本文主要是介绍【Python从入门到进阶】49、当当网Scrapy项目实战(二),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
接上篇《48、当当网Scrapy项目实战(一)》
上一篇我们正式开启了一个Scrapy爬虫项目的实战,对当当网进行剖析和抓取。本篇我们继续编写该当当网的项目,讲解刚刚编写的Spider与item之间的关系,以及如何使用item,以及使用pipelines管道进行数据下载的操作。
一、使用item封装数据
在上一篇我们通过编写的爬虫文件,获取到当当网“一般管理类”书籍的第一页的明细列表信息。但是我们仅仅是将爬取到的目标信息print打印到控制台了,没有保存下来,这里我们就需要item先进行数据的封装。在“dang.py”爬虫文件里,我们获取到了目标数据,这些数据是我们之前通过item定义过这些数据的数据结构,但是没有使用过:
import scrapyclass ScrapyDangdang01Item(scrapy.Item):# 书籍图片src = scrapy.Field()# 书籍名称title = scrapy.Field()# 书籍作者search_book_author = scrapy.Field()# 书籍价格price = scrapy.Field()# 书籍简介detail = scrapy.Field()那么,我们如何使用item定义好的数据结构呢?我们在爬虫文件中,首先通过from引用上面的class的名称:
from scrapy_dangdang_01.items import ScrapyDangdang01Item注:可能编译器会报错,这是编译器版本的问题,不影响后面的执行,可以忽略。
导入完毕之后,我们创建一个book对象,这个对象就是把上面那些零散的信息全部都组装起来的集合体,然后在构造函数中,将所有抓取到的属性,挨个赋值到item文件中的各个属性中去:
book = ScrapyDangdang01Item(src=src, title=title, search_book_author=search_book_author, price=price, detail=detail)然后这个book对象,就要交给pipelines进行下载。
二、设置yield返回目标对象
这里我们需要使用到Python中的yield指令,它的作用如下:
yield是Python中的一个关键字,主要用于定义生成器(generator)。生成器是一种特殊的迭代器,可以逐个地生成并返回一系列的值,而不是一次性地生成所有的值。这可以节省大量的内存,尤其是在处理大量数据时。
yield的工作原理类似于return,但它不仅仅返回一个值,还可以保存生成器的状态,使得函数在下次调用时可以从上次离开的地方继续执行。
下面是一个简单的生成器函数的例子:def simple_generator(): n = 1 while n <= 5: yield n n += 1 for i in simple_generator(): print(i)在这个例子中,simple_generator 是一个生成器函数,它使用 yield 来生成一系列的数字。当我们对这个生成器进行迭代(例如,在 for 循环中)时,它会逐个生成数字 1 到 5,并打印出来。
所以我们这里使用yield是用来将上面for循环中的每一个book交给pipelines处理,循环一个处理一个。编写代码如下:
