均值专题

KEYSIGHT U2020 X系列 USB峰值和均值功率传感器
_是德(KEYSIGHT) _ U2020 X系列 USB峰值和均值功率传感器 苏州新利通仪器仪表 U2020 X 系列功率传感器得到 Keysight BenchVue 软件的支持。使用 BenchVue 软件,您无需编程便可轻松控制功率计记录数据,并以各种形式显示测量结果。 只需将传感器连接至安装了 BenchVue BV0007B 功率计/传感器控制与分析软件的计算

均值滤波器的原理及实现
1.均值滤波器 平滑线性空间滤波器的输出是包含在滤波器模板邻域内的像素的简单平均值,也就是均值滤波器。均值滤波器也是低通滤波器,均值滤波器很容易理解,即把邻域内的平均值赋给中心元素。 均值滤波器用来降低噪声,均值滤波器的主要应用是去除图像中的不相关细节,不相关是指与滤波器的模板相比较小的像素区域。模糊图片以便得到感兴趣物体的粗略描述,因此那些较小的物体的灰度就会与背景混合在一起,较大的物体则变

基于Python的机器学习系列(20):Mini-Batch K均值聚类
简介 K均值聚类(K-Means Clustering)是一种经典的无监督学习算法,但在处理大规模数据集时,计算成本较高。为了解决这一问题,Mini-Batch K均值聚类应运而生。Mini-Batch K均值聚类通过使用数据的子集(mini-batch)来更新簇中心,从而减少了计算量,加快了处理速度。 Mini-Batch K均值算法 Mini-Batch

机器学习一:k均值算法用processing实现
代码仅供参考,请勿抄袭。转载请注明出处。class Point{float x , y;int k;Point(float x1,float y1){x=x1;y=y1;}}class Type{int k;int num=0;float x_old , y_old;float x_new , y_new;int r = 0 , g = 0 , b = 0;}int num = 500

基于Python的机器学习系列(19):K均值聚类(K-Means Clustering)
简介 K均值聚类(K-Means Clustering)是一种常用的无监督学习算法,用于将数据样本划分为若干个“簇”,使得同一簇内的数据点彼此相似,而不同簇的数据点之间差异较大。由于K均值不依赖于标签,因此它是一种无监督学习方法。常见的应用包括客户细分、图像分割和数据可视化等。 K均值算法 K均值算法的基本步骤如下: 定义簇的数量 k(需手动设定)。初始化簇的质心,这些质心
fpga图像处理实战-均值滤波
均值滤波 均值滤波是一种简单的图像处理技术,主要用于平滑图像,去除噪声。它通过用当前像素邻域的平均值代替该像素值,从而实现图像的平滑处理。这种滤波器在图像处理中被广泛用于减少图像中的随机噪声。 算法原理 均值滤波的基本思想是使用一个固定大小的滑动窗口(通常为方形,如 3x3 或 5x5 窗口),逐个遍历图像中的每个像素点。对于每个像素点,计算其邻域像素值的平均
模糊C均值聚类算法及实现
模糊C均值聚类算法的实现 研究背景 https://blog.csdn.net/liu_xiao_cheng/article/details/50471981 聚类分析是多元统计分析的一种,也是无监督模式识别的一个重要分支,在模式分类 图像处理和模糊规则处理等众多领域中获得最广泛的应用。它把一个没有类别标记的样本按照某种准则划分为若干子集,使相似的样本尽可能归于一类,而把不相似的样本划

