pooling专题

Convolutional layers/Pooling layers/Dense Layer 卷积层/池化层/稠密层
Convolutional layers/Pooling layers/Dense Layer 卷积层/池化层/稠密层 Convolutional layers 卷积层 Convolutional layers, which apply a specified number of convolution filters to the image. For each subregion, the

C++卷积神经网络实例:tiny_cnn代码详解(6)——average_pooling_layer层结构类分析
在之前的博文中我们着重分析了convolutional_layer类的代码结构,在这篇博文中分析对应的下采样层average_pooling_layer类: 一、下采样层的作用 下采样层的作用理论上来说由两个,主要是降维,其次是提高一点特征的鲁棒性。在LeNet-5模型中,每一个卷积层后面都跟着一个下采样层: 原因就是当图像在经过卷积层之后,由于每个卷积层都有多个卷积

HBase Connection Pooling
两种方法获得连接: Configuration configuration = HBaseConfiguration.create(); ExecutorService executor = Executors.newFixedThreadPool(nPoolSize); (1)旧API中: Connection connection = HConnectionManag

一文彻底搞懂CNN - 卷积和池化(Convolution And Pooling)
Convolutional Neural Network CNN(卷积神经网络)最核心的两大操作就是卷积(Convolution)和池化(Pooling)。卷积用于特征提取,通过卷积核在输入数据上滑动计算加权和;池化用于特征降维,通过聚合统计池化窗口内的元素来减少数据空间大小。 Convolution And Pooling 一、_卷积(Convolution) 卷积(Convol

CV-笔记-重读Fast R-CNN的ROI pooling
目录 1 原图上的ROI坐标如何映射到feature map上?2 ROI Pooling是如何做?3 ROI Pooling的梯度反向传播是怎么做的?4 那么多的ROI Pooling做完以后是怎么进入到全连接层进行训练的?5 正负样本怎么制作?6 loss怎么计算?smooth L1 7回归的数值是什么?引用 Fast R-CNN主要是使用了一个ROI Pooling操作来对候

pytorch--Pooling layers
文章目录 1.torch.nn.MaxPool1d()2.torch.nn.MaxPool2d3.torch.nn.AvgPool2d()4.torch.nn.FractionalMaxPool2d()5.torch.nn.AdaptiveMaxPool2d()6.torch.nn.AdaptiveAvgPool2d() 1.torch.nn.MaxPool1d() t

【池化方法】——strip pooling
转载自:AI算法修炼营 论文链接:https://arxiv.org/abs/2003.13328v1 代码链接:https://github.com/Andrew-Qibin/SPNet 1. 前言 提高卷积神经网络中远程依赖关系建模能力的一种方法是采用self-attention机制或non-local模块。然而,它们会消耗大量内存。 具体文章可以关注:视觉注意力机制:self-a
【深度学习】之 卷积(Convolution2D)、最大池化(Max Pooling)和 Dropout 的NumPy实现
1. 2D 卷积操作 import numpy as npdef conv2d(image, kernel, stride=1, padding=0):"""应用2D卷积操作到输入图像上。参数:- image: 输入图像,2D数组。- kernel: 卷积核,2D数组。- stride: 卷积步幅。- padding: 图像周围的零填充数量。返回值:- output: 卷积操作的结果。"""#

PARTICULAR OBJECT RETRIEVAL WITH INTEGRAL MAX-POOLING OF CNN ACTIVATIONS阅读笔记
不久前看到一篇paper,感觉效果虽然不是特别好,但是对于图像检索和目标识别的后续工作特别有启发意义,所以大致记录一下阅读笔记,以此激励自己学习。 近年来,基于CNN的图像表征已经为图像检索提供了很有效的描述子,超越了很多由预训练CNN模型的到的短向量表示。然而这些方法和模型不适用于几何感知重排,仍然会被一些依赖于精确的特征匹配,几何重排或者查询扩展的传统图像检索所超越。所以本文的工作利用CNN

