lmdeploy专题

书生大模型实战营(第3期)进阶岛第3关--LMDeploy 量化部署进阶实践
1 配置LMDeploy环境 1.1 InternStudio开发机创建与环境搭建 点选开发机,自拟一个开发机名称,选择Cuda12.2-conda镜像。 我们要运行参数量为7B的InternLM2.5,由InternLM2.5的码仓查询InternLM2.5-7b-chat的config.json文件可知,该模型的权重被存储为bfloat16格式。 对于一个7B(70亿)参数的模型,

书生大模型实战营闯关记录----第十一关:LMDeploy 量化部署进阶实践 KV cache量化部署,W4A16 模型量化和部署
文章目录 1 配置LMDeploy环境1.1 环境搭建1.2 InternStudio环境获取模型1.3 LMDeploy验证启动模型文件 2 LMDeploy与InternLM2.5 2.1 LMDeploy API部署InternLM2.52.1.1 启动API服务器 2.1.2 以命令行形式连接API服务器 2.1.3 以Gradio**网页形式连接API服务器** 2.2 LMDe

LMDeploy 量化部署实践闯关任务
进行模型量化 量化1.8b模型 `lmdeploy chat /root/models/internlm2_5-1_8b-chat-w4a16-4bit/ --model-format awq 模型量化结果 测试 占用 kv量化 占用

LMDeploy 量化部署进阶实践
1 配置LMDeploy环境 1.1 InternStudio开发机创建与环境搭建 打开InternStudio平台,进入如下界面并按箭头指示顺序点击创建开发机。 点选开发机,自拟一个开发机名称,选择Cuda12.2-conda镜像。 我们要运行参数量为7B的InternLM2.5,由InternLM2.5的码仓查询InternLM2.5-7b-chat的config.js

【#第三期实战营闯关作业##LMDeploy 量化部署进阶实践 】
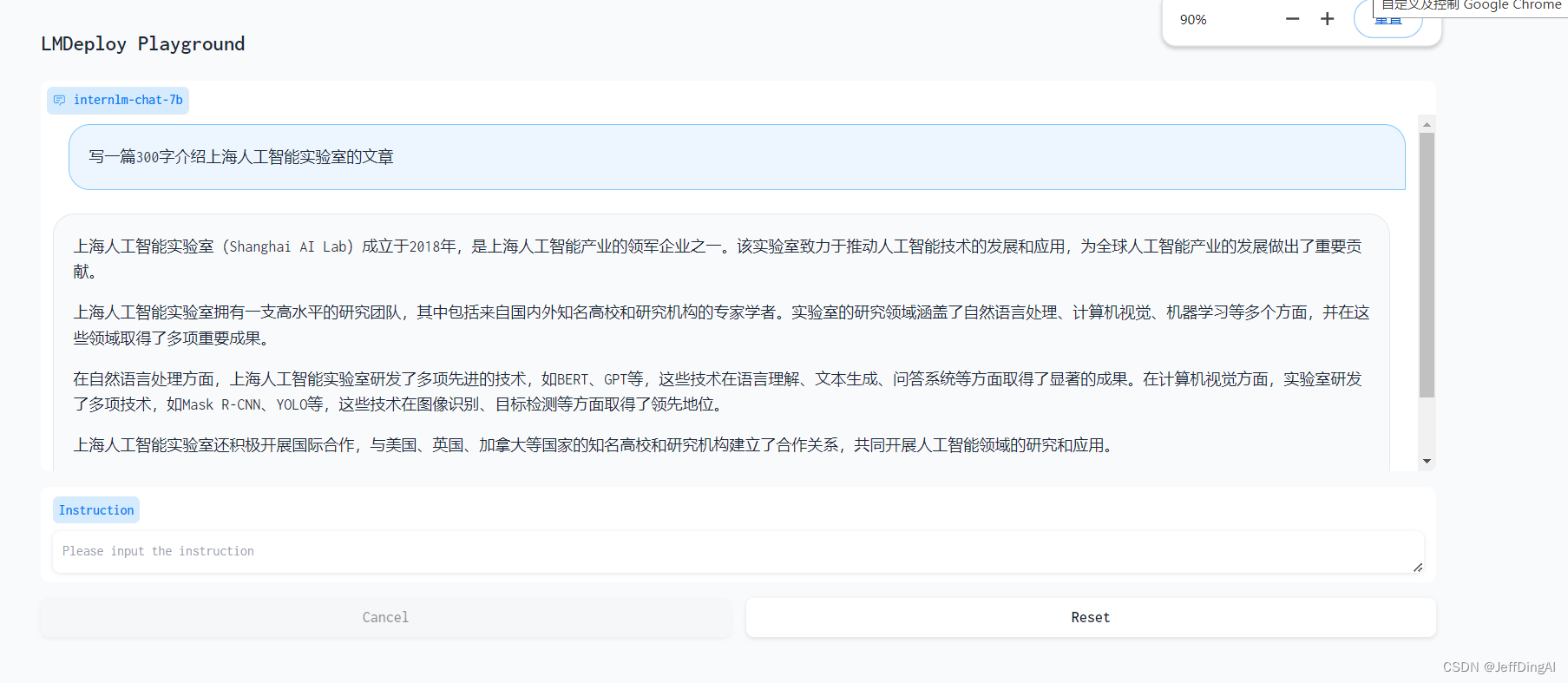
今天学习了《LMDeploy 量化部署进阶实践》一课,,收获很大。以下是记录复现过程及截图: 创建一个名为lmdeploy的conda环境 创建成功后激活环境并安装0.5.3版本的lmdeploy及相关包。 相关包install成功 创建好的conda环境并启动InternLM2_5-7b-chat。这是对话截图 运行InternLM2.5 -20B模型,会发现此时显存占用大约71G:单卡80

