opencompass专题
OpenCompass:大模型测评工具
大模型相关目录 大模型,包括部署微调prompt/Agent应用开发、知识库增强、数据库增强、知识图谱增强、自然语言处理、多模态等大模型应用开发内容 从0起步,扬帆起航。 大模型应用向开发路径:AI代理工作流大模型应用开发实用开源项目汇总大模型问答项目问答性能评估方法大模型数据侧总结大模型token等基本概念及参数和内存的关系大模型应用开发-华为大模型生态规划从零开始的LLaMA-Factor

【InternLM实战营第二期笔记】07:OpenCompass :是骡子是马,拉出来溜溜
文章目录 课程实操 课程 评测的意义是什么呢?我最近也在想。看到这节开头的内容后忽然有个顿悟:如果大模型最终也会变成一种基础工具(类比软件),稳定或可预期的效果需要先于用户感知构建出来,评测 case 就需要变成用例的相对充分抽样。 除了提高效率本身,最近还有一个很好的工作 MixEval,把标准、静态的 benchmarks 跟 elo 表现做了充分关联,使得只测试少量

Opencompass模型评测教程
模型评测 模型评测非常关键,目前主流的方法主要可以概括为主观评测和客观评测,主观评测又可以分为两种形式:人工判断或者和模型竞技场。客观评测一般采用评测数据集的形式进行模型评测。