本文主要是介绍SparkCore(13):TopN算法,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1.实现功能
针对数据,进行排序选取TopN的数据。
2.数据
aa 78
bb 98
aa 80
cc 98
aa 69
cc 87
bb 97
cc 86
aa 97
bb 78
bb 34
cc 85
bb 92
cc 72
bb 32
bb 233.代码
3.1 SparkUtil
package SparkUtilimport org.apache.spark.{SparkConf, SparkContext}/*** Created by ibf on 2018/7/18.*/
object SparkUtil {def createSparkContext(isLocal:Boolean,appName:String): SparkContext ={if(isLocal) {val conf = new SparkConf().setAppName(appName).setMaster("local[2]")val sc = SparkContext.getOrCreate(conf)val ssc=SparkContext.getOrCreate(conf)sc}else{val conf = new SparkConf().setAppName(appName)val sc = SparkContext.getOrCreate(conf)sc}}}
3.2 GroupSortTopN
package _0722rdd
import SparkUtil.SparkUtil
import org.apache.spark.rdd.RDD
/*** Created by Administrator on 2018/7/22.*/
object GroupSortTopN {def main(args: Array[String]): Unit = {val sc = SparkUtil.createSparkContext(true,"GroupSortTopN")// linux上:val inputPathfile:///opt/datas/groupsort.txtval inputPath="datas/groupsort.txt"val rdd=sc.textFile(inputPath,1)val N=3//方法一/*(aa,List(78, 80, 97))(bb,List(92, 97, 98))(cc,List(86, 87, 98))*/val resultRdd1: RDD[(String, List[Int])] =rdd.map(_.split(" ")).filter(arr=>{arr.length==2}).map(t=>(t(0),t(1).toInt)).groupByKey().map({case(key,itr)=>{//应该是asc(key,itr.toList.sorted.takeRight(N))//下面的是降序排序***
// (key,itr.toList.sortWith((a,b)=>a>b).takeRight(N))}})resultRdd1.foreach(println)//方法二/*(aa,78)(bb, 98)(cc,98)*/val resultRdd2=rdd.map(_.split(" ")).filter(arr=>{arr.length==2}).map(t=>(t(0),t(1).toInt)).groupByKey().flatMap({case(key,itr)=>{//应该是ascval ite=itr.toList.sorted.takeRight(3)ite.map(it=>(key,it))}})resultRdd2.foreach(println)}
}
(1)按照降序排序的方法
(key,itr.toList.sortWith((a,b)=>a>b).takeRight(N))(2)方法一和方法二的区别是返回值是集合还是单个元组
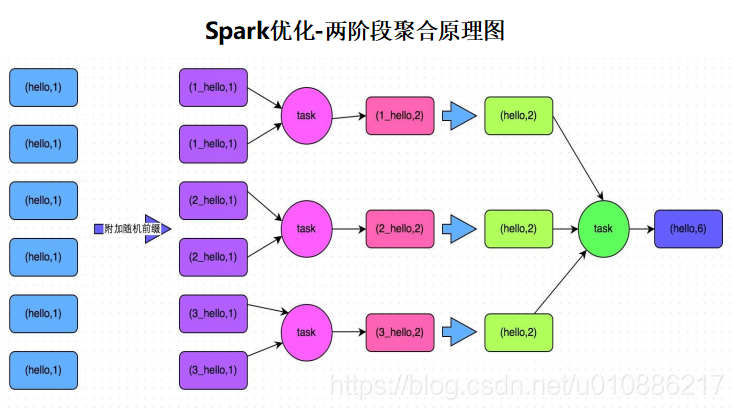
4.优化groupByKey可能导致的数据倾斜
(1)适用场景:对RDD进行分组操作的时候,某些Task处理数据过多或者产生OOM内存溢出异常等情况
(2)实现思路:第一阶段给每个key加一个随机数,然后进行局部的聚合操作;第二阶段去除每个key的前缀,然后进行全局的聚合操作
(3)实现原理:将key添加随机前缀的方式可以让一个key变成多个key,可以让原 本被一个task处理的数据分布到多个task上去进行局部的聚合,进而解决单个task处理数据太多的问题;随后去掉前缀,进行全局集合,完成功能的实现
(4)优缺点:对于聚合类shuffle操作(groupByKey、reduceByKey等)产生的问题 能够很好的解决;但是对于非聚合类shuffle操作( join等)产生的问题很难使用 该方式解决
(5)原理图
这篇关于SparkCore(13):TopN算法的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








