下游专题

在下游市场需求带动下 我国聚天门冬氨酸脂防腐涂料市场规模不断扩大
在下游市场需求带动下 我国聚天门冬氨酸脂防腐涂料市场规模不断扩大 聚天门冬氨酸酯防腐涂料又称为天冬聚脲防腐涂料,是以聚天门冬氨酸酯作为主体树脂、脂肪族异氰酸酯为固化剂而形成的一种防腐涂料。与其他类型的防腐涂料相比,聚天门冬氨酸酯防腐涂料具有耐紫外线、耐磨、固化速度快、保光保色能力优异、防腐效果好等优点。 目前,我国聚天门冬氨酸酯防腐涂料的产业链已经形成。产业链上游主要为原材料行业,提

SiC晶圆市场步入价格调整期:技术革新与产能扩张共促成本降低,加速下游应用拓展
近期硅碳(SiC)晶圆市场传出了降价的风声,似乎一场价格战即将拉开序幕。那么,当前SiC晶圆市场的实际情况如何呢? 供应链中多数企业普遍认同SiC晶圆价格确实在下滑。环球晶圆董事长徐秀兰公开表示,全球6英寸SiC晶圆产能的释放,加上电动车需求暂时减缓,使得2024年SiC晶圆价格面临下行压力。而另一方面,SiC晶圆制造商三安集成在5月9日的投资者关系报告中指出了价格下降的两大内部原因:技术创新和

计算机视觉中,什么是上游任务、下游任务和pretext task?
在机器学习和深度学习的语境中,尤其是当涉及到预训练模型时,我们经常听到“上游任务”和“下游任务”这两个术语。 上游任务通常指的是模型在大量无标签或有标签的数据上进行预训练的任务,其目标是让模型学习到数据的内在规律和特征表示。 下游任务则是指模型在特定的、具体的应用场景中进行微调或训练的任务,这些任务通常与实际应用需求密切相关。 pretext task是指在进行主要任务(如目标检测、图像分割
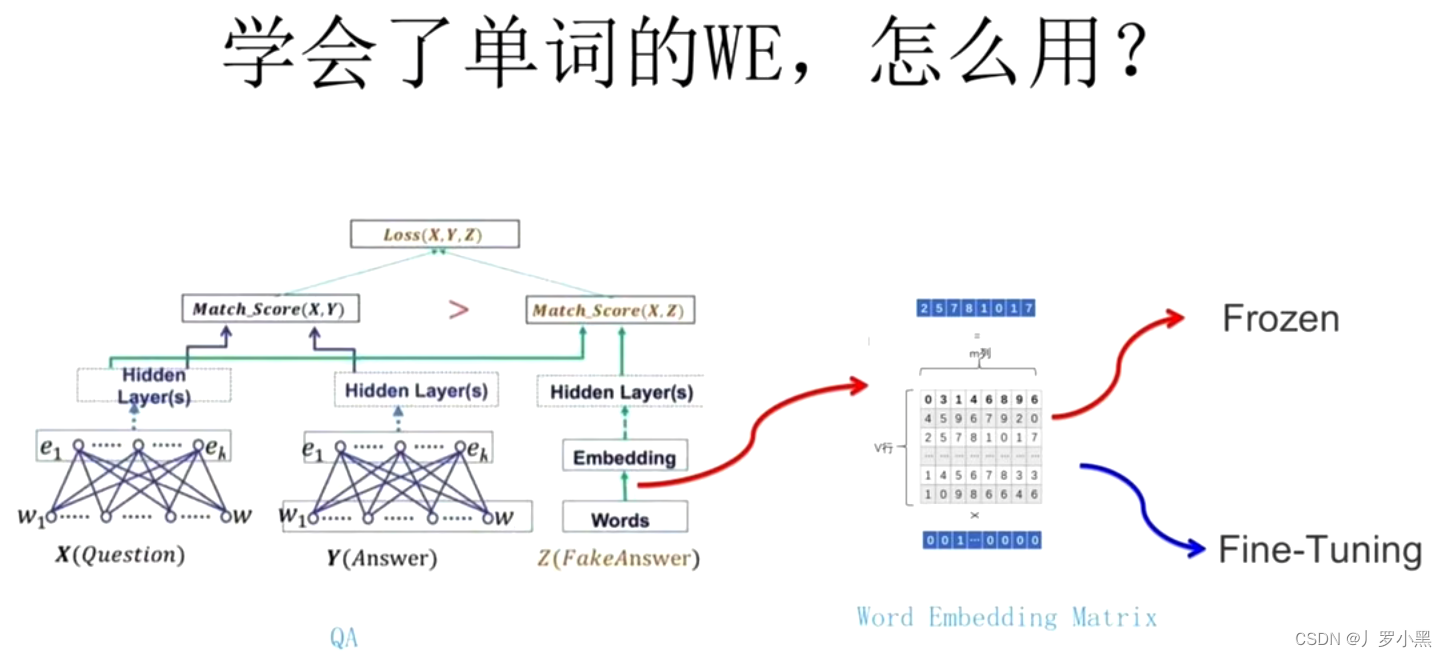
Transformer的前世今生 day03(Word2Vec、如何使用在下游任务中)
