当当网专题

专访当当网张亮:深度解读分布式作业调度框架elastic-job
摘要:日前,笔者采访了当当网架构师、当当技术委员会成员张亮,在本次采访中他主要分享了对架构师的理解,以及重点解读了分布式作业调度框架elastic-job是什么、架构设计思路、具体模块的底层及如何实现等。 【编者按】互联网从诞生到现在,网站的规模不断扩大,存储和处理的数据量也远远超出了人们的想象,又随着对信息实时性、多媒体需求大幅增长的现象,互联网架构面临越来越大的挑战。CSDN致力于

当当网近4年图书畅销榜单分析(看看你喜欢的书籍/作者是否在里面)
1.项目背景 在图书市场中,了解读者的行为和需求对于制定有效的营销策略至关重要。本项目通过分析当当网2020至2023年的畅销书排行榜数据,利用可视化分析和数据挖掘技术,对上榜图书和作者进行深入分析,出版商和网站能够更好地理解读者的需求,从而制定更有效的市场策略,提升用户满意度,最终推动业务发展。 2.数据说明 字段说明排行榜类型数据对应的年份,例如2020年、2021年等。排序书籍在榜单中
【爬虫之scrapy框架——尚硅谷(学习笔记one)--基本步骤和原理+爬取当当网(基本步骤)】
爬虫之scrapy框架——基本原理和步骤+爬取当当网(基本步骤) 下载scrapy框架创建项目(项目文件夹不能使用数字开头,不能包含汉字)创建爬虫文件(1)第一步:先进入到spiders文件中(进入相应的位置)(2)第二步:创建爬虫文件(3)第三步:查看创建的项目文件——检查路径是否正确 运行爬虫代码查看robots协议——是否有反爬取机制——君子协议(修改君子协议)(1)查看某网站的君子
python爬虫实战2-获取当当网近30日好评榜前500本书籍-使用BeautifulSoup
所有的一切都跟上一篇文章是一样的,不同的是不用写长长的正则表达式啦,上一期传送门https://blog.csdn.net/u010376229/article/details/114042780 这次我们需要用到BeautifulSoup,只需简单的学习一下就剋不用写正则表达式啦,而且更加清楚 def get_books_info_of_current_page(page):html = g

python爬虫实战1-获取当当网近30日好评榜前500本书籍
