sparkcore专题

Spark学习之路 (十四)SparkCore的调优之资源调优JVM的GC垃圾收集器
《2021年最新版大数据面试题全面开启更新》 欢迎关注github《大数据成神之路》 目录 一、概述 二、垃圾收集器(garbage collector (GC)) 是什么? 三、为什么需要GC? 四、为什么需要多种GC? 五、对象存活的判断 六、垃圾回收算法 6.1 标记 -清除算法 6.2 复制算法 6.3 标记-整理算法 6.4 分代收集算法 七、垃圾收集器 7.1 Serial收集器
Spark学习之路 (十三)SparkCore的调优之资源调优JVM的基本架构
《2021年最新版大数据面试题全面开启更新》 欢迎关注github《大数据成神之路》 目录 一、JVM的结构图 1.1 Java内存结构 1.2 如何通过参数来控制各区域的内存大小 1.3 控制参数 1.4 JVM和系统调用之间的关系 二、JVM各区域的作用 2.1 Java堆(Heap) 2.2 方法区(Method Area) 2.3 程序计数器(Program Counter R

Spark学习之路 (十二)SparkCore的调优之资源调优
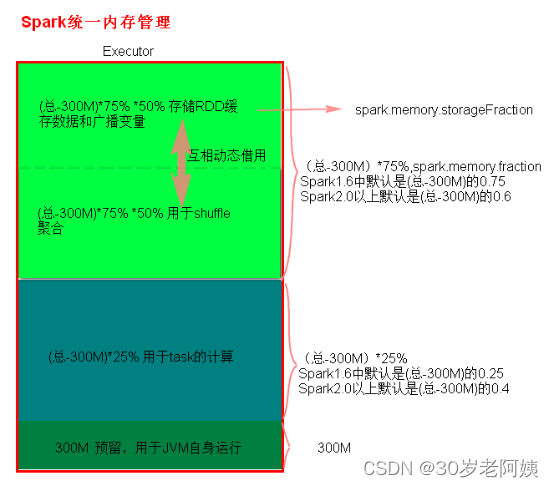
《2021年最新版大数据面试题全面开启更新》 欢迎关注github《大数据成神之路》 目录 一、概述 二、Spark作业基本运行原理 三、资源参数调优 3.1 num-executors 3.2 executor-memory 3.3 executor-cores 3.4 driver-memory 3.5 spark.default.parallelism 3.6 spark.storag

Spark学习之路 (十)SparkCore的调优之Shuffle调优
《2021年最新版大数据面试题全面开启更新》 欢迎关注github《大数据成神之路》 目录 一、概述 二、shuffle的定义 三、ShuffleManager发展概述 四、HashShuffleManager的运行原理 4.1 未经优化的HashShuffleManager 4.2 优化后的HashShuffleManager 五、SortShuffleManager运行原理 5.1 普通
Spark学习之路 (九)SparkCore的调优之数据倾斜调优
《2021年最新版大数据面试题全面开启更新》 欢迎关注github《大数据成神之路》 目录 调优概述 数据倾斜发生时的现象 数据倾斜发生的原理 如何定位导致数据倾斜的代码 某个task执行特别慢的情况 某个task莫名其妙内存溢出的情况 查看导致数据倾斜的key的数据分布情况 数据倾斜的解决方案 解决方案一:使用Hive ETL预处理数据 解决方案二:过滤少数导致倾斜的key 解决方案三:提
Spark学习之路 (八)SparkCore的调优之开发调优
《2021年最新版大数据面试题全面开启更新》 欢迎关注github《大数据成神之路》 前言 在大数据计算领域,Spark已经成为了越来越流行、越来越受欢迎的计算平台之一。Spark的功能涵盖了大数据领域的离线批处理、SQL类处理、流式/实时计算、机器学习、图计算等各种不同类型的计算操作,应用范围与前景非常广泛。在美团•大众点评,已经有很多同学在各种项目中尝试使用Spark。大多数同学(包括笔

