标图片对于tag名为''img'',class=''lazy'' 查找时使用 find_all('img',class_='lazy') # conding :utf-8from bs4 import BeautifulSoupimport requestsurl
网络爬虫_BeautifulSoup
import requestsfrom bs4 import BeautifulSoupr = requests.get("https://www.python123.io/ws/demo.html")demo = r.text # demo获取url所有源代码# BeautifulSoup 解析网页源代码# 格式:BeautifulSoup('url', 'html.parser')#

Python爬虫-BeautifulSoup解析
1.简介 BeautifulSoup 是一个用于解析 HTML 和 XML 文档的 Python 库。它提供了一种灵活且方便的方式来导航、搜索和修改树结构或标记文档。这个库非常适合网页抓取和数据提取任务,因为它允许你以非常直观的方式查询和操作文档内容。 2.安装 Beautiful Soup 终端输入:pip install beautifulsoup4 3.四个关键对象-覆盖了
2020-11-06 Python----------爬取豆瓣预备知识(urllib库request,beautifulsoup)
Python爬取豆瓣 Python编码规范 一般第一句加 # -*- coding: utf-8 -*- 或 # coding=utf-8 加入main函数用于测试函数 # -*- coding: utf-8 -*-def main():print("hello")if __name__ == "_main_": #主程序入口main()#两个下划线name再两个下划线
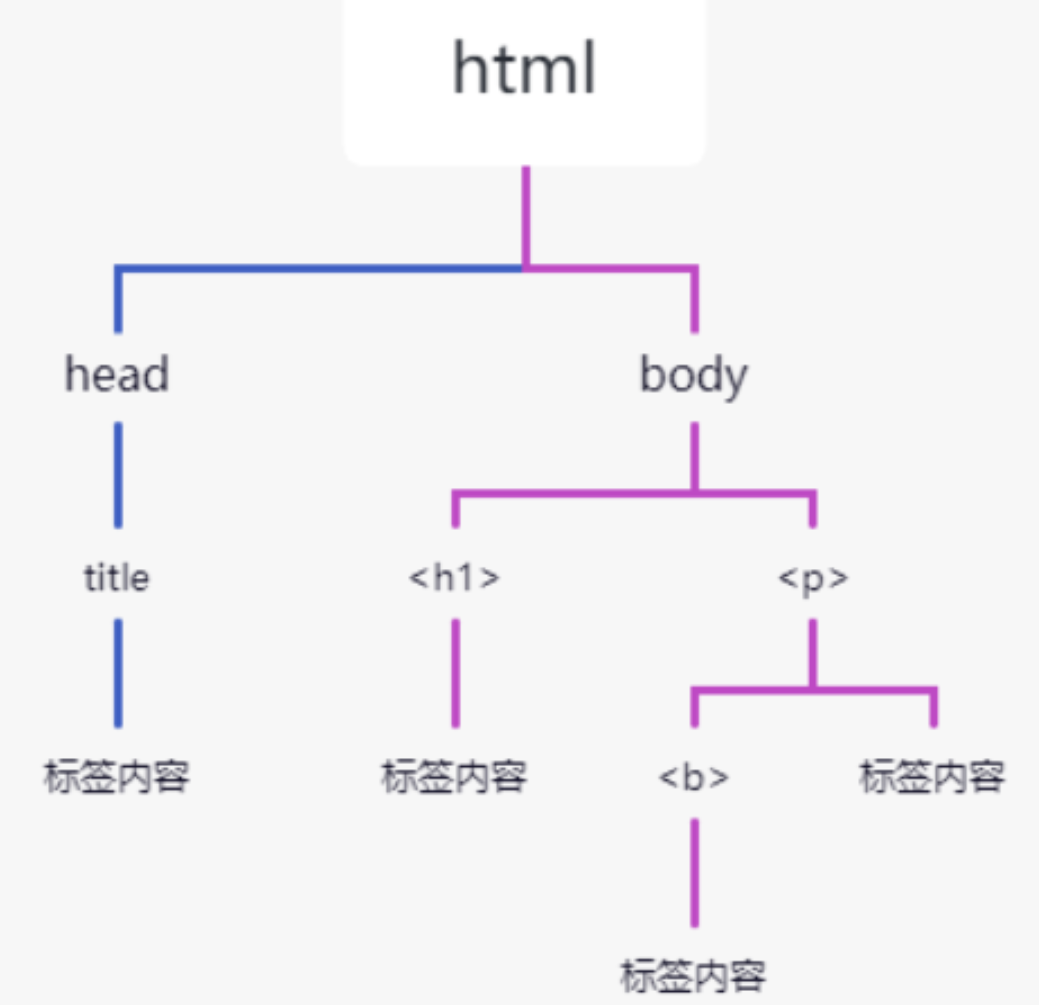
BeautifulSoup模块
【一】Beautifulsoup4初始 【前言】bs4模块 安装 pip install beautifulsoup4 【1】什么是beautifulsoup: 是一个可以从HTML或XML文件中提取数据的Python库。它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式。(官方) beautifulsoup是一个解析器,可以特定的解析出内容,省去了我们编