理解CNN参数及PyTorch实例,卷积核kernel,层数Channels,步长Stride,填充Padding,池化Pooling,PyTorch中的相关方法,MNIST例子
1.34.理解CNN参数及PyTorch实例 1.34.1.卷积核kernel 1.34.2.层数Channels 1.34.3.步长Stride 1.34.4.填充Padding 1.34.5.池化Pooling 1.34.6.PyTorch中的相关方法 1.34.7.MNIST例子 1.34.理解CNN参数及PyTorch实例 参考地址:http://guileen.github.io/2

CNN中难点分析--对卷积层(Convolution)与池化层(Pooling)的理解
传统机器学习通过特征工程提取特征,作为Input参数进行输入,从而拟合一个相对合适的w参数,而CNN利用卷积层感知局部特征,然后更高层次对局部进行综合操作,从而得到全局信息,池化层层提取主要特征,从而自动提取特征。 1、池化层的理解 pooling池化的作用则体现在降采样:保留显著特征、降低特征维度,增大kernel的感受野。另外一点值得注意:pooling也可以提供一些旋转不变性。 池化

【论文快读】Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
链接:https://arxiv.org/abs/1406.4729 作者:Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun 摘要: SPP可以用于: 1.大幅提高各种cnn的性能: 现有网络对输入图片的size要求一定,这种“人工设定”可能对accuracy造成影响。本文提出的SPP-net则是“input size/scale free”的
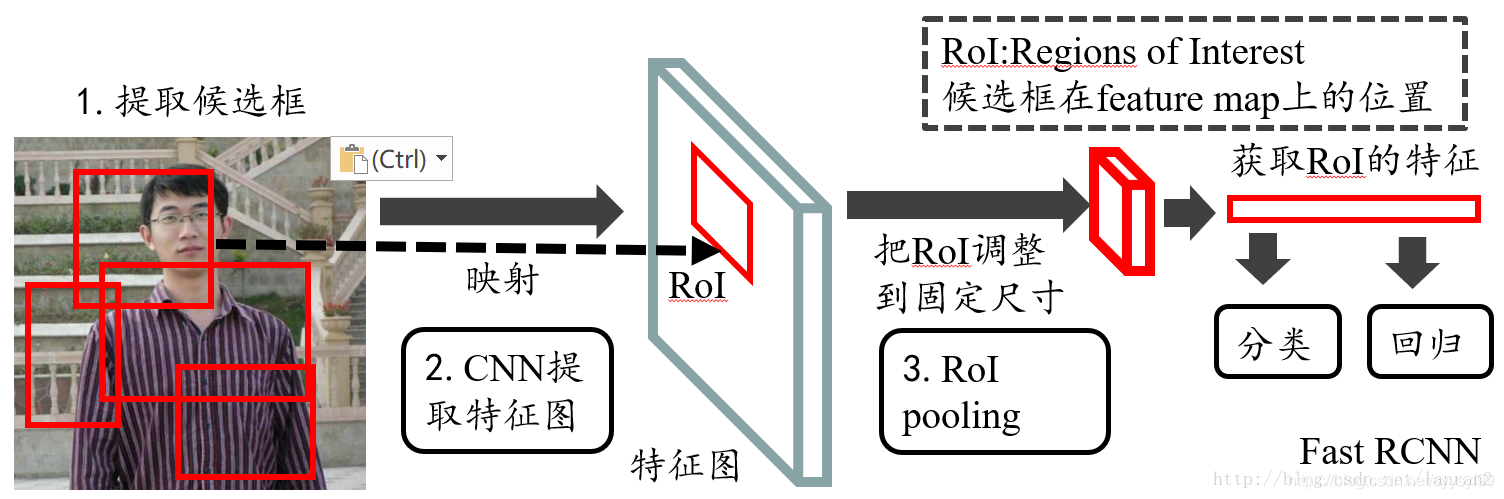
目标检测之ROI Pooling层解析
参考: 1 2 ROIs Pooling是Pooling层的一种,特点是输入特征图尺寸不固定,但是输出特征层尺寸固定。 ROI即region of interests,指的是特征图上的框。 在fast rcnn中,roi是指的是selective search完成之后得到的候选框在特征图上的映射。如下图: 而在faster rcnn中是在rpn之后产生的,然后再把各个候选框映射到特征图

