本文主要是介绍selenium爬虫爬取当当网书籍信息 | 最新!,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
如果对selenium不了解的话可以到下面的链接中看基础内容:
selenium爬取有道翻译-CSDN博客
废话不多说了下面是代码并且带有详细的注释:
爬取其他类型的书籍和下面基本上是类似的可以自行更改。
# 导入所需的库
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import time
import csv# 创建一个Chrome浏览器实例,并设置为无头模式(不显示界面)
options = webdriver.ChromeOptions()
options.add_argument('--headless')
driver = webdriver.Chrome(options=options)# 访问当当网首页
driver.get('https://www.dangdang.com/')# 在搜索框中输入关键词"科幻"
key = driver.find_element(By.ID, "key_S")
key.send_keys("科幻")# 点击搜索按钮
element = driver.find_element(By.ID, "search_btn")
driver.execute_script("arguments[0].click();", element)# 创建CSV文件并写入表头
with open('output.csv', 'w', newline='', encoding='utf-8') as csvfile:writer = csv.writer(csvfile)writer.writerow(['标题', '价格'])# 循环爬取前3页的书籍信息
for i in range(3):# 获取当前页面的所有书籍列表shoplist = driver.find_elements(By.CSS_SELECTOR, ".shoplist li")# 遍历每本书的信息for li in shoplist:# 获取书名title = li.find_element(By.CSS_SELECTOR, "a").get_attribute("title")# 获取价格price = li.find_element(By.CSS_SELECTOR, ".search_now_price").text# 将获取到的数据添加到CSV文件中with open('output.csv', 'a', newline='', encoding='utf-8') as csvfile:writer = csv.writer(csvfile)writer.writerow([title, price])# 获取下一页的链接并点击next = driver.find_element(By.LINK_TEXT, "下一页")next.click()# 等待页面加载完成time.sleep(2)# 当用户输入1时,退出浏览器
if input('1'):driver.quit()
下面是运行效果
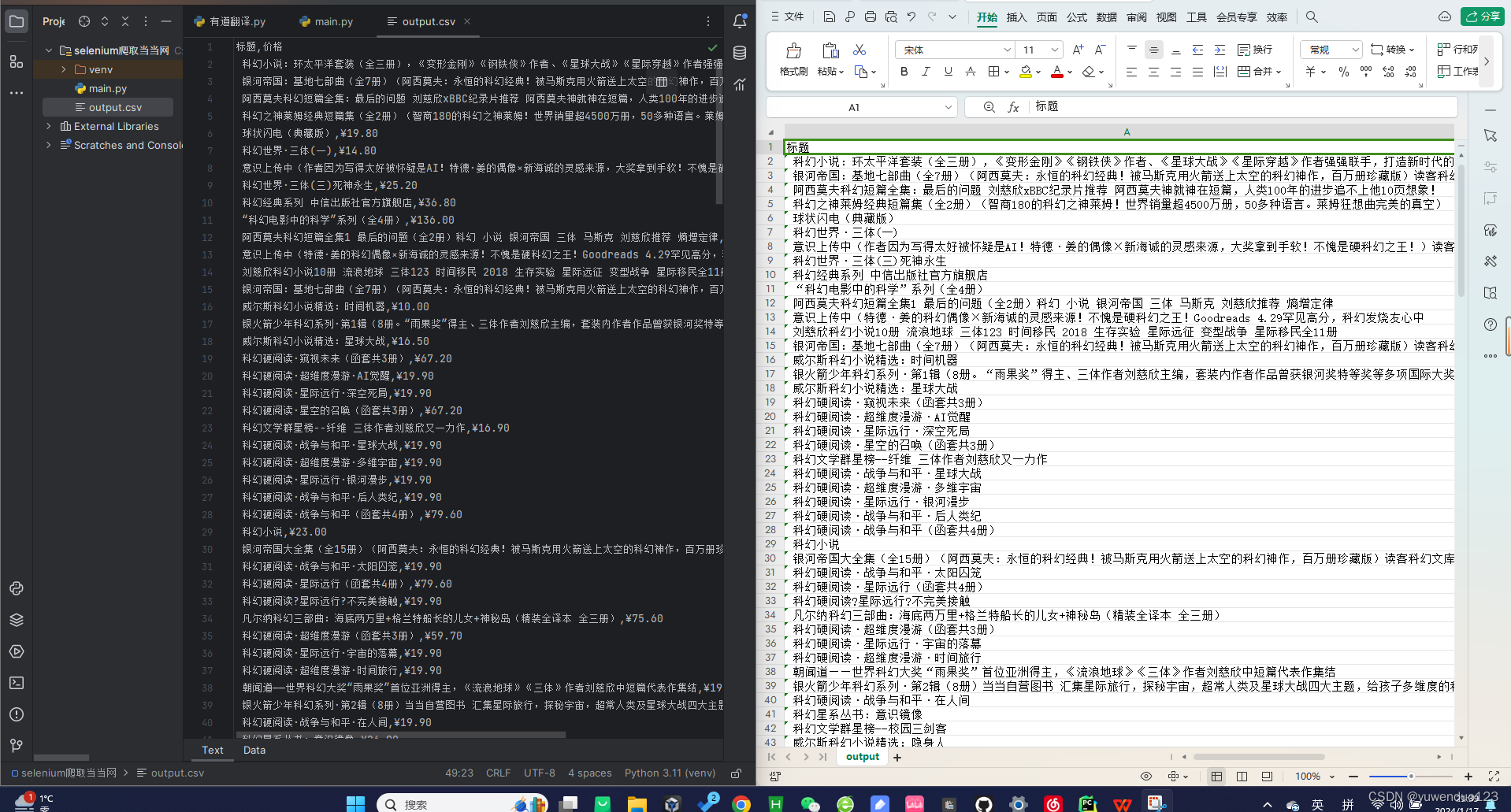
代码是最新的,在这一段时间内一定是可以运行的
如果有啥问题可以问我看到一定会回复大家,如果大家喜欢可以作者点赞和关注
大家的支持是我创作下去的最大动力!
这篇关于selenium爬虫爬取当当网书籍信息 | 最新!的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