前情回顾 由上一节,我们可以得到: 任何一个独热编码的词都可以通过Q矩阵得到一个词向量,而词向量有两个优点: 可以改变输入的维度(原来是很大的独热编码,但是我们经过一个Q矩阵后,维度就可以控制了)相似词之间的词向量有了关系 但是,在NNLM(神经网络语言模型的一种)中,词向量是一个副产品,即主要目的并不是生成词向量,而是去预测下一个词是什么,所以它对预测的精度要求很高,模型就会很复杂,也就不容

下游job获得上游构建的war包
小白的傻瓜教程,有错请指出~~转载请注明 出处,谢谢~~~ 以前使用Jenkins进行持续集成是把构建和部署放在同一个job了,但原则上是每个job只做一个步骤,所以我在使用Jenkins的pipeline功能后,就分成了构建和部署两个job。 以前直接在同一个job的工作目录下就可以获得war部署到服务器上,现在遇到的问题是怎样从上游的工作目录里获得构建产物。 于是我用到了co

python解析帆软cpt及frm文件(xml)获取源数据表及下游依赖表
#!/user/bin/evn pythonimport os,re,openpyxl'''输入:帆软脚本文件路径输出:帆软文件检查结果Excel'''#获取来源表def table_scan(sql_str):# remove the /* */ commentsq = re.sub(r"/\*[^*]*\*+(?:[^*/][^*]*\*+)*/", "", sql_str)# re
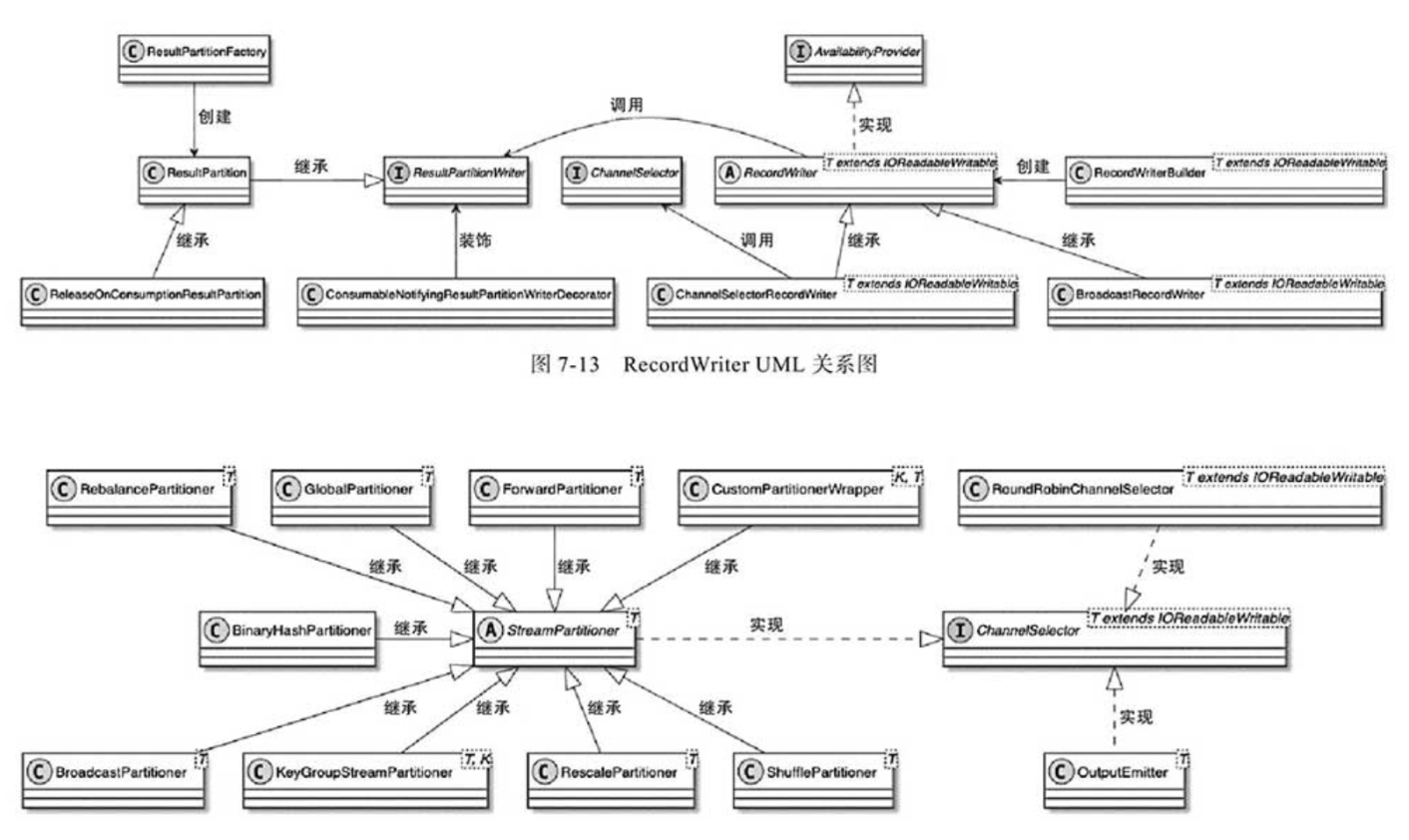
【Flink网络数据传输(3)】RecordWriter的能力:实现数据分发策略或广播到下游InputChannel
文章目录 一.创建RecordWriter实例都做了啥1. 根据recordWrites数量创建不同的代理类2. 创建RecordWriters3. 单个RecordWriter的创建细节 二. RecordWriter包含的主要组件1. RecordWriter两种实现类分别实现分发策略和广播2. ChannelSelectorRecordWriter的发送策略2.1. ChannelSe