LMDeploy的KV Cache管理器可以通过设置--cache-max-entry-count参数 TurboMind理解
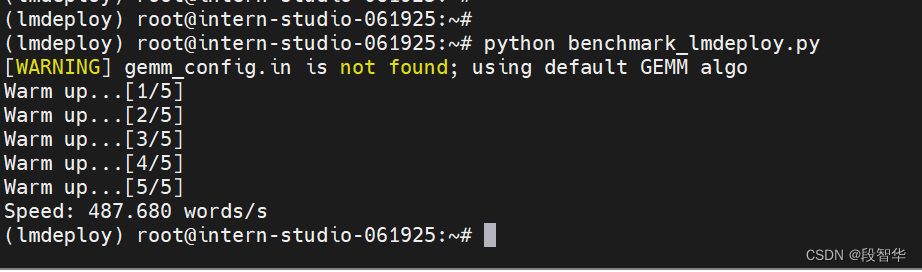
参考https://blog.csdn.net/m0_65719612/article/details/138634868 模型在运行时,占用的显存可大致分为三部分:模型参数本身占用的显存、KV Cache占用的显存,以及中间运算结果占用的显存。LMDeploy的KV Cache管理器可以通过设置–cache-max-entry-count参数,控制KV缓存占用剩余显存的最大比例。默认的比例为0

【书生大模型实战营(暑假场)】进阶任务三 LMDeploy 量化部署实践闯关任务
进阶任务三 LMDeploy 量化部署实践闯关任务 任务文档视频 1 大模型部署基本知识 1.1 LMDeploy部署模型 定义 在软件工程中,部署通常指的是将开发完毕的软件投入使用的过程。在人工智能领域,模型部署是实现深度学习算法落地应用的关键步骤。简单来说,模型部署就是将训练好的深度学习模型在特定环境中运行的过程。 场景 服务器端:CPU部署,单GPU/TPU/NPU部署,多卡/

