本文主要是介绍LMDeploy 大模型量化部署,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Weight Only量化是一种常见的模型优化技术,特别是在深度学习模型的部署中。这种技术仅对模型的权重进行量化,而不涉及激活(即模型中间层的输出)。选择采用Weight Only量化的原因主要包括以下几点:
-
减少模型大小
通过将权重从浮点数(如32位的float)量化到较低位数的表示(如8位或16位的整数),可以显著减小模型的存储大小。这对于需要在资源受限的设备上部署模型的场景尤其重要,如移动设备、嵌入式系统等,因为这些设备的存储空间和内存通常非常有限。 -
加速推理
权重量化可以减少模型的计算需求,因为使用较低位宽的运算通常比浮点运算要快。这意味着模型的推理速度可以得到提升,特别是在不支持高效浮点运算的硬件上。此外,减少的权重大小也意味着可以减少内存带宽需求,进一步加速模型的推理过程。 -
降低能耗
在移动和嵌入式设备上,能耗是一个重要的考虑因素。权重量化通过减少计算量和存储需求,可以有效降低设备的能耗,延长电池寿命。 -
保持激活的动态范围
仅对权重进行量化,而不量化激活,可以保持激活的动态范围,从而在一定程度上维持模型的精度。激活的动态范围通常比权重更大,直接量化激活可能会导致更大的信息损失。因此,Weight Only量化是一种在减少模型大小和计算需求与保持模型精度之间寻求平衡的方法。 -
简化部署流程
相比全面的量化(包括权重和激活),Weight Only量化过程相对简单,对模型的推理流程影响较小。这使得模型的量化和后续部署过程更加简化,便于实现和测试。## 大模型部署背景
模型部署
- 模型部署指的是将机器学习或深度学习模型集成到现有的生产环境中,以便它们可以接收输入数据并提供决策支持或预测。模型部署是机器学习项目生命周期的一个重要环节,它标志着模型从开发阶段过渡到实际应用阶段。
- 为了满足性能和效率的需求,常常需要对模型进行优化,例如模型压缩和模型加速
产品形态
-
API服务: 将模型部署为API服务是一种常见形式,允许其他应用程序通过网络请求与模型交互。这种方式使得模型能够被不同的客户端和服务调用,便于集成和扩展。
-
嵌入式系统: 在一些场景下,模型可能会被部署到嵌入式系统中,如智能设备、物联网(IoT)设备或移动设备。这种情况下,模型直接在设备上运行,可以提供实时或近实时的预测,适用于对延迟敏感或网络连接受限的应用。
-
云平台: 利用云计算资源,可以将模型部署到云平台上,利用云服务提供的弹性计算和存储资源。这种方式便于管理和扩展,特别适合处理大规模数据和需求波动较大的场景。
-
边缘计算: 在边缘计算场景中,模型被部署在靠近数据源的边缘设备上,例如安全摄像头、工业控制系统等。这样可以减少数据传输延迟和带宽需求,提高响应速度和数据处理效率。
计算设备
-
CPU: 通用计算处理器,适用于不需要高度并行处理的任务或小规模数据处理。
-
GPU: 图形处理单元,特别适合进行大规模并行计算,广泛应用于深度学习模型的训练和推理,可以显著加快计算速度。
-
TPU: 张量处理单元,由谷歌专为深度学习设计的定制硬件,可以提供极高的计算效率和吞吐量。
-
FPGA: 可编程逻辑门阵列,可定制的硬件加速器,适用于特定应用的高效计算,如图像处理和机器视觉。
-
移动设备芯片: 如智能手机、平板电脑和其他智能设备中的芯片,这些专为低功耗设计的芯片可以直接运行模型,支持边缘计算应用。
大模型特点
-
大量参数
-
亿级别或更多参数:大模型如GPT-3、BERT-large等拥有从几亿到数十亿甚至上百亿的参数。
-
深层网络结构:这些模型通常包含大量的层,包括隐藏层、注意力层等,以支持复杂的数据表示和处理。
-
庞大的参数量。7B模型仅仅权重需要14+G 内存
-
采用了自回归生成token,需要缓存Attention的k/V,带来巨大的内存开销
-
动态shape
-
请求数不固定
-
Token逐个不固定
-
相对视觉模型,LLM结构简单
-
Transformers 结构,大部分是decoder-only
大模型部署挑战
设备
- 低存储设备如何部署?