AAAI 2024 | Adobe提出全新上下文提示学习框架CoPL,高效提升下游性能
论文题目:CoPL: Contextual Prompt Learning for Vision-Language Understanding 论文链接:https://arxiv.org/abs/2307.00910 提示学习(Prompt Learning)在近几年的快速发展,激活了以Transformer为基础的大型语言模型(LLM)的性能涌现。这一技术范式迅速在多模

HuggingFace-transformers系列的介绍以及在下游任务中的使用
这篇博客主要面向对Bert系列在Pytorch上应用感兴趣的同学,将涵盖的主要内容是:Bert系列有关的论文,Huggingface的实现,以及如何在不同下游任务中使用预训练模型。 看过这篇博客,你将了解: Transformers实现的介绍,不同的Tokenizer和Model如何使用。如何利用HuggingFace的实现自定义你的模型,如果你想利用这个库实现自己的下游任务,而不想过多关注其
【flink番外篇】15、Flink维表实战之6种实现方式-通过广播将维表数据传递到下游
Flink 系列文章 一、Flink 专栏 Flink 专栏系统介绍某一知识点,并辅以具体的示例进行说明。 1、Flink 部署系列 本部分介绍Flink的部署、配置相关基础内容。 2、Flink基础系列 本部分介绍Flink 的基础部分,比如术语、架构、编程模型、编程指南、基本的datastream api用法、四大基石等内容。 3、Flik Table API和SQL基础系列 本部

认识OCR,从文字检测到文字识别,从任务定义到下游任务,从形态学方法到深度学习
