本文主要是介绍【Flink网络数据传输(3)】RecordWriter的能力:实现数据分发策略或广播到下游InputChannel,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 一.创建RecordWriter实例都做了啥
- 1. 根据recordWrites数量创建不同的代理类
- 2. 创建RecordWriters
- 3. 单个RecordWriter的创建细节
- 二. RecordWriter包含的主要组件
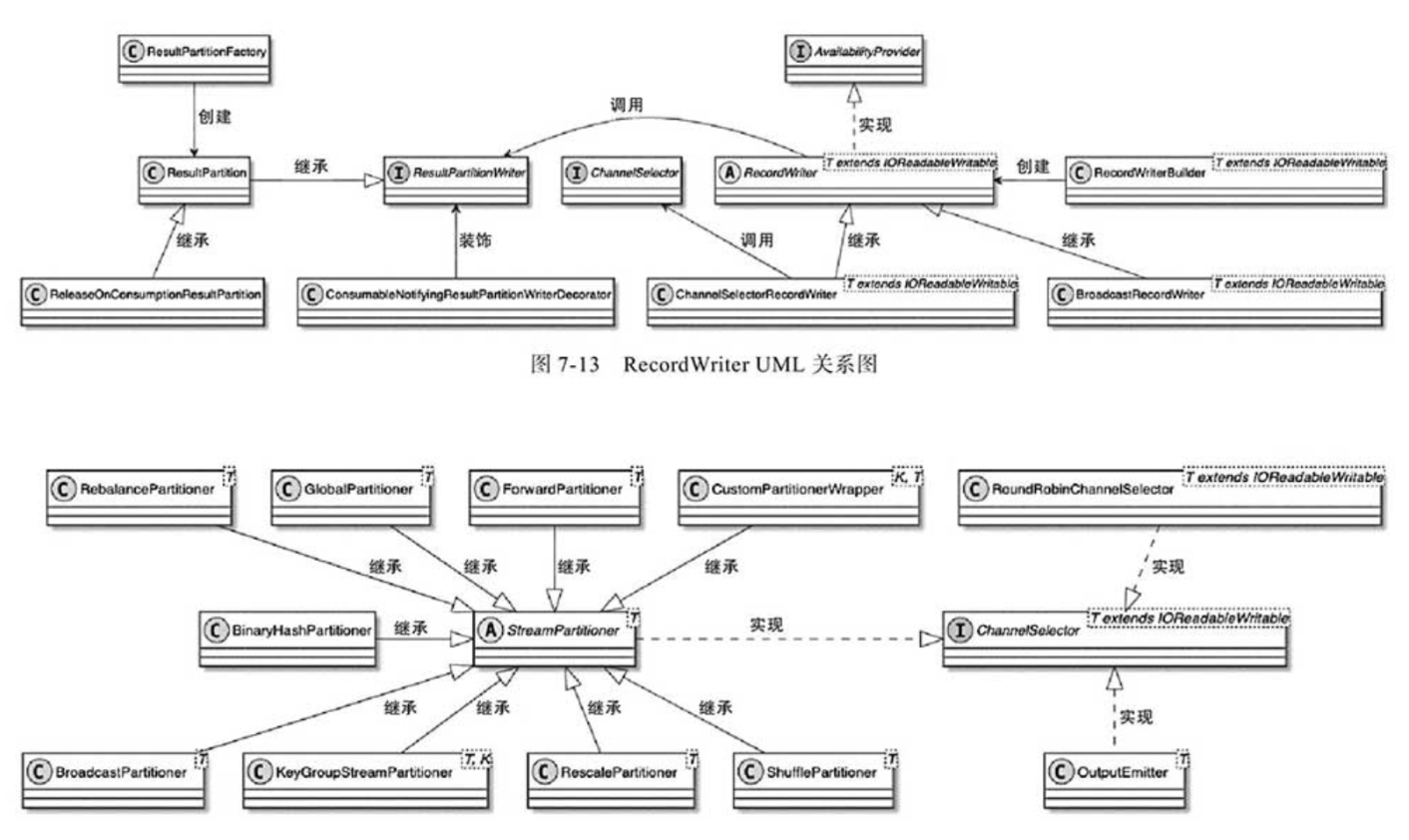
- 1. RecordWriter两种实现类分别实现分发策略和广播
- 2. ChannelSelectorRecordWriter的发送策略
- 2.1. ChannelSelector根据实现类实现不同发送策略
- 2. BroadcastRecordWriter广播所有元素到下游InputChannel
StreamTask节点中的中间结果数据元素最终通过RecordWriterOutput实现了网络输出,RecordWriterOutput底层依赖RecordWriter组件完成数据输出操作,接下来我们深入了解RecordWriter的设计和实现。
一.创建RecordWriter实例都做了啥
在StreamTask构造器方法中会直接创建RecordWriter实例,用于输出当前任务产生的Intermediate Result数据。
1. 根据recordWrites数量创建不同的代理类
其中createRecordWriterDelegate根据recordWrites的数量创建对应的RecordWriterDelegate代理类。
protected StreamTask( Environment environment, @Nullable TimerService timerService, Thread.UncaughtExceptionHandler uncaughtExceptionHandler, StreamTaskActionExecutor actionExecutor, TaskMailbox mailbox) throws Exception {...this.recordWriter = createRecordWriterDelegate(configuration, environment);...}
//1. 如果recordWrites数量等于1,则创建SingleRecordWriter代理类;
//2. 如果recordWrites数量等于0,则创建NonRecordWriter代理类;
//3. 其他情况则创建MultipleRecordWriters代理类。@VisibleForTesting
public static <OUT> RecordWriterDelegate<SerializationDelegate<StreamRecord<OUT>>> createRecordWriterDelegate( StreamConfig configuration, Environment environment) { List<RecordWriter<SerializationDelegate<StreamRecord<OUT>>>> recordWrites = createRecordWriters(configuration, environment); if (recordWrites.size() == 1) { return new SingleRecordWriter<>(recordWrites.get(0)); } else if (recordWrites.size() == 0) { return new NonRecordWriter<>(); } else { return new MultipleRecordWriters<>(recordWrites); }
}
2. 创建RecordWriters
获取StreamTask的所有输出边放到RecordWriters中,返回创建的RecordWriter集合。
private static <OUT> List<RecordWriter<SerializationDelegate<StreamRecord<OUT>>>> createRecordWriters(StreamConfig configuration,Environment environment) {// 创建RecordWriter集合List<RecordWriter<SerializationDelegate<StreamRecord<OUT>>>> recordWriters = new ArrayList<>();// 获取输出的StreamEdge(所有的输出边)List<StreamEdge> outEdgesInOrder = configuration.getOutEdgesInOrder(environment.getUserClassLoader());// 