paddleocr专题

使用百度飞桨PaddleOCR进行OCR识别
1、代码及文档 代码:https://github.com/PaddlePaddle/PaddleOCR?tab=readme-ov-file 介绍文档:https://paddlepaddle.github.io/PaddleOCR/ppocr/overview.html 2、依赖安装 在使用过程中需要安装库,可以依据代码运行过程中的提示安装。我使用的为python3.7,安装库为:

PaddleOCR 实现车牌识别----利用PaddleOCR训练车牌识别数据_未完待续
1.下载CCPD数据集 去网址 https://aistudio.baidu.com/aistudio/datasetdetail/17968 下载CCPD数据集并解压。 2. 参考文献: PaddleOCR训练自己的数据集 https://blog.csdn.net/u013171226/article/details/115179480 PaddleOCR

PaddleOCR删除部分log的打印
Question 一段非常简单的调用代码,如图。 from paddleocr import PaddleOCRimport cv2ocr = PaddleOCR(use_angle_cls=False, use_gpu=False)img = cv2.imread('test.jpg')result = ocr.ocr('test.jpg', cls=False) 但是控制台里面却是

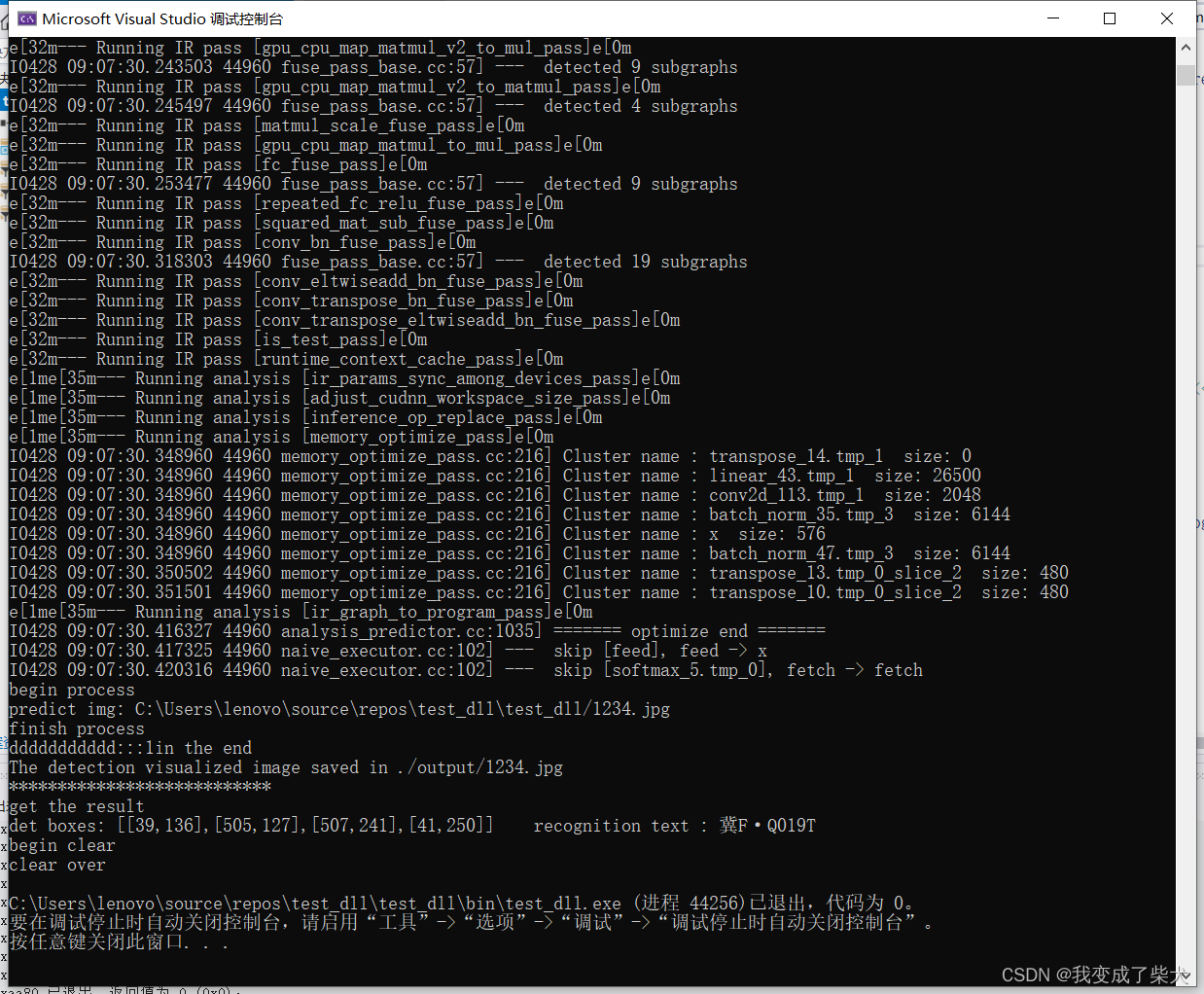
PaddleOCR打包exe--Pyinstaller