书生.浦江大模型实战训练营——(十一)LMDeploy 量化部署进阶实践
最近在学习书生.浦江大模型实战训练营,所有课程都免费,以关卡的形式学习,也比较有意思,提供免费的算力实战,真的很不错(无广)!欢迎大家一起学习,打开LLM探索大门:邀请连接,PS,邀请有算力哈哈。 文章目录 一、环境配置二、LMDeploy和InternLM2.52.1 LMDeploy API部署InternLM2.52.2 LMDeploy Lite 三. LMDeploy之

书生浦语大模型实战营:LMDeploy量化部署
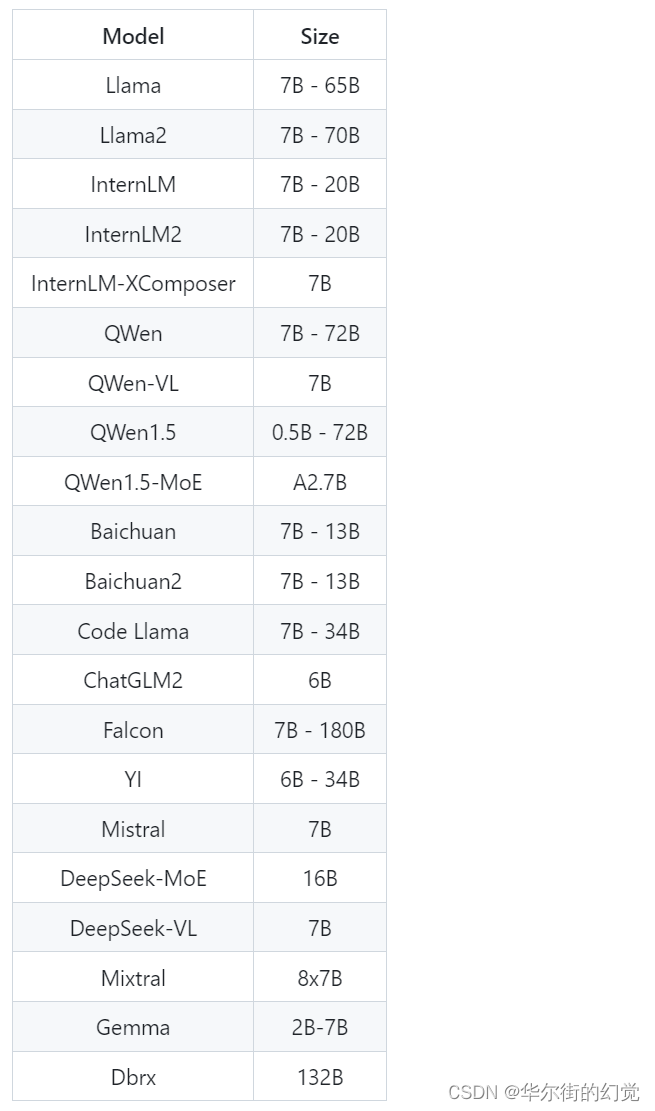
1.任务: 使用结合W4A16量化与kv cache量化的internlm2_5-1_8b-chat模型封装本地API并与大模型进行一次对话。 2.背景: 1.计算模型需要的权重大小: 1B代表10个亿参数,假如是16位浮点数(f16),也就是2个Byte,则模型的权重大小为:1 * 10^9 * 2 = 2GB;假如是20B,则权重大小为40GB。 2.背景存在问题: 实际上不止40GB

第三期书生大模型实战营 进阶岛第3关LMDeploy 量化部署进阶实践
环境准备 conda create -n lmdeploy python=3.10 -yconda activate lmdeployconda install pytorch==2.1.2 torchvision==0.16.2 torchaudio==2.1.2 pytorch-cuda=12.1 -c pytorch -c nvidia -ypip install timm==1.