Datawhale-爬虫-Task3(beautifulsoup)
Beautiful Soup Beautiful Soup是一个非常流行的Python模块。该模块可以解析网页,并提供定位内容的便捷接口。使用Beautiful Soup的第一步是将已下载的HTML内容解析为soup文档。由于大多数网页都不具备良好的HTML格式,因此Beautiful Soup需要对其实际格式进行确定。 例如,在下面这个简单的网页列表中,存在属性值两侧引号缺失和标签未闭合的问
Python 爬虫基础:利用 BeautifulSoup 解析网页内容
1. 理解 Python 爬虫基础 在当今信息爆炸的时代,网络上充斥着海量的数据,而网络爬虫作为一种数据采集工具,扮演着至关重要的角色。网络爬虫是一种自动化的程序,可以模拟浏览器访问网页,获取所需信息并进行提取和整合。Python作为一种简洁、易学的编程语言,在网络爬虫领域备受青睐。 Python爬虫的优势主要体现在其丰富的爬虫库和强大的支持功能上。比如,Requests库可以帮助我们轻松实现
关于BeautifulSoup的总结
最近一直在用BeautifulSoup,但是语法很容易忘记。在这里做个学习总结吧。 参考: Beautiful Soup 4.2.0 文档 功能 BeautifulSoup是用来从HTML或XML中提取数据的Python库。 导入 使用方法:from bs4 import BeautifulSoupsoup = BeautifulSoup(html) 编码 soup使
BeautifulSoup模块
BeautifulSoup模块可以参考官方文档,这里是翻译版的地址:https://www.crummy.com/software/BeautifulSoup/bs4/doc/index.zh.html

python网络爬虫2——BeautifulSoup库信息提取
一、安装 cmd :pip install beautifulsoup4 from bs4 import BeautifulSoup #BeautifulSoup是一个类soup = BeautifulSoup('<p>data</p>', 'html.parser')#'<p>data</p>'是需要解析的html格式的信息,'html.parser'是解析器soup2 = Beaut