一、前期准备 首先确保代码在虚拟环境中能够成功运行, gui.py from paddleocr import PaddleOCR# 模型路径下必须含有model和params文件ocr = PaddleOCR(det_model_dir = './inference/default_det_model_dir/', # 检测模型所在文件夹rec_model_dir = './infere
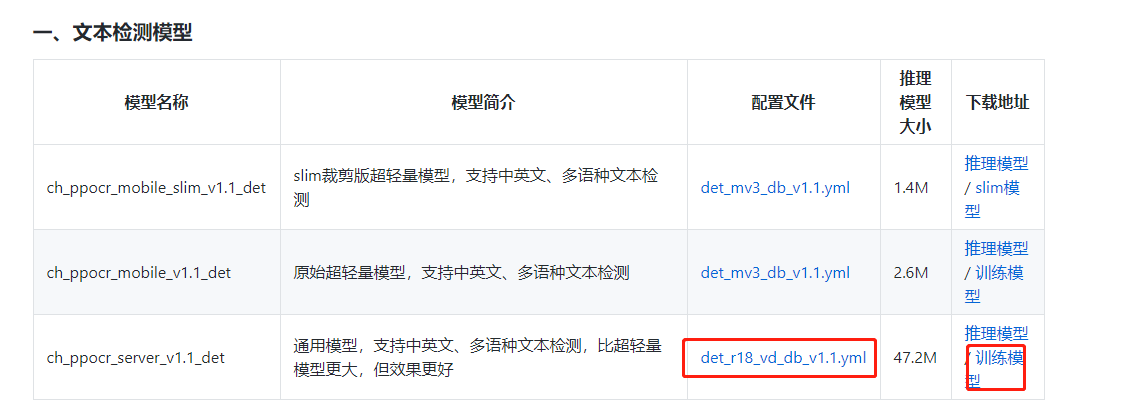
基于PaddleOCR提供的训练模型进行文本检测训练
首先我先讲下为什么要基于官方提供的训练模型进行训练: (1)基于基础算法模型库的训练模型,需要自己基于很多数据进行训练才能得到一个好的效果,如果数据量少了就会出现预测效果不好的情况。 (2)PaddleOCR提供的训练模型和预训练模型已经是基于一定的数据量训练出来的模型。训练模型是基于预训练模型在真实数据与竖排合成文本数据上finetune得到的模型,在真实应用场景中有着更好的表现,预训练模型
基于国产飞腾2000制作的paddleocr hubserving服务docker镜像文件
目录导航 paddleocr hubserving国产化飞腾、鲲鹏armv8 api服务镜像制作 一、编译paddle 二、准备Dockerfile文件 三、制作paddleocr hubserving服务镜像 四、paddleocr hubserving镜像导出和导入 paddleocr hubserving国产化飞腾、鲲鹏armv8 api服务镜像制作

Paddleocr数据增强调用逻辑
数据增强调用逻辑 以在ppocr/data/simple_dataset.py为例: get_ext_data通过self.ops[:self.ext_op_transform_idx]获取配置文件中数据增强 self.ops在def __init__(self, config, mode, logger, seed=None):中通过解析配置文件中'transforms'内容获取数据增强