LMDeploy 量化部署
LMDeploy简介 LMDeploy是一个由MMDeploy和MMRazor团队联合开发的工具包,旨在为大型语言模型(LLM)提供全套的轻量化、部署和服务解决方案。以下是对LMDeploy的简介,采用分点表示和归纳的方式: 核心功能: 高效推理引擎TurboMind:基于FasterTransformer,实现了高效推理引擎TurboMind,支持InternLM、LLaMA、vicu
![[书生·浦语大模型实战营]——LMDeploy 量化部署 LLM 实践](https://img-blog.csdnimg.cn/direct/9b284c3d82b7450788e3cc75181b6972.png)
[书生·浦语大模型实战营]——LMDeploy 量化部署 LLM 实践
1.基础作业 1.1配置 LMDeploy 运行环境 创建开发机 创建新的开发机,选择镜像Cuda12.2-conda;选择10% A100*1GPU;点击“立即创建”。注意请不要选择Cuda11.7-conda的镜像,新版本的lmdeploy会出现兼容性问题。其他和之前一样,不赘述。 创建conda环境 studio-conda -t lmdeploy -o pytorch-2.1.2

LMDeploy Windows 平台最佳实践
Windows 是全球范围内最流行的操作系统之一,许多企业和个人用户都在使用 Windows 系统。通过在 Windows 系统上支持 LLM 的推理,许多办公软件、聊天应用等都可以受益于 LLM 的技术,为用户提供更智能、更个性化的服务。LMDeploy 支持在 Windows 平台进行部署与使用,本文会从以下几个部分,介绍如何使用 LMDeploy 部署 internlm2-chat-1_8b
五一超级课堂---Llama3-Tutorial(Llama 3 超级课堂)---第四节Llama 3 高效部署实践(LMDeploy 版)
课程文档: https://github.com/SmartFlowAI/Llama3-Tutorial 课程视频: https://space.bilibili.com/3546636263360696/channel/collectiondetail?sid=2892740&spm_id_from=333.788.0.0 操作平台: https://studio.intern-ai.org.c

Llama3-Tutorial之LMDeploy高效部署Llama3实践
Llama3-Tutorial之LMDeploy高效部署Llama3实践 Llama 3 近期重磅发布,发布了 8B 和 70B 参数量的模型,lmdeploy团队对 Llama 3 部署进行了光速支持!!! 书生·浦语和机智流社区同学光速投稿了 LMDeploy 高效量化部署 Llama 3,欢迎 Star。 https://github.com/internLM/LMDeploy 参考: h

使用LMDeploy部署和量化Llama 3模型
## 引言 在人工智能领域,大型语言模型(LLMs)正变得越来越重要,它们在各种自然语言处理任务中发挥着关键作用。Llama 3是近期发布的一款具有8B和70B参数量的模型,它在性能和效率方面都取得了显著的进步。为了简化Llama 3的部署和量化过程,lmdeploy团队提供了强大的支持。本文将详细介绍如何使用LMDeploy工具来部署和量化Llama 3模型,以及如何运行视觉多模态大模型Llav

LMDeploy量化部署LLMVLM实践-笔记五
本次课程由西北工业大学博士生、书生·浦源挑战赛冠军队伍队长、第一期书生·浦语大模型实战营优秀学员【安泓郡】讲解【OpenCompass 大模型评测实战】课程 课程视频:https://www.bilibili.com/video/BV1tr421x75B/ 课程文档:https://github.com/InternLM/Tutorial/blob/camp2/lmdeploy/READ