1、首先打开当当网,点击好评榜,选择近30日,此时浏览器中的URL复制一下,备用 http://bang.dangdang.com/books/fivestars/01.00.00.00.00.00-recent30-0-0-1-1 2、每一页显示20本书,点击下一页可以发现URL变化了,但是只有最后一个数变化,http://bang.dangdang.com/books/fivestar

详解当当网的分布式架构Elastic-Job
作业的必要性以及存在的问题 1. 为什么需要作业? 作业即定时任务。一般来说,系统可使用消息传递代替部分使用作业的场景。两者确有相似之处。可互相替换的场景,如队列表。将待处理的数据放入队列表,然后使用频率极短的定时任务拉取队列表的数据并处理。这种情况使用消息中间件的推送模式可更好的处理实时性数据。而且基于数据库的消息存储吞吐量远远小于基于文件的顺序追加消息存储。 但在某些场景下则不能互换
【Python从入门到进阶】49、当当网Scrapy项目实战(二)
接上篇《48、当当网Scrapy项目实战(一)》 上一篇我们正式开启了一个Scrapy爬虫项目的实战,对当当网进行剖析和抓取。本篇我们继续编写该当当网的项目,讲解刚刚编写的Spider与item之间的关系,以及如何使用item,以及使用pipelines管道进行数据下载的操作。 一、使用item封装数据 在上一篇我们通过编写的爬虫文件,获取到当当网“一般管理类”书籍的第一页的明细列表信息。但是

SpringBoot整合当当网config toolkit管理配置信息
使用configtoolkit的原因 在大型分布式集群应用中,配置不应该分散在每个集群节点。应该统一配置中心,有两个好处: (1)配置全局管理,一处修改,则重启程序时不用每次都修改配置文件。 (2)配置文件配置热更新,程序中应用到的配置,可以集中修改,然后每个节点立刻生效。 官网地址 https://github.com/dangdangdotcom/config-toolkithttp
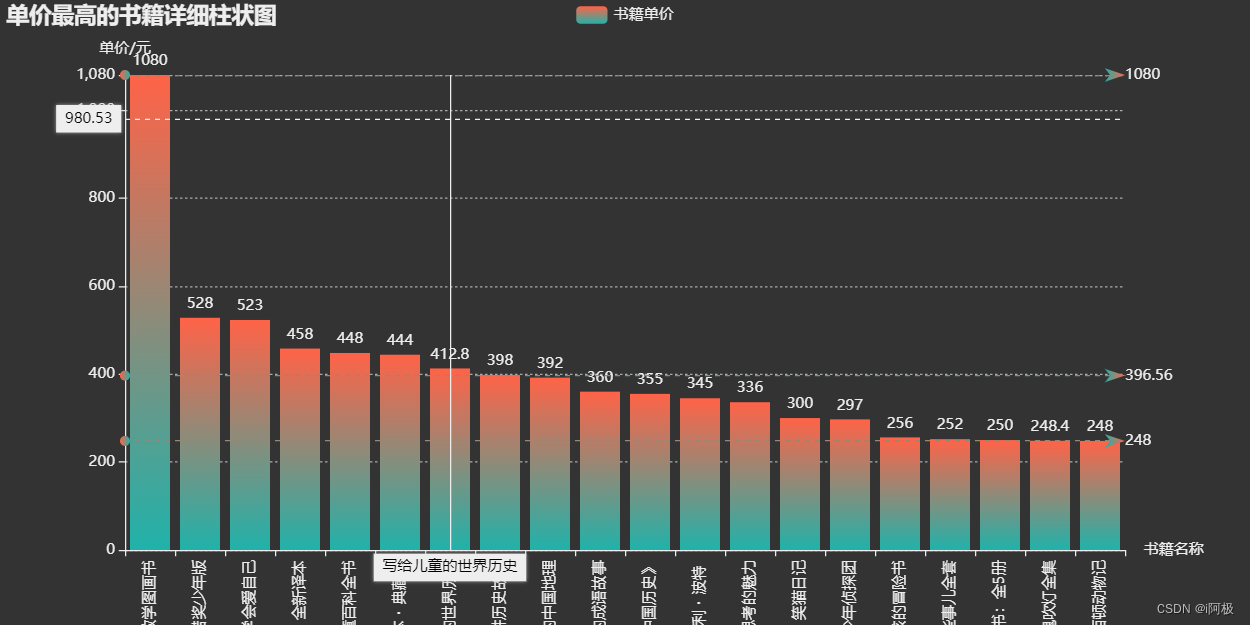
数据分析:当当网书籍数据可视化分析
当当网书籍数据可视化分析 作者:i阿极 作者简介:Python领域新星作者、多项比赛获奖者:博主个人首页 😊😊😊如果觉得文章不错或能帮助到你学习,可以点赞👍收藏📁评论📒+关注哦!👍👍👍 📜📜📜如果有小伙伴需要数据集和学习交流,文章下方有交流学习区!一起学习进步!💪 专栏案例:《数据可视化分析》数据分析:某电商优惠卷数据分析数据分析:旅游景点销售门票和消费
php快速采集图书图片,傻瓜操作批量采集当当网图片神器,不再担心素材的问题...
