scikit专题

机器学习-有监督学习-分类算法:最大熵模型【迭代过程计算量巨大,实际应用比较难;scikit-learn甚至都没有最大熵模型对应的类库】
最大熵模型(maximum entropy model, MaxEnt)也是很典型的分类算法了。 它和逻辑回归类似,都是属于对数线性分类模型。在损失函数优化的过程中,使用了和支持向量机类似的凸优化技术。而对熵的使用,让我们想起了决策树算法中的ID3和C4.5算法。 理解了最大熵模型,对逻辑回归,支持向量机以及决策树算法都会加深理解。本文就对最大熵模型的原理做一个小结。 一、熵和条件熵 熵

生信机器学习入门3 - Scikit-Learn训练机器学习分类感知器
1. 在线读取iris数据集 import osimport pandas as pd# 下载try:s = 'https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data'print('From URL:', s)df = pd.read_csv(s,header=None,encoding='utf-8'

分类学习-支持向量机(Scikit-learn)
手写体数字识别 1、手写体数据读取 from sklearn.datasets import load_digitsdigits = load_digits() #获得的手写体数据图片存储在digits变量中print(digits.data.shape) 2、数据分割 from sklearn.cross_validation import train_te
【实战教程】用scikit-learn玩转KNN:鸢尾花数据集的分类之旅
KNN(K-Nearest Neighbors)算法是一种简单直观的监督学习算法,被广泛应用于分类和回归任务中。本文将带你一步步了解如何使用Python中的scikit-learn库实现KNN算法,并通过鸢尾花数据集来进行实战演练。让我们一起探索如何用KNN算法对鸢尾花进行分类吧! 1. 准备工作 首先,我们需要安装必要的库。如果你还没有安装scikit-learn,可以通过以下命令进行安

Scikit中使用Grid_Search来获取模型的最佳参数
1. grid search是用来寻找模型的最佳参数 先导入一些依赖包 from sklearn.ensemble import GradientBoostingClassifierfrom sklearn.grid_search import GridSearchCVfrom sklearn import metricsimport numnpy as npimport pandas

Scikit-learn之Cross_Validation
1. Cross Validation是用来进行交叉验证 先导入一些依赖包 from sklearn.ensemble import GradientBoostingClassifierfrom sklearn.cross_validation import cross_val_scorefrom sklearn import metricsimport numnpy as npimp
scikit-learn中常见的train test split
1. train_test_split 进行一次性划分 import numpy as npfrom sklearn.model_selection import train_test_splitX, y = np.arange(10).reshape((5, 2)), range(5)"""X: array([[0, 1],[2, 3],[4, 5],[6, 7],[8, 9]])l
【Python】处理 scikit-learn 中的 SettingWithCopyWarning
那年夏天我和你躲在 这一大片宁静的海 直到后来我们都还在 对这个世界充满期待 今年冬天你已经不在 我的心空出了一块 很高兴遇见你 让我终究明白 回忆比真实精彩 🎵 王心凌《那年夏天宁静的海》 这不是一个错误,而是一个 SettingWithCopyWarning 警告。这个警告在你尝试修改一个从 DataFrame 的切片(子集)上创建的副本时
【Python】处理 scikit-learn 中的 FutureWarning
那年夏天我和你躲在 这一大片宁静的海 直到后来我们都还在 对这个世界充满期待 今年冬天你已经不在 我的心空出了一块 很高兴遇见你 让我终究明白 回忆比真实精彩 🎵 王心凌《那年夏天宁静的海》 在数据科学和机器学习领域,scikit-learn 是一个非常流行的库,用于构建和评估各种机器学习模型。然而,随着版本的更新,库中的某些模块和功能可能会被
Scikit-learn学习笔记(一)
Scikit-learn学习笔记(一) 这段时间在学习机器学习相关的知识,一方面要学习理论知识,另一方面还要不断的练习和实践,只有不断的实践才能真正地掌握和理解这些理论知识。在众多编程语言中,python具有独特的优势,也是机器学习领域使用最多的语言之一,因为其语法简洁、可移植性好以及快速迭代的优势,使其成为机器学习各种算法实现的最佳载体之一,scikit-learn是python版的机
scikit-image安装报错
scikit-image安装报错: pip install scikit-image==0.21.0 报错信息: Collecting PyWavelets>=1.1.1 (from scikit-image==0.21.0) Installing build dependencies … error error: subprocess-exited-with-error 解决方法: 提前安装

