本文主要是介绍SparkCore(7):SparkOnYarn提交(生产环境),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、实现功能
将spark的wordcount任务提交到Yarn上,然后计算结果输出到hdfs上。
二、实现步骤
1.Wordcount_product代码
package _0722rdd/*** Created by Administrator on 2018/7/16.*/
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}object Wordcount_product {def main(args: Array[String]) {//1/创建sparkconf和spark上下文/**A master URL must be set in your configurationAn application name must be set in your configuration所有的配置文件信息,其实都是在sparkconf当中加载的,所以如果你要设置配置文件的信息的话,conf.set("key","value")*///四步//1.创建sparkContext上下文val conf = new SparkConf()//本地模式,* 会在运行期间检查当前环境下还剩下多少cpu核心,占满
// .setMaster("local[*]") //设定运行位置【否则报错!】.setAppName("idea_start_wc") //设置运行程序名称【否则报错!】val sc = new SparkContext(conf)// 2.读取数据-》形成RDD// 3.数据处理-》RDD->API的调用val colsesceNumInt: Int =Integer.parseInt(conf.get("spark.app.coalesce"))// (1)hdfs文件// 上传到hdfsbin/hdfs dfs -put /opt/modules/spark-2.1.0-bin-2.7.3/README.md /
// val resultRdd: RDD[(String, Int)] = sc.textFile("hdfs://192.168.31.3:8020/README.md")
// val resultRdd: RDD[(String, Int)] = sc.textFile("file:///opt/modules/spark-2.1.0-bin-2.7.3/README.md")val resultRdd: RDD[(String, Int)] = sc.textFile("file:///opt/modules/cdh5.7.0/spark-2.1.0-bin-2.6.0-cdh5.7.0/README.md").flatMap(_.split(" ")).map((_,1)).reduceByKey(_ + _) //到这一步已经实现wc.map(t=>(-t._2,t._1)).sortByKey().map(t=>(t._2,-t._1)) //这一步做排序//repartition coalesce//以上这两个重分区的api有什么区别?.coalesce(colsesceNumInt)// (2)本地文件:从本地项目下的data文件读取word.txt,存储到本地项目下的result/wc文件// val path="data/word.txt"// val savePath=s"result/wc"//4.保存结果-》RDD数据输出保存resultRdd.saveAsTextFile("hdfs://hadoop:8020/sparkrwordcount_20191114")// 打印到控制台// resultRdd.foreachPartition(iter=>iter.foreach(println))//调用线程等待,为了方便去页面上看结果信息Thread.sleep(100000000)//程序终止(通过正常手段关闭程序)sc.stop()}
}
2.打包代码scalaProjectMaven
参考:https://blog.csdn.net/u010886217/article/details/82795047
3.上传到linux (ws-hadoop01)
/opt/project/scalaproject/scalaProjectMaven.jar4.开启
hdfs和yarn
三、测试运行
1.确认类的引用:_0722rdd.Wordcount_product
2.上传jar包到Linux
/opt/project/scalaproject/scalaProjectMaven.jar3.开启hdfs和yarn
4.提交spark任务
date=`date +"%Y%m%d%H%M"`
/opt/modules/cdh5.7.0/spark-2.1.0-bin-2.6.0-cdh5.7.0/bin/spark-submit \
--master yarn \
--deploy-mode client \
--class _0722rdd.Wordcount_product \
--driver-memory 1G \
--driver-cores 1 \
--executor-memory 1G \
--executor-cores 1 \
--num-executors 1 \
--conf spark.app.coalesce=1 \
/opt/project/scalaproject/scalaProjectMaven.jar
注意:--conf spark.app.coalesce=1这个参数为分区数,决定最终写入hdfs上文件的数量。
结果:
19/11/14 17:18:09 INFO YarnSchedulerBackend$YarnSchedulerEndpoint: ApplicationMaster registered as NettyRpcEndpointRef(null)
19/11/14 17:18:09 INFO YarnClientSchedulerBackend: Add WebUI Filter. org.apache.hadoop.yarn.server.webproxy.amfilter.AmIpFilter, Map(PROXY_HOSTS -> hadoop, PROXY_URI_BASES -> http://hadoop:8088/proxy/application_1573707031333_0001), /proxy/application_1573707031333_0001
19/11/14 17:18:09 INFO JettyUtils: Adding filter: org.apache.hadoop.yarn.server.webproxy.amfilter.AmIpFilter
19/11/14 17:18:10 INFO Client: Application report for application_1573707031333_0001 (state: RUNNING)
19/11/14 17:18:10 INFO Client: client token: N/Adiagnostics: N/AApplicationMaster host: 192.168.0.8ApplicationMaster RPC port: 0queue: root.rootstart time: 1573723074065final status: UNDEFINEDtracking URL: http://hadoop:8088/proxy/application_1573707031333_0001/user: root
19/11/14 17:18:10 INFO YarnClientSchedulerBackend: Application application_1573707031333_0001 has started running.
