本文主要是介绍Opencompass模型评测教程,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
模型评测
模型评测非常关键,目前主流的方法主要可以概括为主观评测和客观评测,主观评测又可以分为两种形式:人工判断或者和模型竞技场。客观评测一般采用评测数据集的形式进行模型评测。本教程使用Opencompass工具进行对Internlm2-7b模型进行评测。
算力平台
本教程在OpenBayes上进行实验,主要的原因在于Openbayes平台可以很方便地使用自定义的数据集。没有注册的用户可以使用我的邀请链接,可以额外获得RTX4090的免费使用时长:
https://openbayes.com/console/signup?r=xiaoshulin_WGv4
硬件环境
首先Opencompass比较消耗资源,一张4090评测一次CMMLU评测集大概需要一个小时,并且选择A100速度也是差不多的(主要还是CPU瓶颈和推理能力),建议选择单张4090进行评测,性价比最高。
下载Opencompass评测数据包
opencompass的数据包分为了两个版本,一个是complete版本和core版本,其中complete版本包含的数据集种类更加全面,core版本包含了主要的核心评测数据集。由于本教程评测使用CMMLU数据集,所以只需要下载core版本即可。
下载方式可以使用官方的办法:
# 下载数据集到 data/ 处
wget https://github.com/open-compass/opencompass/releases/download/0.2.2.rc1/OpenCompassData-core-20240207.zip
unzip OpenCompassData-core-20240207.zip