当当网是国内最早的图书购买平台,网站上有大量的图书信息,做图书网店的朋友们在处理产品图片时会参考大量的同类产品,在当当网遇到喜欢的图片可以批量保存到电脑,而且操作的方法也非常简单,一键就能操作,为电商朋友节省大量的时间,接下来我们一起了解当当网图片批量下载的方法吧。 需要准备的工具: Win7或Win7以上系统的电脑一台 常用的浏览器 提前到固乔工作室网站下载固乔电商图片助手 具体的操作步骤如
【Python从入门到进阶】48、当当网Scrapy项目实战(一)
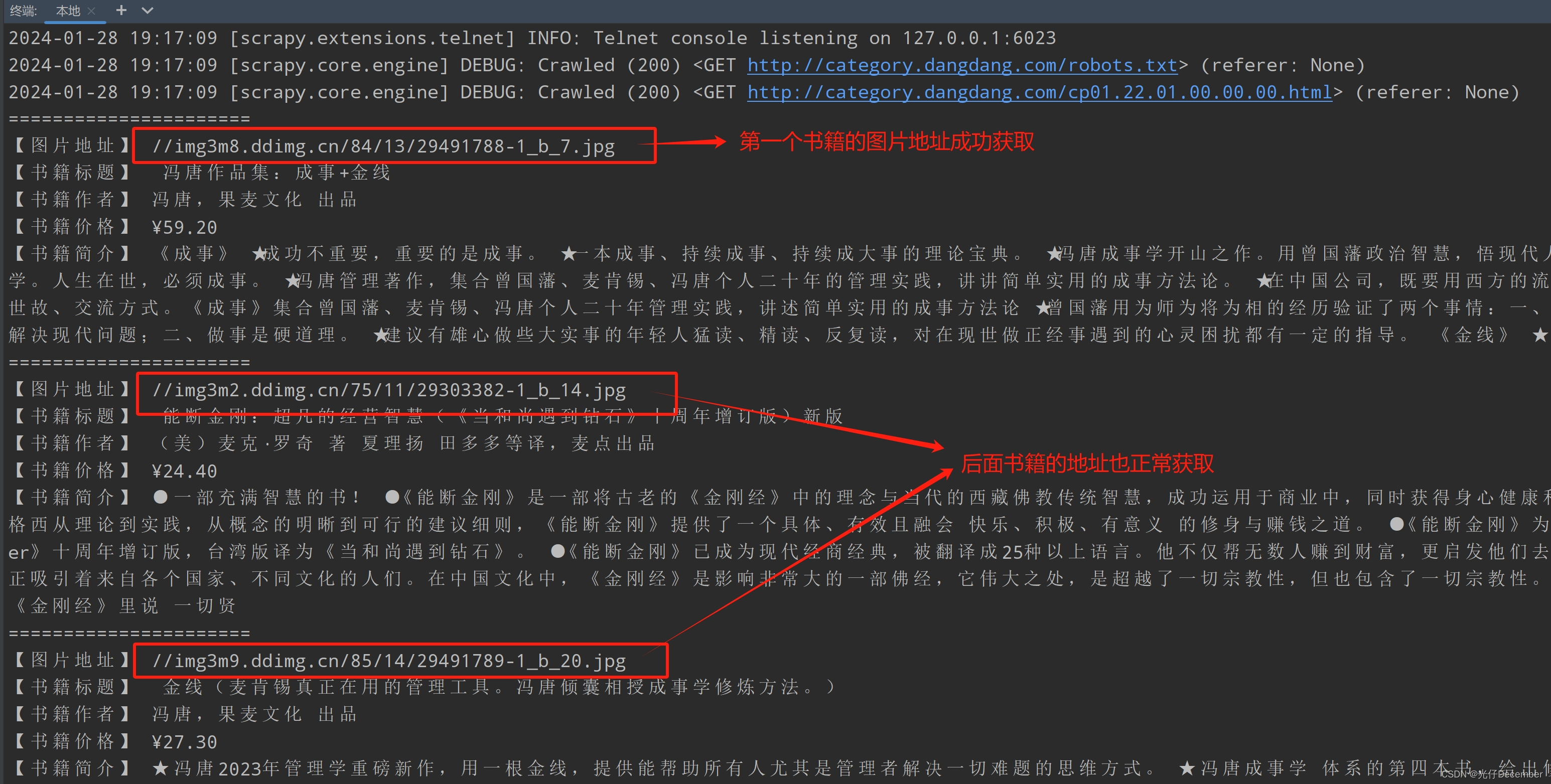
接上篇《47、Scrapy Shell的了解与应用》 上一篇我们学习了Scrapy终端命令行工具Scrapy Shell,并了解了它是如何帮助我们更好的调试爬虫程序的。本篇我们将正式开启一个Scrapy爬虫项目的实战,对当当网进行剖析和抓取。 