SparkCore(15):Shuffle原理和优化
一、总括 Shuffle是进行重新分区的过程,即上游RDD与下游RDD是宽依赖的关系。以下操作可能会引起Shuffle (1)重新调整分区操作:repartiton,coalesce (2)*ByKey:groupByKey,reduceByKey (3)关联操作:join 二、shuffle Manager改进 1-》Spark在1.1以前的版本一直是采用Hash Shuffle的实现的
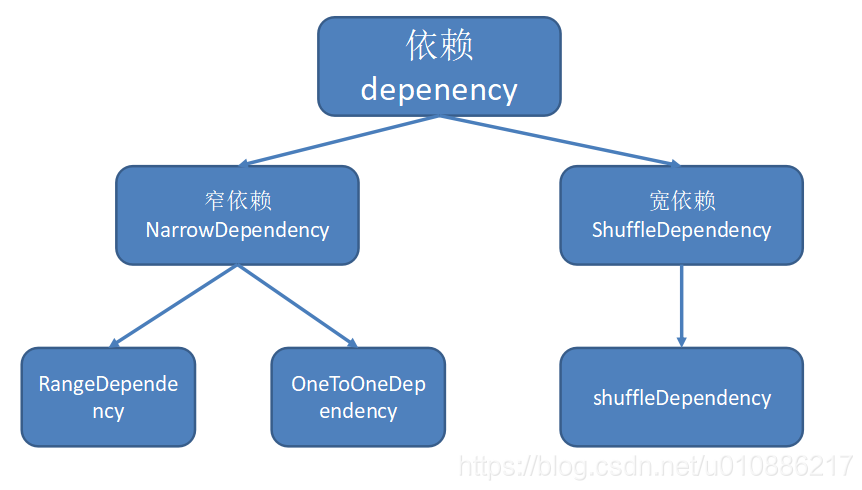
SparkCore(14):RDD宽依赖和窄依赖
一、两者区别的架构 1.宽依赖和窄依赖操作算子的区别 2.宽依赖和窄依赖类型区别 二、概念 1.窄依赖 (1)概念 子RDD的每个分区的数据来自常数个父RDD分区;父RDD的每个分区的数据到子RDD的时候在一个分区中进行处理。即,父依赖的每个分区都分到子依赖的一个分区中 (2)对应算子 (a)输入输出一对一的算子,且结果 RDD 的分区结构不变,主要是
SparkCore(13):TopN算法
1.实现功能 针对数据,进行排序选取TopN的数据。 2.数据 aa 78bb 98aa 80cc 98aa 69cc 87bb 97cc 86aa 97bb 78bb 34cc 85bb 92cc 72bb 32bb 23 3.代码 3.1 SparkUtil package SparkUtilimport org.apache.spark.{S
SparkCore(12):RDD三种API
一、简介 RDD的操作分为三类:transformation、action以及persistent,分别有不同功能,以下做一个详细介绍。 二、RDD三种API 1.tranformation (1)执行时间:由一个RDD产生一个新的RDD,不会触发job的执行 (2)作用:这个操作是在driver过程中执行的,当有action的操作时,就会把对应的信息发送到excutor上面 (3)常
SparkCore(11):RDD概念和创建RDD两种方法,以及RDD的Partitions以及并行度理解
一、RDD概念 1.概念 Resilient Distributed Datasets弹性分布式数据集,默认情况下:每一个block对应一个分区,一个分区会开启一个task来处理。 (a)Resilient:可以存在给定不同数目的分区、数据缓存的时候可以缓存一部分数据也可以缓存全部数据 (b)Distributed:分区可以分布到不同的executor执行(也就是不同的worker/NM上执
SparkCore(10):uv/pv实例
1.统计样例 2013-05-19 13:00:00 http://www.taobao.com/17/?tracker_u=1624169&type=1 B58W48U4WKZCJ5D1T3Z9ZY88RU7QA7B1 http://hao.360.cn/ 1.196.34.243 NULL -12013-05-19 13:00:00 http://www.taobao.com/item/9