图灵测试是人工智能是否真正能够成功的一个标准,“计算机科学之父”、“人工智能之父”英国数学家图灵在1950年的论文《机器会思考吗》中提出了图灵测试的概念。即把一个人和一台计算机分别放在两个隔离的房间中,房间外的一个人同时询问人和计算机相同的问题,如果房间外的人无法分别哪个是人,哪个是计算机,就能够说明计算机具有人工智能。 1981年的诺贝尔将颁发给了David Hubel和Torsten Wi
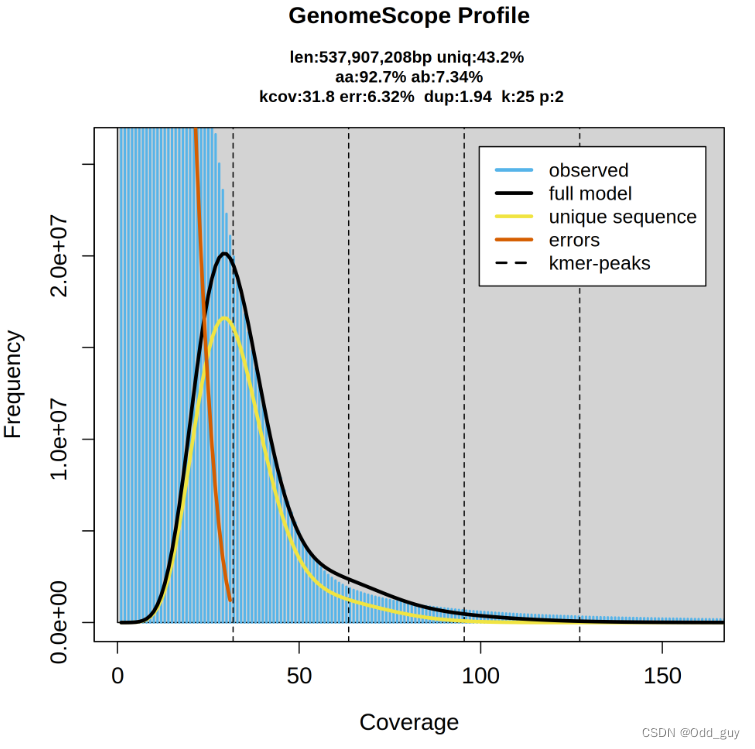
GenomeScope——jellyfish k-mer分析的下游分析
GenomeScope 2.0是一个可对多倍体基因组数据进行概括性分析的有效工具,其可以将jellyfish或KMC等k-mer分析软件的结果作为输入,并拟合混合模型,对基因组数据进行更深入的挖掘。 一、安装 GenomeScope 2.0的工作依赖于R,且需要安装其依赖包:argparse、minpack.lm。可以使用conda工具进行安装: #安装依赖包conda install -

arthas一次操作实现递归分析下游方法的耗时
背景 使用arthas的trace分析方法的耗时时,我们一般只能分析下一层的方法的耗时,然后一层一层的递归进去找到耗时最长的那个方法,有没有一种方式可以一次trace分析就可以把所有要关注的下层所有的耗时都打印出来? 解决方式 使用trace -E com.test.ClassA|org.test.ClassB method1|method2|method3 这种方式可以变相达到一次操作然后

HuggingFace-利用BERT预训练模型实现中文情感分类(下游任务)
准备数据集 使用编码工具 首先需要加载编码工具,编码工具可以将抽象的文字转成数字,便于神经网络后续的处理,其代码如下: # 定义数据集from transformers import BertTokenizer, BertModel, AdamW# 加载tokenizertoken = BertTokenizer.from_pretrained('bert-base-chinese')
