分词器专题

【docker】基于docker-compose 安装elasticsearch + kibana + ik分词器(8.10.4版本)
记录下,使用 docker-compose 安装 Elasticsearch 和 Kibana,并配置 IK 分词器,你可以按照以下步骤进行。此过程适用于 Elasticsearch 和 Kibana 8.10.4 版本。 安装 首先,在你的工作目录下创建一个 docker-compose.yml 文件,用于配置 Elasticsearch 和 Kibana 的服务。 version:

elasticsearch 2.3.4 java API 连接,ik分词器,设置集群节点,创建index,mapping的几种方式
1、默认集群连接 Client client = TransportClient.builder().build().addTransportAddress(new InetSocketTransportAddress(InetAddress.getByName("localhost"), 9300)); 2、自定义集群连接 Settings settings = S

重生之我们在ES顶端相遇第11 章 - 深入自定义语言分词器
文章目录 0. 前言1. 英语分词器2. 阿拉伯语分词器3. 结语 0. 前言 国内企业出海是大势所趋,那么基于不同的语种进行分词就显得尤为重要,因为这会让用户的搜索体验更棒! 国内出海企业,会更偏向于选择欧美、中东这 2 个地区。 因此本文章也重点介绍英语、阿拉伯语的分词。 在 ES 中内置的分词器中,有一个叫 Language analyzers,我们可以根据该分词

重生之我们在ES顶端相遇第10 章- 分分分词器的基本使用
文章目录 思维导图0. 前言1. 光速上手1.1 指定分词器1.2 测试分词器 2. 分词流程(重要)2.1 基本介绍2.2 深入如何测试分词器 3. 自定义一个简单的分词器 思维导图 0. 前言 分词器在 ES 搜索使用中非常关键,一个好的分词器能够提高搜索的质量,让用户搜索到其想要的内容。 下面我将带大家从整体了解分词器。 1. 光速上手 1.1 指定分词器

【Python机器学习】NLP分词——利用分词器构建词汇表(四)——标点符号的处理
目录 正则表达式的工作机理 改进的用于分词的正则表达式 缩略语 某些情况下,除空格外还有一些字符用于将句子中的词分隔开,比如之前case中“26.”末尾的句号(英文)。分词器不仅可以利用空格还可以基于标点符号(如逗号、句号、分号、连字符等)将句子切开。在某些情况下,我们希望这些标点符号也像词一样,被看成独立的词条,但另一些情况下可能又要忽略这些标点符号。 在“26.”的例子中,由

【Python机器学习】NLP分词——利用分词器构建词汇表(六)——词汇表归一化
目录 大小写转换 词干还原 词形归并 使用场景 词汇表大小对NLP流水线的性能有很大的影响,有一种减少词汇表大小的方法是将词汇表归一化以便意义相似的词条归并成单个归一化的形式。这样做一方面可以减少需要再词汇表中保留的词条数,另一方面也会提高语料库中意义相似但是拼写不同的词条或者n-gram之间的语义关联。 大小写转换 当两个单词只有大小写形式不同时,大小写转换会用来把笔不同的

【Python机器学习】NLP分词——利用分词器构建词汇表(三)——度量词袋之间的重合度
如果能够度量两个向量词袋之间的重合度,就可以很好地估计他们所用词的相似程度,而这也是它们语义上重合度的一个很好的估计。因此,下面用点积来估计一些新句子和原始的Jefferson句子之间的词袋向量重合度: import pandas as pdsentence="""Thomas Jefferson Began buliding Monticelli as the age of 26.\n""
采用ELK搭建日志平台,安装elasticsearch中文分词器
1、进入ES安装目录下 cd /usr/local/elasticsearch7.17 2、安装 ./bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.17.7/elasticsearch-analysis-ik-7.17.7.zip

docker安装ES(Elasticsearch)的IK分词器
大家可以先看我的Docker中部署Kibana: “Docker中部署Kibana:步骤与指南“-CSDN博客 其实这几篇博文都是有关系的,希望大家学有所成。 问题:命令中有一个unzip没有安装,需要先安装一下,安装命令: yum install unzip 1.打开目录: cd /usr/local/docker/es/plugins/ 2.创建ik文件夹

【Python机器学习】NLP分词——利用分词器构建词汇表(二)——点积
在自然语言处理中将会有多处用到点积,点积也被称为内积,这是因为两个向量(每个向量中的元素个数)或矩阵(第一个矩阵的行数和第二个矩阵的列数)的“内部”维度必须一样,这种情况下才能相乘。这个关系数据库表的内连接操作很相似。 点击也被称为标积,因为其输出结果是个单独的标量值。这使其有别于叉积这个概念,后者的输出结果是一个向量。显然,这些名称体现了标识符的形状,在正式数学符号当中,标积用“”表示,叉积用

elasticsearch 安装 ik中文分词器
1,下载ik分词器,根据自己es的版本下载对应的版本 下载地址: https://github.com/medcl/elasticsearch-analysis-ik 我这里是使用的6.2.1版本,直接下载就可以了 wget https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v6.2.1/elasticse

ElasticSearch ik分词器的安装使用
目录 一、下载二、解压三、拷贝插件目录四、重启ES 一、下载 下载链接:https://github.com/medcl/elasticsearch-analysis-ik,选择与自己 es 版本对应的 ik 版本下载: 我下载的版本是 7.15.2,https://github.com/medcl/elasticsearch-analysis-ik/releases/ta