但是经过本人测试,下载速度非常有限,所以可以使用我下面的链接:opencompass包阿里云
同时,强烈建议将数据集上传到openBayes平台给用户挂载的数据集文件夹。
1、首先创建一个数据集:
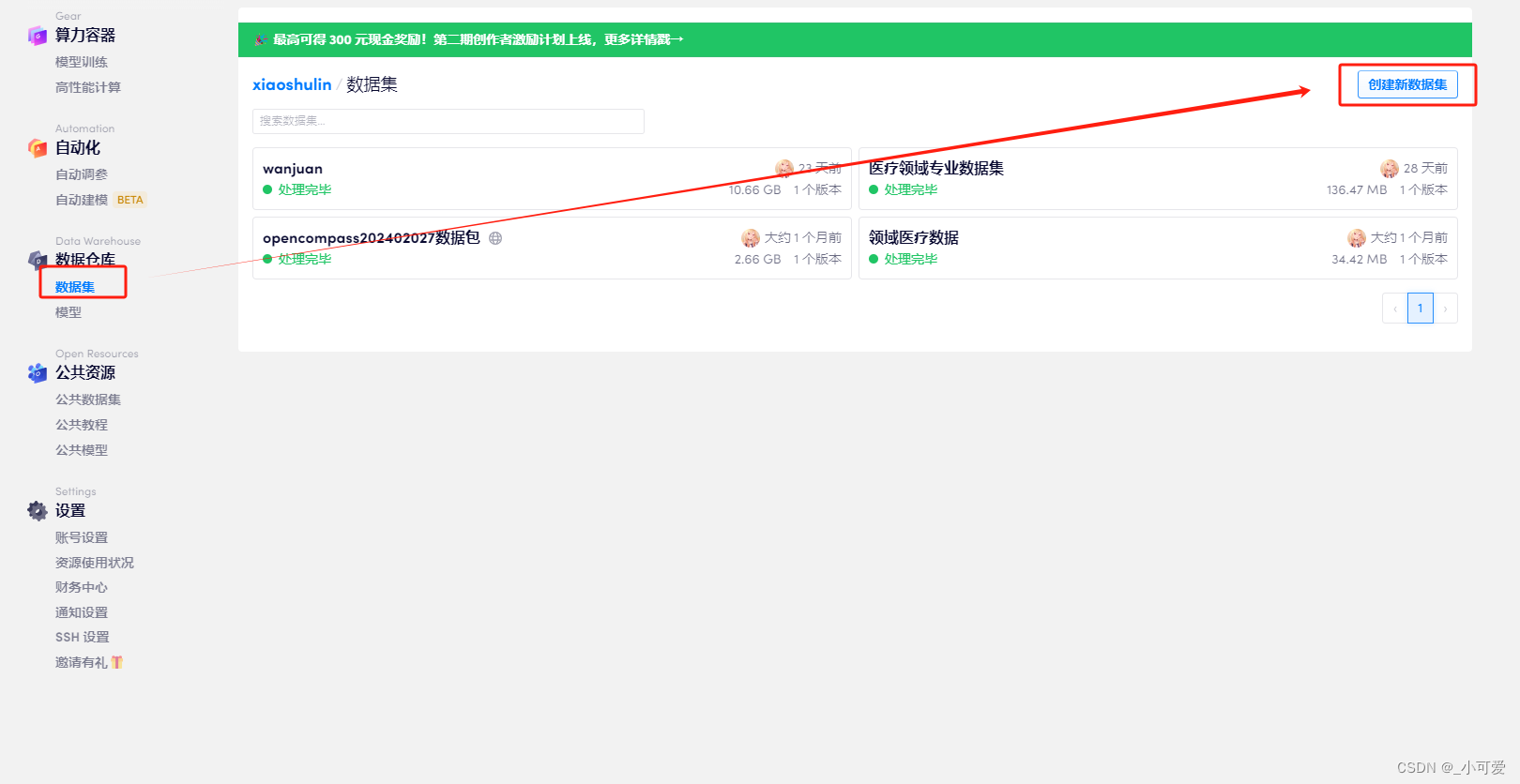
我这里命名为opencompass评测数据集。
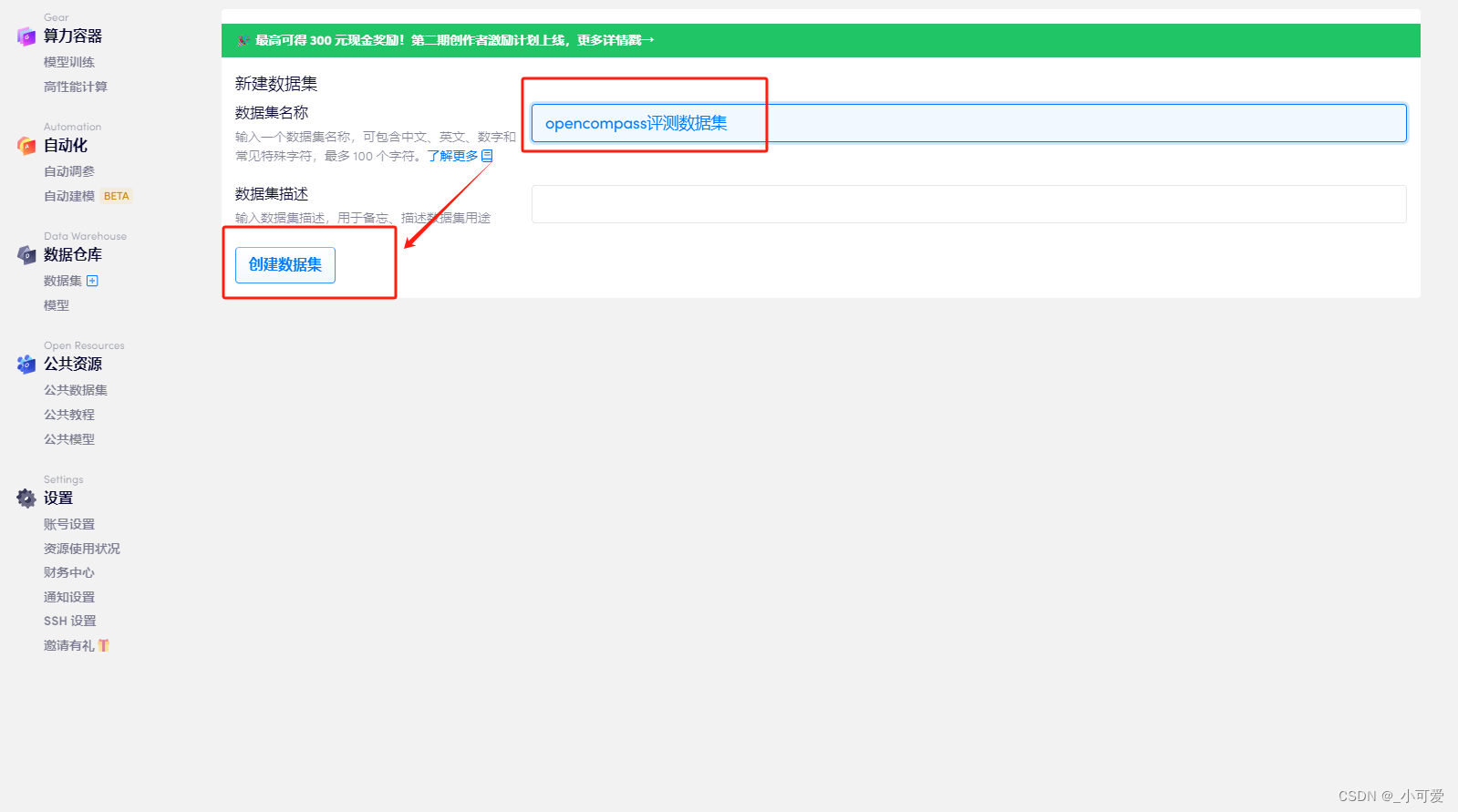
然后需要创建一个新的版本(openBayes的管理和github很像,无论是模型还是数据集都是有版本一说,这样子的话可以方便管理数据集的不同版本,这也是非常nice的一点):
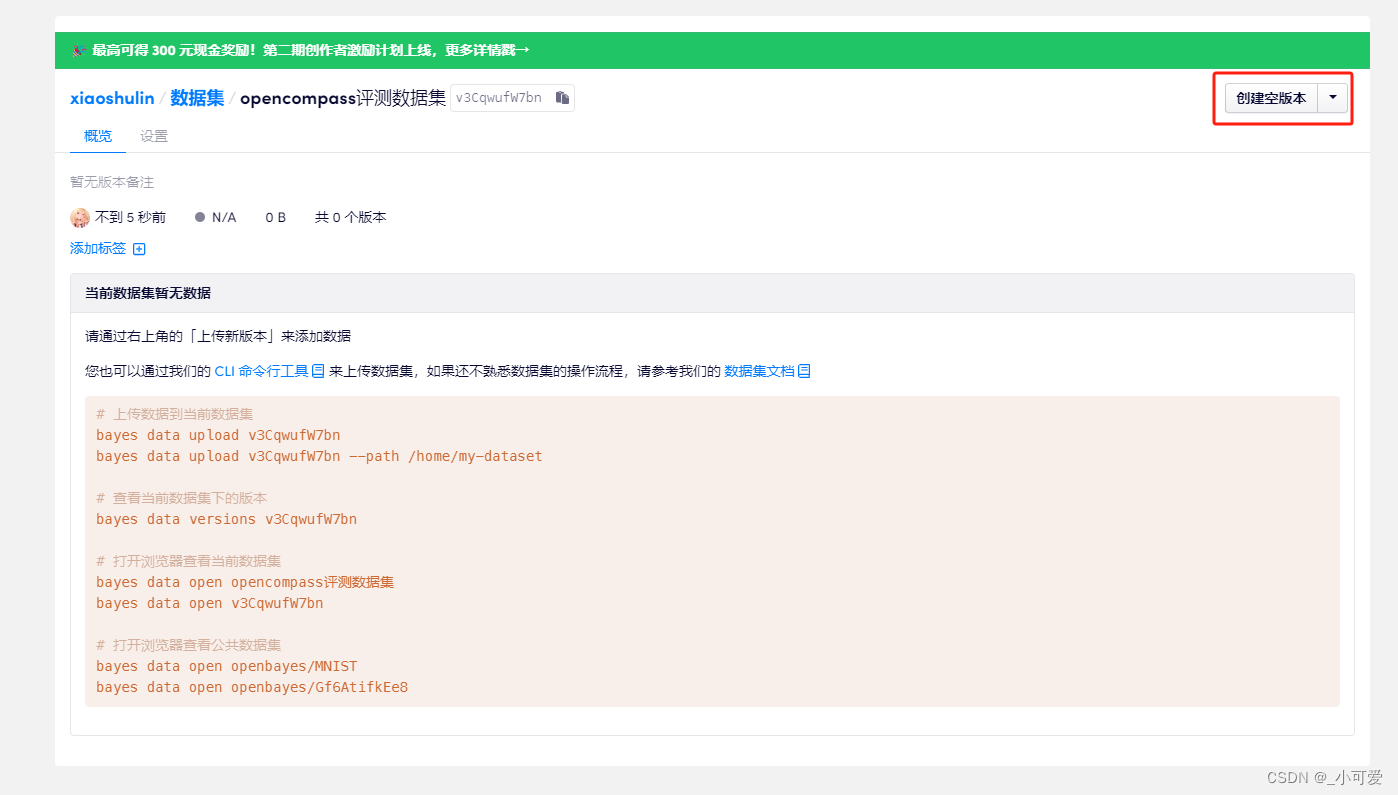
然后在对应的版本里面上传需要的数据集即可。

配置硬件环境
本教程使用RTX4090进行模型的评测。但是首先我们需要创建一个算力容器。
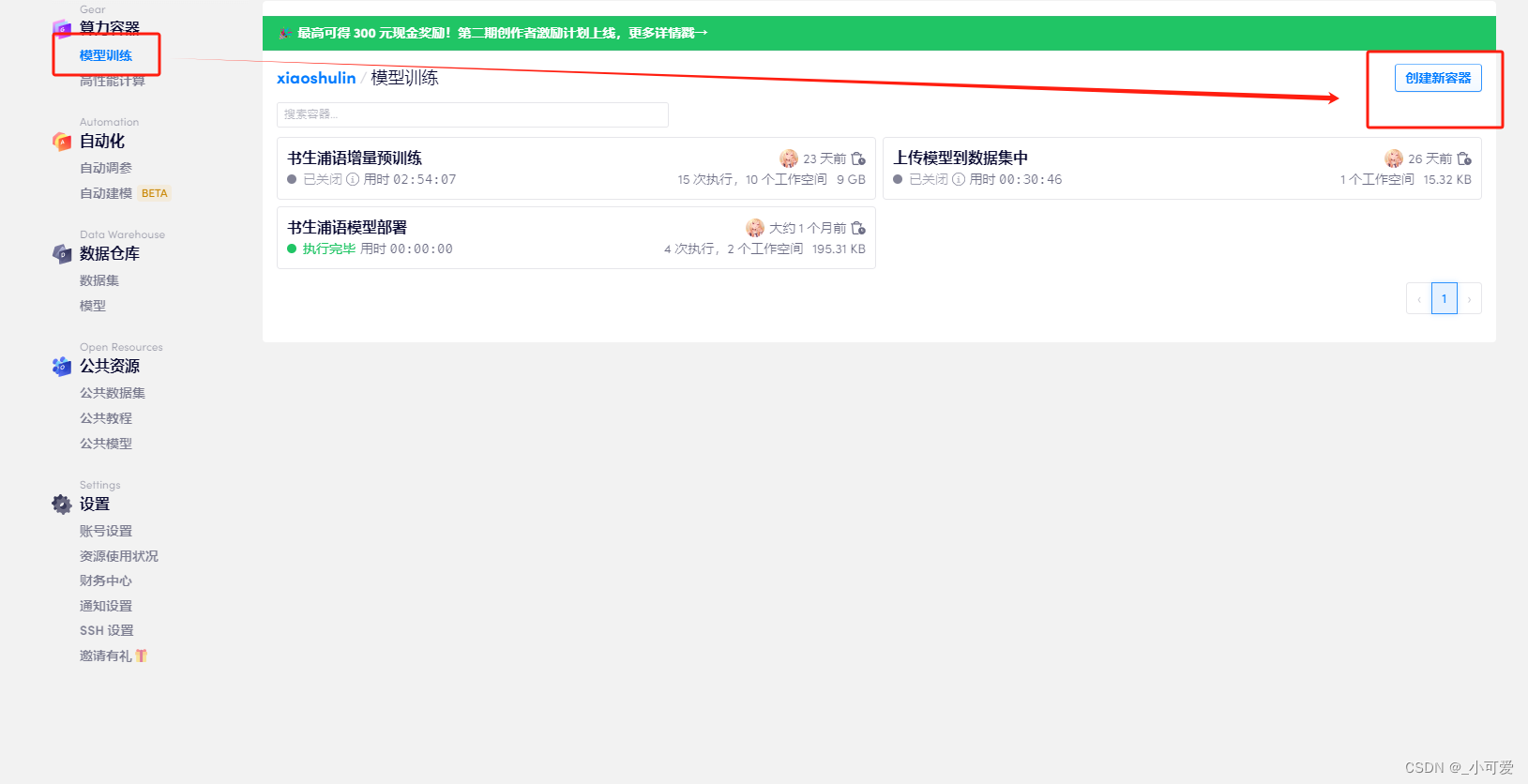