SparkCore(9):Spark应用资源构成和启动配置信息三个位置
一、spark应用资源构成和执行过程 1.资源构成 一个spark应用是由:Driver + Executors组成,其中: (1)Driver: SparkContext上下文的构建、RDD的构建、RDD的调度 (2)Executor:具体task执行的位置 备注:一个application 可以包含多个jobs,一个job包含多个stage,一个stage包含多个task 2.
SparkCore(7):SparkOnYarn提交(生产环境)
一、实现功能 将spark的wordcount任务提交到Yarn上,然后计算结果输出到hdfs上。 二、实现步骤 1.Wordcount_product代码 package _0722rdd/*** Created by Administrator on 2018/7/16.*/import org.apache.spark.rdd.RDDimport org.apache.spark
Spark重温笔记(二):快如闪电的大数据计算框架——你真的了解SparkCore的 RDD 吗?(包含企业级搜狗案例和网站点击案例)
Spark学习笔记 前言:今天是温习 Spark 的第 2 天啦!主要梳理了 Spark 核心数据结构:RDD(弹性分布式数据集),其中包括基于内存计算的 SparkCore 各类技术知识点希望对大家有帮助! Tips:"分享是快乐的源泉💧,在我的博客里,不仅有知识的海洋🌊,还有满满的正能量加持💪,快来和我一起分享这份快乐吧😊! 喜欢我的博客的话,记得点个红心❤️和小关小
Spark官方文档-SparkCore
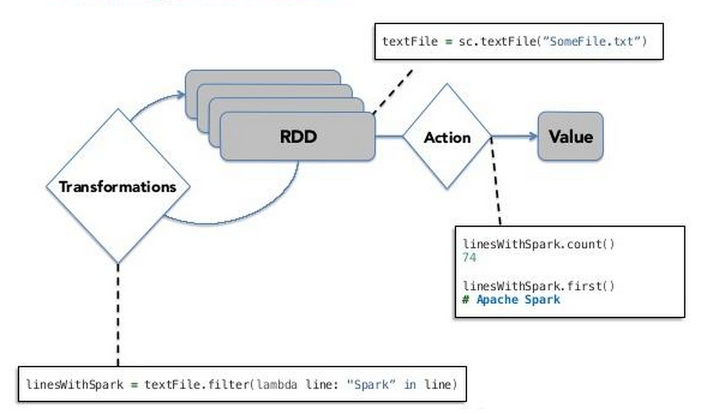
快速开始 RDD 1.Spark 的主要抽象是一个分布式弹性数据集(RDD),可以从 Hadoop InputFormats(例如 HDFS 文件)或通过转换其他RDD来创建RDD。 val textFile = spark.read.textFile("README.md") 2.可以通过调用某些操作直接从 RDD中获取值,或者转换RDD以获得新的值 textFile.count()

2024.1.8 Day04_SparkCore_homeWork
目录 1. 简述Spark持久化中缓存和checkpoint检查点的区别 2 . 如何使用缓存和检查点? 3 . 代码题 浏览器Nginx案例 先进行数据清洗,做后续需求用 1、需求一:点击最多的前10个网站域名 2、需求二:用户最喜欢点击的页面排序TOP10 3、需求三:统计每分钟用户搜索次数 学生系统案例 4. RDD依赖的分类 5. 简述DAG与Stage 形成过程

38 Sparkcore中的BlockManager
主要内容: 1. BlockManager 运行实例 2. BlockManager 原理流程图 37中的回顾: 首先讲解了Task内部具体执行的流程;然后介绍了Driver是如何对Executor处理后的Task执行的结果进行进一步的处理的。 从上一讲的内容可以看出在Shuffle过程中要读写数据(即上一个Stage的数据)时需要BlockManager的
大数据开发:SparkCore开发调优原则
在大数据计算引擎当中,Spark受到的重视是越来越多的,尤其是对数据处理实时性的要求越来越高,Hadoop原生的MapReduce引擎受到诟病,Spark的性能也需要不断调整优化。今天的大数据开发学习分享,我们就来讲讲SparkCore开发调优原则。 Spark在大数据领域,能够实现离线批处理、SQL类处理、流式/实时计算、机器学习、图计算等各种不同类型的计算操作,对于企业而言是
Spark---SparkCore(五)
五、Spark Shuffle文件寻址 1、Shuffle文件寻址 1)、MapOutputTracker MapOutputTracker是Spark架构中的一个模块,是一个主从架构。管理磁盘小文件的地址。 MapOutputTrackerMaster是主对象,存在于Driver中。MapOutputTrackerWorker是从对象,存在于Excutor中。 2)、BlockMana
Spark---SparkCore(五)
五、Spark Shuffle文件寻址 1、Shuffle文件寻址 1)、MapOutputTracker MapOutputTracker是Spark架构中的一个模块,是一个主从架构。管理磁盘小文件的地址。 MapOutputTrackerMaster是主对象,存在于Driver中。MapOutputTrackerWorker是从对象,存在于Excutor中。 2)、BlockMana
Python大数据之PySpark(八)SparkCore加强
文章目录 SparkCore加强Spark算子补充[掌握]RDD 持久化[掌握]RDD Checkpoint后记 SparkCore加强 重点:RDD的持久化和Checkpoint提高拓展知识:Spark内核调度全流程,Spark的Shuffle练习:热力图统计及电商基础指标统计combineByKey作为面试部分重点,可以作为扩展知识点 Spark算子补充 关联函数补充
CC00032.spark——|HadoopSpark.V06|——|Spark.v06|sparkcore|RDD编程高阶RDD分区器|
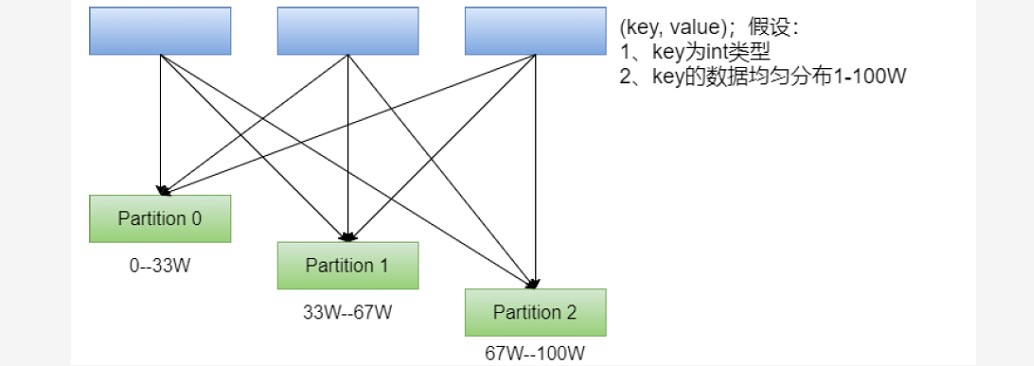
一、RDD分区器 ### --- 以下RDD分别是否有分区器,是什么类型的分区器scala> val rdd1 = sc.textFile("/wcinput/wc.txt")rdd1: org.apache.spark.rdd.RDD[String] = /wcinput/wc.txt MapPartitionsRDD[34] at textFile at <console>:2

