本文主要是介绍OpenCompass 大模型评测实战——笔记,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
OpenCompass 大模型评测实战——笔记
- 一、评测
- 1.1、为什么要做评测
- 1.2、如何通过能力评测促进模型发展
- 1.2.1、面向未来拓展能力维度
- 1.2.2、扎根通用能力
- 1.2.3、高质量
- 1.2.4、性能评测
- 1.3、评测的挑战
- 1.3.1、全面性
- 1.3.2、评测成本
- 1.3.3、数据污染
- 1.3.4、鲁棒性
- 二、OpenCompass怎么评测
- 2.1、模型分类
- 2.2、客观与主观评测
- 2.3、提示词工程
- 2.4、长文本评测
一、评测
1.1、为什么要做评测
因为通过评测,可以更好地发现大模型的问题。现在大模型在各个领域都有应用,那显然,也需要多维度的评测体系对其检测,发现哪个维度强,哪个维度弱,然后对于弱的维度,再进行针对性地提高。
这就像学习一样,如果没有平常的考试,你是不会确定自己到底学的怎么样,哪些知识点是薄弱环节需要重点提高。
1.2、如何通过能力评测促进模型发展
1.2.1、面向未来拓展能力维度
评测体系需增加新能力维度如数学、复杂推理、逻辑推理、代码和智能体等,以全面评估模型性能。
1.2.2、扎根通用能力
聚焦垂直行业在医疗、金融、法律等专业领域,评测需结合行业知识和规范,以评估模型的行业适用性。
1.2.3、高质量
中文基准针对中文场景,需要开发能准确评估其能力的中文评测基准,促进中文社区的大模型发展。
1.2.4、性能评测
反哺能力迭代通过深入分析评测性能,探索模型能力形成机制,发现模型不足,研究针对性提升策略。
1.3、评测的挑战
1.3.1、全面性
现在大模型应用场景千变万化,几乎各行各业都能看到它的影子,同时,模型能力演进迅速,在这样的条件下,如何设计和构造可扩展的能力维度体系,难度还是很大的。
1.3.2、评测成本
在客观评测方面,比如评测数十万道题,那是需要大量算力资源。
在主观评测方面,有时候需要调用 api 来评测,比如调用 GPT-4 作为法官来评测哪个模型好,那这也是需要成本的。
基于人工打分的主观评测成本不用说,那就更高昂了。
1.3.3、数据污染
海量语料不可避免带来评测集污染,比如有的模型,它是在测试集上做的训练,这就会导致后面测试分数虚高,但他们也不公布自己训练的数据集,所以别人就不知道,或者测试集和训练集有大量重叠部分,也相当于作弊或者自欺欺人,所以亟需可靠的数据污染检测技术,那如何设计可动态更新的高质量评测基准,也是个问题。
1.3.4、鲁棒性
