本文主要是介绍书生·浦语大模型实战营之LMDeploy 量化部署 LLM-VLM 实践,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
书生·浦语大模型实战营之LMDeploy 量化部署 LLM-VLM 实践



创建开发机
打开InternStudio平台,创建开发机。
填写开发机名称;选择镜像Cuda12.2-conda;选择10% A100*1GPU;点击“立即创建”。注意请不要选择Cuda11.7-conda的镜像,新版本的lmdeploy会出现兼容性问题。
studio-conda -t lmdeploy -o pytorch-2.1.2
安装LMDeploy
接下来,激活刚刚创建的虚拟环境。
conda activate lmdeploy
安装0.3.0版本的lmdeploy
pip install lmdeploy[all]==0.3.0

LMDeploy模型对话(chat)
Huggingface与TurboMind
- HuggingFace
HuggingFace是一个高速发展的社区,包括Meta、Google、Microsoft、Amazon在内的超过5000家组织机构在为HuggingFace开源社区贡献代码、数据集和模型
托管在HuggingFace社区的模型通常采用HuggingFace格式存储,简写为HF格式。
但是HuggingFace社区的服务器在国外,国内访问不太方便。国内可以使用阿里巴巴的MindScope社区,或者上海AI Lab搭建的OpenXLab社区,上面托管的模型也通常采用HF格式。
- TurboMind
TurboMind是LMDeploy团队开发的一款关于LLM推理的高效推理引擎,它的主要功能包括:LLaMa 结构模型的支持,continuous batch 推理模式和可扩展的 KV 缓存管理器。
TurboMind推理引擎仅支持推理TurboMind格式的模型。因此,TurboMind在推理HF格式的模型时,会首先自动将HF格式模型转换为TurboMind格式的模型。该过程在新版本的LMDeploy中是自动进行的,无需用户操作。
- TurboMind与LMDeploy的关系:LMDeploy是涵盖了LLM 任务全套轻量化、部署和服务解决方案的集成功能包,TurboMind是LMDeploy的一个推理引擎,是一个子模块。LMDeploy也可以使用pytorch作为推理引擎。
- TurboMind与TurboMind模型的关系:TurboMind是推理引擎的名字,TurboMind模型是一种模型存储格式,TurboMind引擎只能推理TurboMind格式的模型。
下载模型
本次实战营已经在开发机的共享目录中准备好了常用的预训练模型,可以运行如下命令查看
ls /root/share/new_models/Shanghai_AI_Laboratory/

执行如下指令由开发机的共享目录软链接或拷贝模型:
ln -s /root/share/new_models/Shanghai_AI_Laboratory/internlm2-chat-1_8b /root/
# cp -r /root/share/new_models/Shanghai_AI_Laboratory/internlm2-chat-1_8b /root/
在终端中输入如下指令,新建pipeline_transformer.py
vim /root/pipeline_transformer.py
import torch
from transformers import AutoTokenizer, AutoModelForCausalLMtokenizer = AutoTokenizer.from_pretrained("/root/internlm2-chat-1_8b", trust_remote_code=True)# Set `torch_dtype=torch.float16` to load model in float16, otherwise it will be loaded as float32 and cause OOM Error.