PaddleOCR 快速开始
1. 安装 1.1 安装PaddlePaddle # GPU cudapip install paddlepaddle-gpu# CPUpip install paddlepaddle 1.2 安装PaddleOCR whl包 pip install paddleocr 2. 便捷使用 2.1 命令行使用 2.1.1 中英文模型 检测+方向分类器+识别全流程:–use_a
<Python><paddleocr>基于python使用百度paddleocr实现图片文字识别与替换
前言 本文是使用百度的开源库paddleocr来实现对图片文字的识别,准确度还不错,对图片文字的替换,则利用opencv来完成。 环境配置 系统:windows 平台:visual studio code 语言:python 库:paddleocr、opencv、pyqt5 依赖库安装 本例所需要的库可以直接用pip来安装。 安装opencv: pip install opencv-pyth
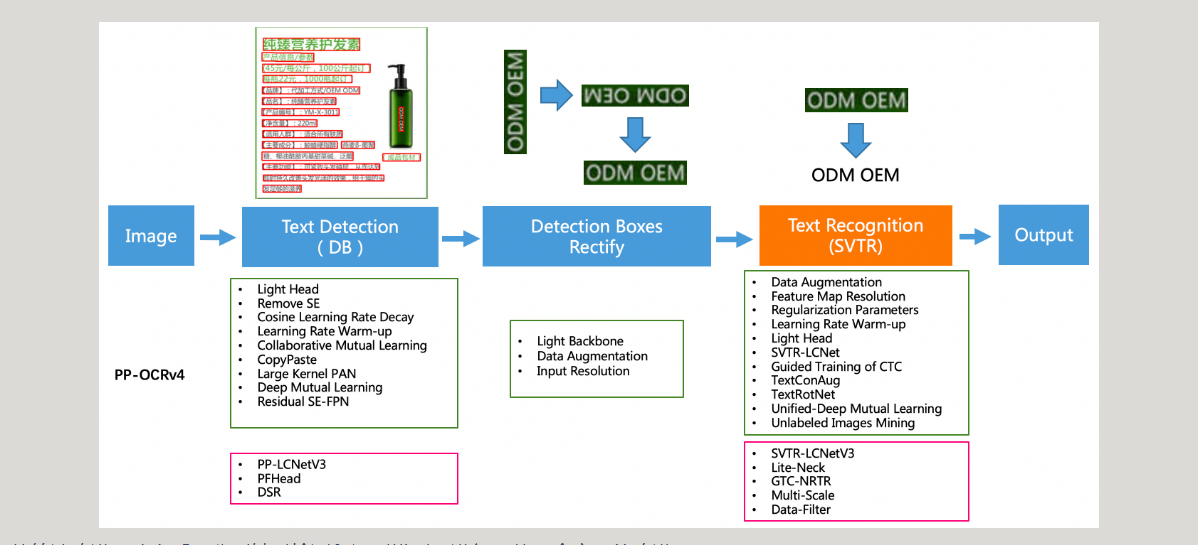
PaddleOCR学习——PP-OCR系列
相关知识前置: PP-LCNet PP-LCNetV3 PP-LCNetV3系列模型是PP-LCNet系列模型的延续,覆盖了更大的精度范围,能够适应不同下游任务的需要。PP-LCNetV3系列模型从多个方面进行了优化,提出了可学习仿射变换模块,对重参数化策略、激活函数进行了改进,同时调整了网络深度与宽度。最终,PP-LCNetV3系列模型能够在性能与效率之间达到最佳的平衡,在不同精度范围
<Python><报错>python安装paddleocr时报错“no module patch_ng”如何解决?