一、当当网介绍 当当网成立于1999年11月,是一家知名的综合性网上购物商城。从早期以图书业务为主的业务形态,逐步拓展到全品类百货,包括图书音像、美妆、

jquery banner广告幻灯片图片轮播切换,模仿实现当当网滚动广告效果
原文:jquery banner广告幻灯片图片轮播切换,模仿实现当当网滚动广告效果 源代码下载地址:http://www.zuidaima.com/share/1749919126785024.htm Jqurey实现的一个滚动图片的效果,用的朋友可以用一下 滚动效果 很简单的代码 供大家学习参考 入门学习很好的 官方验证: 是通过jquery实现的
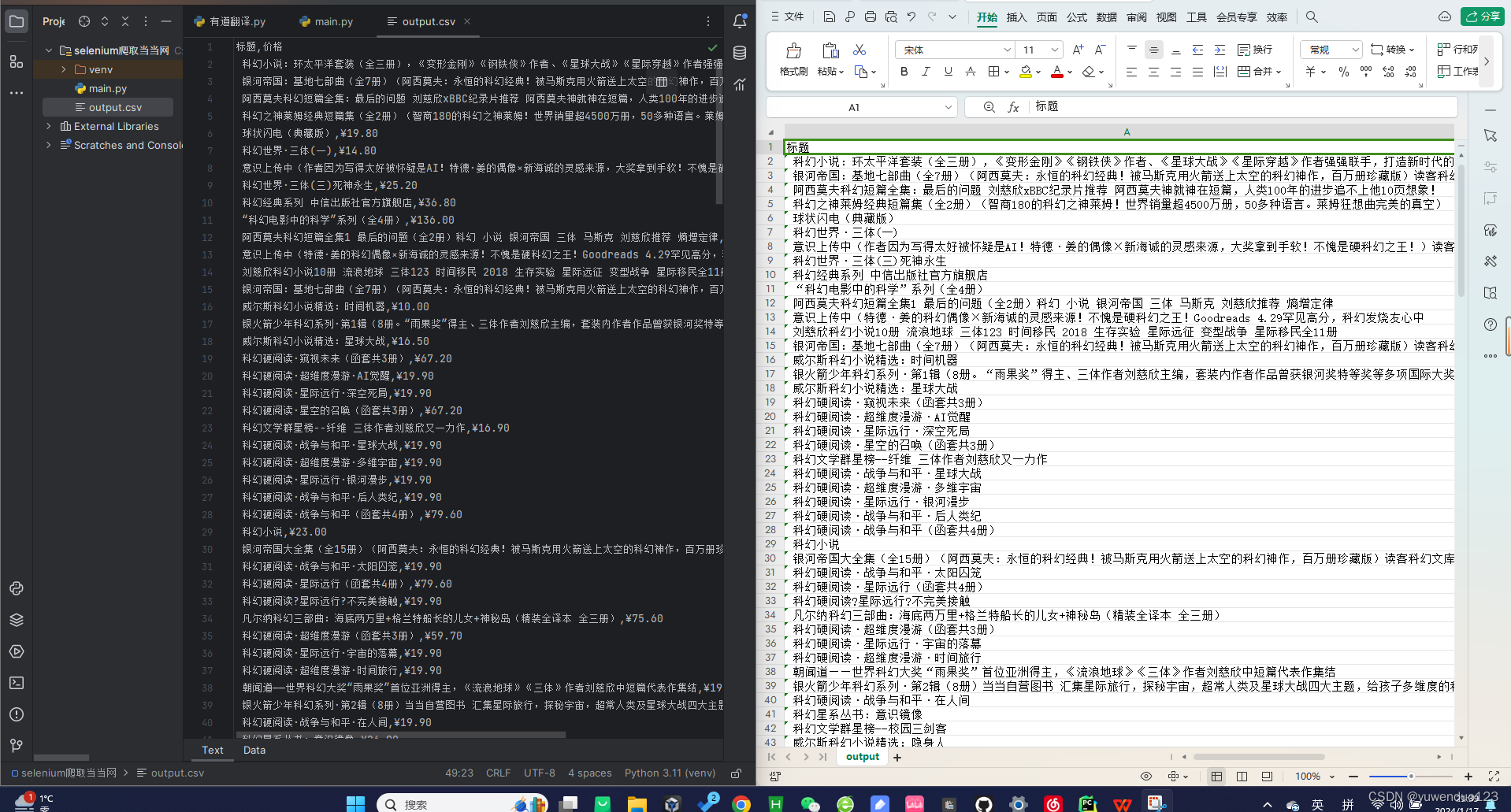
selenium爬虫爬取当当网书籍信息 | 最新!