均值漂移算法原理及Python实践
均值漂移算法(Mean Shift Algorithm)是一种基于密度的非参数聚类算法,其原理主要基于核密度估计和梯度上升方法。以下是均值漂移算法原理的详细解析: 1. 基本思想 均值漂移算法的基本思想是通过迭代地更新数据点的位置,使得数据点向密度较高的区域移动,最终聚集成簇。算法假设不同簇类的数据集符合不同的概率密度分布,目标是找到任一样本点密度增大的最快方向(即Mean Shift方向),

matlab-----均值滤波函数的实现
均值滤波的原理是对图像以一个区域(方形,圆形)等为模板,对该区域内的数据求平均后赋值给区域的中心 这种滤波方式原理简单,但是在滤波的同时会造成图像模糊。 本文将尝试对matlab中的filter2()均值函数用自定义函数averfilter()实现。 </pre><pre name="code" class="plain">%x是需要滤波的图像,n是模板大小(即n×n

python画图高斯平滑均值曲线
注:细线是具体值,粗线是高斯平滑处理后的均值曲线 #coding=gbkimport matplotlib.pyplot as pltimport numpy as npfrom scipy.ndimage import gaussian_filter1d# 生成一些示例数据np.random.seed(0)timesteps = np.linspace(1000, 0, 1000

量化交易策略的实现_均值回归策略
一:均值回归策略的理解 均值回归策略是一种基于金融资产价格会围绕其长期均值波动的交易方法。这种策略认为,资产价格在短期内可能会偏离其均值,但最终会回归到均值附近。交易者可以通过识别这种偏离并采取相反方向的交易来捕捉利润。 均值回归策略的基本原理是资产价格将围绕其历史均值进行波动,当价格偏离其长期平均水平时,价格趋向于回归到其平均水平,价格的偏离程度越大,回归的力度越大。因此,可以通过采取反向交

sparkdataframe 对多列进行先filter后求均值
import org.apache.spark.sql.{Column, DataFrame, Dataset, Row, SparkSession} spark dataframe 对多列进行先filter后求均值 meanDf = df.select(df.columns.map(k=>mean(when(col(k)>0, col(k))).alias(k+“mean”)): _*) sp

聚类算法(1)---最大最小距离、C-均值算法
本篇文章是博主在人工智能等领域学习时,用于个人学习、研究或者欣赏使用,并基于博主对人工智能等领域的一些理解而记录的学习摘录和笔记,若有不当和侵权之处,指出后将会立即改正,还望谅解。文章分类在AI学习笔记: AI学习笔记(7)---《聚类算法(1)---最大最小距离、C-均值算法》 聚类算法(1)---最大最小距离、C-均值算法 目录 一、聚类算法背景知识
什么叫图像的均值滤波,并附利用OpenCV和MATLB实现均值滤波的代码
均值滤波是一种常见的图像处理技术,主要用于平滑图像、去除噪声。它通过计算图像中每个像素及其邻域像素的平均值来实现。具体过程如下: 定义滤波器窗口:选择一个窗口(通常是一个正方形或矩形,比如 3×3或 5×5 的大小)。这个窗口在图像上滑动,逐个像素点进行处理。 计算均值:对于窗口中心的每个像素,计算窗口内所有像素的灰度值或颜色值的平均值。 替换像素值:用计算得到的均值替换窗口中心的像素值。

机器学习笔记——无监督学习下的k均值聚类
k均值聚类算法原理 目标是将样本分类 原理:首先随机选择k何点作为中心,然后计算每一个点到中心的聚类,然后计算到每个中心的距离,选择到中心最短距离的那个中心所在的类进行归类,然后更新中心点,一直重复。 主成分分析分析的原理 主要是实现降为,选择重要的成分 贝叶斯网络 由依赖关系构成的有向图,称为贝叶斯网络。也叫信念网络 尾对尾 头对头 头对尾 朴素贝叶斯 贝叶斯公式何贝
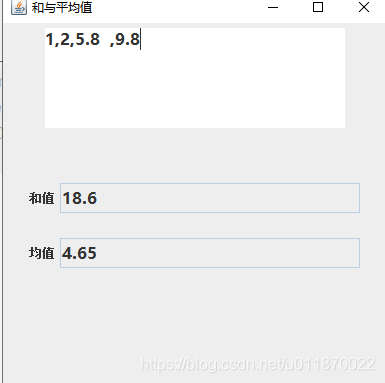
使用swing实现求和以及均值(有按钮和无按钮两份代码以及详细注释)——Java语言程序设计
Java语言程序设计–实验2:文本框、文本区和布局的设计(有按钮和无按钮以及详细注释菜鸟都能看得懂) 目的: 通过编写一个Java GUI应用程序,进一步熟悉Java GUI应用程序的结构和开发过程;熟悉窗口、组件的创建、布局管理器的使用以及事件处理机制。 题目: 根据教材关于Java GUI的介绍,编写一个具有如上基本布局的应用程序,要求当在上面的文本区中输入若干数后(输入的多个数据之间以逗