Scikit-Learn支持向量机回归
Scikit-Learn支持向量机回归 1、支持向量机回归1.1、最大间隔与SVM的分类1.2、软间隔最大化1.3、支持向量机回归1.4、支持向量机回归的优缺点 2、Scikit-Learn支持向量机回归2.1、Scikit-Learn支持向量机回归API2.2、支持向量机回归初体验2.3、支持向量机回归实践(加州房价预测) 1、支持向量机回归 支持向量机(Sup

【scikit-learn入门指南】:机器学习从零开始
1. 简介 scikit-learn是一款用于数据挖掘和数据分析的简单高效的工具,基于NumPy、SciPy和Matplotlib构建。它能够进行各种机器学习任务,如分类、回归和聚类。 2. 安装scikit-learn 在开始使用scikit-learn之前,需要确保已经安装了scikit-learn库。可以使用以下命令安装: pip install scikit-learn 3
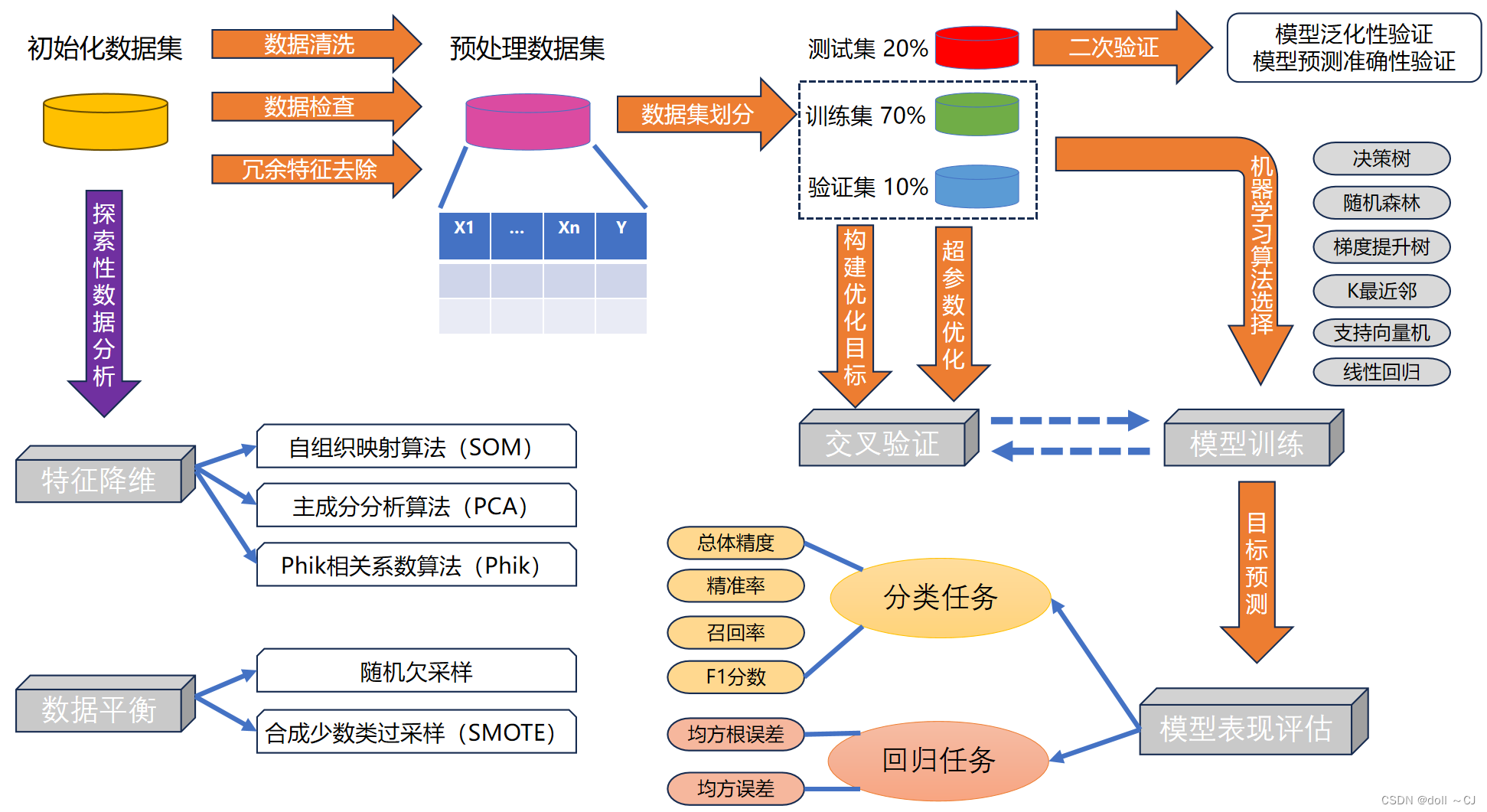
基于scikit-learn的机器学习分类任务实践——集成学习
一、传统机器学习分类流程与经典思想算法简述 传统机器学习是指,利用线性代数、数理统计与优化算法等数学方式从设计获取的数据集中构建预测学习器,进而对未知数据分类或回归。其主要流程大致可分为七个部分,依次为设计获取数据特征集(特征构造和特征提取)、探索性地对数据质量分析评价、数据预处理、数据集划分、机器学习算法建模(学习器选择、特征筛选与参数调优)、任务选择(分类或回归)和精度评价与

