本文主要是介绍数据分析:当当网书籍数据可视化分析,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

当当网书籍数据可视化分析
作者:i阿极
作者简介:Python领域新星作者、多项比赛获奖者:博主个人首页
😊😊😊如果觉得文章不错或能帮助到你学习,可以点赞👍收藏📁评论📒+关注哦!👍👍👍
📜📜📜如果有小伙伴需要数据集和学习交流,文章下方有交流学习区!一起学习进步!💪
| 专栏案例:《数据可视化分析》 |
|---|
| 数据分析:某电商优惠卷数据分析 |
| 数据分析:旅游景点销售门票和消费情况分析 |
| 数据分析:消费者数据分析 |
| 数据分析:餐厅订单数据分析 |
| 数据分析:基于随机森林(RFC)对酒店预订分析预测 |
| 数据分析:基于K-近邻(KNN)对Pima人糖尿病预测分析 |
| 数据分析:麦当劳食品营养数据探索并可视化 |
文章目录
- 当当网书籍数据可视化分析
- 1、前言
- 2、导入模块
- 3、导入数据
- 4、数据预处理
- 4.1、数据处理
- 4.2、提取评论数
- 4.3、原价、售价、电子书价格 数值化
- 4.4、选择需要用到的列
- 4.5、缺失值
- 4.6、电子书价格列额外处理
- 4.7、重复值
- 5、数据可视化
- 5.1、书籍总体价格区间
- 5.2、各个出版社书籍数量柱状图
- 5.3、电子书版本占比
- 5.4、书籍评论数最高Top20
- 总结
1、前言
随着互联网的快速发展,电子商务行业在中国经历了爆炸式的增长。作为国内知名的在线购物平台,当当网在其中发挥了举足轻重的作用。为了更好地满足消费者的需求,优化用户体验,提高运营效率,数据分析成为了当当网运营过程中不可或缺的一环。
数据分析在电子商务中扮演着至关重要的角色。通过对大量数据的挖掘和分析,企业可以洞察市场趋势,了解用户行为,优化产品布局,制定营销策略等。当当网的数据分析流程旨在从海量数据中提取有价值的信息,为公司的决策提供数据支持。
2、导入模块
import pandas as pd
from pyecharts.charts import *
from pyecharts.globals import ThemeType
from pyecharts.commons.utils import JsCode
import pyecharts.options as opts
import pandas as pd: 导入pandas库,并给它一个简短的别名pd。pandas是一个用于数据处理和分析的强大库。
from pyecharts.charts import *: 从pyecharts库的charts模块导入所有内容。pyecharts是一个用于生成Echarts图表的Python库。
from pyecharts.globals import ThemeType: 从pyecharts库的globals模块导入ThemeType。这可能用于设置图表的默认主题。
from pyecharts.commons.utils import JsCode: 从pyecharts库的commons.utils模块导入JsCode。这可能是一个用于与JavaScript代码交互的工具。
import pyecharts.options as opts: 从pyecharts库导入其选项模块,并给它一个简短的别名opts。这可能用于配置图表的选项和参数。
这段代码主要用于数据分析和可视化的目的,特别是使用Echarts图表库来生成和配置图表。
3、导入数据
df = pd.read_csv('.\书籍信息.csv')
df.head()