19/11/14 17:18:10 INFO Utils: Successfully started service 'org.apache.spark.network.netty.NettyBlockTransferService' on port 39142.
19/11/14 17:18:10 INFO NettyBlockTransferService: Server created on 192.168.0.8:39142
19/11/14 17:18:10 INFO BlockManager: Using org.apache.spark.storage.RandomBlockReplicationPolicy for block replication policy
19/11/14 17:18:10 INFO BlockManagerMaster: Registering BlockManager BlockManagerId(driver, 192.168.0.8, 39142, None)
19/11/14 17:18:10 INFO BlockManagerMasterEndpoint: Registering block manager 192.168.0.8:39142 with 413.9 MB RAM, BlockManagerId(driver, 192.168.0.8, 39142, None)
19/11/14 17:18:10 INFO BlockManagerMaster: Registered BlockManager BlockManagerId(driver, 192.168.0.8, 39142, None)
19/11/14 17:18:10 INFO BlockManager: Initialized BlockManager: BlockManagerId(driver, 192.168.0.8, 39142, None)
19/11/14 17:18:11 INFO YarnClientSchedulerBackend: SchedulerBackend is ready for scheduling beginning after waiting maxRegisteredResourcesWaitingTime: 30000(ms)
19/11/14 17:18:12 INFO MemoryStore: Block broadcast_0 stored as values in memory (estimated size 264.0 KB, free 413.7 MB)
19/11/14 17:18:13 INFO MemoryStore: Block broadcast_0_piece0 stored as bytes in memory (estimated size 21.3 KB, free 413.6 MB)
19/11/14 17:18:13 INFO BlockManagerInfo: Added broadcast_0_piece0 in memory on 192.168.0.8:39142 (size: 21.3 KB, free: 413.9 MB)
19/11/14 17:18:13 INFO SparkContext: Created broadcast 0 from textFile at Wordcount_product.scala:34
19/11/14 17:18:13 INFO FileInputFormat: Total input paths to process : 1
19/11/14 17:18:14 INFO SparkContext: Starting job: sortByKey at Wordcount_product.scala:36
19/11/14 17:18:14 INFO DAGScheduler: Registering RDD 3 (map at Wordcount_product.scala:35)
19/11/14 17:18:14 INFO DAGScheduler: Got job 0 (sortByKey at Wordcount_product.scala:36) with 2 output partitions
19/11/14 17:18:14 INFO DAGScheduler: Final stage: ResultStage 1 (sortByKey at Wordcount_product.scala:36)
19/11/14 17:18:14 INFO DAGScheduler: Parents of final stage: List(ShuffleMapStage 0)
19/11/14 17:18:14 INFO DAGScheduler: Missing parents: List(ShuffleMapStage 0)
19/11/14 17:18:14 INFO DAGScheduler: Submitting ShuffleMapStage 0 (MapPartitionsRDD[3] at map at Wordcount_product.scala:35), which has no missing parents
19/11/14 17:18:15 INFO MemoryStore: Block broadcast_1 stored as values in memory (estimated size 4.8 KB, free 413.6 MB)
19/11/14 17:18:15 INFO MemoryStore: Block broadcast_1_piece0 stored as bytes in memory (estimated size 2.8 KB, free 413.6 MB)
19/11/14 17:18:15 INFO BlockManagerInfo: Added broadcast_1_piece0 in memory on 192.168.0.8:39142 (size: 2.8 KB, free: 413.9 MB)
19/11/14 17:18:15 INFO SparkContext: Created broadcast 1 from broadcast at DAGScheduler.scala:996
19/11/14 17:18:15 INFO DAGScheduler: Submitting 2 missing tasks from ShuffleMapStage 0 (MapPartitionsRDD[3] at map at Wordcount_product.scala:35)
19/11/14 17:18:15 INFO YarnScheduler: Adding task set 0.0 with 2 tasks