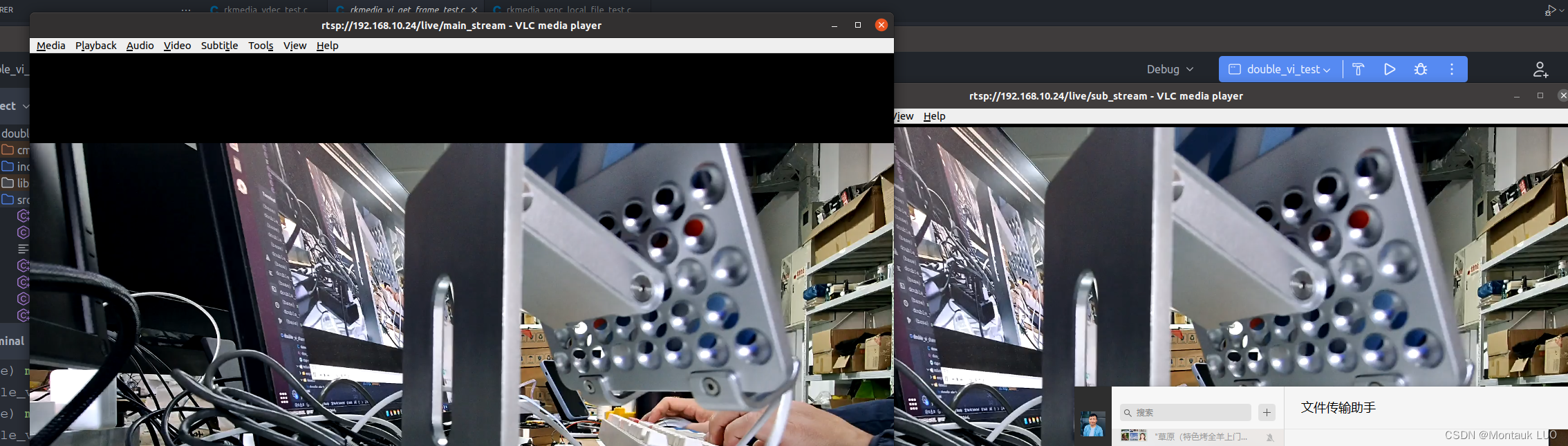
rk平台一个头两个流, 即同一个vi通道, 接两个不同的下游通道,比如rga
最早我有个迷思, 觉得, 每个vi的通道, 只能对应一个下游通道, 但是当我拿vdec当作输入的时候, 发现是不是并没有必要每个进来的包, 都做两次解码, 那不是有点傻么, 后来我在做rtsp+rknn的时候, 发现一个问题, 如果把一个节点, 比如rkisp_scanle0, 跟rkisp_scale1, 都做19201080输入, 直接就会报错, 原因如下图 原因是rkisp_scale1支
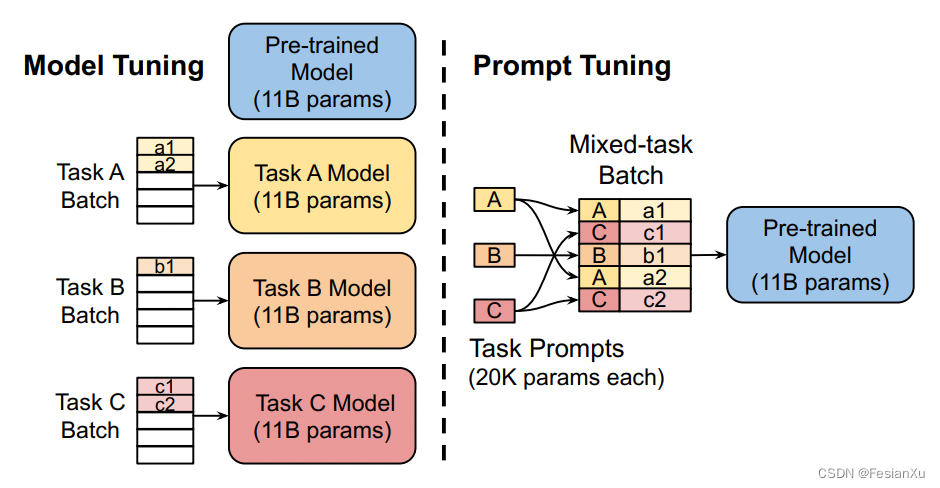
【论文极速读】Prompt Tuning——一种高效的LLM模型下游任务适配方式
【论文极速读】Prompt Tuning——一种高效的LLM模型下游任务适配方式 FesianXu 20230928 at Baidu Search Team 前言 Prompt Tuning是一种PEFT方法(Parameter-Efficient FineTune),旨在以高效的方式对LLM模型进行下游任务适配,本文简要介绍Prompt Tuning方法,希望对读者有所帮助。如有
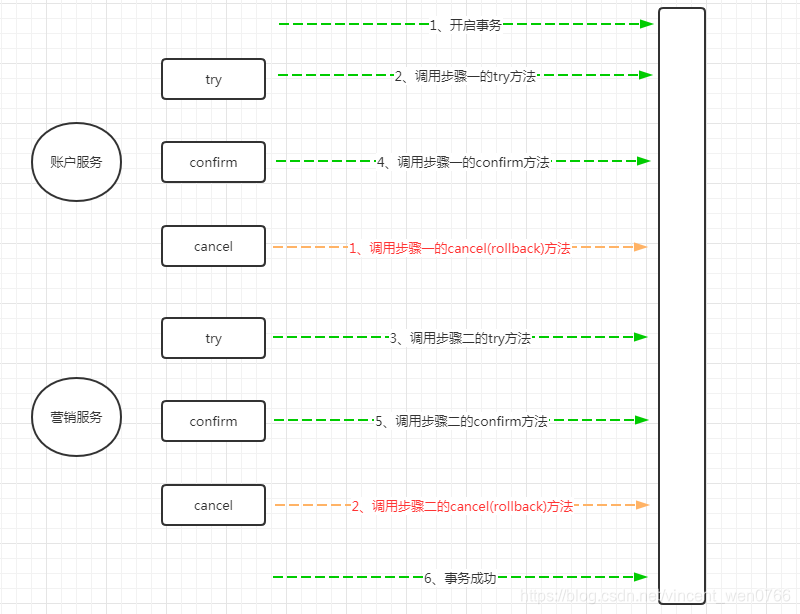
软件架构场景之—— 数据一致性:下游服务失败上游服务如何独善其身?
业务场景 使用微服务时,很多时候我们往往需要跨多个服务去更新多个数据库的数据,类似下图所示的架构 如图所示,如果业务正常运转,3 个服务的数据应该变为 a2、b2、c2,此时数据才一致。但是如果出现网络抖动、服务超负荷或者数据库超负荷等情况,整个处理链条有可能在步骤二失败,这时数据就会变成 a2、b1、c1,当然也有可能在步骤三失败,最终数据就会变成 a2、b2、c1,这样数据就对不上了,

预训练机器阅读理解模型:对齐生成式预训练与判别式下游场景
