本文主要是介绍机器学习笔记——无监督学习下的k均值聚类,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
k均值聚类算法原理
目标是将样本分类
原理:首先随机选择k何点作为中心,然后计算每一个点到中心的聚类,然后计算到每个中心的距离,选择到中心最短距离的那个中心所在的类进行归类,然后更新中心点,一直重复。
主成分分析分析的原理
主要是实现降为,选择重要的成分
贝叶斯网络
由依赖关系构成的有向图,称为贝叶斯网络。也叫信念网络
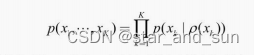
尾对尾


头对头
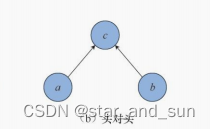

头对尾


朴素贝叶斯
贝叶斯公式何贝叶斯网络模型的简单运用。只使用条件独立的假设何计数方法,统计变量的先验分布,再有贝叶斯反推参数的后验分布。同时假设每个样本类别y何特征变量x相互独立。
基于朴素贝叶斯 新闻分类任务的实现

马尔可夫网络
变量和变量之间的关联是双向的
这篇关于机器学习笔记——无监督学习下的k均值聚类的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