model = AutoModelForCausalLM.from_pretrained("/root/internlm2-chat-1_8b", torch_dtype=torch.float16, trust_remote_code=True).cuda()
model = model.eval()inp = "hello"
print("[INPUT]", inp)
response, history = model.chat(tokenizer, inp, history=[])
print("[OUTPUT]", response)inp = "please provide three suggestions about time management"
print("[INPUT]", inp)
response, history = model.chat(tokenizer, inp, history=history)
print("[OUTPUT]", response)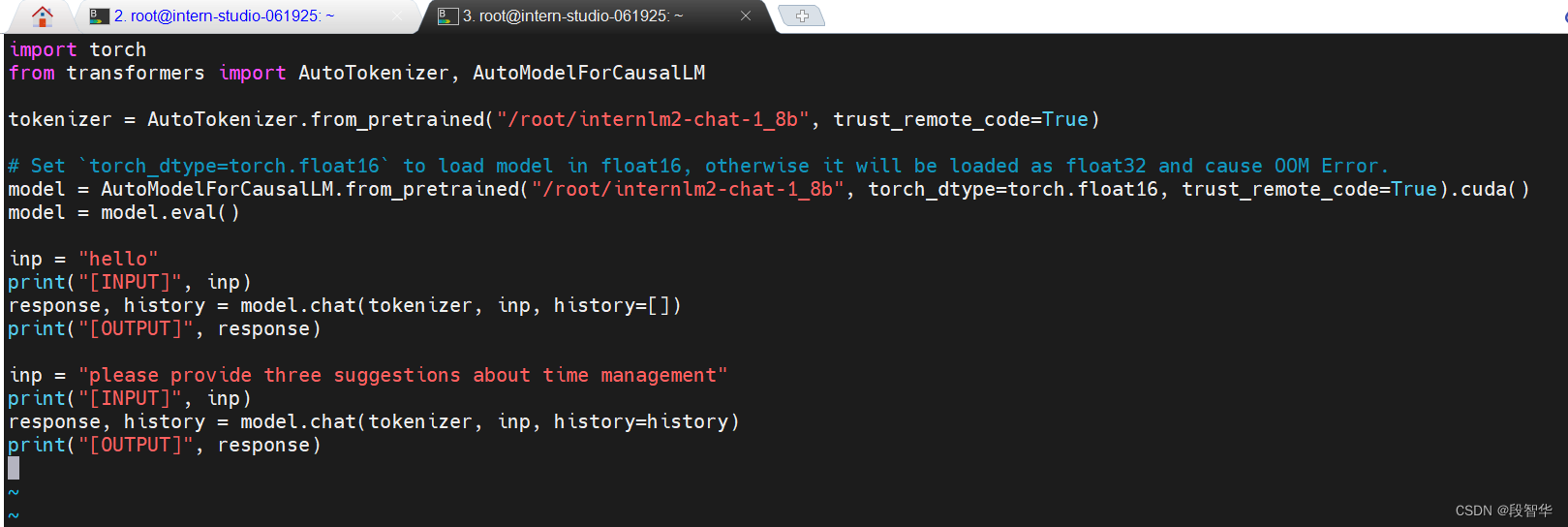
conda activate lmdeploy运行python代码:
python /root/pipeline_transformer.py
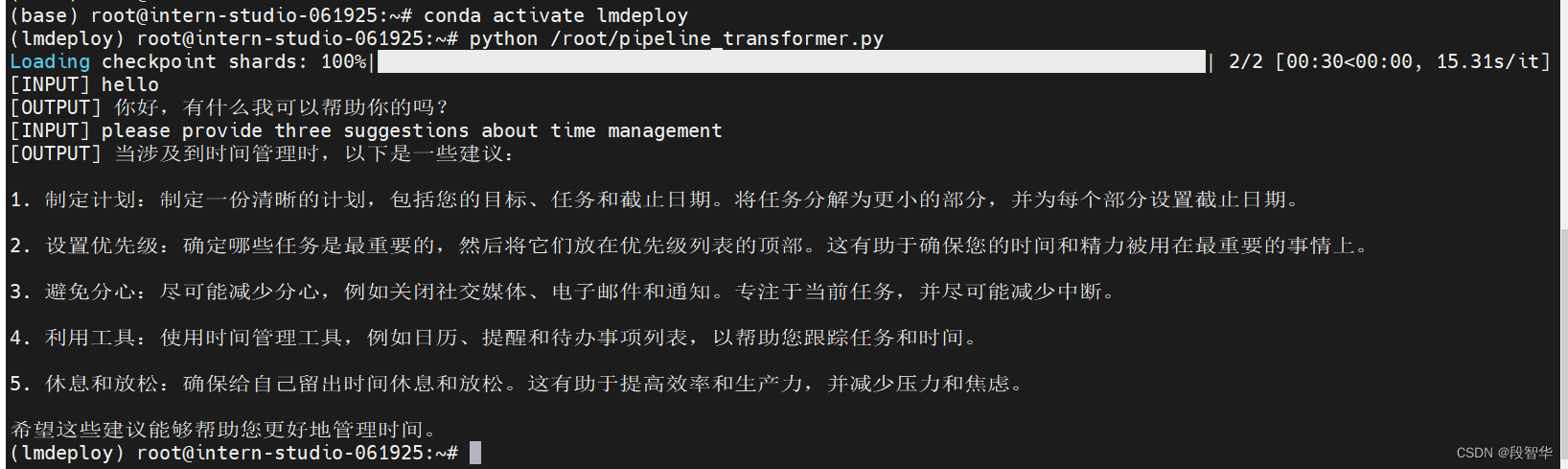
使用LMDeploy与模型对话
应用LMDeploy直接与模型进行对话。
使用LMDeploy与模型进行对话的通用命令格式为
lmdeploy chat [HF格式模型路径/TurboMind格式模型路径]
可以执行如下命令运行下载的1.8B模型:
lmdeploy chat /root/internlm2-chat-1_8b
(lmdeploy) root@intern-studio-061925:~# lmdeploy chat /root/internlm2-chat-1_8b
2024-04-11 16:21:37,565 - lmdeploy - WARNING - model_source: hf_model
2024-04-11 16:21:37,565 - lmdeploy - WARNING - kwargs max_batch_size is deprecated to initialize model, use TurbomindEngineConfig instead.
2024-04-11 16:21:37,565 - lmdeploy - WARNING - kwargs cache_max_entry_count is deprecated to initialize model, use TurbomindEngineConfig instead.
2024-04-11 16:21:40,956 - lmdeploy - WARNING - model_config:[llama]
model_name = internlm2
tensor_para_size = 1
head_num = 16
kv_head_num = 8
vocab_size = 92544
num_layer = 24
inter_size = 8192
norm_eps = 1e-05
