本文主要是介绍使用PaddleOCR做车牌识别,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
由于车牌检测可选的方法有很多, 可以使用yolov7, paddledetection,也可以直接用paddleocr的det训练检测模型. 这里只处理识别的任务.
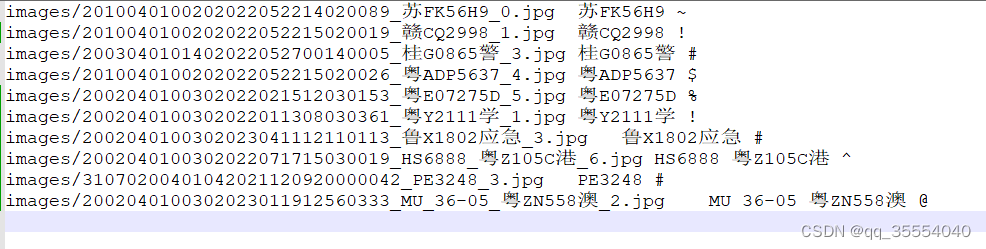
使用的图片如下:

训练列表:
图片和字符标签TAB隔开, 多个车牌用空格隔开, 最后空格+颜色符号
车牌颜色对应符号:(更多颜色只需要新增符号映射即可)

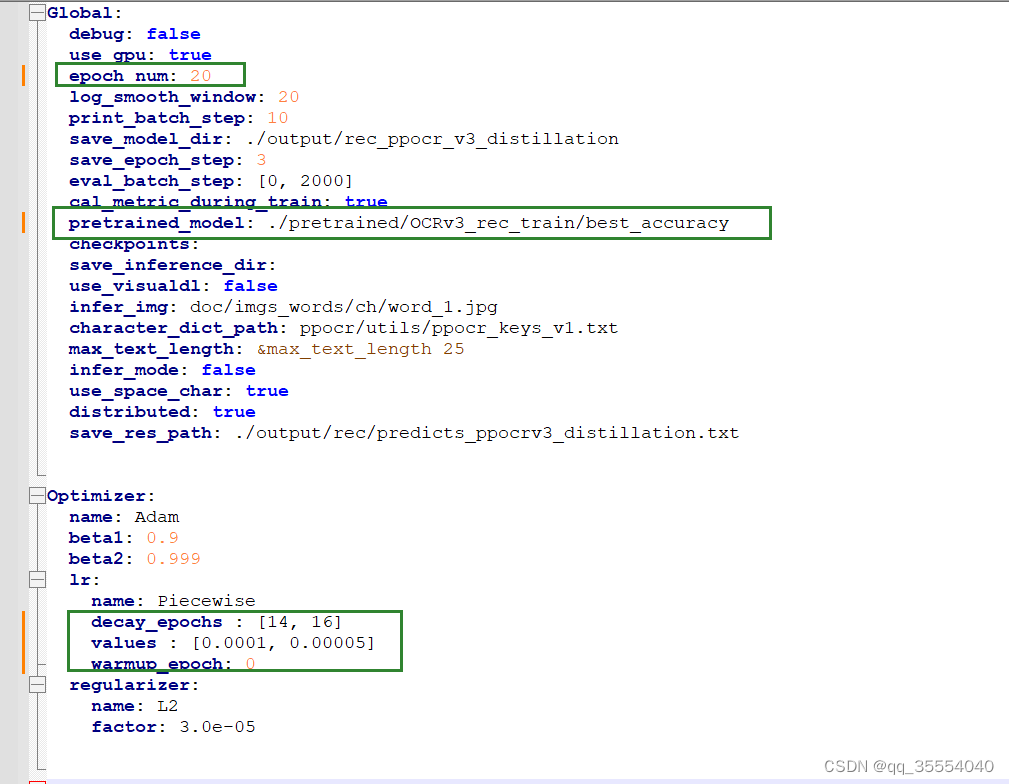
模型配置文件: 选用ch_PP-OCRv3_rec_distillation.yml
这里使用预训练模型, 注意要使用预训练对应的字典,可以更快收敛.
调整批次和学习率.
测试情况: (使用Intel(R) Core(TM) i3-1115G4 @ 3.00GHz, onnxruntime推理)

总结:
1. 能够识别多行文字.
2. 通过符号关联颜色, 可以一次识别出字符和颜色.
3. 训练和部署都十分简单, 识别速度快.
这篇关于使用PaddleOCR做车牌识别的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