19/11/14 17:18:19 INFO YarnSchedulerBackend$YarnDriverEndpoint: Registered executor NettyRpcEndpointRef(null) (192.168.0.8:51107) with ID 1
19/11/14 17:18:19 INFO TaskSetManager: Starting task 0.0 in stage 0.0 (TID 0, hadoop, executor 1, partition 0, PROCESS_LOCAL, 6079 bytes)
19/11/14 17:18:19 INFO BlockManagerMasterEndpoint: Registering block manager hadoop:38675 with 413.9 MB RAM, BlockManagerId(1, hadoop, 38675, None)
19/11/14 17:18:21 INFO BlockManagerInfo: Added broadcast_1_piece0 in memory on hadoop:38675 (size: 2.8 KB, free: 413.9 MB)
19/11/14 17:18:21 INFO BlockManagerInfo: Added broadcast_0_piece0 in memory on hadoop:38675 (size: 21.3 KB, free: 413.9 MB)
19/11/14 17:18:23 INFO TaskSetManager: Starting task 1.0 in stage 0.0 (TID 1, hadoop, executor 1, partition 1, PROCESS_LOCAL, 6079 bytes)
19/11/14 17:18:23 INFO TaskSetManager: Finished task 0.0 in stage 0.0 (TID 0) in 4730 ms on hadoop (executor 1) (1/2)
19/11/14 17:18:24 INFO TaskSetManager: Finished task 1.0 in stage 0.0 (TID 1) in 309 ms on hadoop (executor 1) (2/2)
19/11/14 17:18:24 INFO YarnScheduler: Removed TaskSet 0.0, whose tasks have all completed, from pool
19/11/14 17:18:24 INFO DAGScheduler: ShuffleMapStage 0 (map at Wordcount_product.scala:35) finished in 8.982 s
19/11/14 17:18:24 INFO DAGScheduler: looking for newly runnable stages
19/11/14 17:18:24 INFO DAGScheduler: running: Set()
19/11/14 17:18:24 INFO DAGScheduler: waiting: Set(ResultStage 1)
19/11/14 17:18:24 INFO DAGScheduler: failed: Set()
19/11/14 17:18:24 INFO DAGScheduler: Submitting ResultStage 1 (MapPartitionsRDD[7] at sortByKey at Wordcount_product.scala:36), which has no missing parents
19/11/14 17:18:24 INFO MemoryStore: Block broadcast_2 stored as values in memory (estimated size 4.1 KB, free 413.6 MB)
19/11/14 17:18:24 INFO MemoryStore: Block broadcast_2_piece0 stored as bytes in memory (estimated size 2.4 KB, free 413.6 MB)
19/11/14 17:18:24 INFO BlockManagerInfo: Added broadcast_2_piece0 in memory on 192.168.0.8:39142 (size: 2.4 KB, free: 413.9 MB)
19/11/14 17:18:24 INFO SparkContext: Created broadcast 2 from broadcast at DAGScheduler.scala:996
19/11/14 17:18:24 INFO DAGScheduler: Submitting 2 missing tasks from ResultStage 1 (MapPartitionsRDD[7] at sortByKey at Wordcount_product.scala:36)
19/11/14 17:18:24 INFO YarnScheduler: Adding task set 1.0 with 2 tasks
19/11/14 17:18:24 INFO TaskSetManager: Starting task 0.0 in stage 1.0 (TID 2, hadoop, executor 1, partition 0, NODE_LOCAL, 5825 bytes)
19/11/14 17:18:24 INFO BlockManagerInfo: Added broadcast_2_piece0 in memory on hadoop:38675 (size: 2.4 KB, free: 413.9 MB)
19/11/14 17:18:24 INFO MapOutputTrackerMasterEndpoint: Asked to send map output locations for shuffle 0 to 192.168.0.8:51107
19/11/14 17:18:24 INFO MapOutputTrackerMaster: Size of output statuses for shuffle 0 is 148 bytes
19/11/14 17:18:24 INFO TaskSetManager: Starting task 1.0 in stage 1.0 (TID 3, hadoop, executor 1, partition 1, NODE_LOCAL, 5825 bytes)