attn_bias = 0
start_id = 1
end_id = 2
session_len = 32776
weight_type = bf16
rotary_embedding = 128
rope_theta = 1000000.0
size_per_head = 128
group_size = 0
max_batch_size = 128
max_context_token_num = 1
step_length = 1
cache_max_entry_count = 0.8
cache_block_seq_len = 64
cache_chunk_size = -1
num_tokens_per_iter = 0
max_prefill_iters = 1
extra_tokens_per_iter = 0
use_context_fmha = 1
quant_policy = 0
max_position_embeddings = 32768
rope_scaling_factor = 0.0
use_dynamic_ntk = 0
use_logn_attn = 02024-04-11 16:21:41,628 - lmdeploy - WARNING - get 195 model params
2024-04-11 16:22:00,321 - lmdeploy - WARNING - Input chat template with model_name is None. Forcing to use internlm2
[WARNING] gemm_config.in is not found; using default GEMM algo
session 1double enter to end input >>>
与InternLM2-Chat-1.8B大模型对话。输入“请给我讲一个小故事吧”,然后按两下回车键
double enter to end input >>> 请给我讲一个小故事吧<|im_start|>system
You are an AI assistant whose name is InternLM (书生·浦语).
- InternLM (书生·浦语) is a conversational language model that is developed by Shanghai AI Laboratory (上海人工智能实验室). It is designed to be helpful, honest, and harmless.
- InternLM (书生·浦语) can understand and communicate fluently in the language chosen by the user such as English and 中文.
<|im_end|>
<|im_start|>user
请给我讲一个小故事吧<|im_end|>
<|im_start|>assistant2024-04-11 16:27:46,877 - lmdeploy - WARNING - kwargs ignore_eos is deprecated for inference, use GenerationConfig instead.
