本文主要是介绍预训练机器阅读理解模型:对齐生成式预训练与判别式下游场景,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

©PaperWeekly 原创 · 作者 | 徐蔚文,李昕,邴立东等
单位 | 阿里巴巴达摩院

论文链接:
https://arxiv.org/pdf/2212.04755.pdf
收录会议:
NeurIPS 2023

论文链接:
https://aclanthology.org/2023.acl-short.131.pdf
收录会议:
ACL 2023
代码链接:
https://github.com/DAMO-NLP-SG/PMR

背景
基于编码器的判别式方法是解决自然语言理解任务(NLU)的非常有效的方法。在预训练模型时代,通常的做法是在掩码模型(MLM)编码器上,添加对应的任务层,用下游 NLU 数据对所有模型参数进行微调 [1,2]。例如在解决命名实体识别任务时,可以在编码器上添加一个标记层(tagging layer)后用对应的任务数据进行微调。
判别式方法通过对应的任务层来改变模型的训练目标,从而向下游 NLU 任务场景对齐。并且判别式的方法的输出空间只涉及少量的任务标签,因此在模式上更简单。在下游微调数据充足的情况下,判别式方法可以很好的从大量数据中学习解决 NLU 任务的模式。然而在数据稀缺的情况下,无法对任务层进行充分的训练。因此判别式方法在低资源情况下的表现不尽人意 [3]。
生成式微调则反其道而行之,通过将下游 NLU 任务往预训练模型的训练模式对齐 [4]。在对下游任务数据进行微调时,由于训练目标的一致并且不需要添加未经训练的模块,预训练的知识能够有效地迁移到下游任务上。因此即使在数据稀缺的情况下,生成式方法也能有较好的表现。尤其是在大模型的加持下,基于解码器的生成式方法有着强大的零样本(zero-shot)和小样本(few-shot)的 NLU 能力 [3]。
然而由于生成式方法的输出空间涉及整个词表,其输出模式远比判别式方法更复杂。这使得生成式模型在更多数据中学习 NLU 任务模式没有判别式方法高效,对应的任务效果也不如充分训练的判别式模型 [5]。
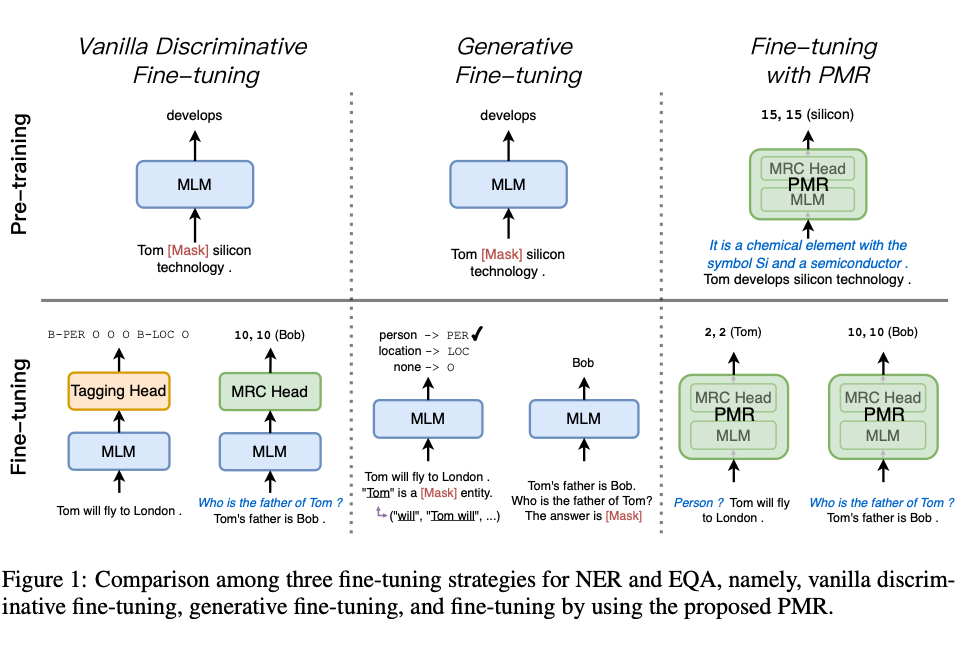
为了解决上述判别式和生成式方法的缺陷,阿里巴巴达摩院联合香港中文大学的研究人员提出了 PMR 系列工作。PMR 及其多语言拓展 mPMR 是基于机器阅读理解(MRC)架构的预训练模型。PMR 通过维基百科的超链接信息构造了大规模高质量的 MRC 数据,并在 RoBERTa 编码器基础上进行增量式 MRC 风格的预训练得到。
在解决下游 NLU 任务时,作为一个判别式模型,PMR 可以有效的学习 NLU 任务模式,同时在把下游任务都统一在 MRC 架构下,PMR 可以消除预训练和微调之间的目标差异,因此在资源充足和低资源场景下也能取得强大的下游任务效果。PMR 方法可以自然的拓展到多语言的环境,其拓展 mPMR 在跨语言任务上更是取得了多项 SOTA 任务表现。PMR 系列工作实现了在低资源,资源充足以及跨语言场景下任务表现的“我全都要”,彻底释放了编码器模型的强大的自然语言理解能力。