Faster RCNN源码解读4-其他收尾工作:ROI_pooling、分类、回归等
Faster RCNN复现 Faster RCNN源码解读1-整体流程和各个子流程梳理 Faster RCNN源码解读2-_anchor_component()为图像建立anchors(核心和关键1) Faster RCNN源码解读3.1-_region_proposal() 筛选anchors-_proposal_layer()(核心和关键2) Faster RCNN源码解读3.2-_r

深度学习方法(十):卷积神经网络结构变化——Maxout Networks,Network In Network,Global Average Pooling
欢迎转载,转载请注明:本文出自Bin的专栏blog.csdn.net/xbinworld。 技术交流QQ群:433250724,欢迎对算法、技术感兴趣的同学加入。 最近接下来几篇博文会回到神经网络结构的讨论上来,前面我在“深度学习方法(五):卷积神经网络CNN经典模型整理Lenet,Alexnet,Googlenet,VGG,Deep Residual Learning”一文中介绍了经

关于Global average Pooling
看了几个典型网络似乎最后都有这一层Global average Pooling,相关说明转载自 https://blog.csdn.net/williamyi96/article/details/77530995 https://blog.csdn.net/losteng/article/details/51520555
max pooling 和 average pooling
采样: pooling 也叫subsample。采样是一个特征选择的过程。 如果不采样,则可能存在: overfitting参数过多,导致运算量大无法满足模型结构需求 池化层的特性: 它可以一定程度提高空间不变性(特征相对位置),比如说平移不变性,尺度不变性,形变不变性 特征提取的误差来源: 领域大小受限卷积层权值参数误差 average pooling 和max-pooling
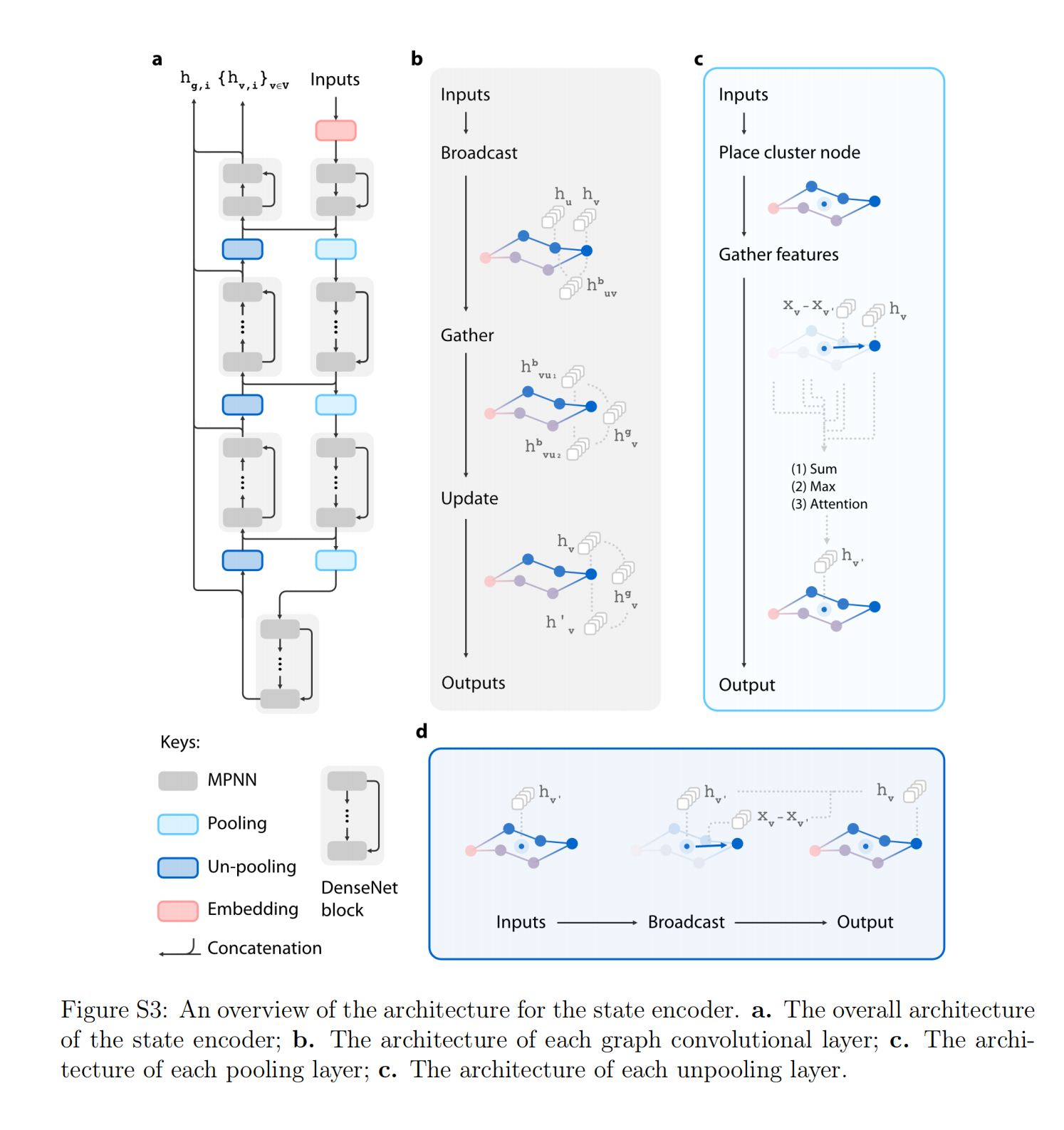
MPNN(Message Passing Neural Network)、graph pooling 、unpooling
The state encoder is mainly composed of MPNN layers organized into DenseNet blocks, which use graph pooling and unpooling layers (see Section S1.5†) to reduce the memory cost during training.