2024-04-11 16:27:46,877 - lmdeploy - WARNING - kwargs random_seed is deprecated for inference, use GenerationConfig instead.当然,我可以给你讲一个关于一只小蝴蝶的故事。从前,有一只非常美丽的小蝴蝶。它拥有五彩斑斓的翅膀,每只翅膀上都缀满了闪亮的斑点,如同天空中最璀璨的星辰。小蝴蝶非常喜欢飞舞在花丛中,享受着阳光、微风和花香的包围。然而,有一天,小蝴蝶不小心掉到了一片黑暗的草丛中,它感到害怕和孤独。就在这时,一位智者出现了,他告诉小蝴蝶,要克服恐惧,需要勇气。于是,小蝴蝶鼓起勇气,开始努力地飞向远方。在接下来的几天里,小蝴蝶不仅学会了飞翔,也学会了在黑暗中寻找光明。它变得越来越自信,不再害怕那些未知的事物。最终,小蝴蝶成功地逃脱了草丛的束缚,飞向了广阔的天空。小蝴蝶的故事告诉我们,勇气和坚持是克服困难的关键,只要我们相信自己,勇敢前行,就能到达远方。无论是在哪里,只要你充满勇气,你就能找到属于自己的未来。double enter to end input >>>
<|im_start|>user
<|im_end|>
<|im_start|>assistant好的,这是一个非常励志的故事,我很高兴能够为你讲述它。如果你还有其他问题,或者需要更多故事内容,请随时告诉我,我会尽力帮助你。double enter to end input >>>
<|im_start|>user
<|im_end|>
<|im_start|>assistant好的,接下来再给你讲一个关于一只小老鼠的故事。从前,住在一座古老村庄里的有一只名叫小黄的小老鼠。小黄非常聪明,它常常能够找到宝藏和美味的点心。然而,小黄也有一个缺点,那就是它非常胆小,总是不敢靠近人类。有一天,村庄里来了一位新的居民,一位年轻的画家。他的画作吸引了每个人的注意力,他们都被他独特的风格和色彩所吸引。小黄很羡慕那些能见到这位新居民的人,它不禁感到有些羡慕和嫉妒。然而,小黄并没有放弃,它决定要变得更勇敢。它开始学习画,努力寻找灵感。最终,小黄的画作被一位富有的商人看中,他邀请小黄到他家中展示画作。在商人家的客厅里,小黄看到了最美丽的画作,它惊叹于画家的技艺和创意。然而,当它看到画作上的文字时,小黄才意识到自己原来也可以有自己的才艺。它开始学习文字,开始写自己的故事,并展示给人们欣赏。在艺术家的帮助下,小黄的画作变得更加丰富多彩,它也变得更加自信。最终,它的才艺被人们知道了,它也成为了村庄里最受欢迎的居民之一。小黄的故事告诉我们,每个人都有自己的特长和机会,只要我们不畏惧困难和挑战,只要我们坚持努力,最终,我们也能实现自己的梦想。无论我们面临什么困难和挑战,只要我们勇敢地面对,我们就能找到属于自己的成功之路。double enter to end input >>>输入“exit”并按两下回车,可以退出对话