推理
- 如何加速token的生成速度 如何有效管理和利用内存。
服务
- 如何提升系统整体的吞吐量
- 如何降低个体用户的响应时长
一些方案
- huggingface transformers
- 专门的推理加速方案
- 模型并行
- 低比特量化
- page Attention
- transformer 计算访问、储存优化
- Continuous Batch
-
云服务部署
使用云计算平台:云平台如AWS、Google Cloud Platform或Azure提供强大的计算资源和灵活的部署选项,能够支持大模型的高性能需求。
优势:易于扩展,可根据需求动态调整计算资源;减轻本地硬件成本和维护负担;提供高可用性和灾难恢复能力。
应用场景:适用于需要高度可扩展性和灵活性的企业级应用。 -
边缘计算部署
部署在边缘设备上:将模型部署在接近数据源的边缘设备上,如智能手机、IoT设备或本地服务器。
优势:减少数据传输延迟,提高响应速度;减少对中央服务器的带宽需求;增强数据隐私和安全性。
应用场景:适用于对实时性要求高、数据敏感或网络连接受限的场景。
LMDeploy 简介
LMDeploy是LLM在英伟达设备上部署的全流程解决方案。包括模型轻量化、推理和服务
LMDeploy

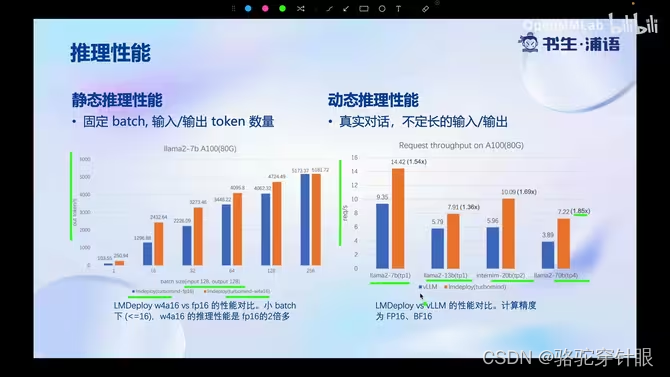
性能对比
LMDeploy核心功能-量化
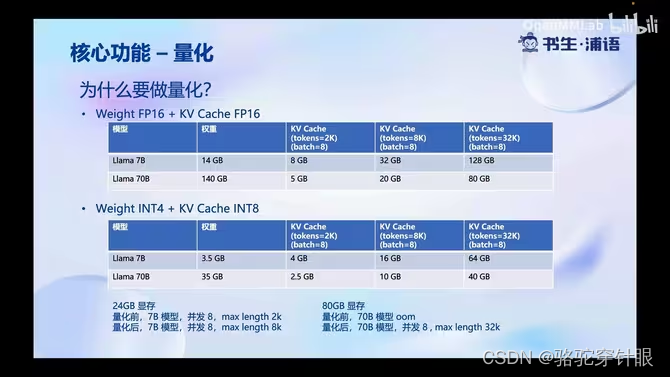
做Weight Only量化原因
Weight Only量化是一种常见的模型优化技术,特别是在深度学习模型的部署中。这种技术仅对模型的权重进行量化,而不涉及激活(即模型中间层的输出)。选择采用Weight Only量化的原因主要包括以下几点:
-
减少模型大小
