本文主要是介绍基于PaddleOCR提供的训练模型进行文本检测训练,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
首先我先讲下为什么要基于官方提供的训练模型进行训练:
(1)基于基础算法模型库的训练模型,需要自己基于很多数据进行训练才能得到一个好的效果,如果数据量少了就会出现预测效果不好的情况。
(2)PaddleOCR提供的训练模型和预训练模型已经是基于一定的数据量训练出来的模型。训练模型是基于预训练模型在真实数据与竖排合成文本数据上finetune得到的模型,在真实应用场景中有着更好的表现,预训练模型则是直接基于全量真实数据与合成数据训练得到,更适合用于在自己的数据集上finetune。
一、基于PaddleOCR提供的文本检测模型进行预测效果演示
1、下载文本检测模型
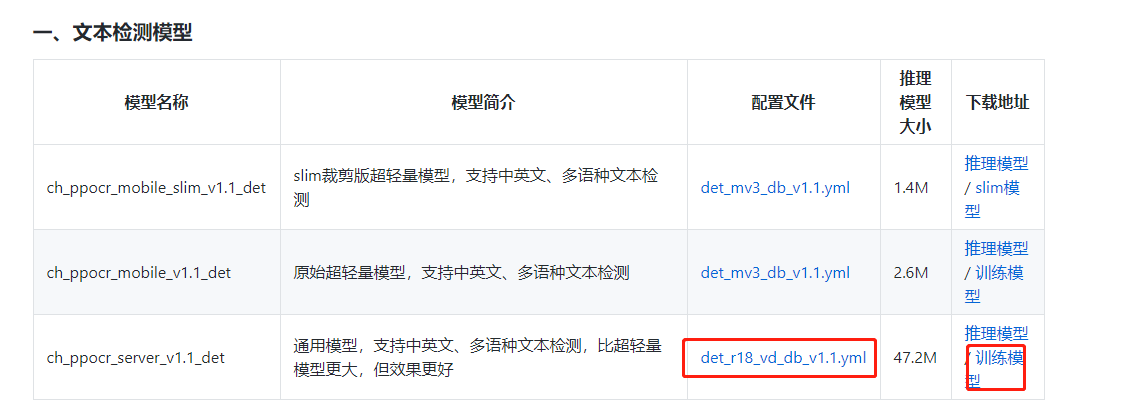
我下载的是ch_ppocr_server_v1.1.det
2、解压到./pretrain_models
sudo tar -xf ch_ppocr_server_v1.1_det_train.tar3、测试预测效果
sudo python tools/infer_det.py -c configs/det_det_r18_vd_db_v1.1.yml -o TestReader.infer_img="test_ocr.jpg" Global.checkpoints="./pretrain_models/ch_ppocr_server_v1.1_det_train/best_accuracy"这篇关于基于PaddleOCR提供的训练模型进行文本检测训练的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