拓展内容:有关LMDeploy的chat功能的更多参数可通过-h命令查看
lmdeploy chat -h
(lmdeploy) root@intern-studio-061925:~# lmdeploy chat -husage: lmdeploy chat [-h] [--backend {pytorch,turbomind}] [--trust-remote-code] [--meta-instruction META_INSTRUCTION][--cap {completion,infilling,chat,python}] [--adapters [ADAPTERS ...]] [--tp TP] [--model-name MODEL_NAME][--session-len SESSION_LEN] [--max-batch-size MAX_BATCH_SIZE] [--cache-max-entry-count CACHE_MAX_ENTRY_COUNT][--model-format {hf,llama,awq}] [--quant-policy QUANT_POLICY] [--rope-scaling-factor ROPE_SCALING_FACTOR]model_pathChat with pytorch or turbomind engine.positional arguments:model_path The path of a model. it could be one of the following options: - i) a local directory path of a turbomindmodel which is converted by `lmdeploy convert` command or download from ii) and iii). - ii) the model_id ofa lmdeploy-quantized model hosted inside a model repo on huggingface.co, such as "internlm/internlm-chat-20b-4bit", "lmdeploy/llama2-chat-70b-4bit", etc. - iii) the model_id of a model hosted inside a modelrepo on huggingface.co, such as "internlm/internlm-chat-7b", "qwen/qwen-7b-chat ", "baichuan-inc/baichuan2-7b-chat" and so on. Type: stroptions:-h, --help show this help message and exit--backend {pytorch,turbomind}Set the inference