前言 python安装paddleocr时报错“no module patch_ng”的解决办法。 错误信息 在使用python安装paddleocr时,可能会遇到一下错误: Collecting lmdb (from paddleocr>=2.0.1)Using cached lmdb-1.4.1.tar.gz (881 kB)Preparing metadata (setup.py) .

【OCR】——paddleocr.srn安装与测试
1. 环境 这里新建了一个conda环境用于测试,官方推荐采用docker # 1. 新建conda环境conda create -n paddleocr python==3.7# 2. 安装paddle1.7.2python3 -m pip install paddlepaddle-gpu==1.7.2.post107 -i https://pypi.tuna.tsinghua.edu.
pyinstall 打包 paddleocr 成为.exe文件步骤
一、首先进入虚拟环境 使用pip安装pyinstaller pip install pyinstaller我的已经安装完成 二、用cmd进入当前打包文件夹下,新建使spec文件内容如下 注意:其中需要修改的部分是pathex中文件所在路径文件内容摘抄自另一篇博文(❄点击可查看❄) # -*- mode: python ; coding: utf-8 -*-a = Analysis(['te

【教程】PaddleOCR高精度文字识别
转载请注明出处:小锋学长生活大爆炸[xfxuezhagn.cn] 如果本文帮助到了你,欢迎[点赞、收藏、关注]哦~ PaddleOCR/doc/doc_ch/quickstart.md at main · PaddlePaddle/PaddleOCR · GitHub 安装 pip install paddlepaddle -i https://mirror.baidu.c
2. C++ 编译 paddleocr 识别库编译
参考: https://blog.csdn.net/qq_37735796/article/details/108015905 参考上述仁兄教程, 不过 VS2017+CMAKE 就可以, OPENCV4 也可以, 不一定需要配置 OPENCV3 和 VS2019 git clone https://github.com/PaddlePaddle/PaddleOCRcd PaddleOCR\d
PaddleOCR_PP-Structure
静态IP设置 # 修改网卡配置文件vim /etc/sysconfig/network-scripts/ifcfg-ens33# 修改文件内容TYPE=EthernetPROXY_METHOD=noneBROWSER_ONLY=noBOOTPROTO=staticIPADDR=192.168.15.132NETMASK=255.255.255.0GATEWAY=192.168.1