4、数据预处理
4.1、数据处理
从DataFrame的’标题’列中提取书名(不包括括号及其内容),并将结果存储在新列’书名’中,然后显示这个处理过的DataFrame的前五行。
df['书名'] = df['标题'].apply(lambda x:x.split('(')[0])
df.head()
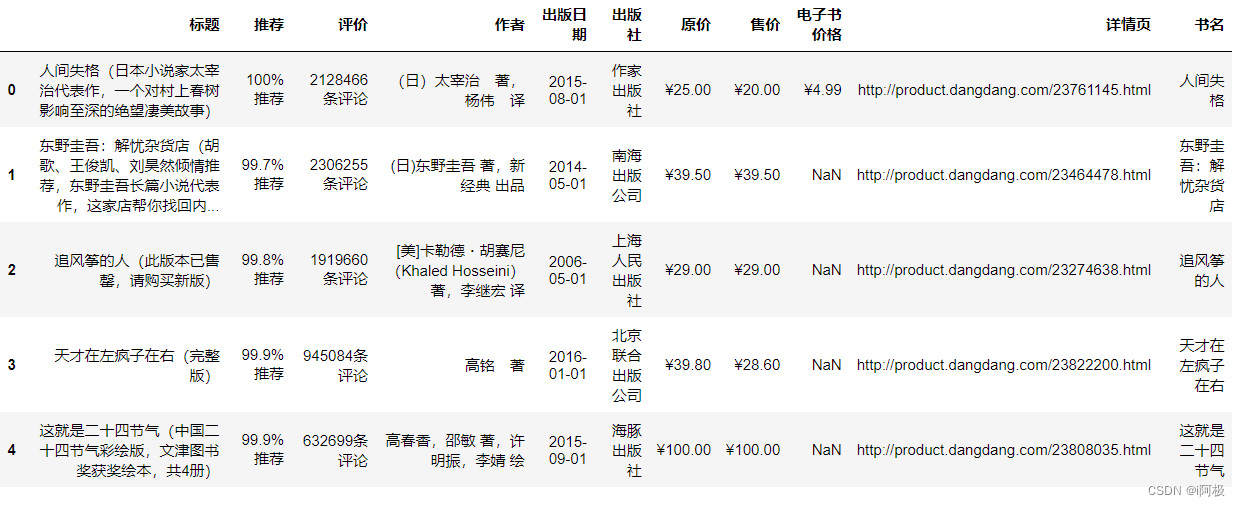
从DataFrame的’标题’列中提取书籍简介(括号及其内容),并将结果存储在新列’书籍简介’中,然后将缺失的值替换为’无’,最后显示这个处理过的DataFrame的第一行。
df['书籍简介'] = df['标题'].str.extract('.*?((.*?))')
df['书籍简介'].fillna('无', inplace=True)
df.head(1)

4.2、提取评论数
从DataFrame的’评价’列中提取评论数(去掉’条评论’),并将结果存储在新列’评论数’中,然后显示这个处理过的DataFrame的第一行。
df['评论数'] = df['评价'].str.replace('条评论','').astype('int64')
df.head(1)

4.3、原价、售价、电子书价格 数值化
从DataFrame的’原价’、'售价’和’电子书价格’列中删除所有的’¥’字符,然后显示这个处理过的DataFrame的第一行。
df['原价'] = df['原价'].str.replace('¥', '')
df['售价'] = df['售价'].str.replace('¥', '')
df['电子书价格'] = df['电子书价格'].str.replace('¥', '')
df.head(1)

df.info()

从DataFrame的’原价’和’售价’列中删除所有的’,'字符,并将这两列从字符串转换为浮点数
df['原价'] = df['原价'].str.replace(',', '').astype('float64')
df['售价'] = df['售价'].str.replace(',', '').astype('float64')
4.4、选择需要用到的列
df = df[['书名','书籍简介','评论数','作者','出版日期','出版社','原价','售价','电子书价格']]
df.head(1)

4.5、缺失值
df.isnull().sum()
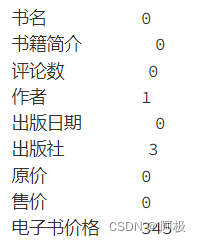
df['作者'].fillna('未知', inplace=True)
df['出版社'].fillna('未知', inplace=True)
df.isnull().sum()

4.6、电子书价格列额外处理
df['电子书价格'] = df['电子书价格'].str.replace(',', '').astype('float64')
df['电子书价格'].fillna('无电子书版本', inplace=True)
4.7、重复值
计算DataFrame df中的重复行数。
df.duplicated().sum()
输出:
0
df.info()

生成描述性统计信息
df.describe()