backend. Default: turbomind. Type: str--trust-remote-code Trust remote code for loading hf models. Default: True--meta-instruction META_INSTRUCTIONSystem prompt for ChatTemplateConfig. Deprecated. Please use --chat-template instead. Default: None. Type:str--cap {completion,infilling,chat,python}The capability of a model. Deprecated. Please use --chat-template instead. Default: chat. Type: strPyTorch engine arguments:--adapters [ADAPTERS ...]Used to set path(s) of lora adapter(s). One can input key-value pairs in xxx=yyy format for multiple loraadapters. If only have one adapter, one can only input the path of the adapter.. Default: None. Type: str--tp TP GPU number used in tensor parallelism. Should be 2^n. Default: 1. Type: int--model-name MODEL_NAMEThe name of the to-be-deployed model, such as llama-7b, llama-13b, vicuna-7b and etc. You can run `lmdeploylist` to get the supported model names. Default: None. Type: str--session-len SESSION_LENThe max session length of a sequence. Default: None. Type: int--max-batch-size MAX_BATCH_SIZEMaximum batch size. Default: 128. Type: int--cache-max-entry-count CACHE_MAX_ENTRY_COUNTThe percentage of gpu memory occupied by the k/v cache. Default: 0.8. Type: floatTurboMind engine arguments:--tp TP GPU number used in