如果对selenium不了解的话可以到下面的链接中看基础内容: selenium爬取有道翻译-CSDN博客 废话不多说了下面是代码并且带有详细的注释: 爬取其他类型的书籍和下面基本上是类似的可以自行更改。 # 导入所需的库from selenium import webdriverfrom selenium.webdriver.common.by import Byfrom sele
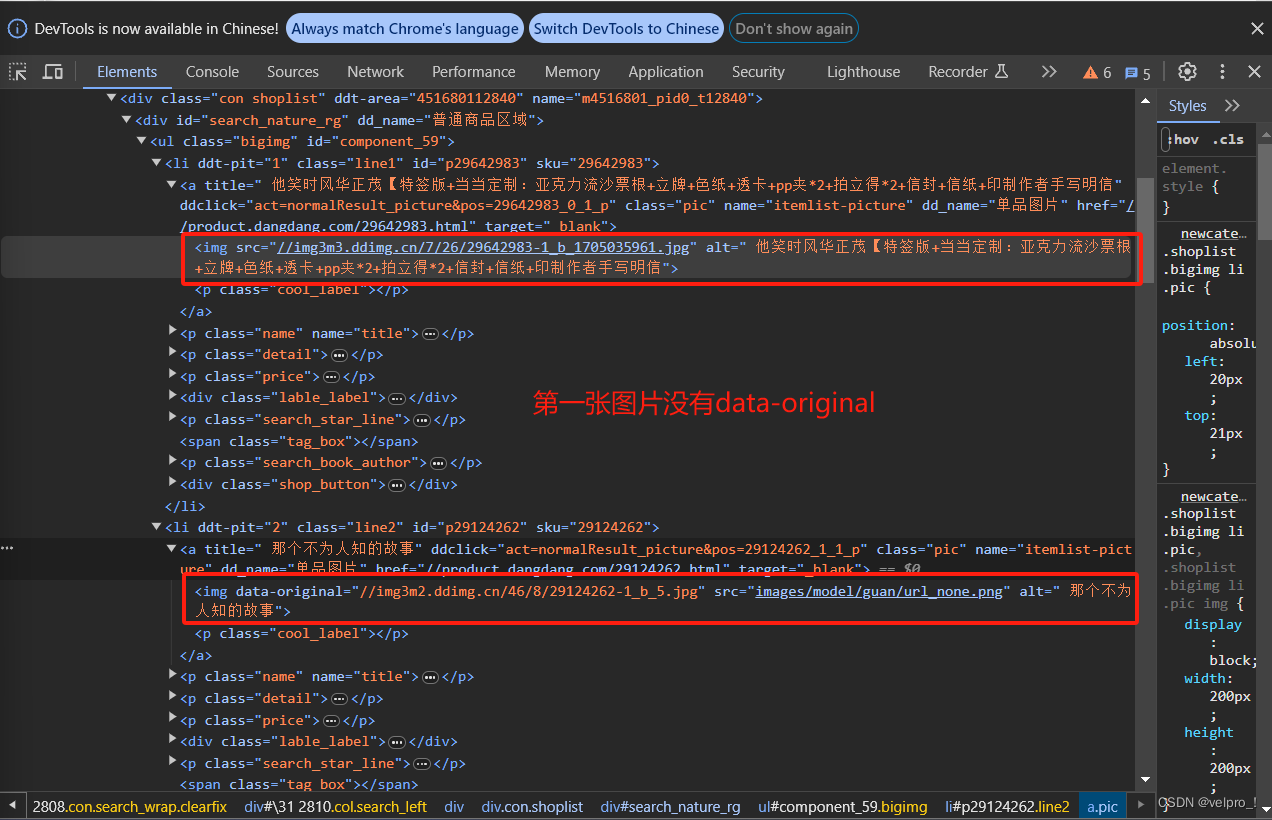
Python爬虫---scrapy框架---当当网管道封装
项目结构: dang.py文件:自己创建,实现爬虫核心功能的文件 import scrapyfrom scrapy_dangdang_20240113.items import ScrapyDangdang20240113Itemclass DangSpider(scrapy.Spider):name = "dang" # 名字# 如果是多页下载的话, 那么必须要调整的是allo
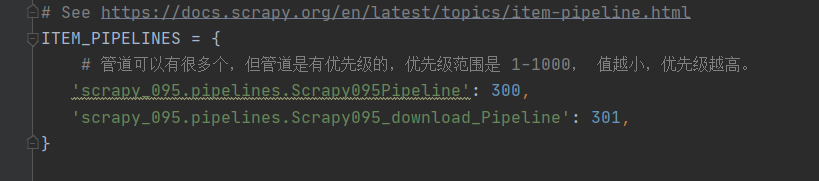
爬虫 scrapy ——scrapy shell调试及下载当当网数据(十一)
目录 一、scrapy shell 1.什么是scrapy shell? 2.安装 ipython 3.使用scrapy shell 二、当当网案例 1.在items.py中定义数据结构 2.在dang.py中解析数据 3.使用pipeline保存 4.多条管道的使用 5.多页下载 参考 一、scrapy shell 1.什么是scrapy shell? 什
1024程序员节,给猿媛们的超值当当网购书薅羊毛
📢1024程序员节来啦~ 向可爱的程序员们致敬! 🎬“人们总说这个世界将被天才改变,但实际上真正将那些天马行空的想象变为现实的,很大概率是看似平凡的程序员们。”随着信息产业日新月异的发展,我们的出行、娱乐、学习…都变的更加便捷高效,这些都离不开程序员的贡献。 🚀话不多说先把福利送上! 👍 当当网计算机图书大促👍 😮全场 5 折😮 不止这些! ⌛机械工业出版社联合爱上游戏

scrapy-redis分布式爬虫,爬取当当网图书信息