大数据系列之SparkCore应用解析(二)
文章目录 第1章 RDD概念1.1 RDD为什么会产生1.2 RDD概述1.2.1 什么是RDD1.2.2 RDD的属性 1.3 RDD弹性1.4 RDD特点1.4.1 分区1.4.2 只读1.4.3 依赖1.4.4 缓存1.4.5 checkpoint 第2章 RDD编程2.1 编程模型2.2 创建RDD2.3 RDD编程2.3.1 Transformation2.3.2 Action2
SparkCore编程RDD
RDD概述 中文名为弹性分布式数据集,是数据处理基本单位。代表一个弹性的,不可变,可分区,里面的数据可并行计算的集合。 RDD和Hadoop MR 的区别: RDD是先明确数据处理流程,数据在行动算子执行前实际上并未被修改MR本质上是摸石头过河,每一步操作时,数据本体已经被修改了,无法恢复。 RDD特性: 一组分区:标记数据是哪个分区的一个计算每个分区的函数RDD之间的依赖关系一个分区器
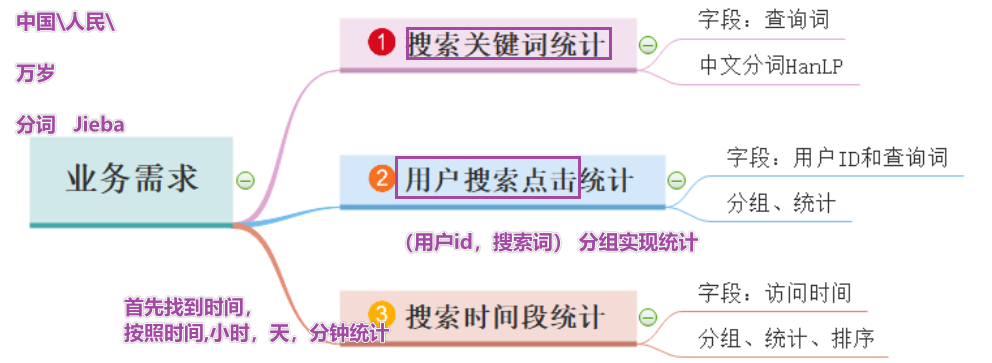
Python大数据之PySpark(七)SparkCore案例
文章目录 SparkCore案例PySpark实现SouGou统计分析 总结后记 SparkCore案例 PySpark实现SouGou统计分析 jieba分词: pip install jieba 从哪里下载pypi 三种分词模式 精确模式,试图将句子最精确地切开,适合文本分析;默认的方式 全模式,把句子中所有的可以成词的词语都扫描出来, 速度非常快,但是不