书生·浦语大模型实战营之Llama 3 高效部署实践(LMDeploy 版)
书生·浦语大模型实战营之Llama 3 高效部署实践(LMDeploy 版) 环境,模型准备LMDeploy chatTurmind和Transformer的速度对比LMDeploy模型量化(lite)LMDeploy服务(serve) 环境,模型准备 InternStudio 可以直接使用 studio-conda -t Llama3_lmdeploy
书生·浦语2.0(InternLM2)大模型实战--Day03 LMDeploy量化部署 | LLMVLM实战
课程视频:https://www.bilibili.com/video/BV1tr421x75B/课程文档:https://github.com/InternLM/Tutorial/blob/camp2/lmdeploy/README.md课程作业:https://github.com/InternLM/Tutorial/blob/camp2/lmdeploy/homework.md平台:In
书生·浦语大模型实战营之LMDeploy 量化部署 LLM-VLM 实践
书生·浦语大模型实战营之LMDeploy 量化部署 LLM-VLM 实践 创建开发机 打开InternStudio平台,创建开发机。 填写开发机名称;选择镜像Cuda12.2-conda;选择10% A100*1GPU;点击“立即创建”。注意请不要选择Cuda11.7-conda的镜像,新版本的lmdeploy会出现兼容性问题。 studio-conda -t lmdepl
【InternLM 实战营笔记】LMDeploy 的量化和部署
环境配置 vgpu-smi 查看显卡资源使用情况 新开一个终端执行下面的命令实时观察 GPU 资源的使用情况。 watch vgpu-smi 复制环境到我们自己的 conda 环境 /root/share/install_conda_env_internlm_base.sh lmdeploy 激活环境 conda activate lmdeploy 安装依赖库 # 解决 M
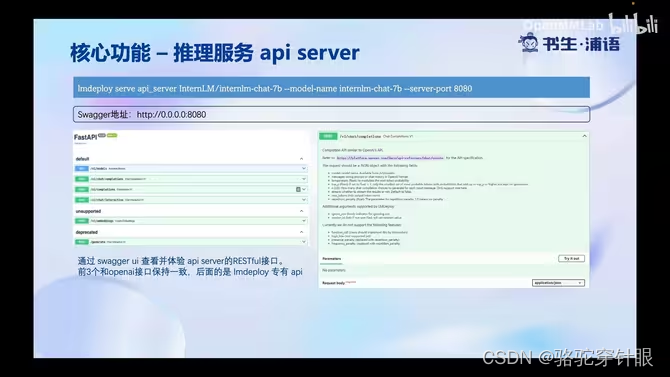
LMDeploy 大模型量化部署
Weight Only量化是一种常见的模型优化技术,特别是在深度学习模型的部署中。这种技术仅对模型的权重进行量化,而不涉及激活(即模型中间层的输出)。选择采用Weight Only量化的原因主要包括以下几点: 减少模型大小 通过将权重从浮点数(如32位的float)量化到较低位数的表示(如8位或16位的整数),可以显著减小模型的存储大小。这对于需要在资源受限的设备上部署模型的场景尤其重要,如移