tensor parallelism. Should be 2^n. Default: 1. Type: int--model-name MODEL_NAMEThe name of the to-be-deployed model, such as llama-7b, llama-13b, vicuna-7b and etc. You can run `lmdeploylist` to get the supported model names. Default: None. Type: str--session-len SESSION_LENThe max session length of a sequence. Default: None. Type: int--max-batch-size MAX_BATCH_SIZEMaximum batch size. Default: 128. Type: int--cache-max-entry-count CACHE_MAX_ENTRY_COUNTThe percentage of gpu memory occupied by the k/v cache. Default: 0.8. Type: float--model-format {hf,llama,awq}The format of input model. `hf` meaning `hf_llama`, `llama` meaning `meta_llama`, `awq` meaning thequantized model by awq. Default: None. Type: str--quant-policy QUANT_POLICYWhether to use kv int8. Default: 0. Type: int--rope-scaling-factor ROPE_SCALING_FACTORRope scaling factor. Default: 0.0. Type: floatLMDeploy模型量化(lite)
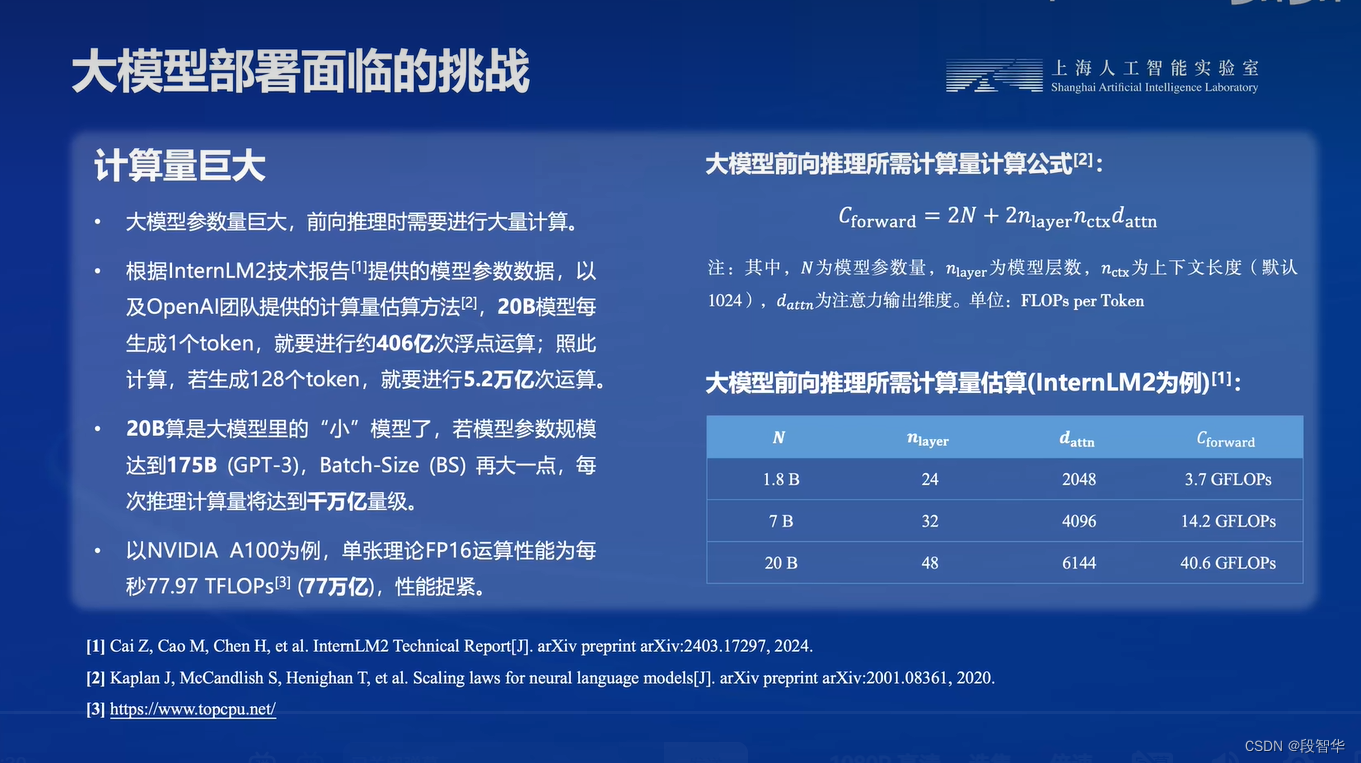
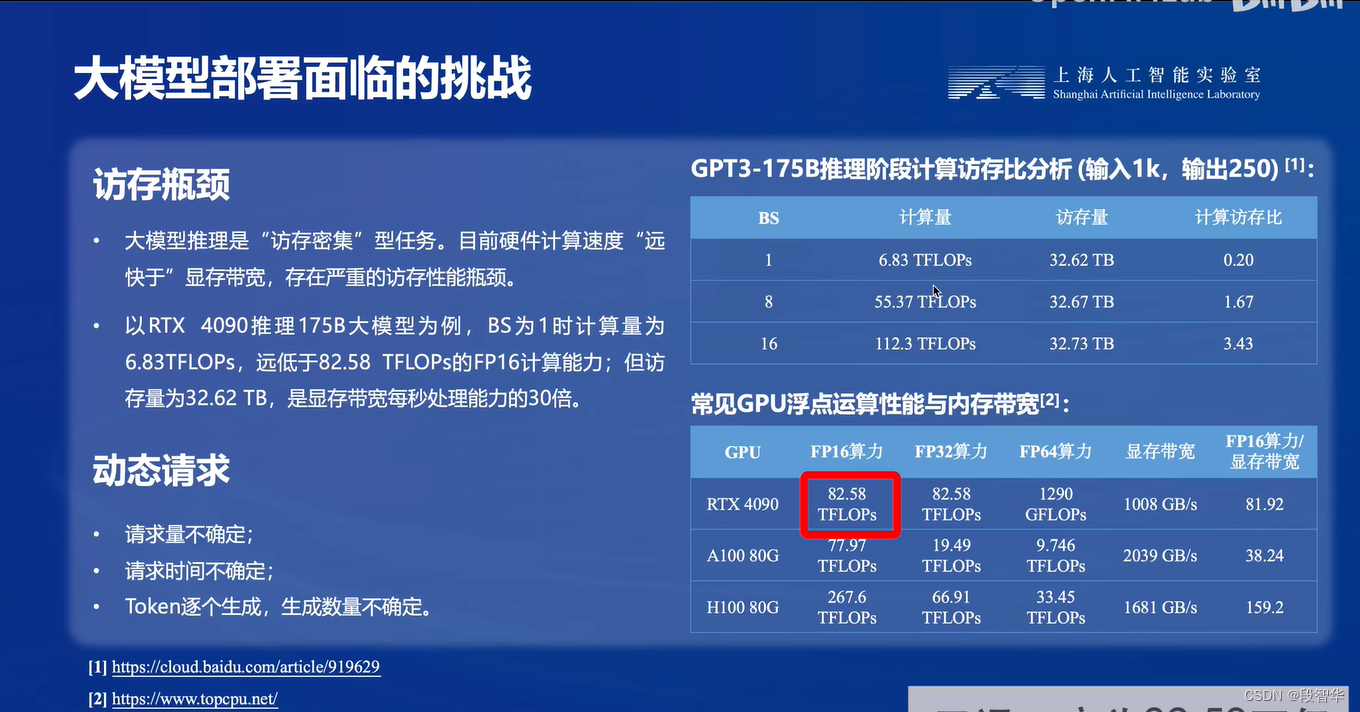
本部分内容主要介绍如何对模型进行量化。主要包括 KV8量化和W4A16量化。量化是一种以参数或计算中间结果精度下降换空间节省(以及同时带来的性能提升)的策略。
- 计算密集(compute-bound): 指推理过程中,绝大部分时间消耗在数值计算上;针对计算密集型场景,可以通过使用更快的硬件计算单元来提升计算速。
- 访存密集(memory-bound): 指推理过程中,绝大部分时间消耗在数据读取上;针对访存密集型场景,一般通过减少访存次数、提高计算访存比或降低访存量来优化。
常见的 LLM 模型由于 Decoder Only 架构的特性,实际推理时大多数的时间都消耗在了逐 Token 生成阶段(Decoding 阶段),是典型的访存密集型场景。