©PaperWeekly 原创 · 作者 | 徐蔚文,李昕,邴立东等 单位 | 阿里巴巴达摩院 论文链接: https://arxiv.org/pdf/2212.04755.pdf 收录会议: NeurIPS 2023 论文链接: https://aclanthology.org/2023.acl-short.131.pdf 收录会议: ACL 2023 代码链接: https://g
爬虫进阶-反爬破解9(下游业务如何使用爬取到的数据+数据和文件的存储方式)
一、下游业务如何使用爬取到的数据 (一)常用数据存储方案 1.百万级别数据:单机数据库,搭建和使用方便快捷,成本低 2.千万级别数据:负载均衡的多台数据库,安全和稳定 3.海量数据:大数据框架,分布式部署,承载量巨大 (二)数据库及框架 1.百万级别数据:Mysql、PostgreSQL、Mongo 2.千万级别数据:主从同步数据库,性能调优 3.大数据框架:Hbase、Elast
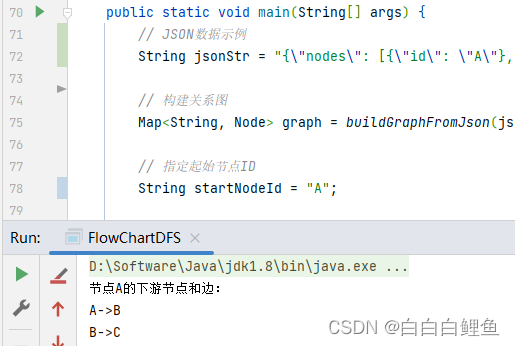
Java数据结构——应用DFS算法计算流程图下游节点(1)
问题描述: 前端在绘制流程图的时候,某些情况需要对某个节点之后的流程图进行折叠,因此需要得到某个节点的ID后,计算出这个ID下游之后的所有节点(找到的节点,边也就找到了) 已知条件: 某个节点的ID,流程图解析成对应的JSON对象文件(有的是将流程图解析成XML文件) 例如: {"nodes": [{"id": "A"},{"id": "B"},{"id": "C"}],"edges
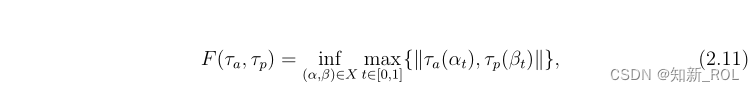
用于物体识别和跟踪的下游任务自监督学习-2-(计算机视觉中的距离度量+损失函数)