本教程使用Opencompass工具进行对Internlm2-7b模型进行评测。 算力平台 本教程在OpenBayes上进行实验,主要的原因在于Openbayes平台可以很方便地使用自定义的数据集。没有注册的用户可以使
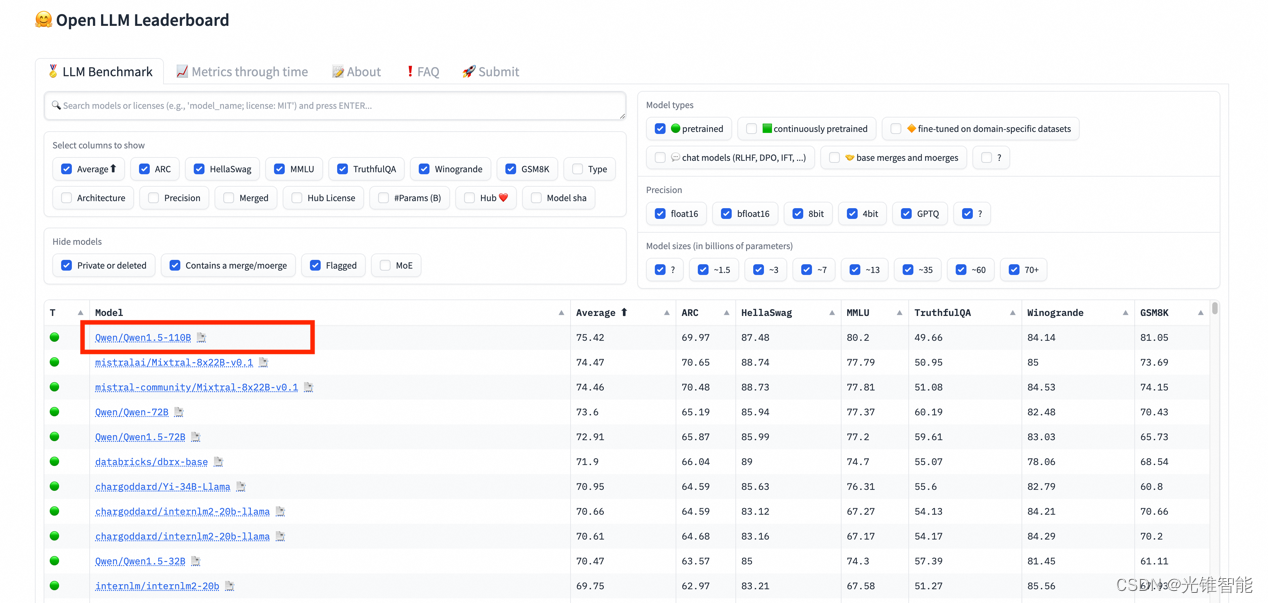
阿里云发布通义千问2.5,OpenCompass上得分追平GPT-4 Turbo
5月9日消息,阿里云正式发布通义千问2.5,模型性能全面赶超GPT-4 Turbo,成为地表最强中文大模型。同时,通义千问最新开源的1100亿参数模型在多个基准测评收获最佳成绩,超越Meta的Llama-3-70B,成为开源领域最强大模型。 相比通义千问2.1版本,通义千问2.5的理解能力、逻辑推理、指令遵循、代码能力分别提升9%、16%、19%、10%,中文能力更是持续领先业界。在权威

第七节课《OpenCompass司南--大模型评测实战》
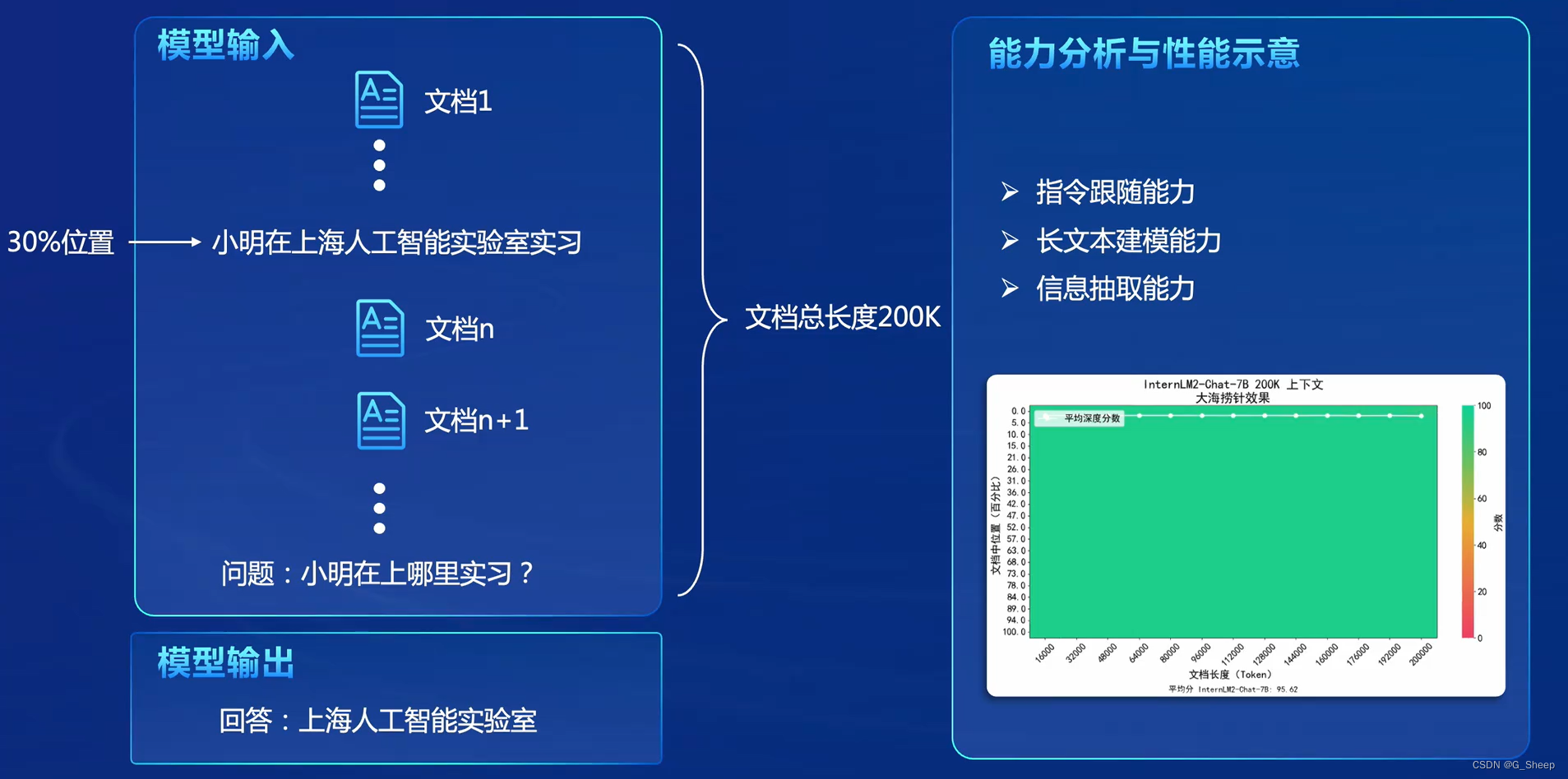
OpenCompass 大模型评测实战_哔哩哔哩_bilibili https://github.com/InternLM/Tutorial/blob/camp2/opencompass/readme.md InternStudio 一、通过评测促进模型发展 面向未来拓展能力维度:评测体系需增加新能力维度(数学、复杂推理、逻辑推理、代码和智能体等),以全面评估模型性能。扎根通用能力聚焦垂直