第五次作业:LMDeploy 的量化和部署
参考文档:https://github.com/InternLM/tutorial/blob/main/lmdeploy/lmdeploy.md 基础作业: 使用 LMDeploy 以本地对话、网页Gradio、API服务中的一种方式部署 InternLM-Chat-7B 模型,生成 300 字的小故事(需截图) 2.1 模型转换 (1)在线转换 直接启动本地的 Huggingface 模型
第五节笔记:LMDeploy 大模型量化部署实践
大模型部署背景 参数用FP16半精度也就是2字节,7B的模型就大约占14G 2.LMDeploy简介 量化降低显存需求量,提高推理速度 大语言模型推理是典型的访问密集型,因为是decoder only的架构,需要token by token的生成,因此需要频繁读取之前生成过的token。 这个量化只是在存储时做的, 在推理时还要反量化回FP16. w4a16意思是参数4bit量化
![第五课[lmdeploy]作业 +第六课[OpenCompass评测]作业](https://img-blog.csdnimg.cn/direct/f5b14ebb924347569eb5dc1c64c82098.png)
第五课[lmdeploy]作业 +第六课[OpenCompass评测]作业
第五课基础作业 如下图,采用api_server部署,并转发端口通过curl提交内容。 第六课基础作业 完了捏?
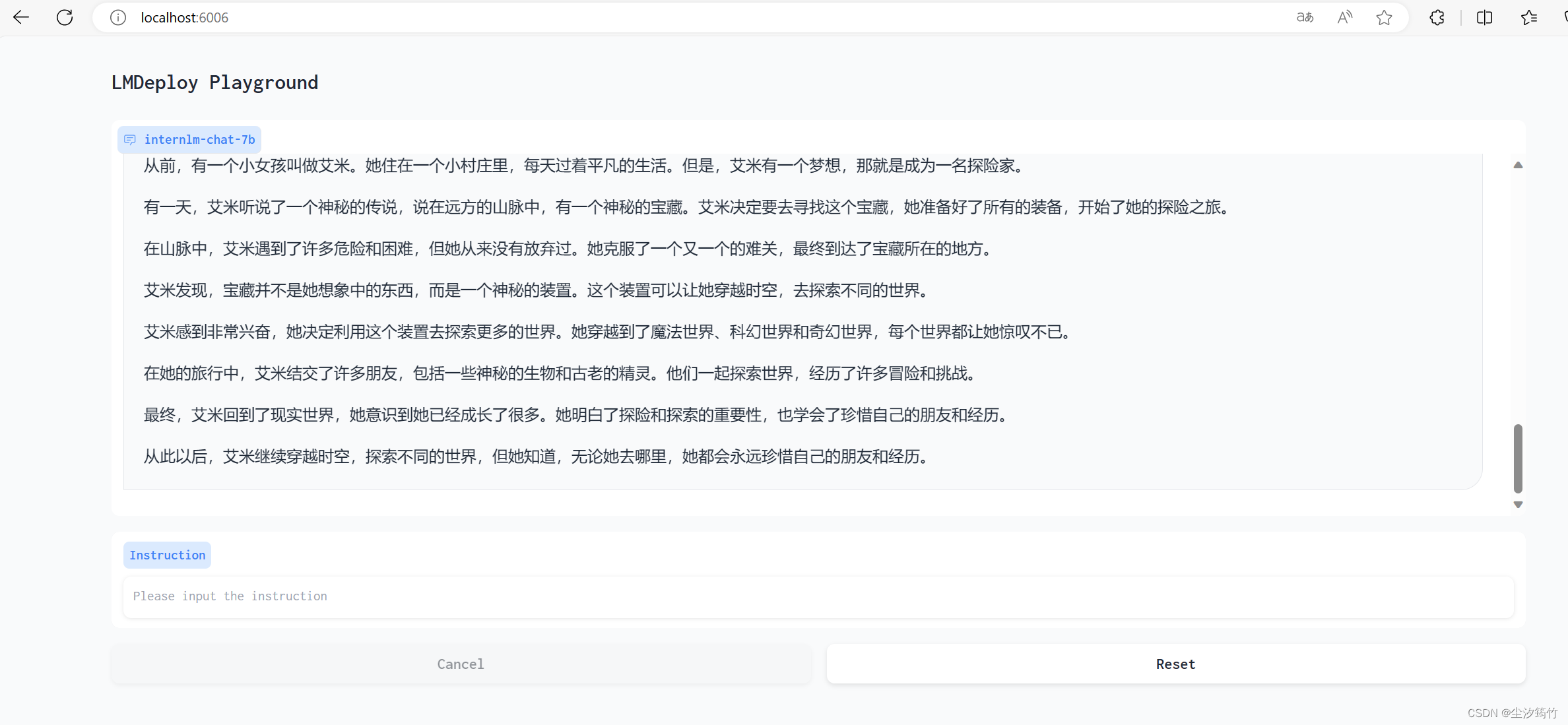
【LMDeploy 大模型量化部署实践】学习笔记
参考学习教程【LMDeploy 的量化和部署】 理论 作业 使用 LMDeploy 以本地对话、网页Gradio、API服务中的一种方式部署 InternLM-Chat-7B 模型,生成 300 字的小故事 本地对话 API服务 Client 命令 端口转发 网页Gradio