Python, Numpy求 list 数组均值,方差,标准差
代码如下: import numpy as np array = [1,3,5,7,9]# 求均值arr_mean = np.mean(array)# 求方差arr_var = np.var(array)# 求标准差arr_std = np.std(array,ddof=1)
图像处理:均值滤波器的应用——去除不相关细节
均值滤波器的常见应用是平滑处理降低噪声,但是由于图像希望保留的边缘也是由图像灰度尖锐变化带来的特性, 均值滤波器会模糊边缘,所以平滑的效果有一定的缺陷。 均值滤波的主要应用:去除图像中的不相关细节,其中“不相关”是指与滤波器模板尺寸相比较小的像素区域,从而 对图像有一个整体的认知。即为了对感兴趣的物体得到一个大致的整体的描述而模糊一幅图像,忽略细小的细节。 忽略细节从整体上认识

模式识别十--k-均值聚类算法的研究与实现
文章转自:http://www.kancloud.cn/digest/prandmethod/102852 本实验的目的是学习和掌握k-均值聚类算法。k-均值算法是一种经典的无监督聚类和学习算法,它属于迭代优化算法的范畴。本实验在MATLAB平台上,编程实现了k-均值聚类算法,并使用20组三维数据进行测试,比较分类结果。实验中初始聚类中心由人为设定,以便于实验结果的比较与分析。 一、技术论述