OpenCompass 大模型评测实战——笔记
OpenCompass 大模型评测实战——笔记 一、评测1.1、为什么要做评测1.2、如何通过能力评测促进模型发展1.2.1、面向未来拓展能力维度1.2.2、扎根通用能力1.2.3、高质量1.2.4、性能评测 1.3、评测的挑战1.3.1、全面性1.3.2、评测成本1.3.3、数据污染1.3.4、鲁棒性 二、OpenCompass怎么评测2.1、模型分类2.2、客观与主观评测2.3、提示词
OpenCompass 大模型评测实战——作业
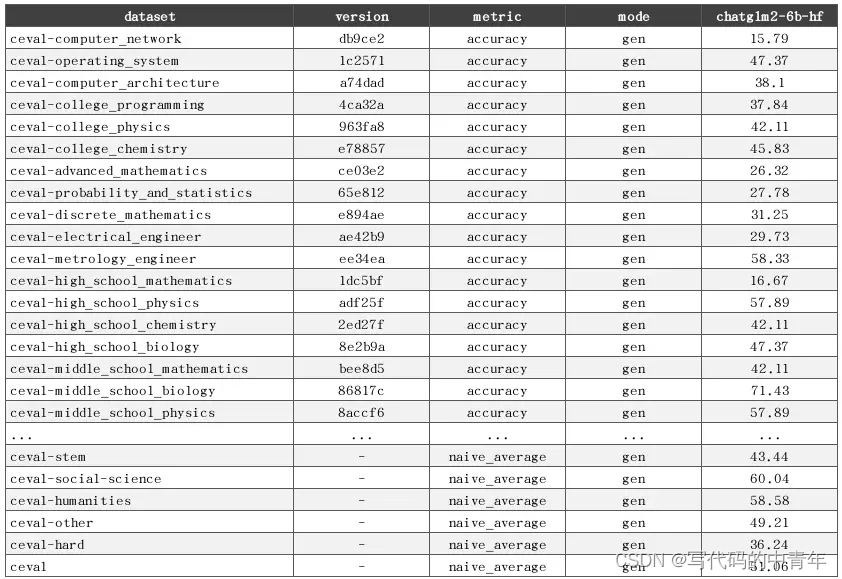
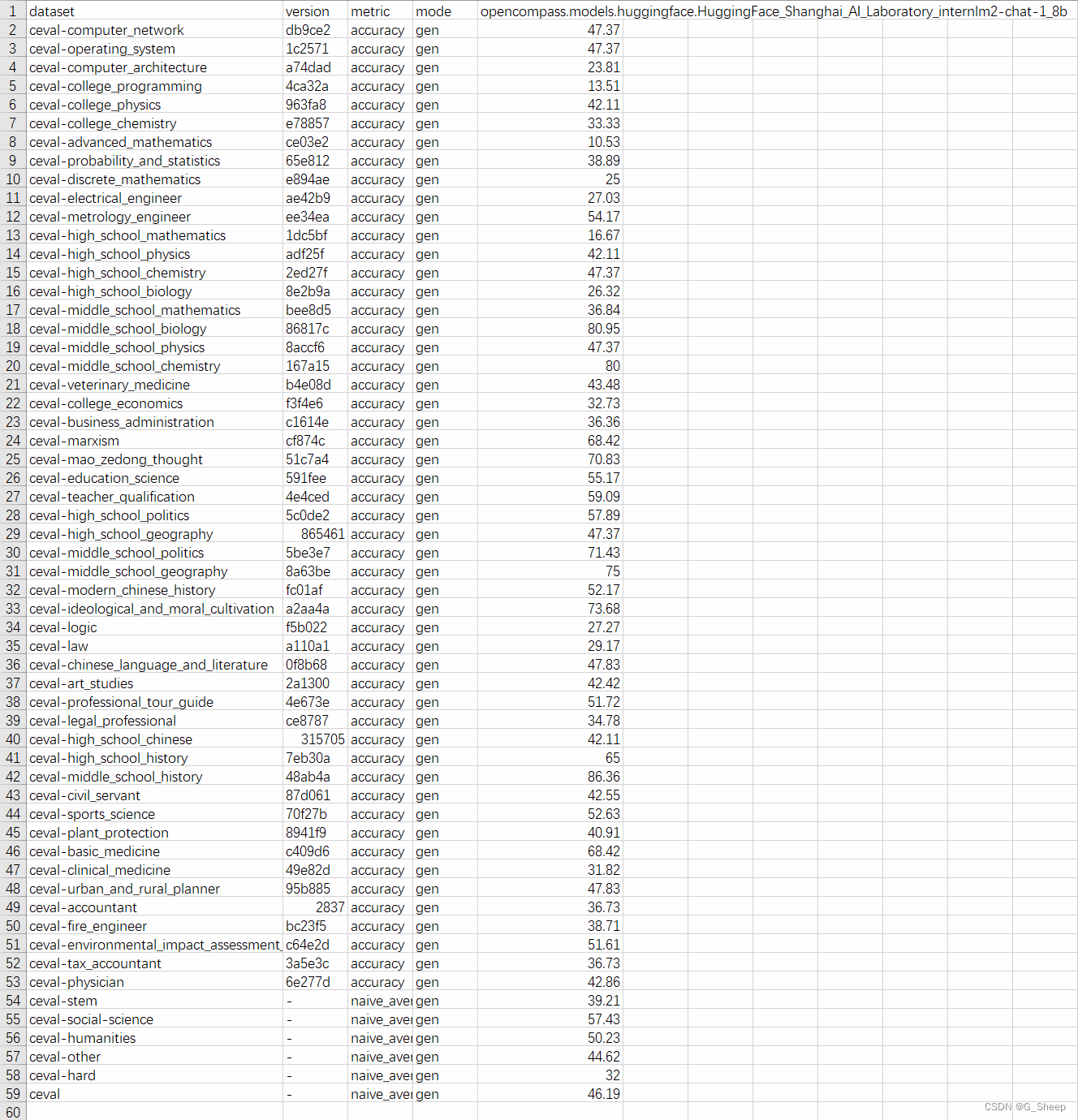
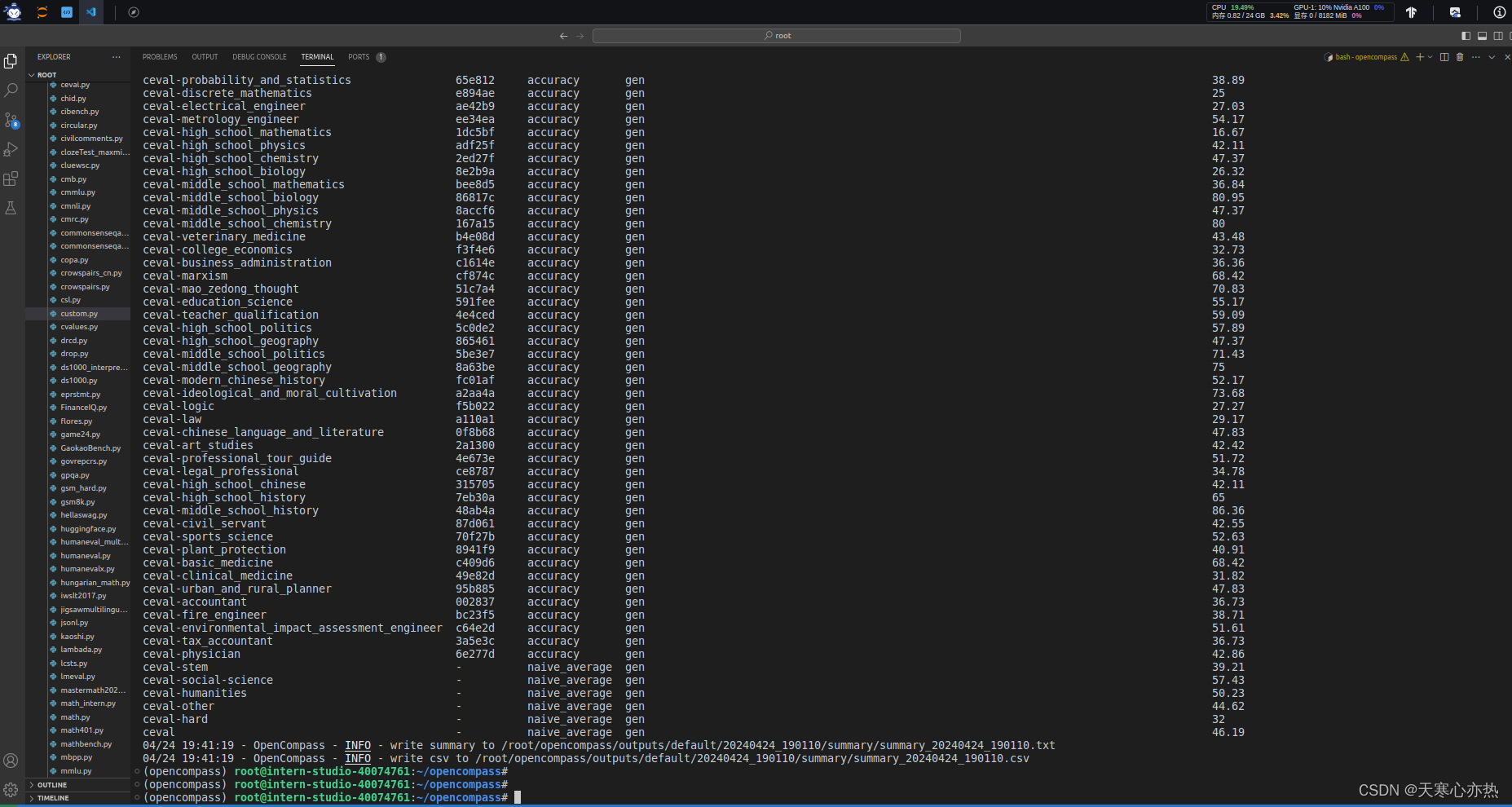
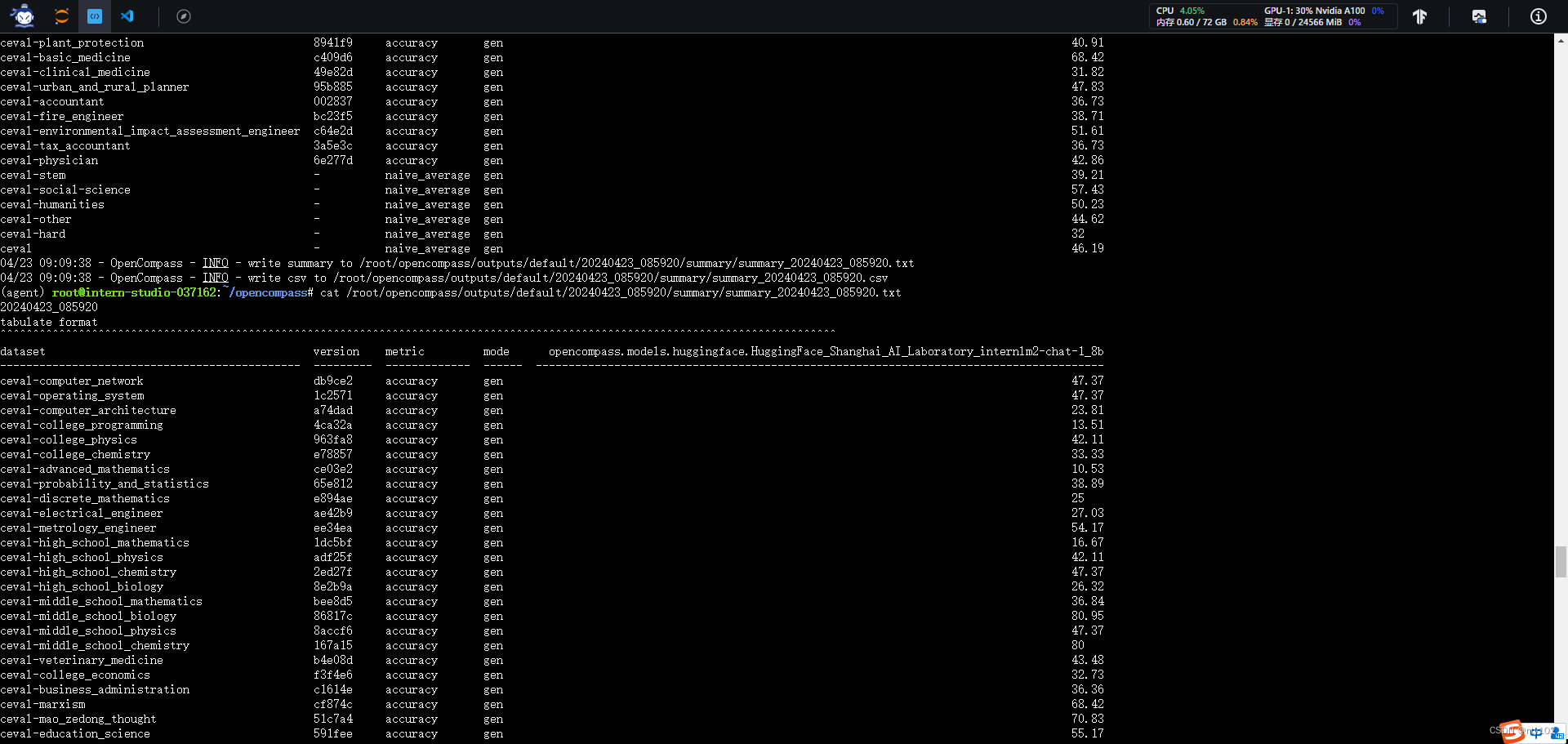
OpenCompass 大模型评测实战——作业 一、基础作业1.1、使用 OpenCompass 评测 internlm2-chat-1_8b 模型在 C-Eval 