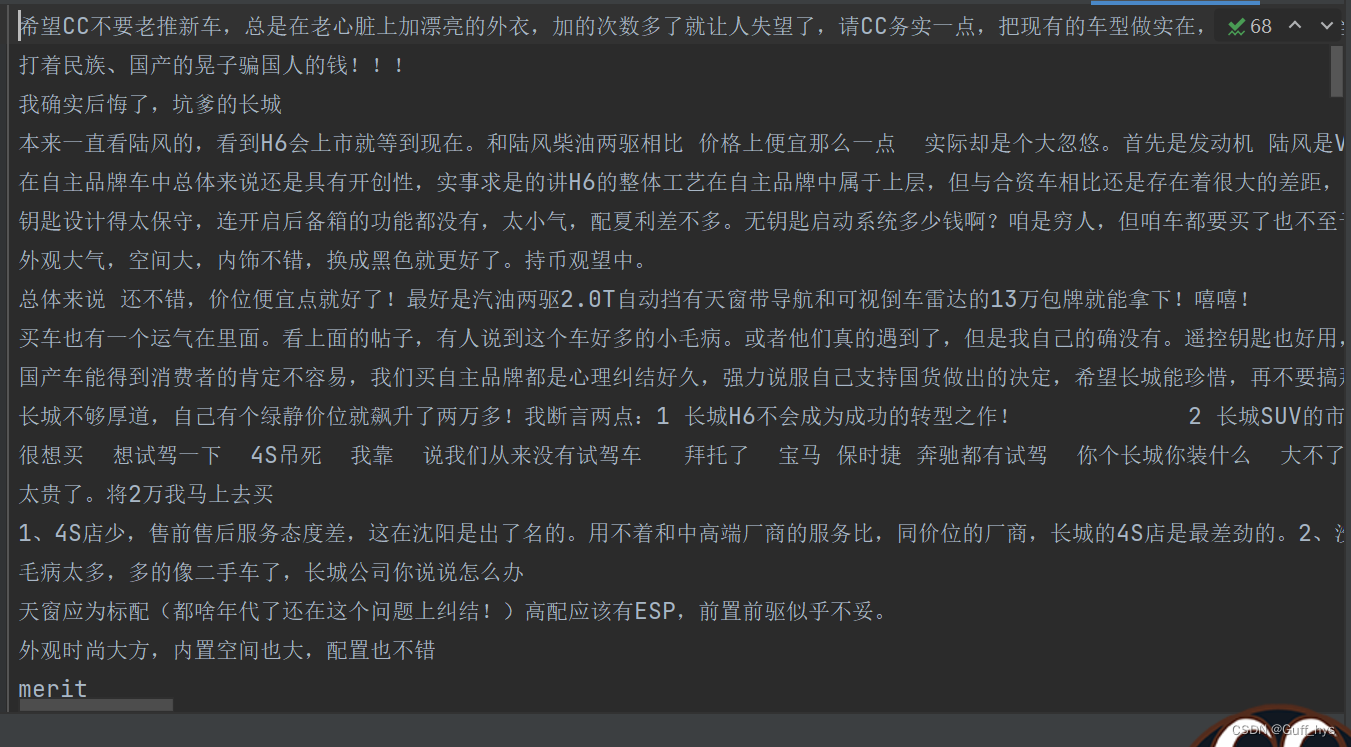
python_BeautifulSoup爬取汽车评论数据
爬取的网站: 完整代码在文章末尾 https://koubei.16888.com/57233/0-0-0-2 使用方法: from bs4 import BeautifulSoup 拿到html后使用find_all()拿到文本数据,下图可见,数据标签为: content_text = soup.find_all('span', class_='show_dp f_r')
beautifulsoup爬虫快速入门一基础知识
主要涉及到的知识点 这里针对的是数据以HTML返回的形式 beautifulsoup、lxml的使用 首先这里需要请求到一个网页地址,之后用beautifulsoup解析网页 requestsAPI = request.get(url)bs = BeautifulSoup(requestsAPI.content,'lxml') 获取的是多个元素find_all many = bs.fin
Python爬虫从入门到精通:(6)数据解析2_使用bs4(BeautifulSoup)_Python涛哥
使用bs4(BeautifulSoup) 数据解析的作用? 用来实现聚焦爬虫 网页中显示的数据都是存储在那里的? 都是存储在html的标签中或者是标签的属性中 数据解析的通用原理是什么? 指定标签的定位取出标签中存储的数据或者标签属性中的数据 bs4解析原理 实例化一个BeautifulSoup对象,且待解析的页面源码数据加载到该对象中调用BeautifulSoup对象中相关方法或者属性

第14.18节 爬虫实战4: request+BeautifulSoup+os实现利用公众服务Wi-Fi作为公网IP动态地址池
写在前面:本文相关方法为作者独创,仅供参考学习爬虫技术使用,请勿用作它途,禁止转载! 一、 引言 在爬虫爬取网页时,有时候希望不同的时候能以不同公网地址去爬取相关的内容,去网上购买地址资源池是大部分人员的选择。老猿所在的环境有电信运输商部署的对外开放的WiFi,由于涉及对外开放支持不同用户接入,其分配的地址经过NAT地址转换,但其公网地址一定是一个地址池,对于需要公网地址池资源的人员来说,这就是