通过将权重从浮点数(如32位的float)量化到较低位数的表示(如8位或16位的整数),可以显著减小模型的存储大小。这对于需要在资源受限的设备上部署模型的场景尤其重要,如移动设备、嵌入式系统等,因为这些设备的存储空间和内存通常非常有限。 -
加速推理
权重量化可以减少模型的计算需求,因为使用较低位宽的运算通常比浮点运算要快。这意味着模型的推理速度可以得到提升,特别是在不支持高效浮点运算的硬件上。此外,减少的权重大小也意味着可以减少内存带宽需求,进一步加速模型的推理过程。 -
降低能耗
在移动和嵌入式设备上,能耗是一个重要的考虑因素。权重量化通过减少计算量和存储需求,可以有效降低设备的能耗,延长电池寿命。 -
保持激活的动态范围
仅对权重进行量化,而不量化激活,可以保持激活的动态范围,从而在一定程度上维持模型的精度。激活的动态范围通常比权重更大,直接量化激活可能会导致更大的信息损失。因此,Weight Only量化是一种在减少模型大小和计算需求与保持模型精度之间寻求平衡的方法。 -
简化部署流程
相比全面的量化(包括权重和激活),Weight Only量化过程相对简单,对模型的推理流程影响较小。这使得模型的量化和后续部署过程更加简化,便于实现和测试。

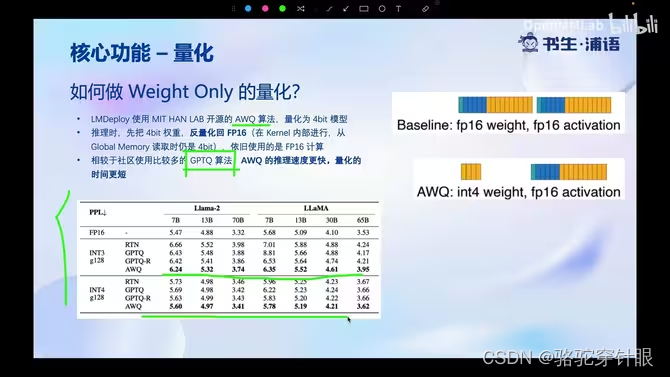
如何做?AWQ算法:4bi模型推理时权重反量化为FP16。比GPTQ更快。
AWQ(Activation-aware Weight Quantization)-激活感知权重量化的原理非常简单,就是计算一个scale系数tensor,shape为[k],k为矩阵乘的权重reduce的维度大小。对激活除以该tensor,并对矩阵乘的权重乘以该tensor,这降低了权重量化的难度,使得权重可以采用常规的group量化(直接根据最大最小值计算scale, zero point)。AWQ的核心技术一是这个对激活和权重应用scale的方法,另外就是如何计算这个scale tensor。因为激活是fp16不量化,对激活进行scale一般不会牺牲精度,因此可以对权重进行一些处理降低量化的难度。