数据集上的性能1.1.1、安装基本环境1.1.2、解压数据集1.1.3、查看支持的数据集和模型1.1.4、启动评测 二、进阶作业2.1、将自定义数据集提交至OpenCompass官网 一、基础作业 1.1、使用
书生·浦语大模型第二期实战营第七节-OpenCompass 大模型评测实战 笔记和作业
来源: 视频教程:https://www.bilibili.com/video/BV1Pm41127jU/?spm_id_from=333.788&vd_source=f4a51f7f5a63e756f73ad0dff318c1a3 文字教程:https://github.com/InternLM/Tutorial/blob/camp2/opencompass/readme.md 作业来
7、OpenCompass 大模型评测实战(homework)
基础作业 使用 OpenCompass 评测 internlm2-chat-1_8b 模型在 C-Eval 数据集上的性能 0、环境安装 studio-conda -o internlm-base -t opencompasssource activate opencompassgit clone -b 0.2.4 https://github.com/open-compass/op

【InternLM 实战营第二期笔记07】OpenCompass 大模型评测实战
一、为什么要研究大模型的评测 研究大模型的评测至关重要,原因如下: 性能评估与比较:通过评测,可以客观地评估大模型的性能,包括其准确性、效率、鲁棒性等多个方面。这有助于模型开发者了解模型的优缺点,从而进行有针对性的改进。同时,评测也为不同模型之间的比较提供了依据,有助于选择最适合特定任务的模型。推动模型发展:评测不仅可以评估现有模型的性能,还可以为模型的发展提供方向。通过分析评测结果,可以发现

第六节笔记:OpenCompass 大模型评测
视频链接:https://www.bilibili.com/video/BV1Gg4y1U7uc/?spm_id_from=333.788&vd_source=3bbd0d74033e31cbca9ee35e111ed3d1

OpenCompass 2.0 司南大模型评测榜单介绍
OpenCompass 2.0,也称为“司南”,是由上海人工智能实验室发布的一个大模型评测体系。这个评测体系旨在为大语言模型和多模态模型等提供一站式的评测服务,全面量化这些模型在知识、语言、理解、推理和考试等五大能力维度的表现。据2023年的评测结果显示,GPT-4 Turbo 在这些评测中获得了最佳表现,紧随其后的是国内的一些模型,例如智谱清言GLM-4、阿里巴巴Qwen-Max