《python程序语言设计》2018版第5章第46题均值和标准方差-下部(本来想和大家说抱歉,但成功了)
接上回,5.46题如何的标准方差 本来想和大家说非常抱歉各位同学们。我没有找到通过一个循环完成两个结果的代码。 但我逐步往下的写,我终于成功了!! 这是我大前天在单位找到的公式里。x上面带一横是平均值。 我不能用函数的办法封装循环。所以我只能从循环里找办法。可是 我建立 了第一个循环 step_num = 0num_c = 0pow_c = 0while step_num <
PCL 点云均值平滑
文章目录 一、简介二、实现代码三、实现代码参考资料 一、简介 这个思路与二维图像的均值滤波很是类似,在一些论文中有学者使用这种方法实现对点云的简单平滑处理,以方便后续的计算。具体的计算过程也很简单:即遍历每个点,并基于每个点的邻域,计算其邻域点集的质心,以此来生成新的平滑点云数据。 二、实现代码 // 标准文件#include <iostream>// PCL#in
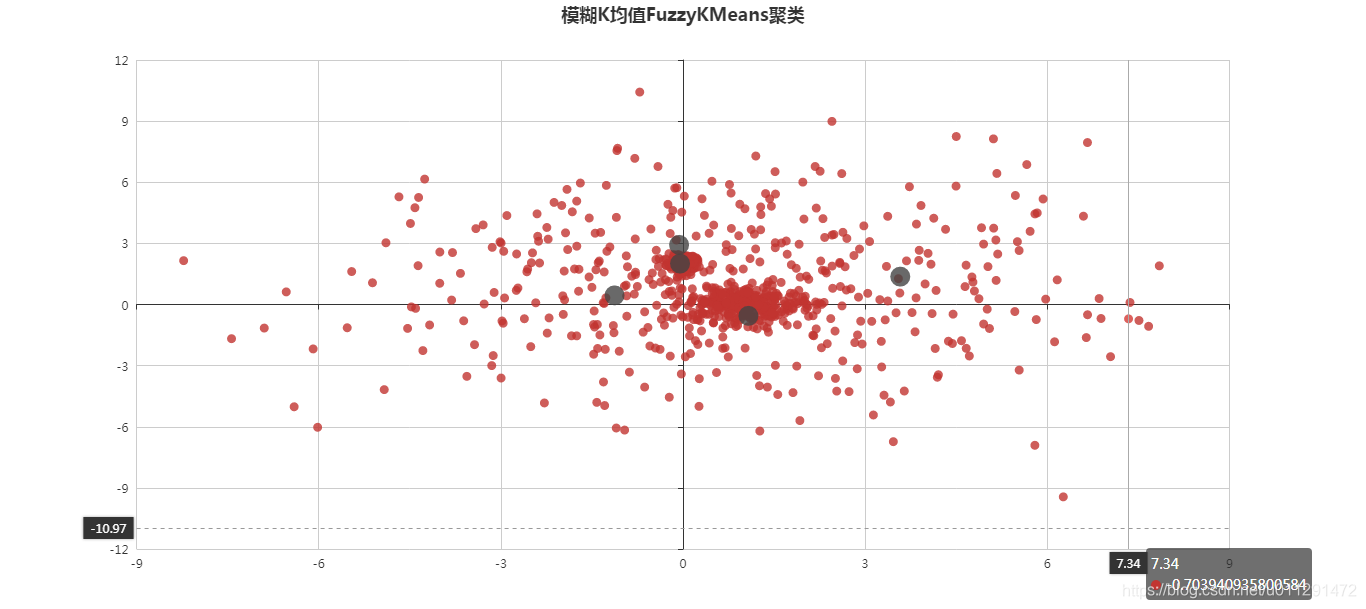
基于模糊K均值FuzzyKMeans聚类的协同过滤推荐算法代码实现(输出聚类计算过程,分布图展示)
基于模糊K均值FuzzyKMeans聚类的协同过滤推荐算法代码实现(输出聚类计算过程,分布图展示) 聚类(Clustering)就是将数据对象分组成为多个类或者簇 (Cluster),它的目标是:在同一个簇中的对象之间具有较高的相似度,而不同簇中的对象差别较大。所以,在很多应用中,一个簇中的数据对象可以被作为一个整体来对待,从而减少计算量或者提高计算质量。 一、FuzzyKMeans聚类算法实
使用均值算法解决温度校准问题
一、问题 温度(整形)校准深度数据,由于输入的温度是底层读取的芯片温度,波动在1-2度之间,41,42,43,41这种。导致计算出来的深度数据差距多大,画面看到深度在跳动。 二、解决办法 温度校准的温度数据一定要稳定,不能波动过大。通过计算前面9个温度+当前1个温度的平均值作为温度校准的输入温度,并将温度改为浮点类型,这样的话,输入的温度波动就小很多了,画
【Python】使用 Pandas 进行均值填充:处理缺失数据的实用指南
缘分让我们相遇乱世以外 命运却要我们危难中相爱 也许未来遥远在光年之外 我愿守候未知里为你等待 我没想到为了你我能疯狂到 山崩海啸没有你根本不想逃 我的大脑为了你已经疯狂到 脉搏心跳没有你根本不重要 🎵 邓紫棋《光年之外》 在数据分析和处理过程中,缺失数据(NaN 值)是一个常见的问题。缺失数据可能会导致错误的分析结果或模型预测。在 Panda
从零开始学统计 03 | 均值,方差,标准差
一、均值 现在,假设已经拿到在实际的肝脏中大约 2400 亿个细胞的X基因表达值。 我们接下来,要计算总体均值与估计总体均值。 现在使用实际的2400亿个细胞计算均值,也就是总体均值(Population Mean) 从总体中抽样 5 个样本,计算估计均值(Estimated Mean): 统计学中,用符号x-bar () 来表示估计均值,也叫样本均值(Sample Mea