我这里命名为书生浦语模型评测,注意在创建数据集的时候需要设置好两个:internlm2-7b模型和你刚才创建的opencompass数据包,这样子的话就根本不需要额外在容器内部下载,白白浪费时间。

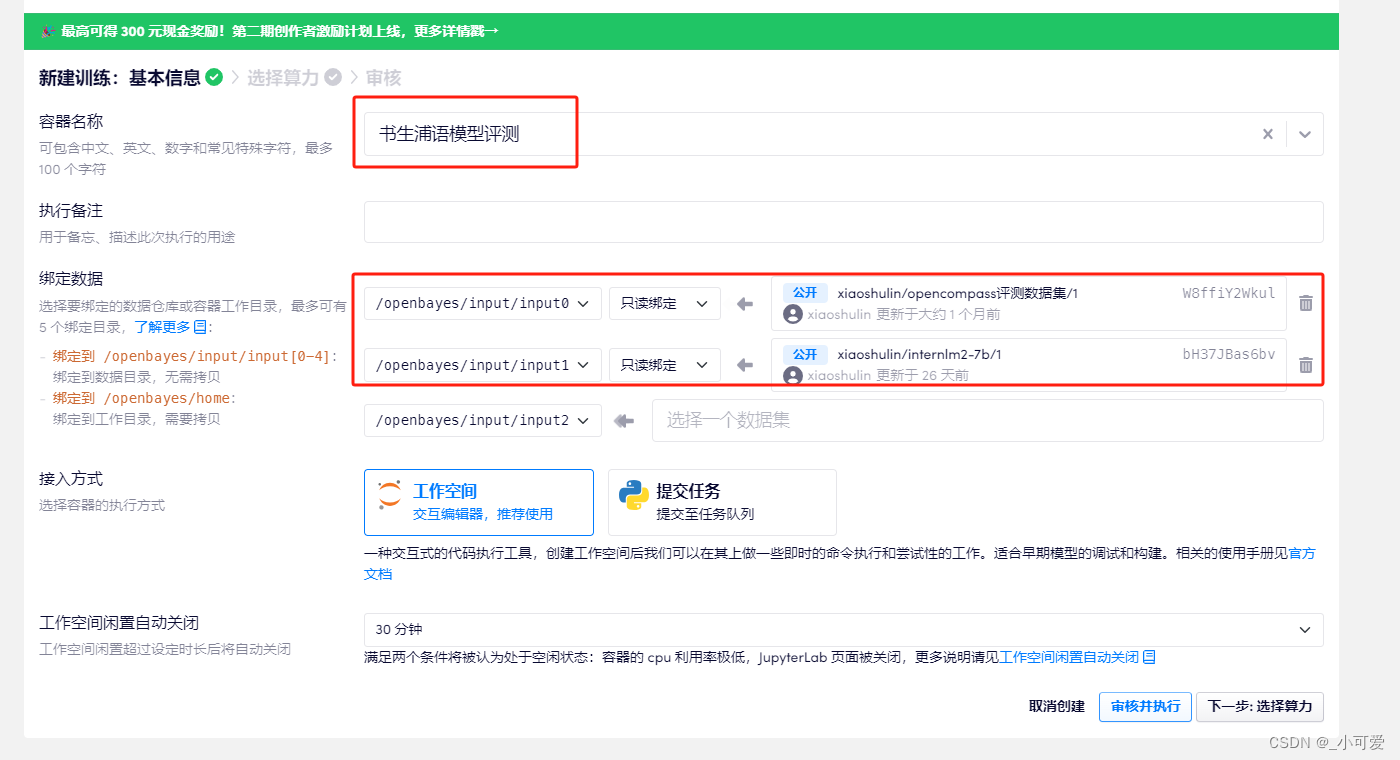
然后到了下一步选择算力,我们选择使用RTX4090加速,并且使用pytorch中的python3.10+cuda12.1环境镜像:
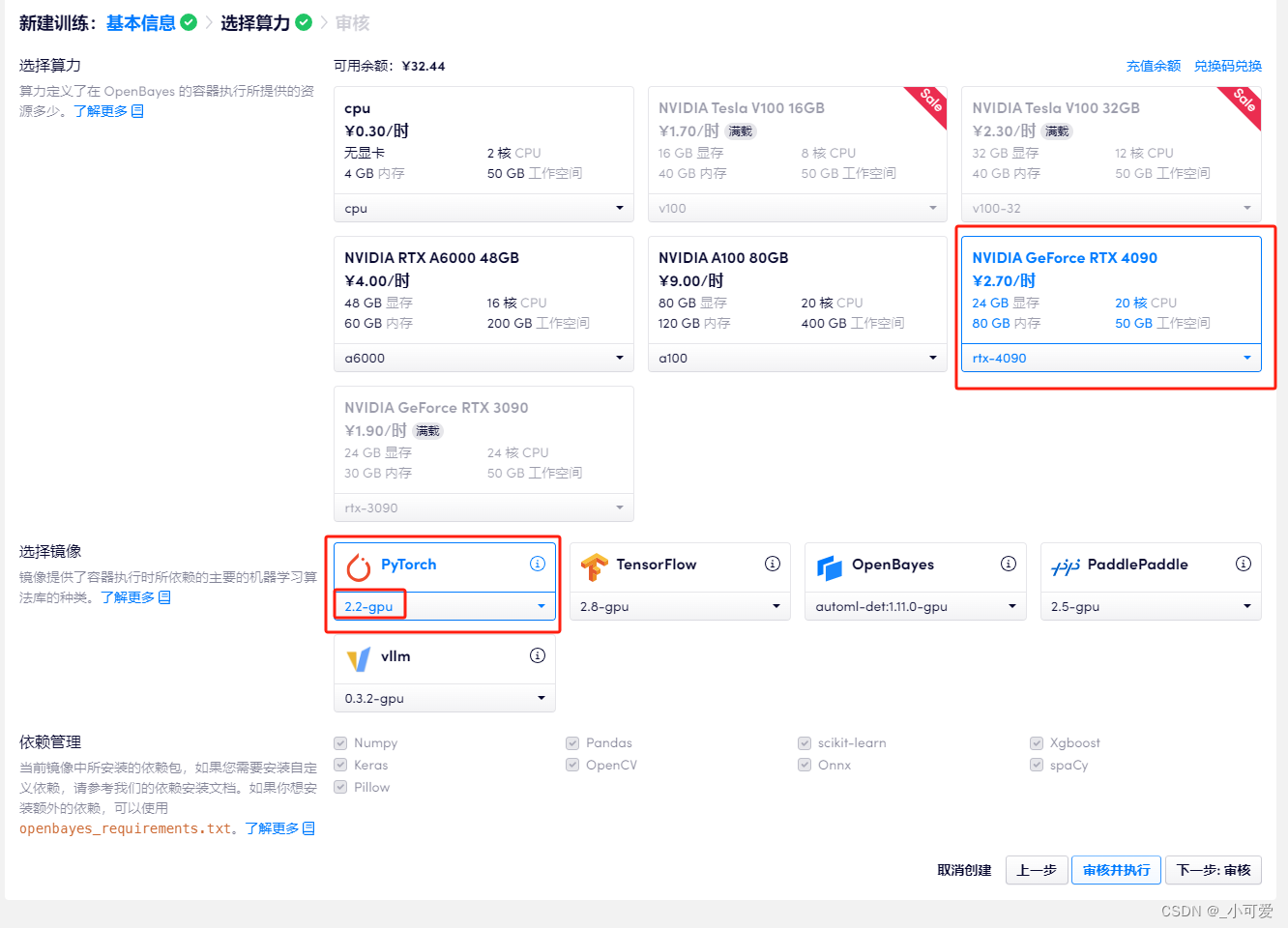
剩下的就是点击审核和执行就可以了。
软件环境配置
这一步,首先打开JupyterLab的工作空间。
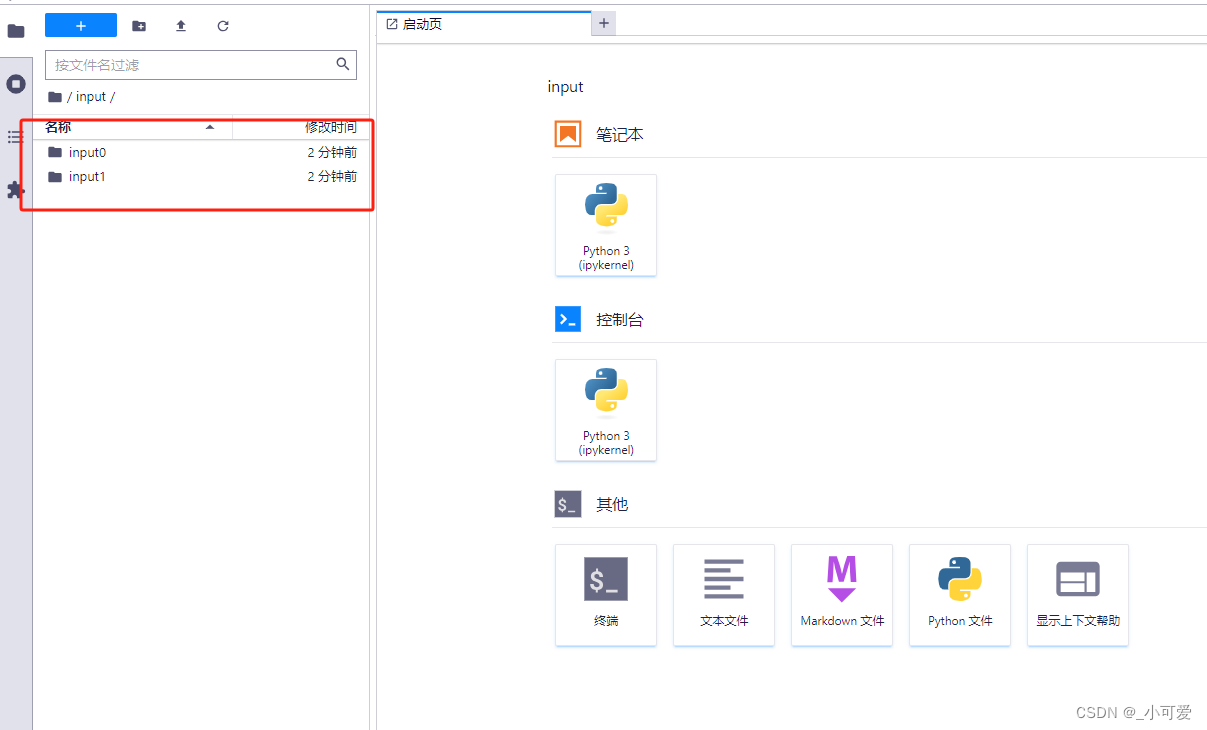
观察这个界面,我们就可以发现到我们刚刚挂载的那个评测数据集和评测的模型(实际上就是两个文件夹)。