19/11/14 17:18:24 INFO TaskSetManager: Finished task 0.0 in stage 1.0 (TID 2) in 404 ms on hadoop (executor 1) (1/2)
19/11/14 17:18:24 INFO DAGScheduler: ResultStage 1 (sortByKey at Wordcount_product.scala:36) finished in 0.512 s
19/11/14 17:18:24 INFO TaskSetManager: Finished task 1.0 in stage 1.0 (TID 3) in 138 ms on hadoop (executor 1) (2/2)
19/11/14 17:18:24 INFO YarnScheduler: Removed TaskSet 1.0, whose tasks have all completed, from pool
19/11/14 17:18:24 INFO DAGScheduler: Job 0 finished: sortByKey at Wordcount_product.scala:36, took 10.570525 s
19/11/14 17:18:25 INFO BlockManagerInfo: Removed broadcast_2_piece0 on 192.168.0.8:39142 in memory (size: 2.4 KB, free: 413.9 MB)
19/11/14 17:18:25 INFO BlockManagerInfo: Removed broadcast_2_piece0 on hadoop:38675 in memory (size: 2.4 KB, free: 413.9 MB)
19/11/14 17:18:25 INFO deprecation: mapred.tip.id is deprecated. Instead, use mapreduce.task.id
19/11/14 17:18:25 INFO deprecation: mapred.task.id is deprecated. Instead, use mapreduce.task.attempt.id
19/11/14 17:18:25 INFO deprecation: mapred.task.is.map is deprecated. Instead, use mapreduce.task.ismap
19/11/14 17:18:25 INFO deprecation: mapred.task.partition is deprecated. Instead, use mapreduce.task.partition
19/11/14 17:18:25 INFO deprecation: mapred.job.id is deprecated. Instead, use mapreduce.job.id
19/11/14 17:18:25 INFO FileOutputCommitter: File Output Committer Algorithm version is 1
19/11/14 17:18:25 INFO SparkContext: Starting job: saveAsTextFile at Wordcount_product.scala:46
19/11/14 17:18:25 INFO DAGScheduler: Registering RDD 5 (map at Wordcount_product.scala:36)
19/11/14 17:18:25 INFO DAGScheduler: Got job 1 (saveAsTextFile at Wordcount_product.scala:46) with 1 output partitions
19/11/14 17:18:25 INFO DAGScheduler: Final stage: ResultStage 4 (saveAsTextFile at Wordcount_product.scala:46)
19/11/14 17:18:25 INFO DAGScheduler: Parents of final stage: List(ShuffleMapStage 3)
19/11/14 17:18:25 INFO DAGScheduler: Missing parents: List(ShuffleMapStage 3)
19/11/14 17:18:25 INFO DAGScheduler: Submitting ShuffleMapStage 3 (MapPartitionsRDD[5] at map at Wordcount_product.scala:36), which has no missing parents
19/11/14 17:18:25 INFO MemoryStore: Block broadcast_3 stored as values in memory (estimated size 4.0 KB, free 413.6 MB)
19/11/14 17:18:25 INFO MemoryStore: Block broadcast_3_piece0 stored as bytes in memory (estimated size 2.4 KB, free 413.6 MB)
19/11/14 17:18:25 INFO BlockManagerInfo: Added broadcast_3_piece0 in memory on 192.168.0.8:39142 (size: 2.4 KB, free: 413.9 MB)
19/11/14 17:18:25 INFO SparkContext: Created broadcast 3 from broadcast at DAGScheduler.scala:996
19/11/14 17:18:25 INFO DAGScheduler: Submitting 2 missing tasks from ShuffleMapStage 3 (MapPartitionsRDD[5] at map at Wordcount_product.scala:36)
19/11/14 17:18:25 INFO YarnScheduler: Adding task set 3.0 with 2 tasks
19/11/14 17:18:25 INFO TaskSetManager: Starting task 0.0 in stage 3.0 (TID 4, hadoop, executor 1, partition 0, NODE_LOCAL, 5820 bytes)
