本文主要是介绍request+BeautifulSoup爬取网站内容,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目标网站:http://699pic.com/sousuo-218808-13-1-0-0-0.html
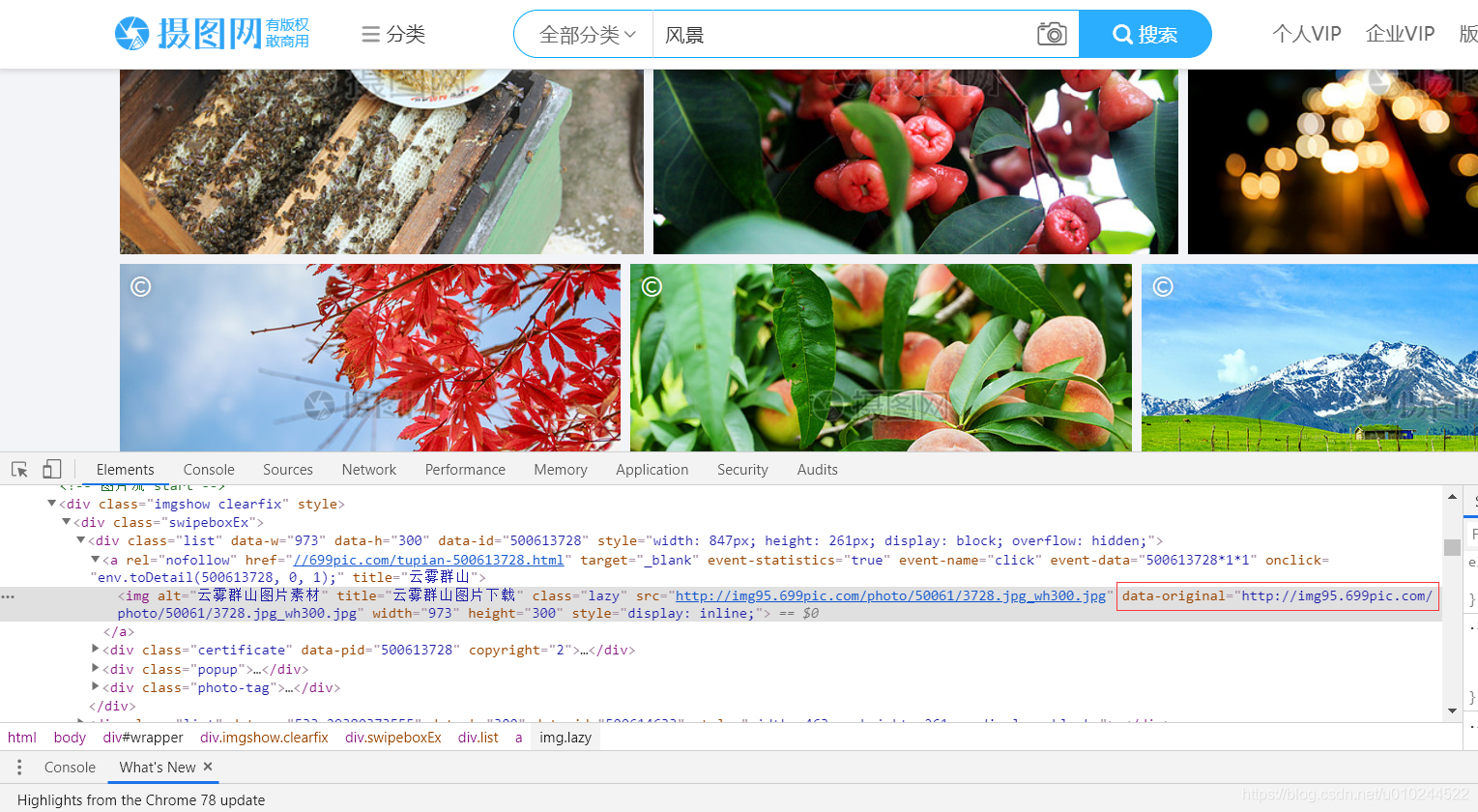
如图,目标图片对于tag名为''img'',class=''lazy''
查找时使用 find_all('img',class_='lazy')
# conding :utf-8from bs4 import BeautifulSoup
import requestsurl ='http://699pic.com/sousuo-218808-13-1.html'
r1 = requests.get(url,verify=True)soup =BeautifulSoup(r1.content.decode('utf-8'),'html.parser') #解析soup对像tags =soup.find_all('img',class_='lazy') #查找所以符合条件的标签
for i in tags:iurl=i['data-original'] #获取图片对应的原地址titel=i['title'] #获取图片对应的名称tup=requests.get(iurl).content #获取图片对应的二进制流fp=open(titel+'.jpg','wb') #打开文件fp.write(tup) #将图片二进制流写入文件fp.close() #关闭文件----------------------------------------------------------------------------------------
t=tags[0] print(t) print(t.name) # 获取tag名称 print(t.string) # str print(t['class']) # class返回的是list print(t.attrs) # 返回的字典,获取所有的属性
官方文档:http://beautifulsoup.readthedocs.io/zh_CN/latest/
所有对象可以归纳为4种:
Tag : 标签对象,如:<p class="title"><b>yoyoketang</b></p>,这就是一个标签
NavigableString :字符对象
BeautifulSoup :就是整个html对象
Comment :注释对象,如:!--for HTML5 --,它其实就是一个特殊NavigableString
1.find_all查找的是一个list对象
2.get_text() 获取tag标签下所有的文本
3.replace替换字符串里面的特殊字符
这篇关于request+BeautifulSoup爬取网站内容的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