获取chainedConfigs参数Map<Integer, StreamConfig> chainedConfigs = configuration.getTransitiveChainedTaskConfigsWithSelf(environment.getUserClassLoader());// 遍历输出节点,分别创建RecordWriter实例for (int i = 0; i < outEdgesInOrder.size(); i++) {StreamEdge edge = outEdgesInOrder.get(i);recordWriters.add(createRecordWriter(edge,i,environment,environment.getTaskInfo().getTaskName(),chainedConfigs.get(edge.getSourceId()).getBufferTimeout()));}return recordWriters;
}
3. 单个RecordWriter的创建细节
看单个RecordWriter的创建过程,包括分区策略、缓存结果的ResultPartition、最后通过RecordWriterBuilder创建RecordWriter、以及设定MetricGroup监控RecordWriter指标并输出。
- 创建outputPartitioner:StreamPartitioner分区策略会被应用在RecordWriter中,例如DataStream.rebalance()操作就会创建RebalancePartitioner作为StreamPartitioner的实现类,并通过RebalancePartitioner
选择下游InputChannel,实现数据元素按照指定的分区策略下发。- ResultPartition: ResultPartition内部
会在本地存储需要下发的Buffer数据,并等待下游节点向上游节点发送数据消费请求。- 通过RecordWriterBuilder创建RecordWriter,在创建过程中会设定outputPartitioner、bufferTimeout以及bufferWriter等参数。
- 为RecordWriter设定MetricGroup,用于监控指标的采集和输出。
private static <OUT> RecordWriter<SerializationDelegate<StreamRecord<OUT>>> createRecordWriter(StreamEdge edge,int outputIndex,Environment environment,String taskName,long bufferTimeout) {@SuppressWarnings("unchecked")// 获取边上的StreamPartitionerStreamPartitioner<OUT> outputPartitioner = (StreamPartitioner<OUT>) edge.getPartitioner();LOG.debug("Using partitioner {} for output {} of task {}", outputPartitioner, outputIndex, taskName);// 获取ResultPartitionWriterResultPartitionWriter bufferWriter = environment.getWriter(outputIndex);// 初始化Partitionerif (outputPartitioner instanceof ConfigurableStreamPartitioner) {int numKeyGroups = bufferWriter.getNumTargetKeyGroups();if (0 < numKeyGroups) {((ConfigurableStreamPartitioner) outputPartitioner).configure(numKeyGroups);}}// 创建RecordWriterRecordWriter<SerializationDelegate<StreamRecord<OUT>>> output = new RecordWriterBuilder<SerializationDelegate<StreamRecord<OUT>>>().setChannelSelector(outputPartitioner).setTimeout(bufferTimeout).setTaskName(taskName).build(bufferWriter);// 设定MetricGroup监控output.setMetricGroup(environment.getMetricGroup().getIOMetricGroup());return output;
}
二. RecordWriter包含的主要组件