2.4 计算机视觉中的距离度量 在深度学习和计算机视觉中,距离度量通常用于比较图像、视频或其他数据的特征或嵌入。根据具体任务和数据属性,可以使用不同类型的距离度量。下面介绍了深度学习和计算机视觉中使用的一些常见类型的距离度量。 余弦相似性距离:余弦相似性测量向量空间模型(VSM)中两个向量之间的距离。余弦相似性Sc(τa,τp)和两个向量τa和τp之间对应的余弦距离Dc(τa、τp)可以定义如
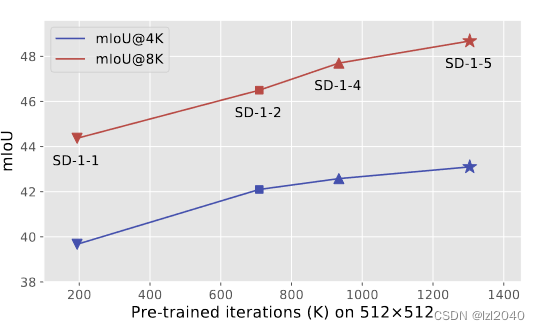
清华团队新作 | 从Text-to-Image扩散模型中提取表征,服务下游任务
文章标题:Unleashing Text-to-Image Diffusion Models for Visual Perception 代码地址:地址 文章地址:http://arxiv.org/abs/2303.02153 摘要 扩散模型(Diffusion Models,DMs)已成为生成模型的新趋势,并表现出强大的条件合成能力。其中,在大规模图文对上预训练的文本到图像扩散模型通过可定制

用于物体识别和跟踪的下游任务自监督学习-2-背景
2.1用于现实世界应用的计算机视觉的基本概念 有许多中间步骤涉及应用计算机视觉算法来解决现实世界中的问题。机器视觉算法从光学传感器的图像采集开始,并最终解决现实世界的决策任务,如自动驾驶汽车、机器人自动化和监控。设计现代计算机视觉算法包括传感器数据编码、解码、数据扩充和预处理、数据分解为训练/val/测试、特征提取、机器学习或深度学习算法设计,然后直观地利用模型特征预测任务解决方案或组合多个任务
用于物体识别和跟踪的下游任务自监督学习-1-引言
一:引言: 图像和视频理解是计算机视觉应用中的基本问题,旨在使机器能够像人类一样解释和理解视觉数据。这些问题涉及识别图像和视频中的对象、人物、动作、事件和场景。如图1.1-(a)所示的图像识别任务包括对象检测[1]、实例[7]、语义[8]或全景分割[9],以定位对象、识别其边界并预测图像帧中所有事物的像素类别。姿态和深度估计技术[10]预测图像中对象的关键点/姿态和深度。典型的挑战关于图像理解任