# 将数据封装到item对象中
book = ScrapyDangdang01Item(src=src, title=title, search_book_author=search_book_author, price=price, detail=detail)# 获取一个book对象,就将该对象交给pipelines
yield book此时for循环每执行一次,爬虫函数就会返回一个封装好的book对象。完整的爬虫文件代码如下(scrapy_dangdang_01/scrapy_dangdang_01/spiders/dang.py):
import scrapyfrom scrapy_dangdang_01.items import ScrapyDangdang01Itemclass DangSpider(scrapy.Spider):name = "dang"allowed_domains = ["category.dangdang.com"]start_urls = ["http://category.dangdang.com/cp01.22.01.00.00.00.html"]def parse(self, response):# 获取所有的图书列表对象li_list = response.xpath('//ul[@id="component_59"]/li')# 遍历li列表,获取每一个li元素的几个值for li in li_list:# 书籍图片src = li.xpath('.//img/@data-original').extract_first()# 第一张图片没有@data-original属性,所以会获取到控制,此时需要获取src属性值if src:src = srcelse:src = li.xpath('.//img/@src').extract_first()# 书籍名称title = li.xpath('.//img/@alt').extract_first()# 书籍作者search_book_author = li.xpath('./p[@class="search_book_author"]//span[1]//a[1]/@title').extract_first()# 书籍价格price = li.xpath('./p[@class="price"]//span[@class="search_now_price"]/text()').extract_first()# 书籍简介detail = li.xpath('./p[@class="detail"]/text()').extract_first()# print("======================")# print("【图片地址】", src)# print("【书籍标题】", title)# print("【书籍作者】", search_book_author)# print("【书籍价格】", price)# print("【书籍简介】", detail)# 将数据封装到item对象中book = ScrapyDangdang01Item(src=src, title=title, search_book_author=search_book_author, price=price, detail=detail)# 获取一个book对象,就将该对象交给pipelinesyield book三、编写pipelines保存数据至本地
