本文主要是介绍Python—豆瓣影评的爬取(指环王),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
之前闲着无聊,也不知哪里找到的这部电影,每一部都是快4个小时,看的,,,,,不过画面很美
编译环境:pycharm
需要导入的第三方库:requests 、BeautifulSoup、random
具体过程如下:
1.导入第三方库:具体方法见博客——>Python——爬取单章小说内容
2.关于豆瓣爬虫,我个人觉得豆瓣网是有反爬虫机制的,不过我的经验还是太少,只知道加请求头这一种方式来进行伪装,很可惜,我昨天晚上试了很久,找的请求头都没有办法使用,一直报404和418的错,就只能拿以前用过的请求头使了。
请求头:
def get_header():#360header1={"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36","Host":"erebor.douban.com"}#ieheader2={"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.140 Safari/537.36 Edge/17.17134","Host":"movie.douban.com"}#谷歌header3={"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.88 Safari/537.36","Host":"movie.douban.com"}header_list=[header1,header2,header3]index=random.randint(0,2)return header_list[index]在这里使用随机函数返回的原因:在下面用到请求头的时候,这个请求头是上面三个请求头中随机选择的一个请求头
3.获取想要的影评(不是短评呦!!!)的网址:
https://movie.douban.com/subject/1291571/reviews?start=0(关于这个链接:如果大家只是打开了影评,最后的?start=0是没有 的,点击一下第二页,再返回到第一页就可以看到了)
4.对网页进行解码:
for i in range(0,4):#这里的for循环知识为了能够获得多页的影评,最开始写的时候建议大家不要这个for循环,在下面的 start=%d"%(i*20) 中,将%d改为0 %(i*20)删去即可url="https://movie.douban.com/subject/1291571/reviews?start=%d"%(i*20)req=requests.get(url=url,headers=get_header())print("响应码",req.status_code)html = req.text# print(html)bf=BeautifulSoup(html,"lxml")# print(bf)div_comments=bf.find_all("div",class_="review-item")# print(div_comments)注意:1.打印响应码,一般情况下,打印的响应码是200,代表访问网页成功。如果是其他值,很大的可能就是访问不成功
2.上面打印的html bf div_comments 最后是代码进行到哪一步,就在哪一步打印一下,否则将来出错,不知道从哪里开始错误
3.怎么找上面的review-item:
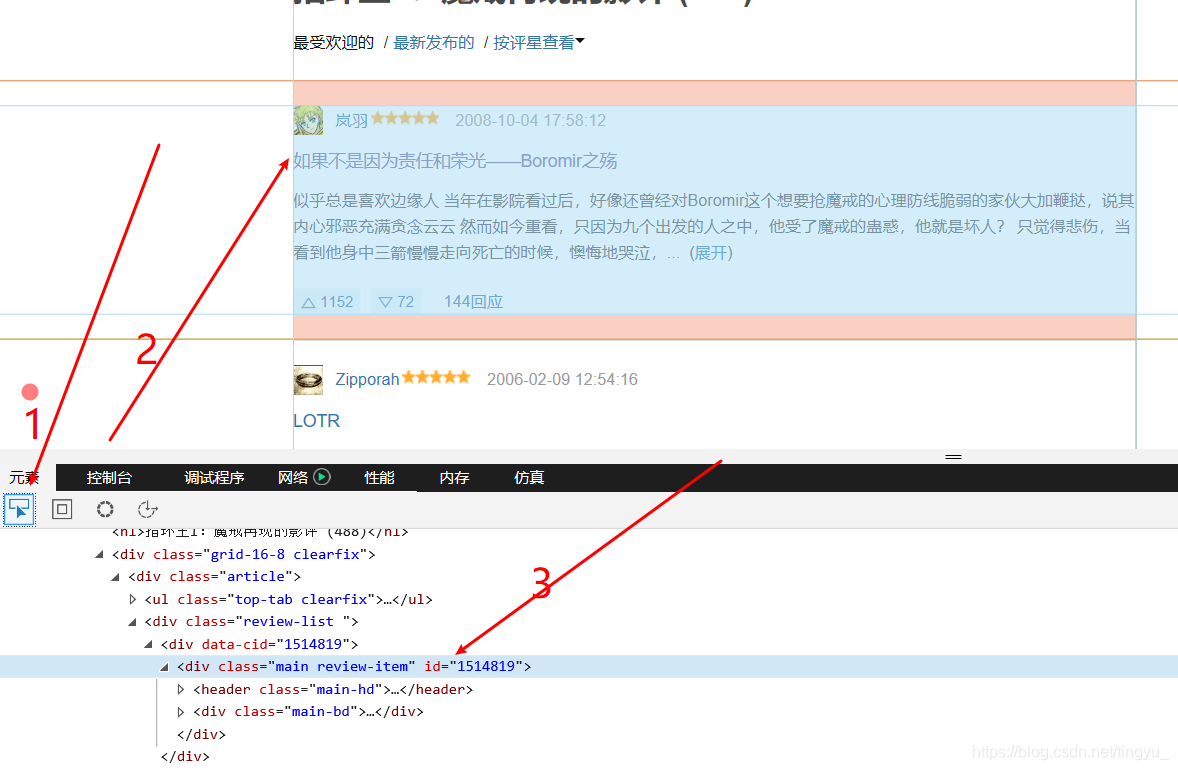
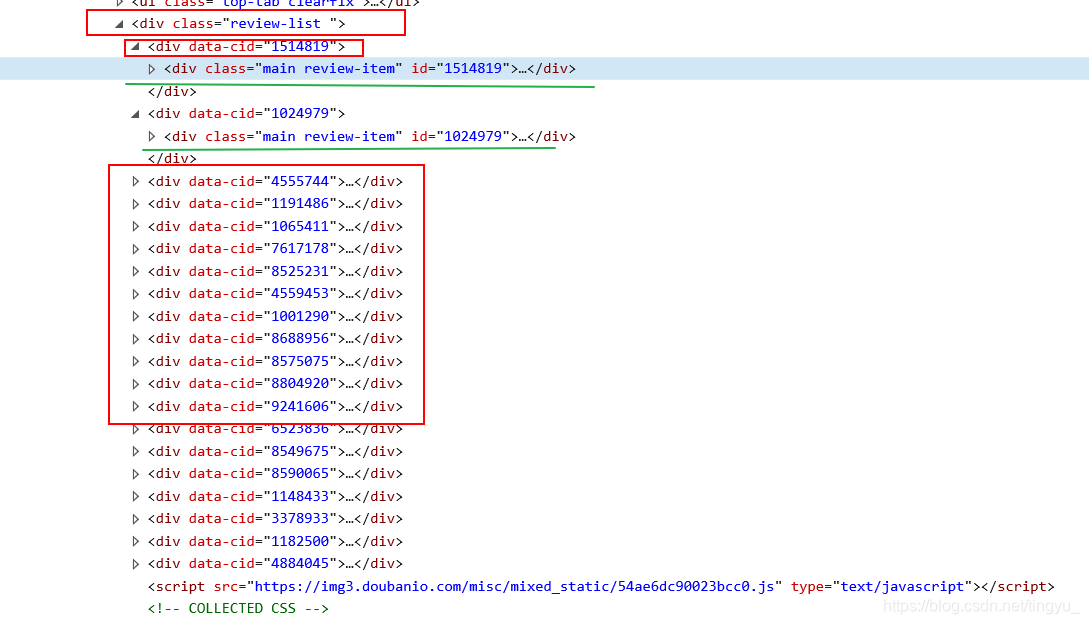
可知,每一条评论都是一个data-cid,每一个data-cid下都有review-item,通过这各就可以找到一个评论列表,如果使用是review-list,在列表中的就只有一个元素了。
4.对div_comments列表也就是review-item评论列表中的每一项进行循环遍历,
在这里可打印一下每一项(每一个item)可以进行验证,自己找的是否正确(可以加一些分隔符之类的)
for item in div_comments:print(item)print("+++++++++++++++++++++")5.从每一项的代码中找到每一项对应的 评论人的昵称,推荐指数,,和评语
(这里找的是为展开版的评论,能力有限,在找展开版时,总是获取不到代码,很是惭愧,想大家说)