书生·浦语-模型评测opencompass
大预言模型评测 模型评测包括主管评测与客观评测 测试模型对提示词的敏感性,或通过提示词获得更准确地答案 主流评测框架 opencompass评测平台 作业
InternLM大模型实战-6.OpenCompass大模型评测
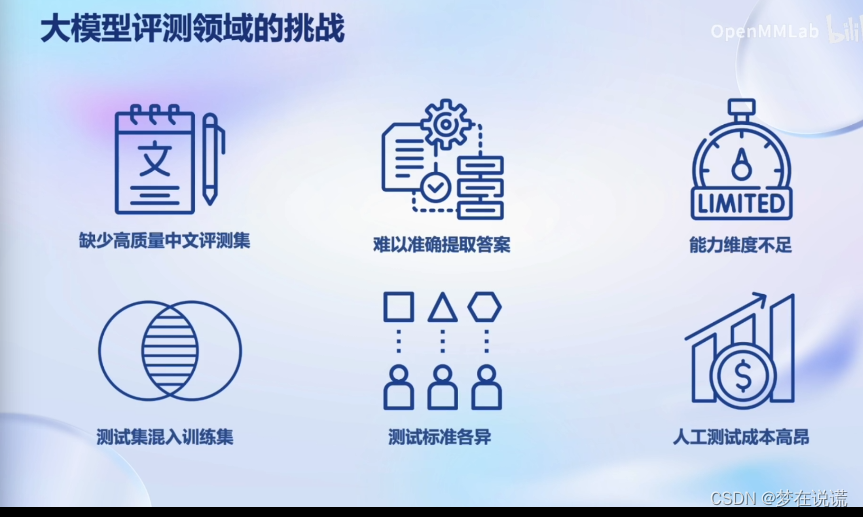
文章目录 前言笔记正文关于模型评测的三个问题为什么需要评测我们需要测什么怎么测试大语言模型 主流大模型评测框架OpenCompass大模型评测领域的挑战 前言 本文是对于InternLM全链路开源体系系列课程的学习笔记。【OpenCompass 大模型评测】 https://www.bilibili.com/video/BV1Gg4y1U7uc/?share_source=co
![第五课[lmdeploy]作业 +第六课[OpenCompass评测]作业](https://img-blog.csdnimg.cn/direct/f5b14ebb924347569eb5dc1c64c82098.png)
第五课[lmdeploy]作业 +第六课[OpenCompass评测]作业
第五课基础作业 如下图,采用api_server部署,并转发端口通过curl提交内容。 第六课基础作业 完了捏?