掌握机器学习基础:Scikit-Learn(sklearn)入门指南
Scikit-Learn(sklearn)是Python中一个非常受欢迎的机器学习库,它提供了各种用于数据挖掘和数据分析的算法。以下是Scikit-Learn的入门指南,以帮助您掌握机器学习的基础知识。 1. 简介 定义:Scikit-Learn是一个基于Python的开源机器学习库,它建立在NumPy、SciPy、Pandas和Matplotlib等库之上。功能:它涵盖了几乎所有主流机器学习
sklearn(Scikit-learn)入门学习教程
sklearn(Scikit-learn)是一个功能强大的Python机器学习库,它提供了丰富的工具和方法,用于数据挖掘、数据分析和预测建模。以下是一个关于sklearn的清晰教程,涵盖了其主要特点和功能: 1. sklearn简介 定义:sklearn是Python中常用的机器学习库,它封装了多种机器学习算法,包括分类、回归、聚类、降维等。特点: 简单高效的数据挖掘和数据分析工具。允许用户在
Scikit-learn 基础教程:机器学习的初步指南
Scikit-learn 是一个用于数据挖掘和数据分析的机器学习库,建立在 NumPy、SciPy 和 matplotlib 之上。它提供了简单而高效的工具来进行数据分析和建模。本文将为您介绍 Scikit-learn 的安装方法、核心组件,以及如何应用这些组件进行一个简单的机器学习项目。 1. 安装 Scikit-learn 安装 Scikit-learn 非常简单,您可以使用 pip 进行
Scikit-learn使用步骤?使用场景?
Scikit-learn(简称sklearn)是Python中一个非常流行的机器学习库,它提供了广泛的机器学习算法和工具,用于数据分析、特征工程、模型训练、模型评估等任务。以下是一个关于sklearn的基础教程,内容将按照几个主要部分进行分点表示和归纳: 1. 简介 sklearn是什么:Scikit-learn(sklearn)是一个基于Python的开源机器学习库,建立在NumPy、Sci
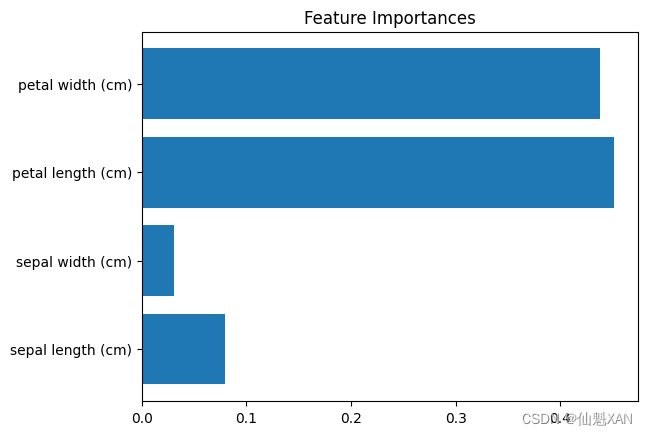
Python 机器学习 基础 之 【常用机器学习库】 scikit-learn 机器学习库
Python 机器学习 基础 之 【常用机器学习库】 scikit-learn 机器学习库 目录 Python 机器学习 基础 之 【常用机器学习库】 scikit-learn 机器学习库 一、简单介绍 二、scikit-learn 基础 1、安装 scikit-learn 2、导入 scikit-learn 3、数据准备 4、数据分割 5、训练模型 5.1 线性回归 5