5、数据可视化
5.1、书籍总体价格区间
这个函数tranform_price根据输入的价格值,返回一个描述价格范围的字符串。如果价格小于或等于50元,返回’050元’;如果价格在50到100元之间,返回’51100元’;以此类推,如果价格大于1000元,返回’1000以上’。
def tranform_price(x):if x <= 50.0:return '0~50元'elif x <= 100.0:return '51~100元'elif x <= 500.0:return '101~500元'elif x <= 1000.0:return '501~1000元'else:return '1000以上'
将DataFrame df中的’原价’列转换为’价格分级’列,并统计每个价格分级的出现次数。
df['价格分级'] = df['原价'].apply(lambda x:tranform_price(x))
price_1 = df['价格分级'].value_counts()
datas_pair_1 = [(i, int(j)) for i, j in zip(price_1.index, price_1.values)]
这段代码将DataFrame df中的’售价’列转换为’售价价格分级’列,并统计每个售价价格分级的出现次数。结果存储在price_2和datas_pair_2中。
df['售价价格分级'] = df['售价'].apply(lambda x:tranform_price(x))
price_2 = df['售价价格分级'].value_counts()
datas_pair_2 = [(i, int(j)) for i, j in zip(price_2.index, price_2.values)]
pie1 = (Pie(init_opts=opts.InitOpts(theme='dark',width='1000px',height='600px')).add('', datas_pair_1, radius=['35%', '60%']).set_series_opts(label_opts=opts.LabelOpts(formatter="{b}:{d}%")).set_global_opts(title_opts=opts.TitleOpts(title="当当网书籍\n\n原价价格区间", pos_left='center', pos_top='center',title_textstyle_opts=opts.TextStyleOpts(color='#F0F8FF', font_size=20, font_weight='bold'),)).set_colors(['#EF9050', '#3B7BA9', '#6FB27C', '#FFAF34', '#D8BFD8', '#00BFFF', '#7FFFAA'])
)
pie1.render_notebook()

5.2、各个出版社书籍数量柱状图
找出拥有最多书籍的20家出版社
counts = df.groupby('出版社')['书名'].count().sort_values(ascending=False).head(20)
bar=(Bar(init_opts=opts.InitOpts(height='500px',width='1000px',theme='dark')).add_xaxis(counts.index.tolist()).add_yaxis('出版社书籍数量',counts.values.tolist(),label_opts=opts.LabelOpts(is_show=True,position='top'),itemstyle_opts=opts.ItemStyleOpts(color=JsCode("""new echarts.graphic.LinearGradient(0, 0, 0, 1,[{offset: 0,color: 'rgb(255,99,71)'}, {offset: 1,color: 'rgb(32,178,170)'}])"""))).set_global_opts(title_opts=opts.TitleOpts(title='各个出版社书籍数量柱状图'),xaxis_opts=opts.AxisOpts(name='书籍名称',type_='category', axislabel_opts=opts.LabelOpts(rotate=90),),yaxis_opts=opts.AxisOpts(name='数量',min_=0,max_=29.0,splitline_opts=opts.SplitLineOpts(is_show=True,linestyle_opts=opts.LineStyleOpts(type_='dash'))),tooltip_opts=opts.TooltipOpts(trigger='axis',axis_pointer_type='cross')).set_series_opts(markline_opts=opts.MarkLineOpts(data=[opts.MarkLineItem(type_='average',name='均值'),opts.MarkLineItem(type_='max',name='最大值'),opts.MarkLineItem(type_='min',name='最小值'),]))
)
bar.render_notebook()

5.3、电子书版本占比
计算在DataFrame df中没有电子书版本的书所占的百分比,并将这个百分比值赋给变量per。
per = df['电子书价格'].value_counts()['无电子书版本']/len(df)
c = (Liquid().add("lq", [1-per], is_outline_show=False).set_global_opts(title_opts=opts.TitleOpts(title="电子书版本占比"))
)
c.render_notebook()