paddleocr C++生成dll
目录 编译完成后修改内容: 新建ppocr.h头文件 注释掉main.cpp内全部内容,将下面内容替换进去。ppocr.h需要再环境配置中包含进去头文件 然后更改配置信息,将exe换成dll 随后右击重新编译会在根目录生成dll,lib文件。 注意这些dll一个也不能少。生成dll后,重新在vs中新建一个C++项目 内容如下: 相关的配置如下: 需要更改输出目录,添加连接器,并
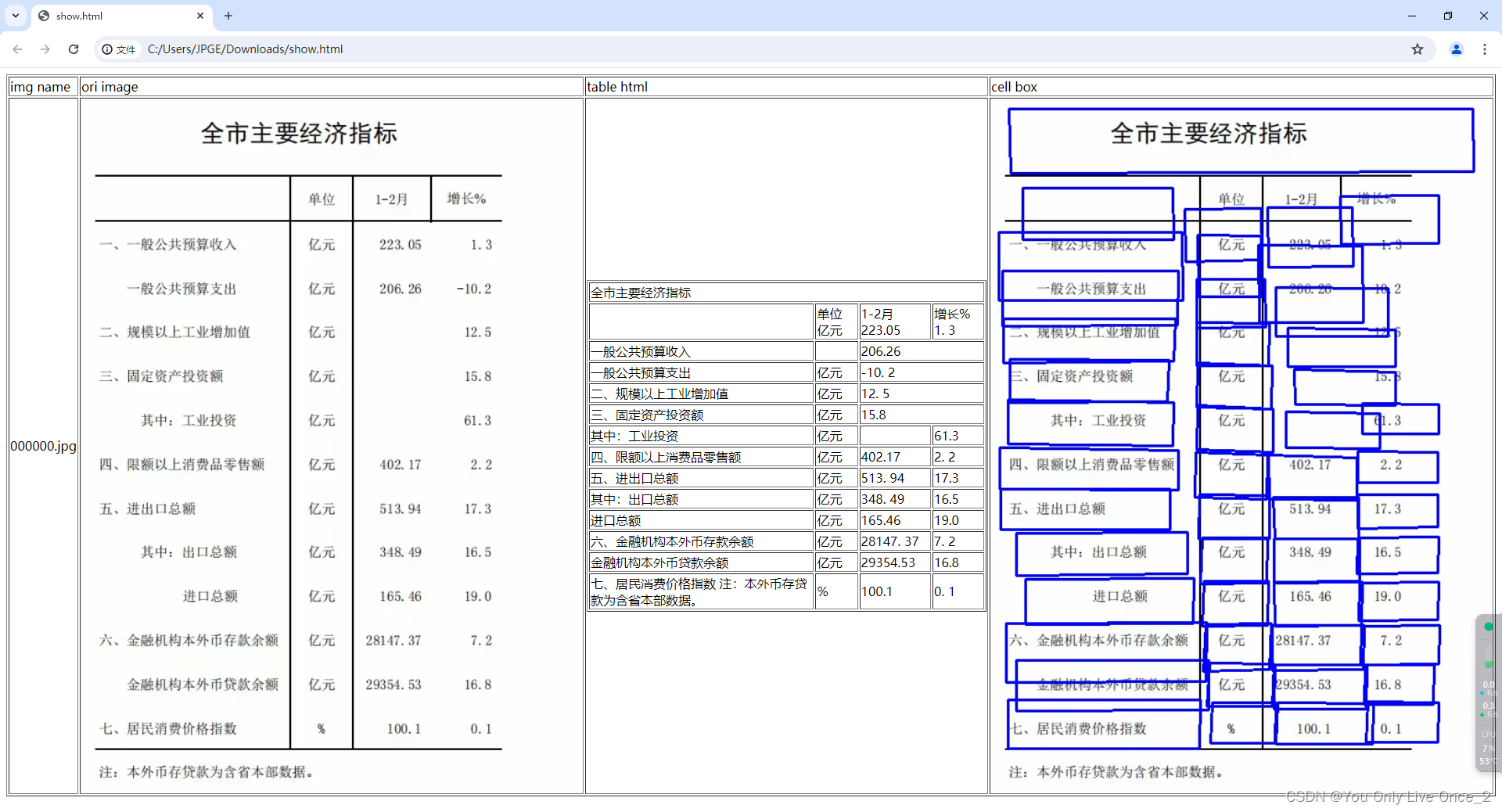
PaddleOCR训练自己的模型(3)-----模型推理
(1)Det模型推理: 打开infer_det.py文件, 配置运行参数(配置方法在上一篇文章有) -c../configs/det/ch_PP-OCRv4/ch_PP-OCRv4_det_student.yml-oGlobal.pretrained_model=../output/ch_PP-OCRv4/best_accuracy.pdparamsGlobal.infer_img="
PaddleOCR 图片日期识别
目录 一 . 获取图片信息种对应坐标区域日期信息 (类型为1:http链接 类型为 2本地图片路径) 二 . ocr图片识别日期信息获取,调用获取图片区域相应位置方法 三 . 如有所需获取rtsp流回放格式 四 . 完整代码如下 (路径可根据自己实际需求替换) 当今数字化的时代,我们经常需要从图像中提取信息,以便进行后续的处理和分析。其中,日期 信息作为一种重要的
windows系统搭建OCR半自动标注工具PaddleOCR
深度学习 文章目录 深度学习前言一、环境搭建准备方式1:安装Anaconda搭建1. Anaconda下载地址: [点击](https://mirrors.tuna.tsinghua.edu.cn/anaconda/archive/?C=M&O=D)2. 创建新的conda环境 方式2. 直接安装python 二、安装CPU版本1. 安装PaddlePaddle2、安装PaddleOC

PaddleOCR-2.1.1集成到opencv项目,在C#中调用
一、下载这3个 https://github.91chifun.workers.dev//https://github.com/PaddlePaddle/PaddleOCR/archive/refs/tags/v2.1.1.zip https://paddle-wheel.bj.bcebos.com/2.0.2/win-infer/mkl/cpu/paddle_inference.zip