RecordWriter内部主要包含RecordSerializer和ResultPartitionWriter两个组件。
- RecordSerializer用于对输出到网络中的数据进行
序列化操作,将数据元素序列化成Bytes[]二进制格式,维护Bytes[]数据中的startBuffer及position等信息。- ResultPartitionWriter是ResultPartition实现的接口,提供了将
数据元素写入ResultPartiton的方法,例如addBufferConsumer()方法就是将RecordSerializer序列化的BufferConsumer数据对象添加到ResultPartition队列并进行缓存,供下游InputGate消费BufferConsumer对象。
1. RecordWriter两种实现类分别实现分发策略和广播
RecordWriter主要有两种实现类:ChannelSelectorRecordWriter和BroadcastRecordWriter。
- ChannelSelectorRecordWriter根据ChannelSelector
选择下游节点的InputChannel,ChannelSelector内部基于StreamPartitoner获取不同的数据下发策略,最终实现数据重分区。- BroadcastRecordWriter对应广播式数据下发,即数据元素会被发送到下游
所有的InputChannel中。当用户执行了Broadcast操作时,就会创建BroadcastRecordWriter实现数据元素的广播下发操作。
如代码:通过RecordWriterBuilder创建RecordWriter,此时会根据selector.isBroadcast()条件选择创建ChannelSelectorRecordWriter还是BroadcastRecordWriter实例。
public RecordWriter<T> build(ResultPartitionWriter writer) {if (selector.isBroadcast()) {return new BroadcastRecordWriter<>(writer, timeout, taskName);} else {return new ChannelSelectorRecordWriter<>(writer, selector, timeout, taskName);}
}
2. ChannelSelectorRecordWriter的发送策略
ChannelSelectorRecordWriter控制数据元素发送到下游的哪些InputChannel中。如代码,调用channelSelector.selectChannel(record)选择下游的InputChannel。
对于非广播类型的分区器,最终都会创建ChannelSelectorRecordWriter实现StreamRecord数据的下发操作。
public void emit(T record) throws IOException, InterruptedException {emit(record, channelSelector.selectChannel(record));
}
2.1. ChannelSelector根据实现类实现不同发送策略
ChannelSelector的实现类主要有StreamPartitioner、RoundRobinChannelSelector和OutputEmitter三种。
- StreamPartitioner:DataStream API中物理操作指定的分区器,例如当用户调用DataStream.rebalance()方法时,会创建RebalencePartitioner。在StreamTask执行的过程中,会获取相应的StreamPartitioner应用在ChannelSelectorRecordWriter中,实现对数据元素分区的选择。
- RoundRobinChannelSelector:ChannelSelector的默认实现类,提供了对Round-Robin策略的支持,以轮询的方式随机选择一个分区输出数据元素。
- OutputEmitter:适用于BatchTask,须配合ShipStrategyType使用,通过ShipStrategyType执行的策略输出数据。
2. BroadcastRecordWriter广播所有元素到下游InputChannel
BroadcastRecordWriter的实现就比较简单了,在BroadcastRecordWriter中不需要ChannelSelector组件选择数据元素分区,直接将所有的数据元素广播发送到下游所有InputChannel中即可。
这篇关于【Flink网络数据传输(3)】RecordWriter的能力:实现数据分发策略或广播到下游InputChannel的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