虽然AWQ与GPTQ两者都采用group量化,对shape为[k, n]的矩阵乘权重都生成(k/group) * n套量化系数。但是GPTQ通常采用act_order=True选项,这个导致每一个group并非使用一组相同的scale和zero point系数,而是每个k位置对应的向量都对应不同的scale和zero point(不同k位置共享一组系数,但是这个位置是随机的),每读取一个元素都要读取scale和zero point,导致反量化效率很低。而act_order=False时,每一个向量group size元素都共享同一组scale和zero point系数,这样反量化只需要每隔group size个元素才需要重新读取一次scale和zero point,反量化效率很高。AWQ反量化跟GPTQ act_order=False是一样的,因此计算效率比较高。
核心功能-推理引擎TuboMind
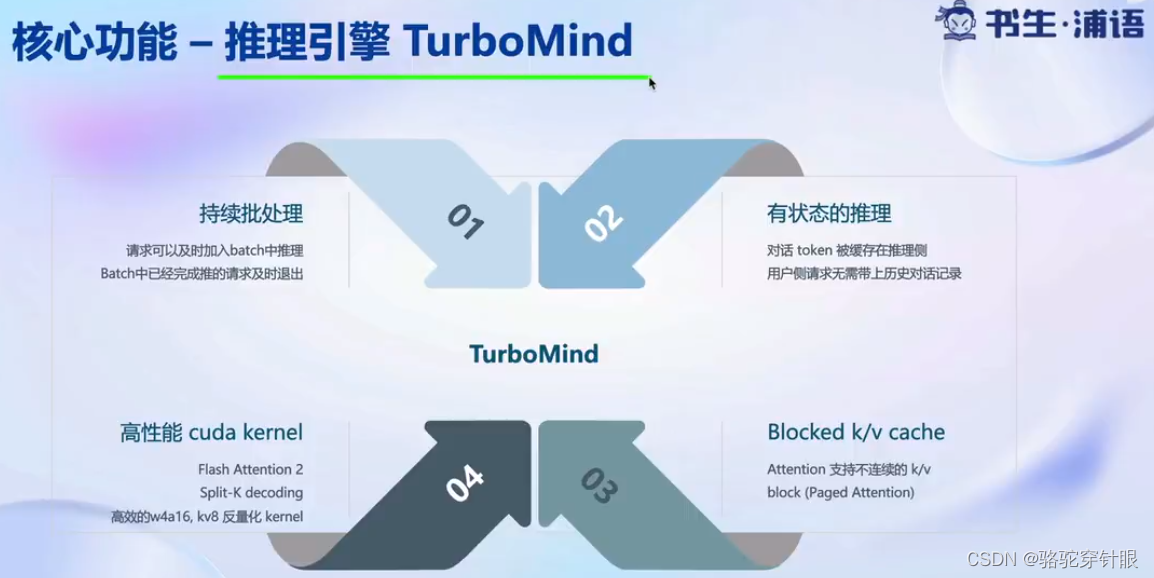
1.持续批处理
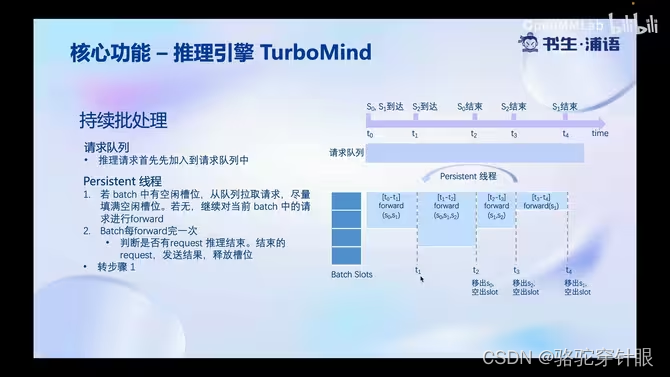
2.有状态推理
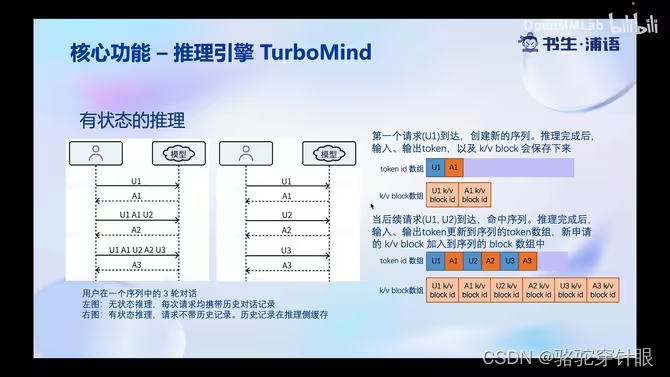
3.高性能 cuda kernel
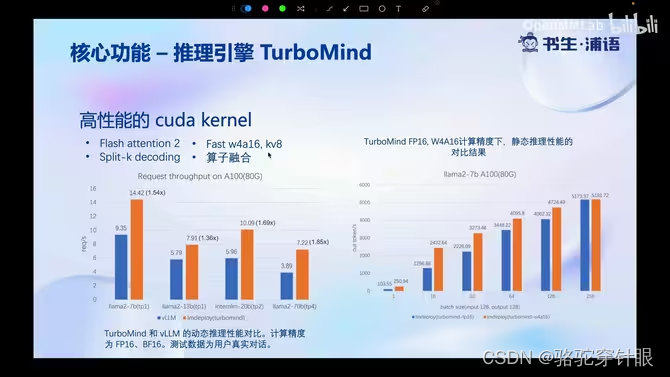
4.Block k/v cache
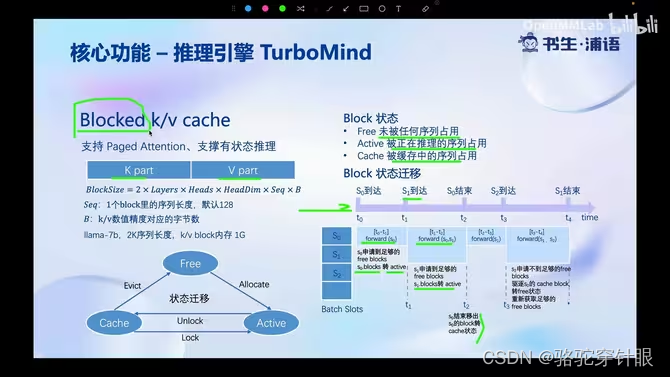
LMDeploy核心功能-推理服务 api server
这篇关于LMDeploy 大模型量化部署的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