A Simple Pooling-Based Design for Real-Time Salient Object Detection
一种基于简单池化的实时显着目标检测——PoolNet(解读)(原论文) 摘要 通过研究如何扩展卷积神经网络中池化部分来解决显着目标检测问题。 网络基于U形结构,贡献有: 首先在自下而上的路径上构建全局引导模块(GGM),旨在为不同特征层提供潜在显着对象的位置信息。设计了一个特征聚合模块(FAM),使粗级语义信息与自上而下的路径中的精细级别特征完美融合。 通过在自上而下路径中的融合操作

k-max pooling实现
使用theano实现k-max pooling,github上目前还没有找到theano的实现,自己就写了一个简单的,仿照的是keras issues里面的一个提交。由于theano在反向bp时能够自动处理array index的变化,因此本质上是很简单的。 def k_max_pooling2d(data, k):output = data[T.arange(data.shape[0]).di

Pooling layers
整理并翻译自吴恩达深度学习系列视频:卷积神经网络1.9 Pooling layers Other than convolutional layers, ConvNets often use pooling layers to reduce the size of their representation to speed up computation, as well as to ma
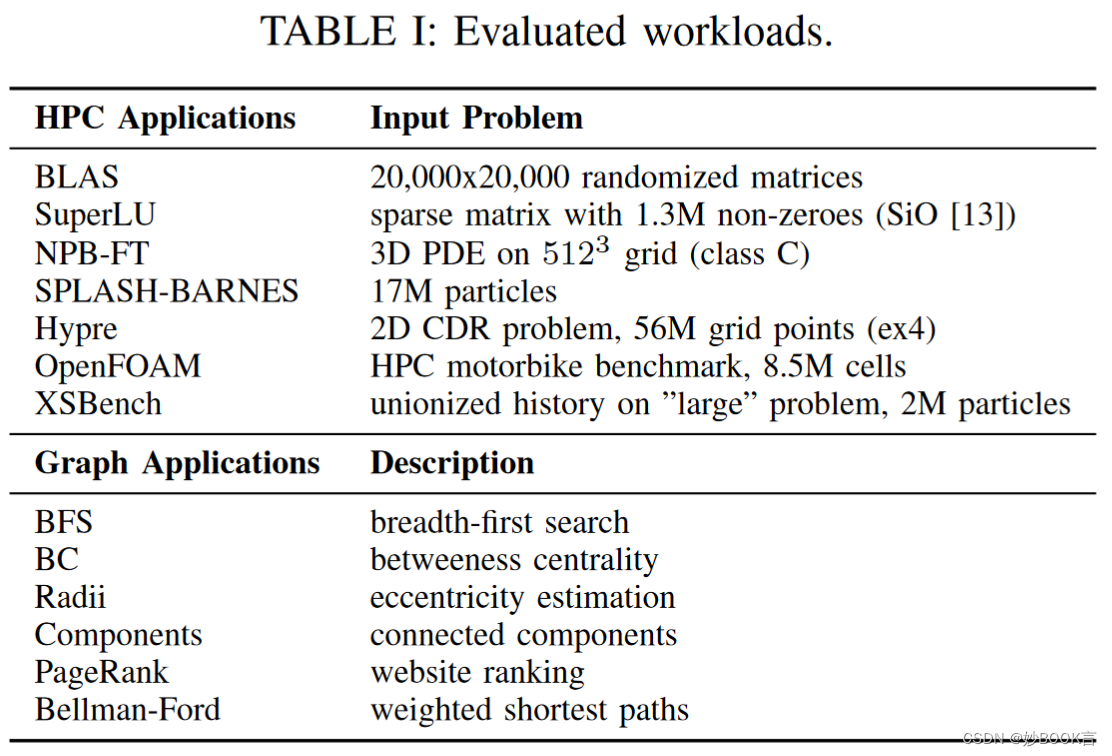