跟我一起学scikit-learn21:PCA算法
PCA算法全称是Principal Component Analysis,即主成分分析算法。它是一种维数约减(Dimensionality Reduction)算法,即把高维度数据在损失最小的情况下转换为低维度数据的算法。显然,PCA可以用来对数据进行压缩,可以在可控的失真范围内提高运算速度。 1.PCA算法原理 我们先从最简单的情况谈起。假设需要把一个二维数据降维成一维数据,要怎么做呢?如下

跟我一起学scikit-learn20:朴素贝叶斯算法
朴素贝叶斯(Naive Bayers)算法是一种基于概率统计的分类方法。它在条件独立假设的基础上,使用贝叶斯定理构建算法,在文本处理领域有广泛的应用。 1.朴素贝叶斯算法原理 朴素贝叶斯算法,需要从贝叶斯定理说起,它是一个条件概率公式。 1.贝叶斯定理 先来看一个案例。某警察使用一个假冒伪劣的呼吸测试仪来测试司机是否醉驾。假设这个仪器有5%的概率会把一个正常的司机判断为醉驾,但对真正醉驾的

跟我一起学scikit-learn19:支持向量机算法
支持向量机(SVM,Support Vector Machine)算法是一种常见的分类算法,在工业界和学术界都有广泛的应用。特别是针对数据集较小的情况下,往往其分类效果比神经网络好。 1.SVM算法原理 SVM的原理就是使用分隔超平面来划分数据集,并使得支持向量(数据集中离分隔超平面最近的点)到该分隔超平面的距离最大。其最大特点是能构造出最大间距的决策边界,从而提高分类算法的鲁棒性。 1.大

跟我一起学scikit-learn17:逻辑回归算法
逻辑回归算法的名字虽然带有“回归”二字,但实际上逻辑回归算法是用来解决分类问题的算法。本章首先从二元分类入手,介绍了逻辑回归算法的预测函数、成本函数和梯度下降算法公式;然后介绍了怎样由二元分类延伸至多元分类的问题;接着介绍了正则化,即通过模型的手段来解决模型的过拟合问题;针对正则化,介绍了L1范数和L2范数的含义及区别;最后用一个乳腺癌检测的实例及其模型性能优化来结束本章内容。 1.逻辑回归算法

跟我一起学scikit-learn16:线性回归算法
线性回归算法是使用线性方程对数据集拟合得算法,是一个非常常见的回归算法。本章首先从最简单的单变量线性回归算法开始介绍,然后介绍了多变量线性回归算法,其中成本函数以及梯度下降算法的推导过程会用到部分线性代数和偏导数;接着重点介绍了梯度下降算法的求解步骤以及性能优化方面的内容;最后通过一个房价预测模型,介绍了线性回归算法性能优化的一些常用步骤和方法。 1.单变量线性回归算法 我们先考虑最简单的单变

跟我一起学scikit-learn15:K-近邻算法
KNN(K-Nearest Neighbor,K-近邻算法)算法是一种有监督的机器学习算法,可以解决分类问题,也可以解决回归问题。 1.KNN算法原理 K-近邻算法的核心思想是未标记样本的类别,由距离其最近的K个邻居投票来决定。 假设,我们有一个已经标记的数据集,即已经知道了数据集中每个样本所属的类别。此时,有一个未标记的数据样本,我们的任务是预测出这个数据样本所属的类别。K-近邻算法的原理

Scikit-Learn随机森林分类
Scikit-Learn随机森林分类 1、随机森林分类1.1、随机森林分类概述1.2、随机森林分类的优缺点 2、Scikit-Learn随机森林分类2.1、Scikit-Learn随机森林分类API2.2、Scikit-Learn随机森林分类初体验(葡萄酒分类)2.3、Scikit-Learn随机森林分类实践(鸢尾花分类)2.4、参数调优与选择 1、随机森林分类