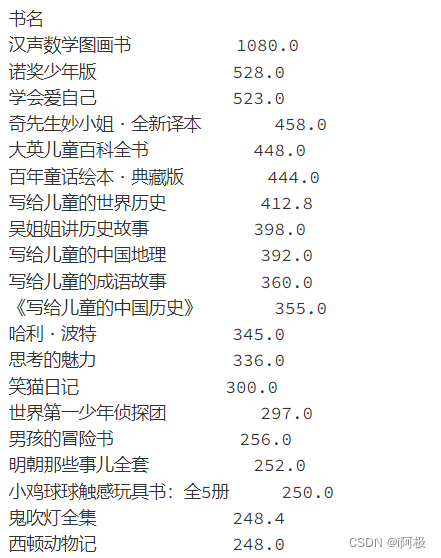
5.4、书籍评论数最高Top20
price_top = df.groupby('书名')['原价'].sum().sort_values(ascending=False).head(20)
price_top
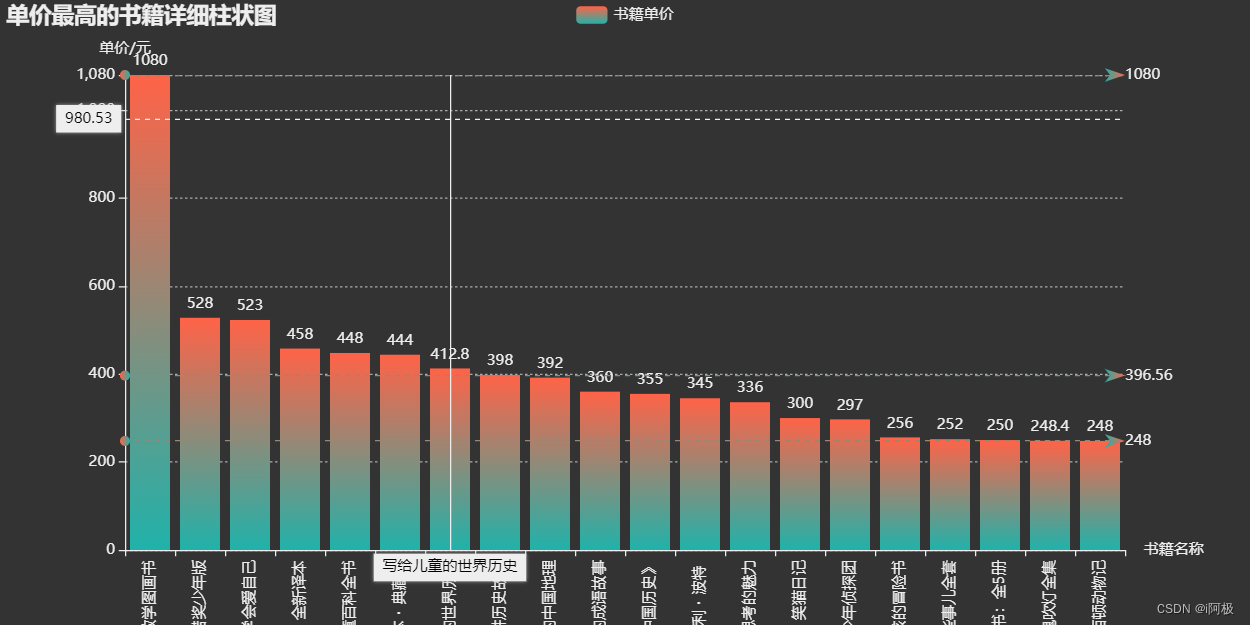
bar=(Bar(init_opts=opts.InitOpts(height='500px',width='1000px',theme='dark')).add_xaxis(price_top.index.tolist()).add_yaxis('书籍单价',price_top.values.tolist(),label_opts=opts.LabelOpts(is_show=True,position='top'),itemstyle_opts=opts.ItemStyleOpts(color=JsCode("""new echarts.graphic.LinearGradient(0, 0, 0, 1,[{offset: 0,color: 'rgb(255,99,71)'}, {offset: 1,color: 'rgb(32,178,170)'}])"""))).set_global_opts(title_opts=opts.TitleOpts(title='单价最高的书籍详细柱状图'),xaxis_opts=opts.AxisOpts(name='书籍名称',type_='category', axislabel_opts=opts.LabelOpts(rotate=90),),yaxis_opts=opts.AxisOpts(name='单价/元',min_=0,max_=1080.0,splitline_opts=opts.SplitLineOpts(is_show=True,linestyle_opts=opts.LineStyleOpts(type_='dash'))),tooltip_opts=opts.TooltipOpts(trigger='axis',axis_pointer_type='cross')).set_series_opts(markline_opts=opts.MarkLineOpts(data=[opts.MarkLineItem(type_='average',name='均值'),opts.MarkLineItem(type_='max',name='最大值'),opts.MarkLineItem(type_='min',name='最小值'),]))
)
bar.render_notebook()
总结
本次数据分析为当当网提供了有价值的洞察和建议。通过深入挖掘和分析销售数据,我们可以更好地了解用户需求和市场趋势,优化库存管理、营销策略和推荐系统。同时,这些发现也为企业决策提供了依据,有助于促进图书市场的可持续发展。
📢文章下方有交流学习区!一起学习进步!💪💪💪
📢首发CSDN博客,创作不易,如果觉得文章不错,可以点赞👍收藏📁评论📒
📢你的支持和鼓励是我创作的动力❗❗❗
这篇关于数据分析:当当网书籍数据可视化分析的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