由于每一次启动openbayes平台都会将base的conda环境的软件依赖全部清理掉,所以最好的方法是使用conda创建一个全新的虚拟环境保存到路径/openbayes/home下面,这个文件夹的所有内容不会被删除。首先创建一个终端,确保在home路径下面,然后执行下面的脚本:
conda create --prefix /openbayes/home/opss python=3.10 pytorch torchvision pytorch-cuda -c nvidia -c pytorch -y
conda activate /openbayes/home/opss
git clone https://github.com/open-compass/opencompass.git
cd opencompass
pip install -e .
由于可能发生缺失文件libGL.so.1,所以需要安装软件依赖:
apt install libgl1-mesa-glx -y
最后我们进入opencompass的目录下面,可以得到下面的结构目录:
opencompass使用
参考文档
官方最新的opencompass使用文档
执行opencompass评测任务
首先需要创建一个data文件夹,存储的就是我们刚刚放上去的opencompass评测集。
然后在将我们的评测数据集复制一份到这个data文件夹里面:
cp -r /openbayes/input/input0/data/* ./data
opencompass的工作原理可以参考文档,也可以参考这个文章:关于openCompass与大模型评测现状的分析
用起来的实际上并不需要特别深入的理解,只需要明白每一步要要干啥就OK了。执行opencompass的一个关键是调整评测集的config,常用的评测数据集的配置文件都在opencompass/configs这个路径下面了。
首先创建一个配置文件eval_internlm2_7b.py放到configs文件夹下面:
from opencompass.models import HuggingFaceCausalLM
from mmengine.config import read_basewith read_base():from .datasets.cmmlu.cmmlu_ppl import cmmlu_datasetsdatasets = [*cmmlu_datasets]models = [dict(type=HuggingFaceCausalLM,abbr='internlm2-7b',path="/openbayes/input/input1/internlm2-7b", # 模型文件路径tokenizer_path='/openbayes/input/input1/internlm2-7b',tokenizer_kwargs=dict(trust_remote_code=True,use_fast=False,),max_seq_len=2048,batch_size=1,model_kwargs=dict(device_map='auto', trust_remote_code=True),run_cfg=dict(num_gpus=1, num_procs=1),) # 多模型评测最好放到一起,因为可以开很多个进程一起评测
]
然后在终端执行命令:
MKL_SERVICE_FORCE_INTEL=1 python run.py configs/eval_internlm2_7b.py
输出会保存到文件opencompass/outputs文件夹里面:

这篇关于Opencompass模型评测教程的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