name=item.select(".name")[0].string# print(comment_info)# name=comment_info.stringprint(name)star=item.select(".main-title-rating")[0].get("title")# star=comment_star.get("title")print(star)comment_review=item.select("div",class_="review-short")[2].textreview=comment_review.replace("\n\n","")review=review.replace(" ","")print(review)6.将爬取的评论写入文件:
with open("指环王豆瓣评论.txt","a",encoding="utf-8") as file:file.write("作者:%s\n" % name)file.write("星级推荐:%s\n" % star)file.write("评论内容:%s\n\n" % review)file.close()完整代码如下:
import requests
from bs4 import BeautifulSoup
import randomdef get_header():#360header1={"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36","Host":"erebor.douban.com"}#ieheader2={"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.140 Safari/537.36 Edge/17.17134","Host":"movie.douban.com"}#谷歌header3={"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.88 Safari/537.36","Host":"movie.douban.com"}header_list=[header1,header2,header3]index=random.randint(0,2)return header_list[index]
if __name__ == '__main__':for i in range(0,4):url="https://movie.douban.com/subject/1291571/reviews?start=%d"%(i*20)req=requests.get(url=url,headers=get_header())print("响应码",req.status_code)html = req.text# print(html)bf=BeautifulSoup(html,"lxml")# print(bf)div_comments=bf.find_all("div",class_="review-item")# print(div_comments)for item in div_comments:# print(item)print("+++++++++++++++++++++")name=item.select(".name")[0].string# print(comment_info)# name=comment_info.stringprint(name)star=item.select(".main-title-rating")[0].get("title")# star=comment_star.get("title")print(star)comment_review=item.select("div",class_="review-short")[2].textreview=comment_review.replace("\n\n","")review=review.replace(" ","")print(review)with open("指环王豆瓣评论.txt","a",encoding="utf-8") as file:file.write("作者:%s\n" % name)file.write("星级推荐:%s\n" % star)file.write("评论内容:%s\n\n" % review)file.close()上面代码中有两次使用了replace,是因为我看着获取到的内容之间间隔很大,只单单复制空白处来进行代替,会出现不在一行的错误,这个问题不同的人有不同的处理习惯,这里仅提供一种参考
前4页都已经证实可以没有问题的爬取下来
爬取结果展示:

这篇关于Python—豆瓣影评的爬取(指环王)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