MRC模型结构
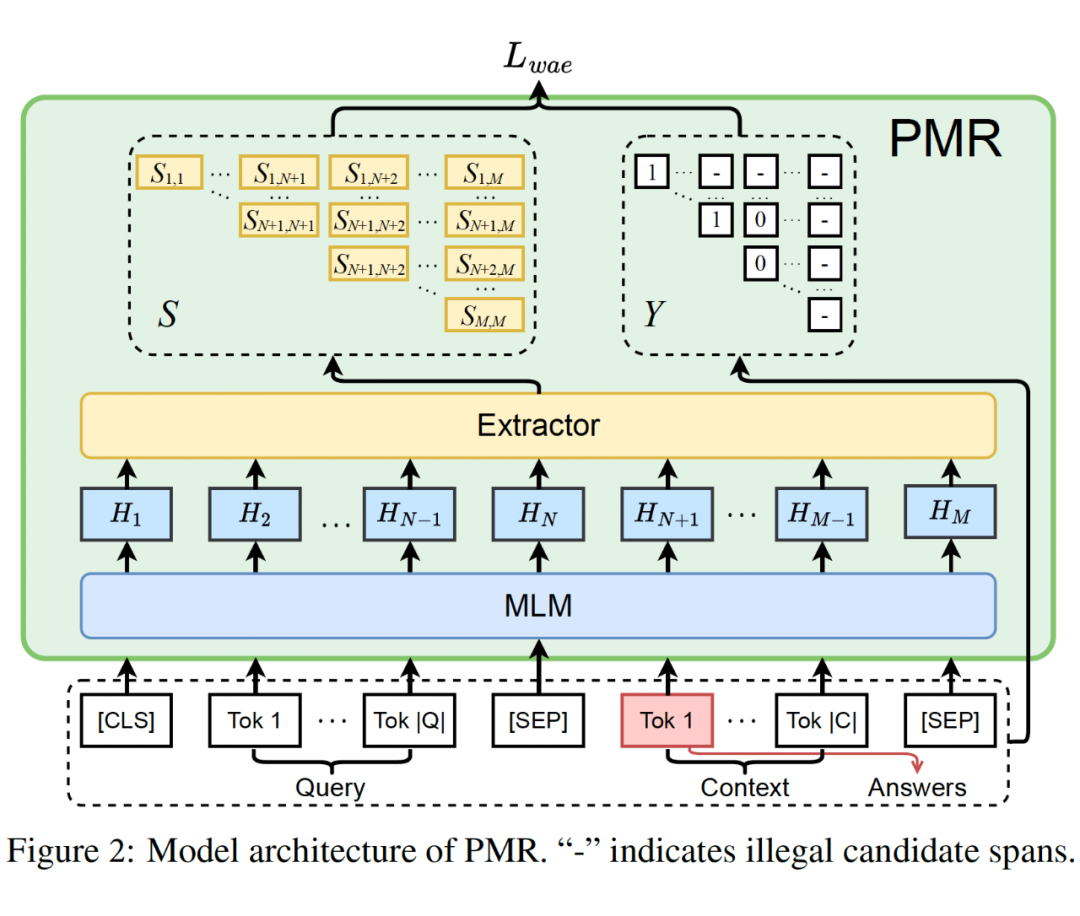
PMR 包含两个模块。首先 PMR 首先使用 RoBERTa(mPMR 使用 XLM-R)作为 MLM 的模块来获得输入查询和上下文文本的词级别表征。其后,PMR 添加了一个抽取器(Extractor),该抽取器计算任意两个词所包含的片段作为答案文本的概率。在训练时,作者提出了一个维基锚抽取(Wiki Anchor Extraction,WAE)的训练目标,该目标训练模型在 MRC 架构下同时高效地统一地进行抽取和分类任务。