首先我们进入setting.py中,设置“ITEM_PIPELINES”参数,在其中添加我们设置的pipelines管道文件的路径地址:
# 管道可以有很多个,前面是管道名后面是管道优先级,优先级的范围是1到1000,值越小优先级越高
ITEM_PIPELINES = {"scrapy_dangdang_01.pipelines.ScrapyDangdang01Pipeline": 300,
}此时我们进入pipelines.py中编写管道逻辑:
from itemadapter import ItemAdapter# 如果需要使用管道,要在setting.py中打开ITEM_PIPELINES参数
class ScrapyDangdang01Pipeline:# process_item函数中的item,就是爬虫文件yield的book对象def process_item(self, item, spider):# 这里写入文件需要用'a'追加模式,而不是'w'写入模式,因为写入模式会覆盖之前写的with open('book.json', 'a', encoding='utf-8') as fp:# write方法必须写一个字符串,而不能是其他的对象fp.write(str(item))return item此时我们执行爬虫函数,可以看到执行成功:
然后我们打开生成的book.json文件,“Ctrl+Alt+l”排版之后,可以看到我们爬取的数据已经生成了: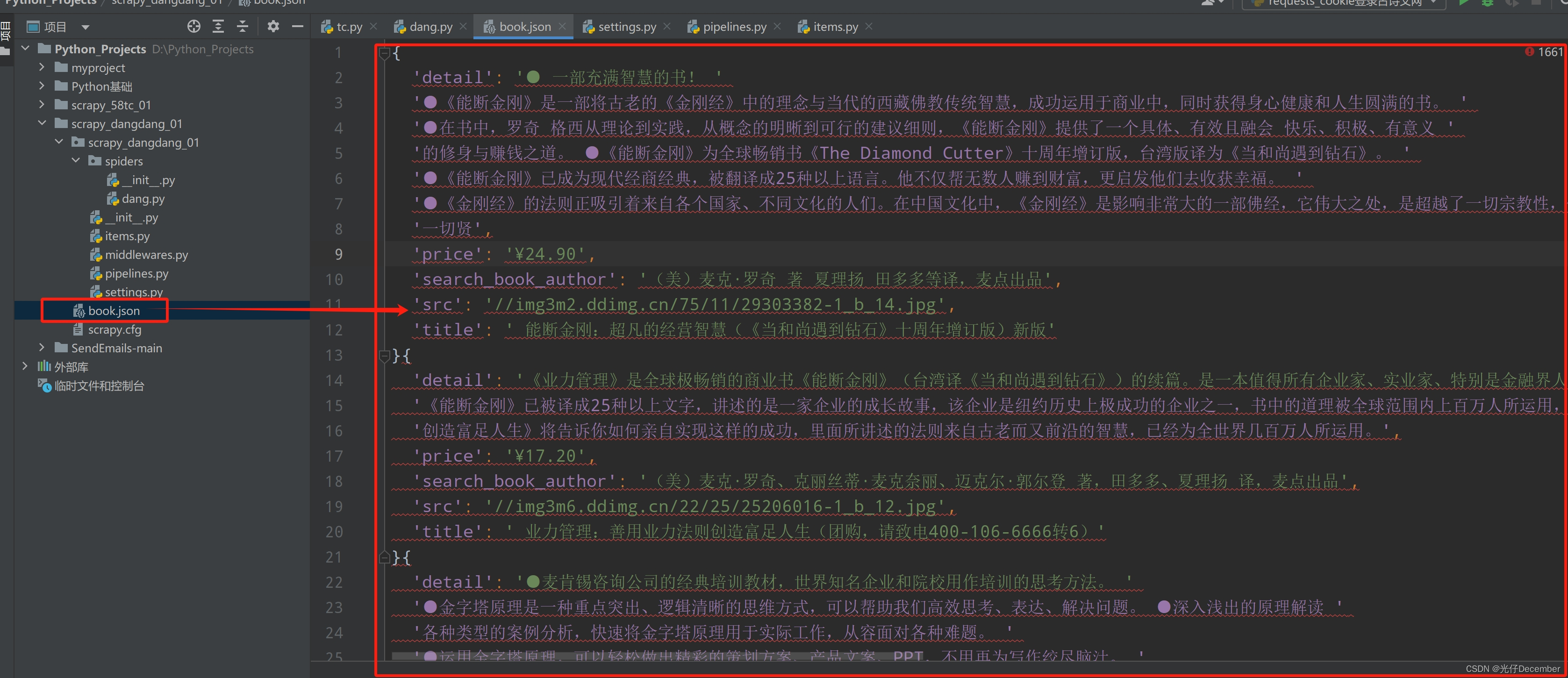
上面就是管道+爬虫+item的综合使用模式。
四、进行必要的优化
在上面的pipelines管道函数中,我们每一次获取到爬虫for循环yield的book对象时,都需要打开一次文件进行写入,比较耗费读写资源,对文件的操作过于频繁。
优化方案:在爬虫执行开始的时候就打开文件,爬虫执行结束之后再关闭文件。此时我们就需要了解pipelines的生命周期函数。分别为以下几个方法:
(1)open_spider(self, spider): 当爬虫开始时,这个方法会被调用。你可以在这里进行一些初始化的操作,比如打开文件、建立数据库连接等。
(2)close_spider(self, spider): 当爬虫结束时,这个方法会被调用。你可以在这里进行清理操作,比如关闭文件、断开数据库连接等。
(3)process_item(self, item, spider): 这是pipelines中最核心的方法。每个被抓取并返回的项目都会经过这个方法。你可以在这里对数据进行清洗、验证、转换等操作。这个方法必须返回一个项目(可以是原项目,也可以是经过处理的新项目),或者抛出一个DropItem异常,表示该项目不应被进一步处理。
此时我们就可以使用open_spider定义爬虫开始时打开文件,close_spider定义爬虫结束时关闭文件,而在爬虫运行期间的process_item方法中,只进行写的操作,完整代码如下:
from itemadapter import ItemAdapter
import json# 如果需要使用管道,要在setting.py中打开ITEM_PIPELINES参数