第六课 OpenCompass 大模型评测
视频:OpenCompass 大模型评测_哔哩哔哩_bilibili 文档:https://github.com/InternLM/tutorial/blob/main/opencompass/opencompass_tutorial.md 第6节课作业(16班):https://github.com/InternLM/tutorial/discussions/450 第6节课笔记(16班)
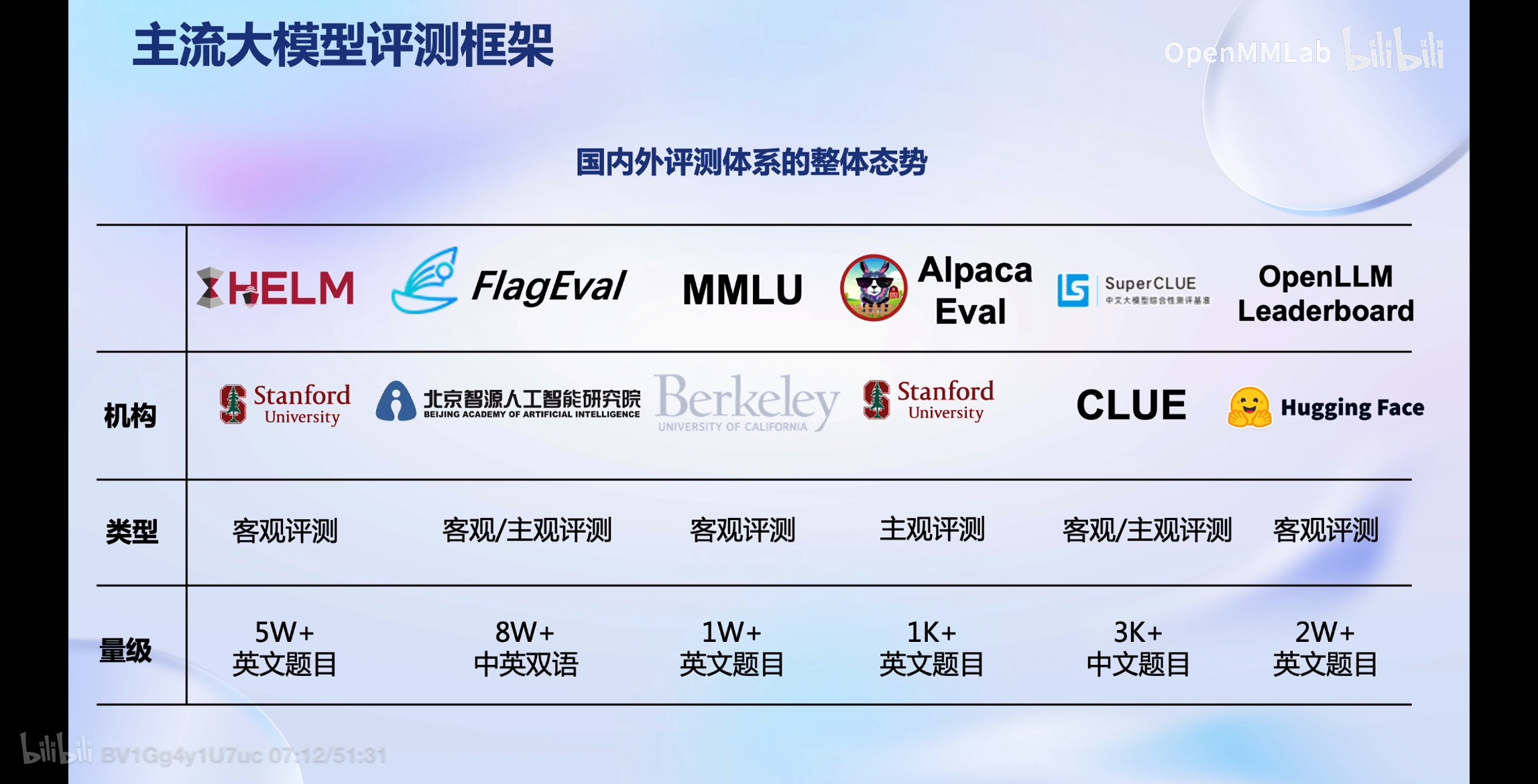
【书生·浦语大模型实战营06】《OpenCompass 大模型评测》学习笔记
《OpenCompass 大模型评测》 1、主观评测 2、提示词工程 李华每周给2个不同的朋友写一封3页的信,一周写两次。他一年总共写了多少页的信? 李华每周给2个不同的朋友写一封3页的信, 一周写两次。他一年总共写了多少页的信。 问题:李华每周给2个不同的朋友写一封3页的信,一 周写两次。他一年总共写了多少页的信?答案: 问题:李华每周给2个不同的朋友写一封3页的信,一周写两次

