本文主要是介绍爬虫-电影影评爬取,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
先上代码
import requests
import timeheaders = {"referer": "http://movie.mtime.com/","user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/106.0.0.0 Safari/537.36"
}
for i in range(1, 6):params = {'tt': "{}".format(int(time.time() * 1000)),'movieId': '251525','pageIndex': i,'pageSize': '20','orderType': '1'}url = "http://front-gateway.mtime.com/library/movie/comment.api"result = requests.get(url, headers=headers, params=params)comments = result.json()['data']['list']for comment in comments:user = comment['nickname']content = comment["content"]print("用户:%s" % user)print("评论:%s" % content)time.sleep(1)
这里面有几个部分需要做下说明:
以哪吒之魔童降世来说,进入此网页,打开开发者模式,点击Network->XHR,因为我们找的是评论,其英文是comment,如下我们找到了。
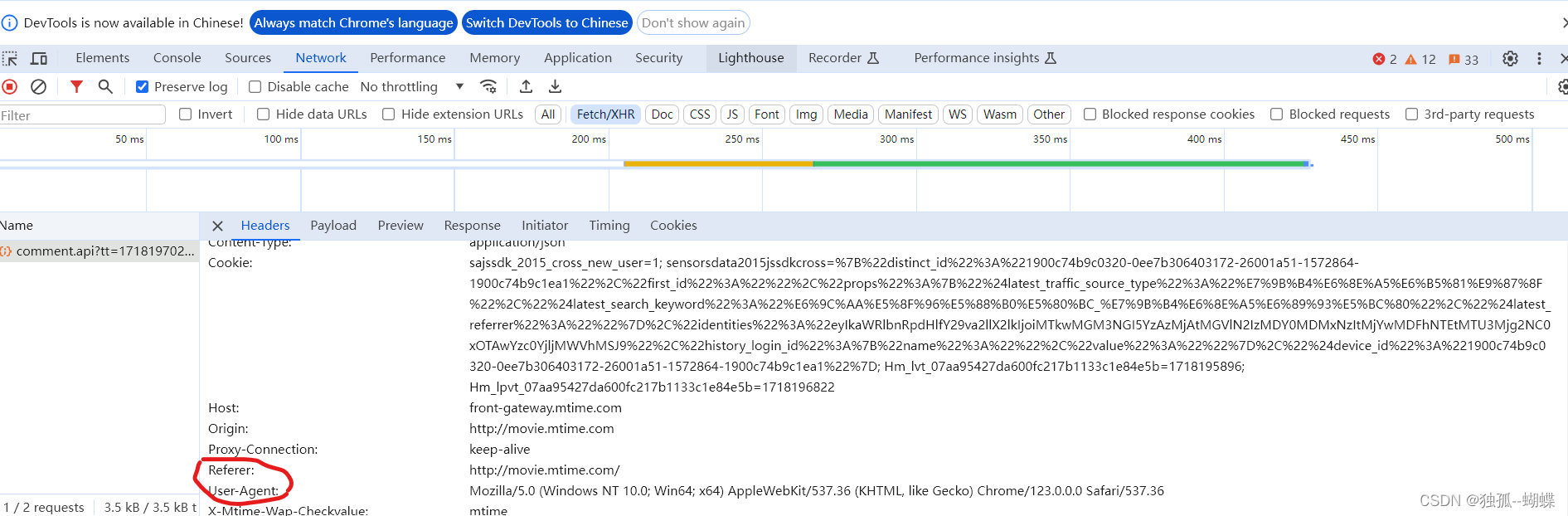
1.headers,它的来源是哪呢?