前期准备 虚拟机下乌班图下redis:url去重,持久化mongodb:保存数据PyCharm:写代码谷歌浏览器:分析要提取的数据爬取图书每个分类下的小分类下的图书信息(分类标题,小分类标题,图书标题,作者,图书简介,价格,电子书价格,出版社,封面,图书链接) 思路:按每个大分类分组,再按小分类分组,再按每本书分组,最后提取数据 下面是代码 爬虫代码 # -*- coding: utf-

python 网络爬虫技术 运用正则表达式爬取当当网(实战演练)
爬取网络:当当网 代码 import reimport requestsimport timeimport xlwturl_basic = 'http://search.dangdang.com/?key='heads = {'Connection': 'keep-alive','Accept-Language': 'zh-CN,zh;q=0.9','Accept': 'text/html

通过Python爬取当当网,学正则表达式
本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,,版权归原作者所有,如有问题请及时联系我们以作处理 作者:啃书君 来源:掘金 原文链接:https://juejin.cn/post/6911667019435737101 PS:如有需要Python学习资料的小伙伴可以加点击下方链接自行获取 python免费学习资料以及群交流解答点击即可加入 准备工作 工欲善
最后一天!当当网160元购买400元图书的优惠活动
文末有干货 “Python高校”,马上关注 真爱,请置顶或星标 囤书囤书,一起薅当当的羊毛 我们一起阅读经典,紧跟前沿技术不掉队 新学期我决定一定要努力学习 没有新书给我充电怎么行? 每次买完新书,感觉都是在开一场私人签售会 哈哈哈这感觉真不错 当当网自营图书大促 >> 每满100减50 << 满200减100 满300减150 满400减200 以为只有这样?秉持绝不让大家多花一分

当当网上筛选“python爬虫”系列书籍爬取9页数据
这周,我们老师让我们写个爬取电商数据的作业,题目如下 对此,我选择了在当当网上爬取“python爬虫”的数据,接下来我将附上我写的代码: # -*- coding: utf-8 -*-import requestsimport csvfrom bs4 import BeautifulSoup as bs#获取网页信息def request_dandan(url): try:#用户代理