OpenCompass 大模型评测
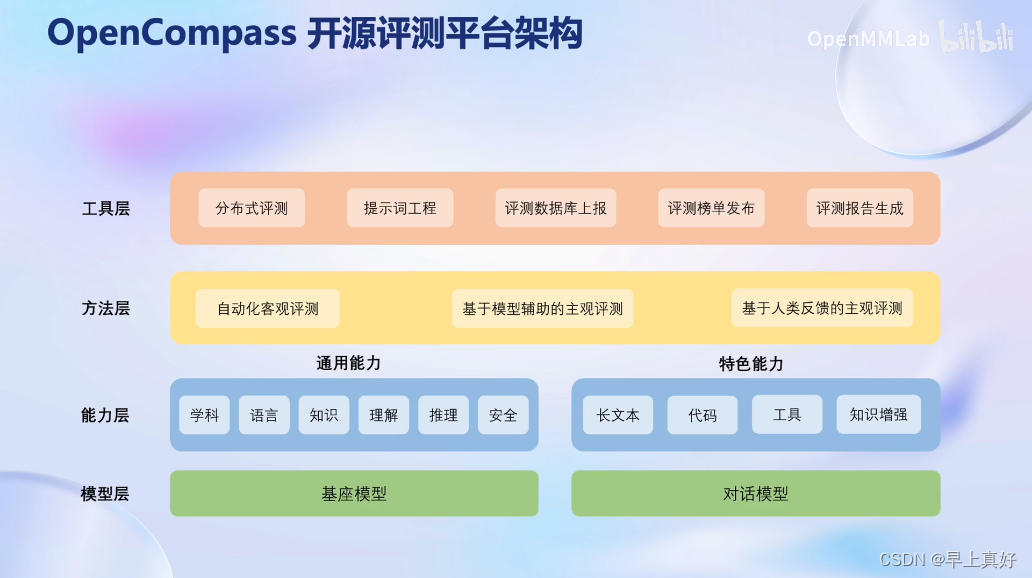
OpenCompass 大模型评测 关于测评的三个问题为什么需要测评?我们需要评测什么?怎么测试大预言模型? 主流大模型评测框架OpenCompass能力框架OpenCompass评测流水线设计 随着人工智能技术的快速发展, 大规模预训练自然语言模型成为了研究热点和关注焦点。OpenAI于2018年提出了第一代GPT模型,开辟了自然语言模型生成式预训练的路线。沿着这条路线,随后又陆续
大模型学习之书生·浦语大模型6——基于OpenCompass大模型评测
基于OpenCompass大模型评测 关于评测的三个问题Why/What/How Why What 有许多任务评测,包括垂直领域 How 包含客观评测和主观评测,其中主观评测分人工和模型来评估。 提示词工程 主流评测框架 OpenCompass 能力框架 模型层能力层方法层工具层 支持丰富的模型 评测流水线设计,能切分多个独立执