MRC数据构造

PMR 通过维基百科的超链接构造了大约 1800 万条高质量的 MRC 数据。具体而言,维基百科的超链接会关联两篇文档,分别叫做“定义文档”以及“提及文档”。定义文档能提供一个维基百科实体的详细描述。通常来说开头的几句话是该实体非常全面的总结,因此可以当作该实体的定义 [6]。在提及文档中,超链接会提供一个精确的文本片段,也叫做锚,并指出该锚所对应的维基实体所对应的定义文档。
提及文档提供了一个实体自然的用法,既锚所在的上下文片段。针对一个锚,即一组超链接信息,作者将该锚作为 MRC 的答案,将锚周围的文本当作 MRC 的上下文,将锚所对应的实体定义当作 MRC 的查询来构建一组 MRC 三元组数据。作者还在查询中对维基实体进行匿名来避免信息泄漏,从而防止模型学会抽取和该实体一样的文本当作答案。作者构造单文本抽取,多文本抽取的正样本数据在 MRC 架构下实现基于抽取的预训练,通过构造无法回答的负样本数据在 MRC 架构下实现基于分类的预训练。

多语言扩展
总体而言,PMR 的数据构造方式是与语言无关的,因此可以无缝的将英语数据的构造方式拓展到各个语言上。然而很多语言面临没有分句工具的困境,因此,作者进一步提出了 Unified Q/C Construction 和 Stochastic Answer Position 两个方案来进一步提升多语拓展的兼容性。其中 Unified Q/C Construction 摒弃了分句工具,通过词的数量来控制查询和上下文的长度;Stochastic Answer Position 则在构造上下文的时候,保证了答案在上下文中位置的随机性,从而避免模型过拟合到通过位置信息来抽取答案。

在MRC范式下统一NLU
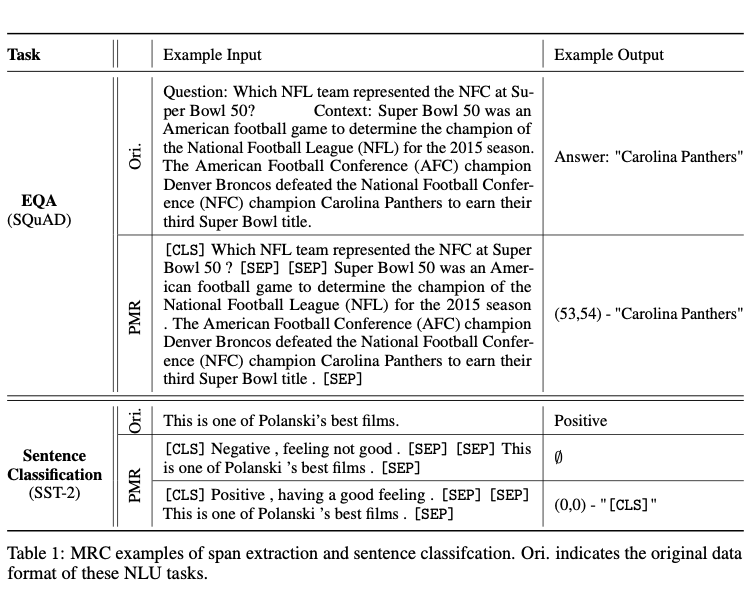
下游 NLU 任务从形式上可以分为分类任务,抽取任务以及该两种类型的组合任务。因此 PMR 将最基本的分类以及抽取任务统一在 MRC 架构下。对于抽取任务,任务的需求被作为查询(如 QA 中的问题以及 NER 中的标签),模型要在给定上下文中输出查询所对应的答案文本的具体位置信息。对于分类任务,任务的标签被视作查询,模型需要判断该查询是否与给定上下文相关。