19/11/14 17:18:25 INFO BlockManagerInfo: Added broadcast_3_piece0 in memory on hadoop:38675 (size: 2.4 KB, free: 413.9 MB)
19/11/14 17:18:25 INFO TaskSetManager: Starting task 1.0 in stage 3.0 (TID 5, hadoop, executor 1, partition 1, NODE_LOCAL, 5820 bytes)
19/11/14 17:18:25 INFO TaskSetManager: Finished task 0.0 in stage 3.0 (TID 4) in 158 ms on hadoop (executor 1) (1/2)
19/11/14 17:18:25 INFO TaskSetManager: Finished task 1.0 in stage 3.0 (TID 5) in 137 ms on hadoop (executor 1) (2/2)
19/11/14 17:18:25 INFO YarnScheduler: Removed TaskSet 3.0, whose tasks have all completed, from pool
19/11/14 17:18:25 INFO DAGScheduler: ShuffleMapStage 3 (map at Wordcount_product.scala:36) finished in 0.290 s
19/11/14 17:18:25 INFO DAGScheduler: looking for newly runnable stages
19/11/14 17:18:25 INFO DAGScheduler: running: Set()
19/11/14 17:18:25 INFO DAGScheduler: waiting: Set(ResultStage 4)
19/11/14 17:18:25 INFO DAGScheduler: failed: Set()
19/11/14 17:18:25 INFO DAGScheduler: Submitting ResultStage 4 (MapPartitionsRDD[11] at saveAsTextFile at Wordcount_product.scala:46), which has no missing parents
19/11/14 17:18:25 INFO MemoryStore: Block broadcast_4 stored as values in memory (estimated size 69.3 KB, free 413.6 MB)
19/11/14 17:18:25 INFO MemoryStore: Block broadcast_4_piece0 stored as bytes in memory (estimated size 25.4 KB, free 413.5 MB)
19/11/14 17:18:25 INFO BlockManagerInfo: Added broadcast_4_piece0 in memory on 192.168.0.8:39142 (size: 25.4 KB, free: 413.9 MB)
19/11/14 17:18:25 INFO SparkContext: Created broadcast 4 from broadcast at DAGScheduler.scala:996
19/11/14 17:18:25 INFO DAGScheduler: Submitting 1 missing tasks from ResultStage 4 (MapPartitionsRDD[11] at saveAsTextFile at Wordcount_product.scala:46)
19/11/14 17:18:25 INFO YarnScheduler: Adding task set 4.0 with 1 tasks
19/11/14 17:18:25 INFO TaskSetManager: Starting task 0.0 in stage 4.0 (TID 6, hadoop, executor 1, partition 0, NODE_LOCAL, 6125 bytes)
19/11/14 17:18:25 INFO BlockManagerInfo: Added broadcast_4_piece0 in memory on hadoop:38675 (size: 25.4 KB, free: 413.9 MB)
19/11/14 17:18:26 INFO MapOutputTrackerMasterEndpoint: Asked to send map output locations for shuffle 1 to 192.168.0.8:51107
19/11/14 17:18:26 INFO MapOutputTrackerMaster: Size of output statuses for shuffle 1 is 145 bytes
19/11/14 17:18:26 INFO DAGScheduler: ResultStage 4 (saveAsTextFile at Wordcount_product.scala:46) finished in 1.070 s
19/11/14 17:18:26 INFO DAGScheduler: Job 1 finished: saveAsTextFile at Wordcount_product.scala:46, took 1.484781 s
19/11/14 17:18:26 INFO TaskSetManager: Finished task 0.0 in stage 4.0 (TID 6) in 1070 ms on hadoop (executor 1) (1/1)
19/11/14 17:18:26 INFO YarnScheduler: Removed TaskSet 4.0, whose tasks have all completed, from pool 5.Hadoop验证
(1)hdfs上结果

(2)yarn的任务
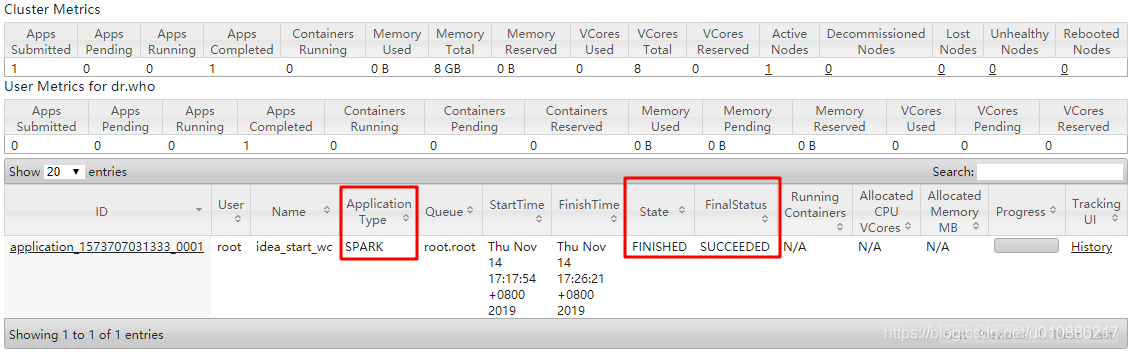
(经测试成功~)
这篇关于SparkCore(7):SparkOnYarn提交(生产环境)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