Evaluating Emerging CXL-enabled Memory Pooling for HPC Systems——论文泛读
MCHPC@SC 2022 Paper CXL论文阅读汇总 问题 当前的高性能计算(HPC)系统提供的内存资源是静态配置的,并与计算节点紧密耦合。然而,HPC系统上的工作负载正在演变。多样化的工作负载导致对可配置内存资源的需求,以实现高性能和高利用率。 现有方法局限性 CXL是用于互连处理器、加速器和内存的开放标准。符合CXL标准的硬件提供了对应用程序代码透明的低延迟、高带宽数据访问。一些
J2EE Database Connection Pooling -连接池
http://www.primrose.org.uk 主页 下载地址: http://www.primrose.org.uk/download.jsp In order to run primrose, you need the primrose.jar file, a configuration file, and supporting JMX files. Several downlo
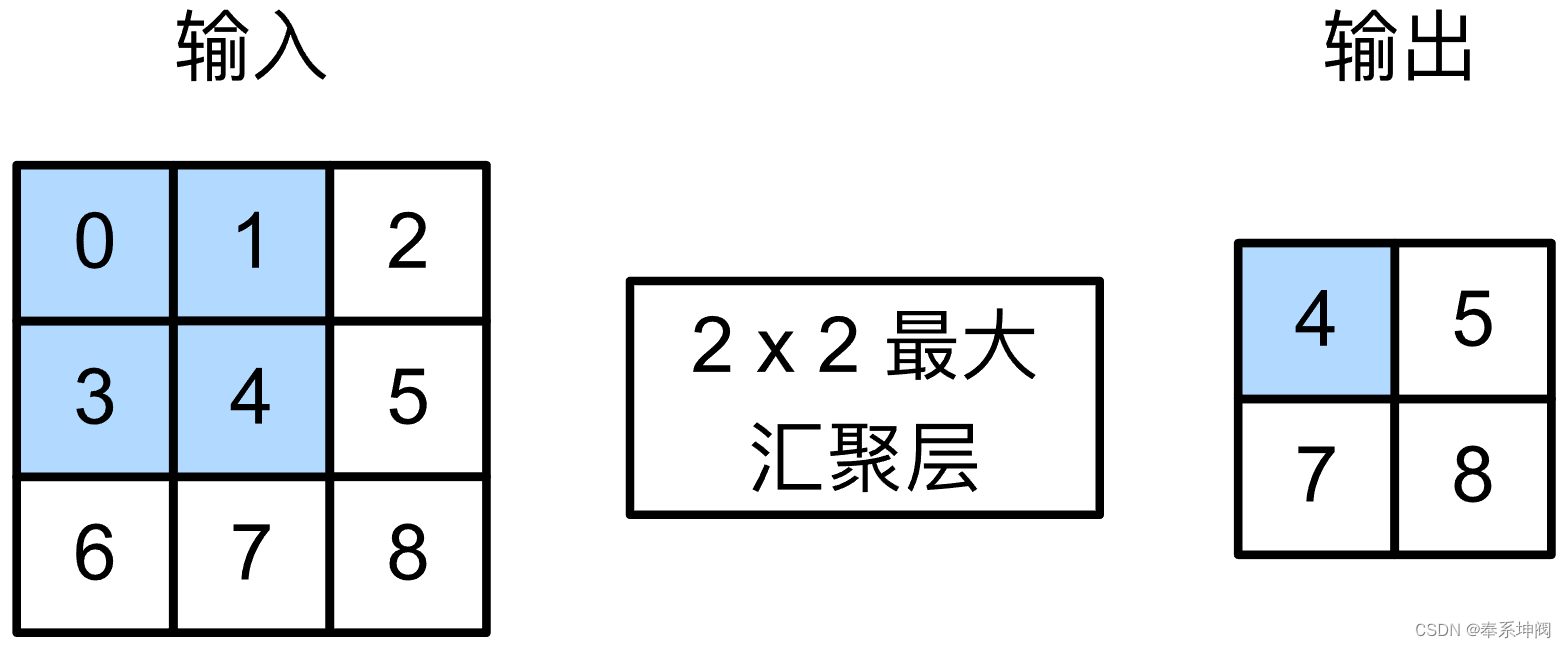
池化层(pooling)
目录 一、池化层 1、最大池化层 2、平均池化层 3、总结 二、代码实现 1、最大池化与平均池化 2、填充和步幅(padding和strides) 3、多个通道 4、总结 一、池化层 1、最大池化层 2、平均池化层 3、总结 池化层返回窗口中最大或平均值环节卷积层对位置的敏感性同样有窗口大小、填充和步幅作为超参数 二、代码实现