点击其头headers,拉到最下面,找到了Referer以及User-Agent,此值直接获取,(上面代码中的user-agent以自己电脑为准)。
2.params中的值。
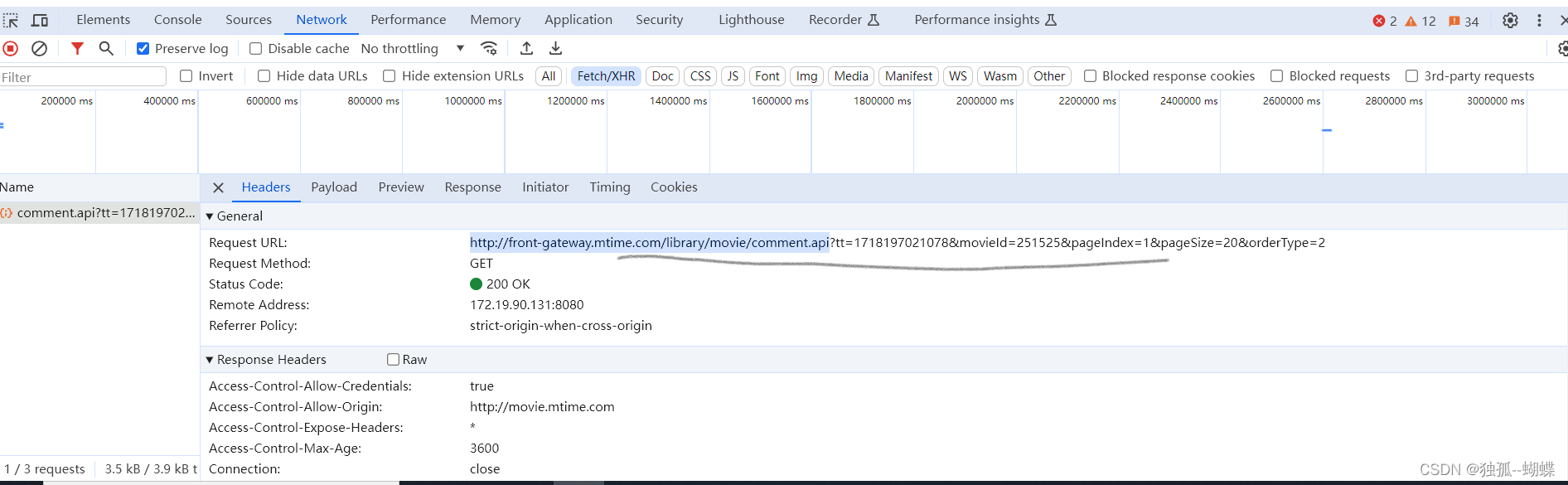
同样是来源于headers中,有个Request URL,它的值是
http://front-gateway.mtime.com/library/movie/comment.api?tt=1718197021078&movieId=251525&pageIndex=1&pageSize=20&orderType=2
我们知道链接中?后面的参数为查询参数,requests.get() 方法提供了 params 参数,能让我们以字典的形式传递链接的查询参数,那几个字段的意义如下:
movieId:电影在时光网中的ID
pageIndex:评论的第x页
pageSize:每页评论数
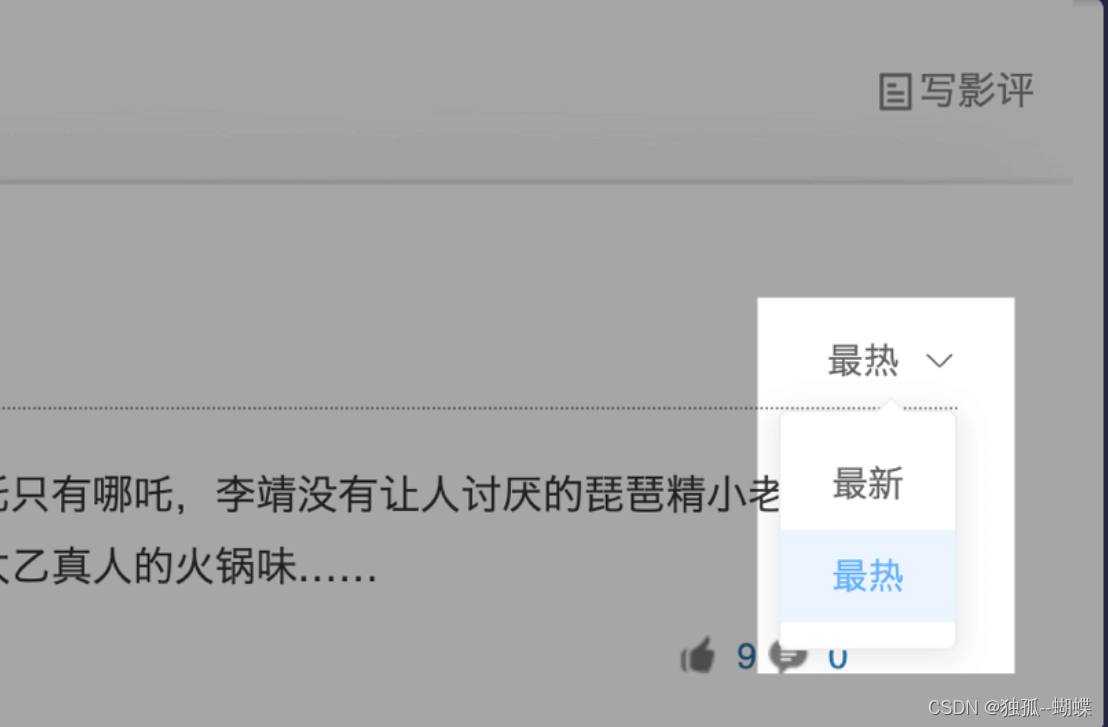
orderType:字面意思是排序方式,而我们发现,短影评页的右上方的确是有这个选项的。值为 1 代表的应该就是按最热排序
tt:时间戳
3.result.json()
result我们知道是获取出来的结果,但是.json的意义是什么?我们需要json是什么
json:(JavaScript Object Notation)是一种轻量级的数据交换格式;构建于两种结构:键值对的集合 和 值的有序列表,分别对应python中 字典和列表。其本质是字符串,只是该字符串符合特定的格式要求。
4.time.sleep(1) 此处是为了让爬虫慢一点,防止被封
这篇关于爬虫-电影影评爬取的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