ES升级--03-- IK分词器
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 IK分词器1. IK分词器 下载https://github.com/infinilabs/analysis-ik/releases 2. 创建文件夹 analysis-ik3.把zip包放至该目录下 解压4. 删除zip包5、重启Elasticsearch, 观察日志 使用kibana测试1、细粒度的拆分

ElasticSearch安装中文分词器IK
1、安装IK分词器,下载对应版本的插件,elasticsearch-analysis-ik中文分词器的开发者一直进行维护的,对应着elasticsearch的版本,所以选择好自己的版本即可。IKAnalyzer中文分词器原作者已经不进行维护了,但是Lucece在不断更新,所以使用Lucece和IKAnalyzer中文分词器集成,需要你进行修改IKAnalyzer中文分词器。 下载地址:https
lucenenbsp;排序、过滤、分词器
1. 排序 1.1. Sort类 public Sort() public Sort(String field) public Sort(String field,Boolean reverse) //默认为false,降序排序 public Sort(String[] fields) public Sort(SortField field) public Sor
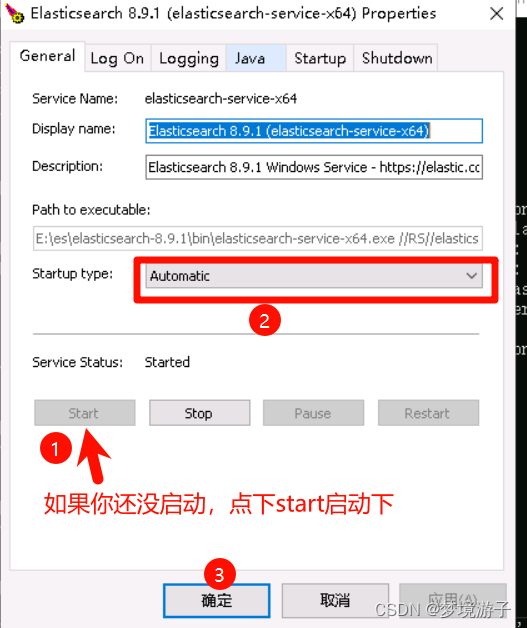
【ElasticSearch】windows server 2019安装ES8.9.1 + kibana8.9.1 + IK分词器
目录 准备工作 ES Kibana IK 安装 es es访问测试 将es安装为系统服务 Kibana 配置es 运行kibana 访问测试 IK 补充 准备工作 ES8.9.1 + kibana8.9.1 + IK的版本最好要对应上!!! ES es8.9.1: https://artifacts.elastic.co/downloa

Elasticsearch分析器与分词器:定制文本处理流程
Elasticsearch分析器与分词器:定制文本处理流程 在Elasticsearch中,文本搜索和处理是核心功能之一。为了优化搜索效率和准确性,Elasticsearch提供了丰富的分析器(Analyzer)和分词器(Tokenizer)来定制文本处理流程。本文将介绍分析器和分词器的基本概念,并探讨如何定制文本处理流程以满足特定的需求。 一、分析器与分词器的基本概念 在Elasticse

Mac 使用Docker安装Elasticsearch、Kibana 、ik分词器、head
安装ElasticSearch 通过docker安装es docker pull elasticsearch:7.8.1 在本地创建elasticsearch.yml文件 mkdir /Users/ky/Documents/learn/es/elasticsearch.yml 编辑yml文件内容 http: host: 0.0.0.0xpack.security.enab

Centos7.6使用docker部署elasticsearch6.8.6 + kibana6.8.6 + ik分词器
Centos7.6使用docker部署elasticsearch6.8.6 + kibana6.8.6 + ik分词器 创建单个节点文件夹,mkdir /home/es/single single目录下包括config data plugins 三个文件夹 在single目录下创建config文件夹,再创建elasticsearch.yml写入配置 echo “network.host:

IK分词器基础安装入门
安装 进入到elasticsearch的安装目录下, 找到bin目录。 执行里面的elasticsearch-plugin 命令,这个命令是管理es中的插件的。 ik分词器就是一个插件。 执行下面这个命令就可以安装成了, 注意IK分词器的版本要和es的版本一致才行。 具体哪个版本可以去github中去找。 bin/elasticsearch-plugin install https://gi
“庖丁解牛” 分词器实现
import java.io.IOException;import java.io.StringReader;import net.paoding.analysis.analyzer.PaodingAnalyzer;import org.apache.lucene.analysis.Analyzer;import org.apache.lucene.analysis.Token;import

【Elasticsearch】IK分词器的下载及使用
安装IK分词器 网址:https://github.com/infinilabs/analysis-ik 3.1.在线安装ik插件(较慢,不推荐) # 进入容器内部 es为容器名称docker exec -it es /bin/bash# 在线下载并安装 7.17.21为镜像版本要与之前保持一致./bin/elasticsearch-plugin install https://g
【Solr6.6.0】Solr对IK分词器的配置、Solr自动生成唯一ID、Solr服务器的增量和全量更新(五)
版权声明:本文为博主原创文章,未经博主允许不得转载。 转载请标明出处:http://blog.csdn.net/u011035026/article/details/79568628
es之ik分词器插件的安装和使用
ik 分词器安装 # 进入 es 集群的 es1 节点容器内部docker exec -it es1 bashcd /usr/share/elasticsearch# 执行安装命令, 请安装 ES 对应版本的分词器, https://github.com/medcl/elasticsearch-analysis-ik/releases# 注意 ik 的版本要与 es 的版本对应上./bin/e