实验结果
作者展示了 PMR 系列工作在小样本,全样本,以及跨语言 NLU 任务上的效果。
1. 小样本
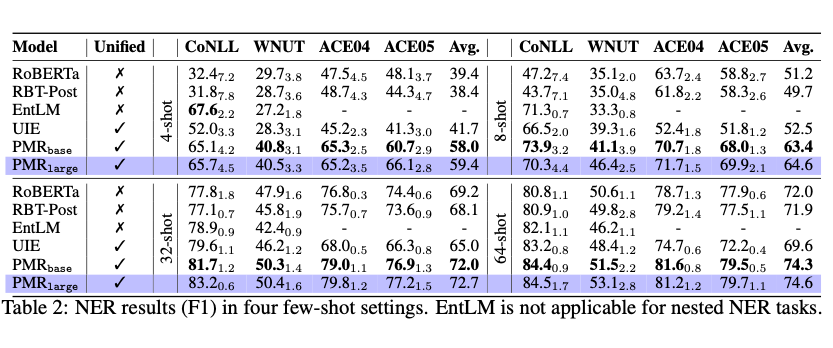
在 4 个 NER 的小样本任务上,PMR 在相比于现有同规模的判别式方法(RoBERTa [2],RBT-Post)和生成式方法(EntLM [7],UIE [8])都取得了极大的性能提升。其中在数据极端稀缺的情况下(4-shot),PMR 相比于现有最好的方法 UIE 平均提升了 16.3 F1。
2. 全样本
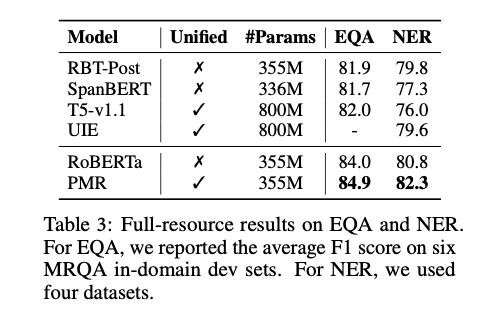
在全样本的 NER 和 EQA 任务上,PMR 仍能在强大的 RoBERTa 基础上继续提升任务的表现。
3. 跨语言
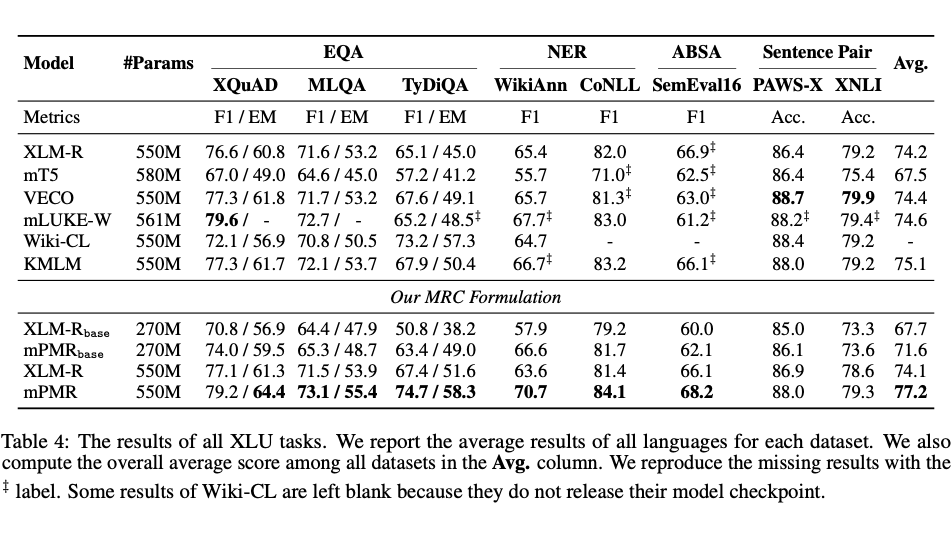
作者测试了大量跨语言抽取和分类任务,该系列 mPMR 能在不增加额外的参数量的情况下显著提升整体跨语言任务的效果。在大部分基于 XLM-R [9] 的方法的提升都不足 1 个点的时候,mPMR 能足足拉开和 XLM-R 平均 3 个点左右的差距。