某些大模型对提示词十分敏感,换了一套问法可能答案就不正确了,又或者是多次采样情况下模型性能不稳定,那这也是评测需要解决的问题。
二、OpenCompass怎么评测
2.1、模型分类
对于模型评测,不可能使用一套标准对所有模型进行评测,所以会将模型先分个类。
司南 评测体系 总共将模型分为四大类,包括:
- 基座模型。一开始的只经过海量数据无监督训练的模型。
- 对话模型。包括经过指令数据有监督微调 ( SFT ) 和 人类偏好对其 ( RLHF ) 的模型。
- 公开权重的开源模型。这类模型使用GPU/推理加速卡进行本地推理。
- API 模型。就是使用者发送网络请求然后获取回复。
2.2、客观与主观评测

2.3、提示词工程
既然要评测,那就是要尽可能在一个相对准备充足的条件下对模型进行评测,但很多时候,因为提问者的问题提问的不够清楚,导致模型的回答也相对较差,那这就体现不出模型的能力,所以肯定是要在能体现模型能力的基础上再进行评测。比如:
- 明确性
不好的示例 : 请写一篇关于人工智能的全面介绍( 目标过于宽泛,缺乏具体要求和细节 )
好的示例 : 请为我写一篇关于人工智能的科普文章,要求涵盖其发展历程、应用领域以及对社会的影响。( 目标明确,完整覆盖了主题内容 ) - 概念无歧义
不好的示例: 我想了解苹果。( 问题内容存在歧义 )
好的示例: 请描述苹果公司的创始人史蒂夫·乔布斯的职业生涯( 给出了准确的概念 ) - 逐步引导
不好的示例 : 告诉我怎么做蛋糕。( 缺少指引)
好的示例: 首先,我需要准备哪些材料来制作巧克力蛋糕? 接下来,烘焙过程中有哪些关键步骤?( 给出了思路引导 ) - 具体描述
不好的示例 : 告诉我一个笑话。( 缺少具体细节 )
好的示例: 请创作一个关于时间旅行的幽默故事( 给出了具体的问题描述和范围 ) - 迭代反馈
不好的示例 : 这个回答不够详细。( 缺少清晰的反馈 )
好的示例:你能更详细地解释人工智能在医疗诊断中的应用吗?( 明确清晰的修改建议 )
还有比如 小样本学习、思维链技术 都可以帮助题目变得更好。
2.4、长文本评测
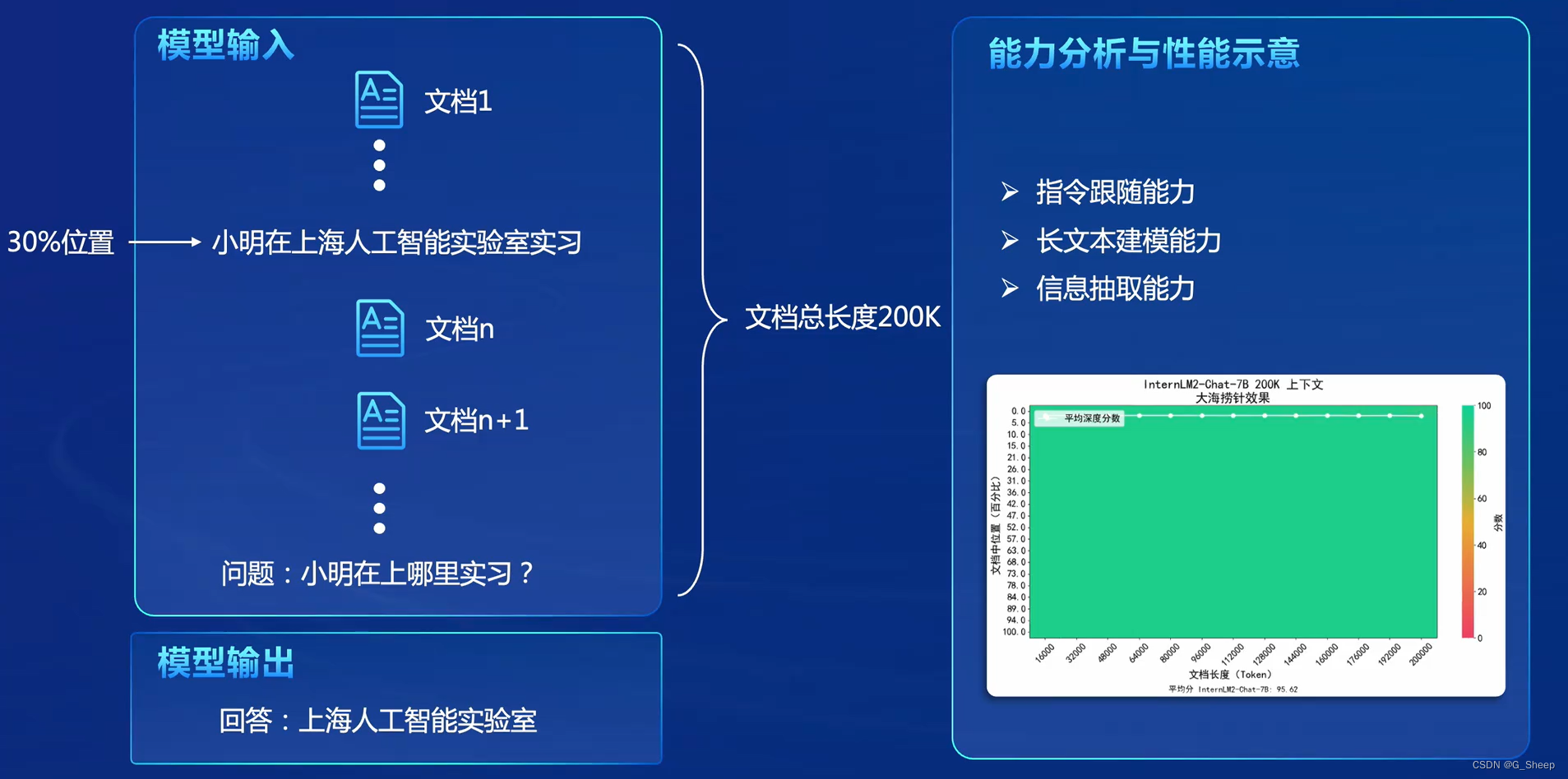
在上面的例子中,在一个很长的文档,比如在红楼梦当中插入一句话 “小明在上海人工智能实验室学习”,这句话和红楼梦没有半点关系,然后交给模型训练,那如果我们后续提问,比如 “小明在哪实习”,模型能回答 “上海人工智能实验室” 这种回答,就代表模型真的能记住这条信息并且能够理解这句话,能够做到 “大海捞针”。
这篇关于OpenCompass 大模型评测实战——笔记的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








