本文主要是介绍书生·浦语大模型第二期实战营第七节-OpenCompass 大模型评测实战 笔记和作业,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
来源:
视频教程:https://www.bilibili.com/video/BV1Pm41127jU/?spm_id_from=333.788&vd_source=f4a51f7f5a63e756f73ad0dff318c1a3
文字教程:https://github.com/InternLM/Tutorial/blob/camp2/opencompass/readme.md
作业来源:https://github.com/InternLM/Tutorial/blob/camp2/opencompass/homework.md
1. OpenCompass 大模型评测

1.1 如何通过能力评测促进模型发展
面向未来,拓展能力维度:大模型学习人的能力,目前的上限是人的想象力上限,设计数学、推理、代码、智能体等各种维度来评测模型性能。
聚焦垂直行业:大模型在通用领域已经能达到不错的效果,但是在医疗金融法律等需要高精的专业领域,需要更加规范的内容来评估模型的行业适用性。
中文基准:目前全球社区大模型生态以英文为主,通过针对中文场景设计相关评测基准,来促进中文社区的大模型发展。
能力评测反哺能力迭代:通过评测,发现模型不足,针对性提升。

1.2 大语言模型评测中的挑战
全面性:
评测需要综合考量模型在不同维度上的表现,包括语言理解、知识应用、逻辑推理、创造力等。同时,还应考虑模型在特定垂直行业如医疗、金融、法律等领域的专业能力,以及其对新情境的适应性和学习能力。
评测成本:
大模型的评测往往涉及大规模的计算资源和数据集,这导致评测成本显著增加。另外,为了获得全面的评测结果,除了客观的打分题目,还有基于人工打分的主观评测,进一步增加了时间和经济成本。
数据污染:
数据污染指的是评测数据被加入到模型的训练数据中,需要可靠的数据污染检测技术和动态调节的评测基准,来获得真实客观的评估结果。
鲁棒性:
评测大模型时,需要检验其在面对变化的提示词输入的鲁棒性,设计针对鲁棒性的评测数据,例如挖掘大模型的bias(针对顺序的bias、针对长短文本的bias等),在多次采样下评估模型的性能。

1.3 如何评测大模型
基座模型:海量数据无监督训练(Base)
对话模型:指令数据有监督微调(SFT)、人类偏好对齐(RLHF)

1.4 提示词工程
构建评测集需要对提示词有较高的要求,避免引入评测结果偏差,下面是一些例子,例如文本语义要明确,具体细节,迭代反馈、few-shot、思维链等一些prompt工程化技巧:

1.5 大模型评测全栈工具链
 1.6 评测基准
1.6 评测基准
MathBench:多层次数学能力评测基准,包括不同的难度,不同的语言。还包括循环评估,可以消除大模型对答案顺序的bias。
CriticBench:多维度LLM反思能力评估基准
T-Eval:大模型细粒度工具能力评测基准
F-Eval:大模型基础能力评测基准
CreationBench:多场景中文创作能力评测标准
CIBench:代码解释能力评测标准
OpenFinData:全场景金融评测基准
LawBench:大模型司法能力基准
MedBench :中文医疗大模型评测基准
SecBench:网络安全评测基准
 2. 作业-使用 OpenCompass 评测 internlm2-chat-1_8b 模型
2. 作业-使用 OpenCompass 评测 internlm2-chat-1_8b 模型
命令行
python run.py --datasets ceval_gen --hf-path /share/new_models/Shanghai_AI_Laboratory/internlm2-chat-1_8b --tokenizer-path /share/new_models/Shanghai_AI_Laboratory/internlm2-chat-1_8b --tokenizer-kwargs padding_side='left' truncation='left' trust_remote_code=True --model-kwargs trust_remote_code=True device_map='auto' --max-seq-len 1024 --max-out-len 16 --batch-size 2 --num-gpus 1 --debugpython run.py
--datasets ceval_gen \
--hf-path /share/new_models/Shanghai_AI_Laboratory/internlm2-chat-1_8b \ # HuggingFace 模型路径
--tokenizer-path /share/new_models/Shanghai_AI_Laboratory/internlm2-chat-1_8b \ # HuggingFace tokenizer 路径(如果与模型路径相同,可以省略)
--tokenizer-kwargs padding_side='left' truncation='left' trust_remote_code=True \ # 构建 tokenizer 的参数
--model-kwargs device_map='auto' trust_remote_code=True \ # 构建模型的参数
--max-seq-len 1024 \ # 模型可以接受的最大序列长度
--max-out-len 16 \ # 生成的最大 token 数
--batch-size 2 \ # 批量大小
--num-gpus 1 # 运行模型所需的 GPU 数量
--debug
protobuf报错
解决方案:
pip install protobuf
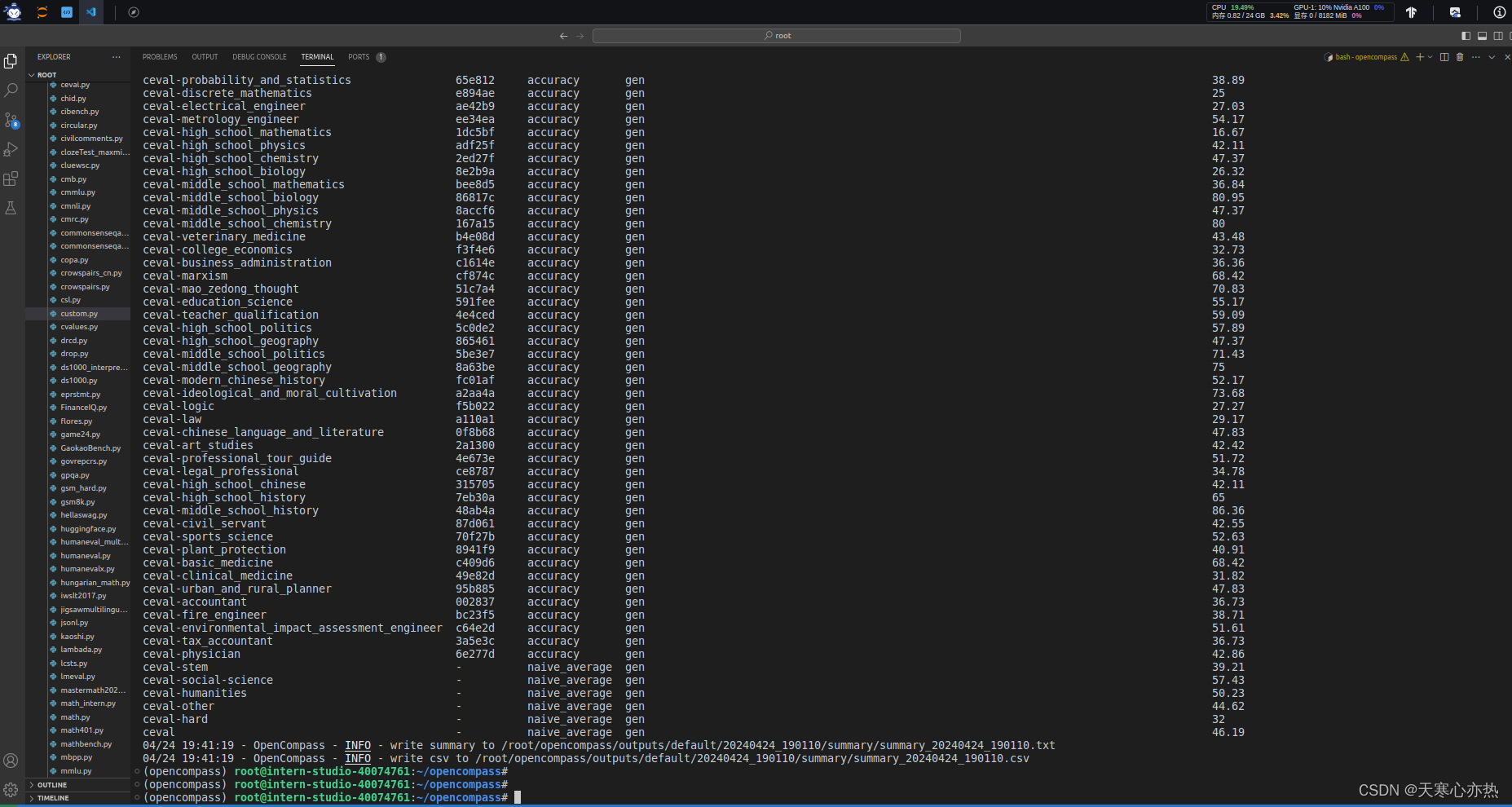
评测


这篇关于书生·浦语大模型第二期实战营第七节-OpenCompass 大模型评测实战 笔记和作业的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