池化总结(OverlappingPooling、 一般池化、Spatial Pyramid Pooling)
池化方法总结(Pooling) 在卷积神经网络中,我们经常会碰到池化操作,而池化层往往在卷积层后面,通过池化来降低卷积层输出的特征向量,同时改善结果(不易出现过拟合)。 为什么可以通过降低维度呢? 因为图像具有一种“静态性”的属性,这也就意味着在一个图像区域有用的特征极有可能在另一个区域同样适用。因此,为了描述大的图像,一个很自然的想法就是对不同位置的特征进行聚合统计,例如,人们可以计算图像
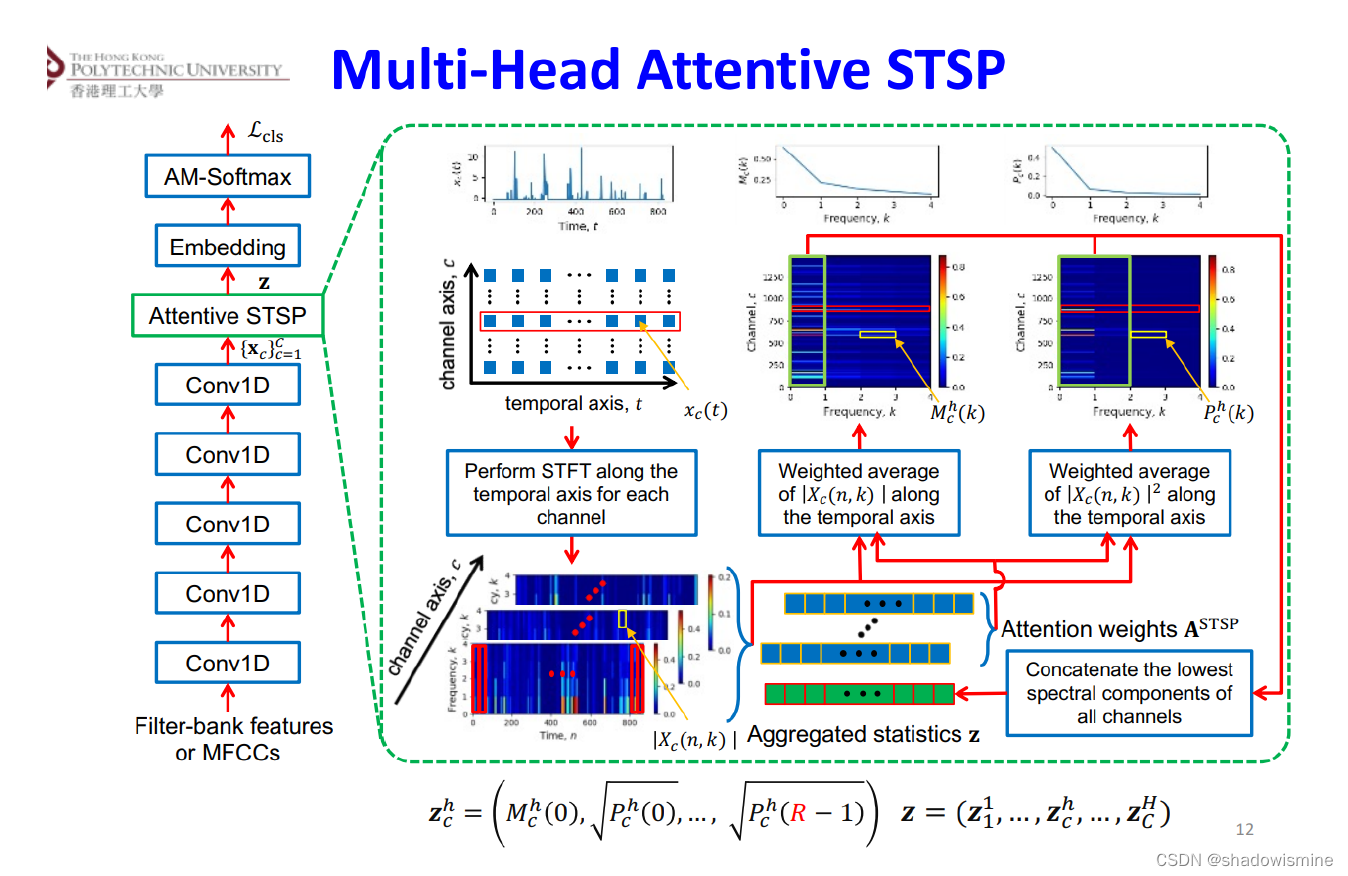
Pooling方法总结(语音识别)
Pooling layer将变长的frame-level features转换为一个定长的向量。 1. Statistics Pooling 链接:http://danielpovey.com/files/2017_interspeech_embeddings.pdf The default pooling method for x-vector is statistics poolin