![PaddleOCR识别框架解读[19] 文本方向分类器--从训练到部署全流程](https://img-blog.csdnimg.cn/direct/7b6d4e96054c4c2fa22d35153335ad04.jpeg#pic_center)
PaddleOCR识别框架解读[19] 文本方向分类器--从训练到部署全流程
文章目录 1. 方法介绍2. 数据准备3. 启动训练4. 训练5. 评估6. 预测 1. 方法介绍 文本方向分类器主要用于图片非0度的场景下,在这种场景下需要对图片里检测到的文本行进行一个转正的操作。在PaddleOCR系统内,文本检测之后得到的文本行图片经过仿射变换之后送入识别模型,此时只需要对文本进行一个0和180度的角度分类,因此PaddleOCR内置的文本方向分类器只支持
【项目】YOLOv5+PaddleOCR实现艺术字验证码识别
YOLOv5+PaddleOCR实现艺术字类验证码识别 一、引言1.1 实现目标1.2 人手动点选验证码逻辑1.3 计算机点选逻辑 二、计算机验证方法2.1 PaddleOCR下方文字识别方法2.2 YOLOv5目标检测方法2.3 艺术字分类方法2.4 返回结果 三、代码获取 一、引言 1.1 实现目标 要识别的验证码类型如下图所示: 1.2 人手动点选验证码逻辑 以我们
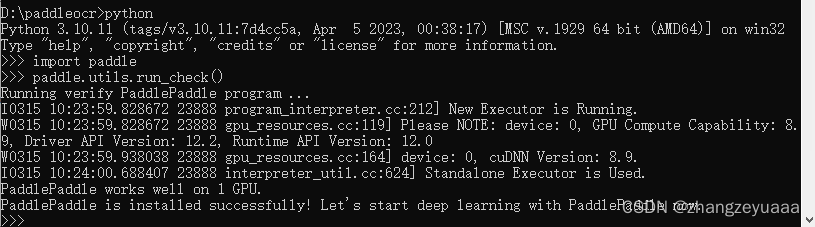
百度paddleocr GPU版部署
显卡:NVIDIA GeForce RTX 4070,Nvidia驱动程序版本:537.13 Nvidia驱动程序能支持的最高cuda版本:12.2.138 Python:python3.10.11。试过python3.12,安装paddleocr失败,找不到相关模块。 飞桨版本:2.6,操作系统:windows 10,安装方式:pip,计算平台:CUDA12.0(飞桨2.6最高支持
PaddleOCR识别框架解读[18] 文本识别rec_loss MultiLoss
文章目录 MultiLossCTCLossSARLoss def build_loss(config):support_dict = ['DBLoss', 'PSELoss', 'EASTLoss', 'SASTLoss', <

使用PaddleOCR做车牌识别
由于车牌检测可选的方法有很多, 可以使用yolov7, paddledetection,也可以直接用paddleocr的det训练检测模型. 这里只处理识别的任务. 使用的图片如下: 训练列表: 图片和字符标签TAB隔开, 多个车牌用空格隔开, 最后空格+颜色符号 车牌颜色对应符号:(更多颜色只需要新增符号映射即可) 模型配置文件: 选用ch_PP-OCRv3_rec