可解释的分类任务

在预训练阶段,PMR 习得根据查询在上下文中抽取文本片段的能力。作者测试 PMR 的抽取能力是否对下游分类任务有帮助。因此作者让经过分类任务数据微调后的 PMR 模型在上下文中抽取一个抽取概率最高的文本片段。在测试了 300 条样例后,令人惊奇的是,在微调阶段,即使没有特定的文本抽取的监督信号,PMR 却能在 224 条样例中抽取出与对应文本标签最相关的内容。这证明了 PMR 能利用其强大的抽取能力在分类任务中抽取合适的文本片段作为支持此次分类的依据,从而提升了模型的可解释性。

在PMR中统一NLU任务
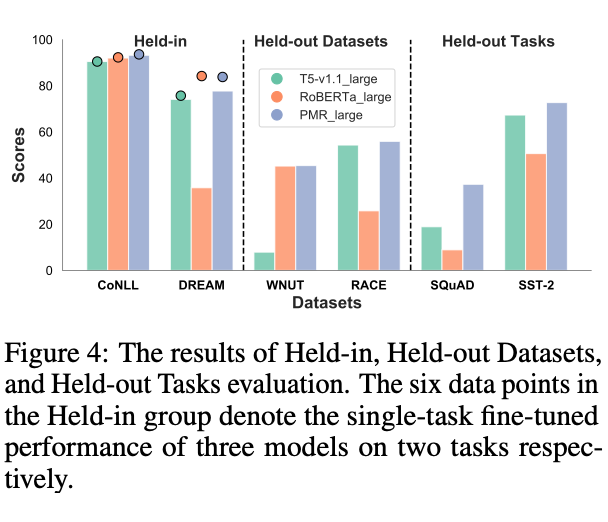
作者还发现 PMR 能作为一个统一的模型来处理分类和抽取任务。作者测试了 PMR 和作为判别式方法的代表 RoBERTa,以及作为生成式方法的代表 T5 在做多任务学习上的表现 [10]。其中 PMR 相比 RoBERTa 和 T5 能够更加有效的学习多任务的知识(Held-in),并且在跨领域(Held-out Datasets)以及跨类型的 NLU 任务上(Held-out Tasks)上,PMR 更是展现了更加强大的迁移能力。

总结
PMR 是一个面向通用自然语言理解的工作,首次提出了基于机器阅读理解的预训练模型,方法以及数据。该工作消除了判别式方法在模型预训练和下游任务微调之间的差距,从而在低资源,资源丰富以及跨语言的场景下,取得显著的自然语言任务上的提升。PMR 在分类任务的可解释性方面,以及统一的 NLU 模型方面也取得长足进展。

参考文献
[1] Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. BERT: Pre-training of deep bidirectional transformers for language understanding. NAACL 2019
[2] ] Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. Roberta: A robustly optimized bert pretraining approach.
[3] Rakesh Chada and Pradeep Natarajan. FewshotQA: A simple framework for few-shot learning of question answering tasks using pre-trained text-to-text models. EMNLP 2021
[4] Timo Schick and Hinrich Schütze. Exploiting cloze-questions for few-shot text classification and natural language inference. EACL 2021
[5] Yubo Ma, Yixin Cao, YongChing Hong, and Aixin Sun. Large language model is not a good few-shot information extractor, but a good reranker for hard samples!, 2023
[6] Wei-Cheng Chang, Felix X. Yu, Yin-Wen Chang, Yiming Yang, and Sanjiv Kumar. Pre-training tasks for embedding-based large-scale retrieval. ICLR 2020
[7] Ruotian Ma, Xin Zhou, Tao Gui, Yiding Tan, Linyang Li, Qi Zhang, and Xuanjing Huang. Template-free prompt tuning for few-shot NER. NAACL 2022
[8] Yaojie Lu, Qing Liu, Dai Dai, Xinyan Xiao, Hongyu Lin, Xianpei Han, Le Sun, and Hua Wu. Unified structure generation for universal information extraction. ACL 2022
[9] Alexis Conneau, Kartikay Khandelwal, Naman Goyal, Vishrav Chaudhary, Guillaume Wenzek, Francisco Guzmán, Edouard Grave, Myle Ott, Luke Zettlemoyer, and Veselin Stoyanov. Unsupervised cross-lingual representation learning at scale. ACL 2020
[10] Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J Liu. Exploring the limits of transfer learning with a unified text-to-text transformer. JMLR 2020
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
·
·

这篇关于预训练机器阅读理解模型:对齐生成式预训练与判别式下游场景的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