class ScrapyDangdang01Pipeline:# 1、在爬虫文件开始执行前执行的方法def open_spider(self,spider):print('++++++++爬虫开始++++++++')# 这里写入文件需要用'a'追加模式,而不是'w'写入模式,因为写入模式会覆盖之前写的self.fp = open('book.json', 'a', encoding='utf-8') # 打开文件写入# 2、爬虫文件执行时,返回数据时执行的方法# process_item函数中的item,就是爬虫文件yield的book对象def process_item(self, item, spider):# write方法必须写一个字符串,而不能是其他的对象self.fp.write(str(item)) # 将爬取信息写入文件return item# 在爬虫文件开始执行后执行的方法def close_spider(self, spider):print('++++++++爬虫结束++++++++')self.fp.close() # 关闭文件写入这样就能解决对文件操作频繁,耗费读写资源的问题了。
五、多管道的支持
pipelines支持设置多个管道,例如我们在原来的pipelines.py中再定义一个管道class类,用来下载每一个图书的图片:
# 下载爬取到的book对象中的图片文件
class ScrapyDangdangImagesPipeline:def process_item(self, item, spider):# 获取book的src属性,并按照地址下载图片,保存值books文件夹下url = 'http:' + item.get('src')filename = './books/' + item.get('title') + '.jpg'# 检查并创建目录if not os.path.exists('./books/'):os.makedirs('./books/')urllib.request.urlretrieve(url=url, filename=filename)return item然后我们在setting.py中的ITEM_PIPELINES参数中追加这个管道:
# 管道可以有很多个,前面是管道名后面是管道优先级,优先级的范围是1到1000,值越小优先级越高
ITEM_PIPELINES = {"scrapy_dangdang_01.pipelines.ScrapyDangdang01Pipeline": 300,"scrapy_dangdang_01.pipelines.ScrapyDangdangImagesPipeline": 301
}运行爬虫文件,可以看到相关的图片已经全部下载下来: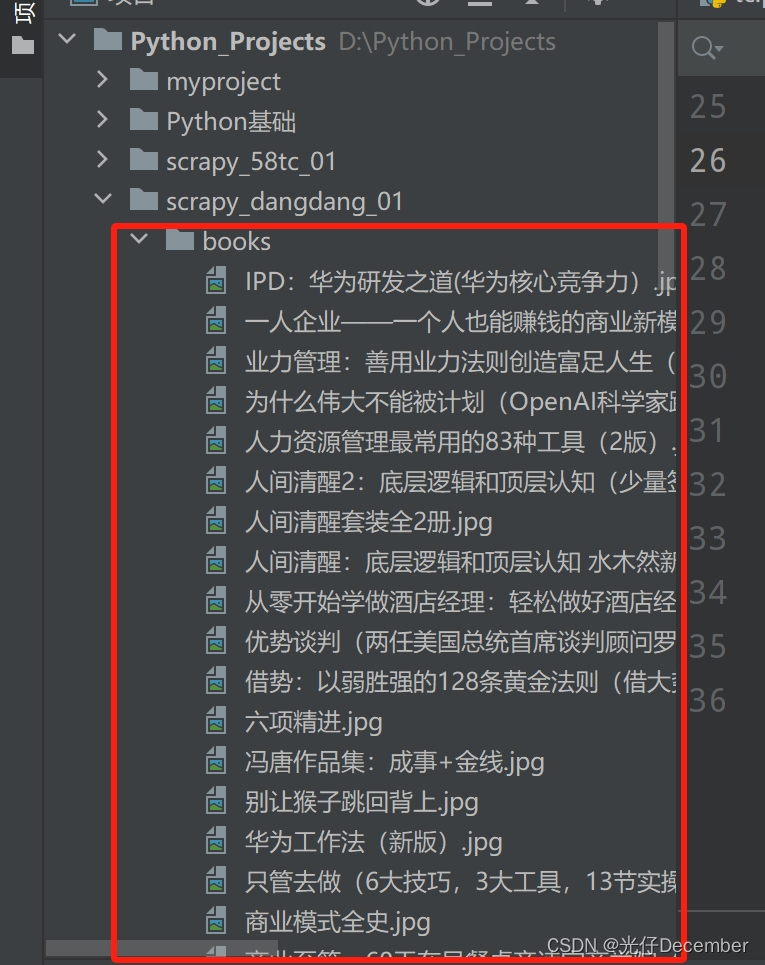
并且都是可以打开的图片: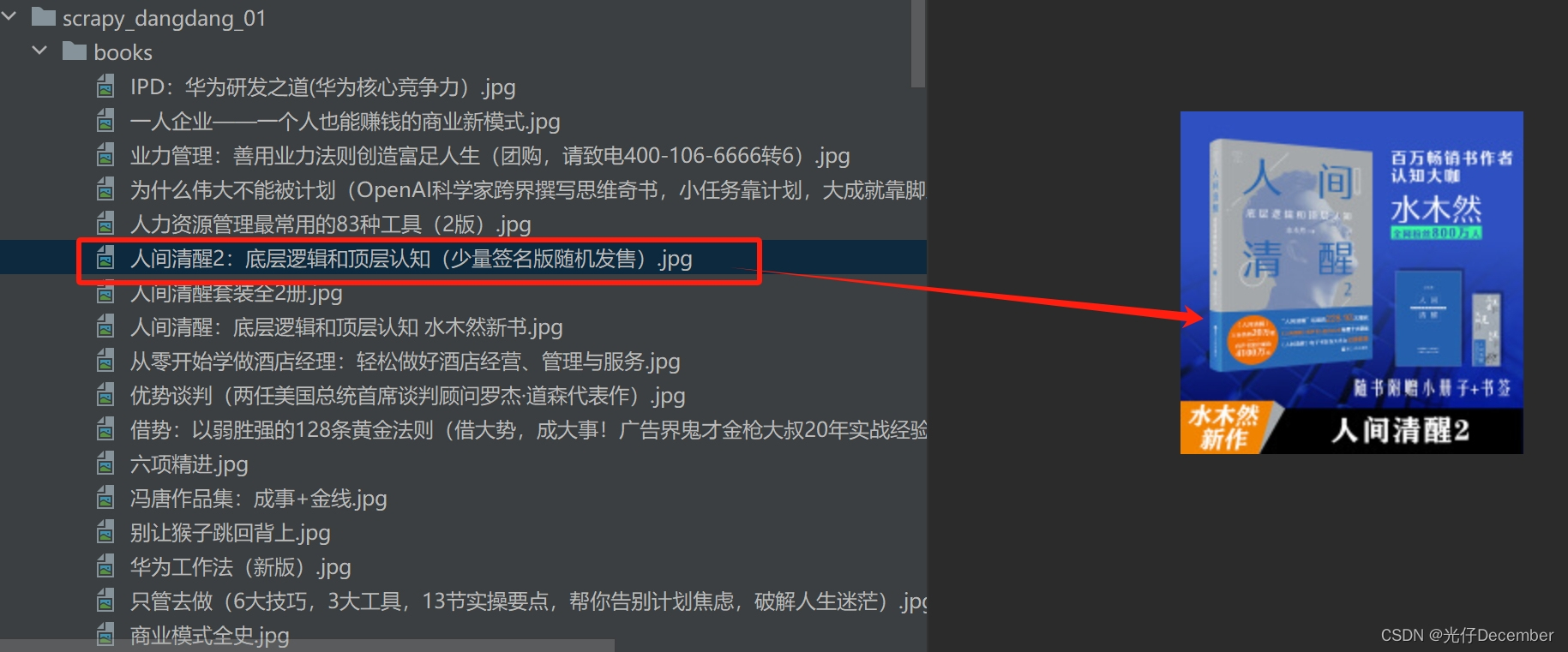
至此管道+爬虫+item的综合使用模式讲解完毕。下一篇我们来讲解Scrapy的多页面下载如何实现。
参考:尚硅谷Python爬虫教程小白零基础速通
转载请注明出处:https://guangzai.blog.csdn.net/article/details/136283532
这篇关于【Python从入门到进阶】49、当当网Scrapy项目实战(二)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