那么,如何优化 LLM 模型推理中的访存密集问题呢? 我们可以使用KV8量化和W4A16量化。
-
KV8量化是指将逐 Token(Decoding)生成过程中的上下文 K 和 V 中间结果进行 INT8 量化(计算时再反量化),以降低生成过程中的显存占用。
-
W4A16 量化,将 FP16 的模型权重量化为 INT4,Kernel 计算时,访存量直接降为 FP16 模型的 1/4,大幅降低了访存成本。Weight Only 是指仅量化权重,数值计算依然采用 FP16(需要将 INT4 权重反量化)
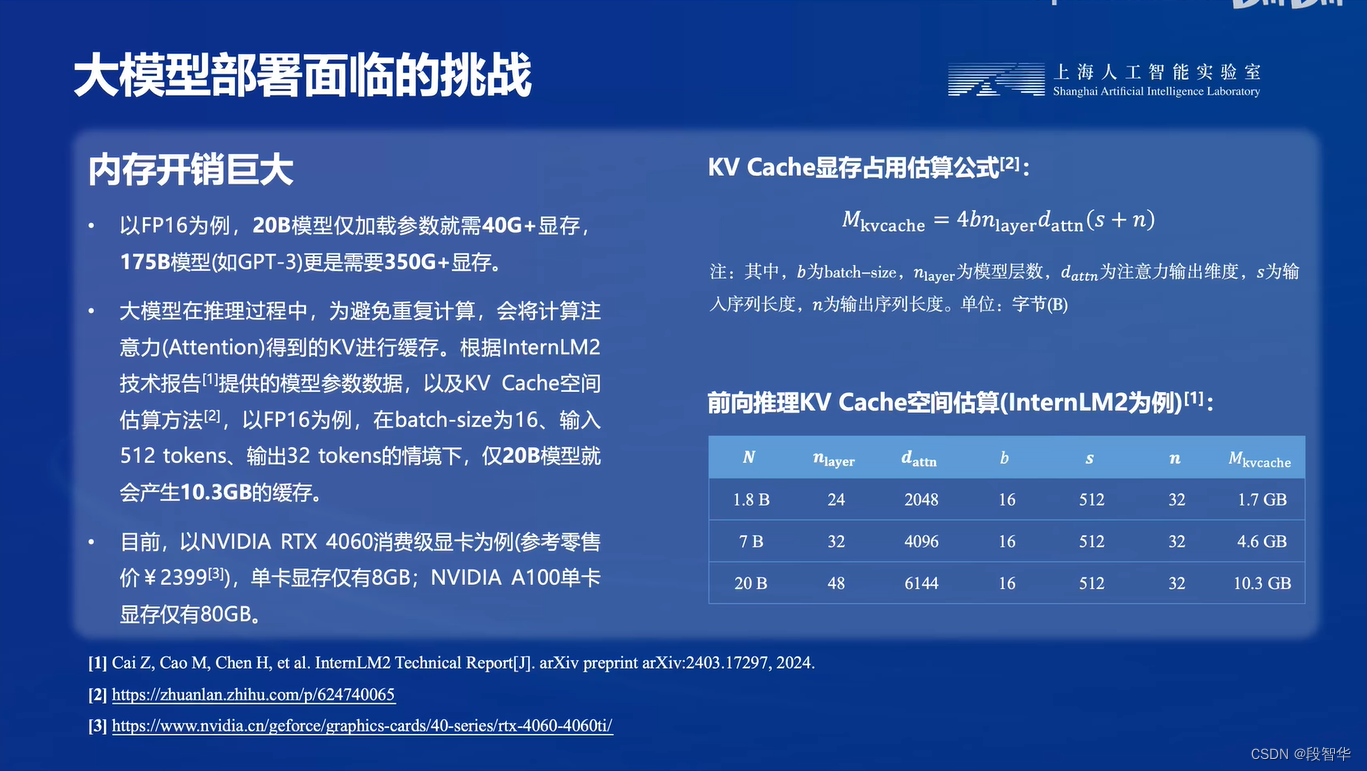
设置最大KV Cache缓存大小
KV Cache是一种缓存技术,通过存储键值对的形式来复用计算结果,以达到提高性能和降低内存消耗的目的。在大规模训练和推理中,KV Cache可以显著减少重复计算量,从而提升模型的推理速度。理想情况下,KV Cache全部存储于显存,以加快访存速度。当显存空间不足时,也可以将KV Cache放在内存,通过缓存管理器控制将当前需要使用的数据放入显存。
模型在运行时,占用的显存可大致分为三部分:
- 模型参数本身占用的显存、
- KV Cache占用的显存
- 以及中间运算结果占用的显存。
LMDeploy的KV Cache管理器可以通过设置–cache-max-entry-count参数,控制KV缓存占用剩余显存的最大比例。默认的比例为0.8。
下面通过几个例子,来看一下调整–cache-max-entry-count参数的效果。首先保持不加该参数(默认0.8),运行1.8B模型
lmdeploy chat /root/internlm2-chat-1_8b
(lmdeploy) root@intern-studio-061925:~# lmdeploy chat /root/internlm2-chat-1_8b
2024-04-11 16:38:07,201 - lmdeploy - WARNING - model_source: hf_model
2024-04-11 16:38:07,202 - lmdeploy - WARNING - kwargs max_batch_size is deprecated to initialize model, use TurbomindEngineConfig instead.
2024-04-11 16:38:07,202 - lmdeploy - WARNING - kwargs cache_max_entry_count is deprecated to initialize model, use TurbomindEngineConfig instead.
2024-04-11 16:38:10,353 - lmdeploy - WARNING - model_config:[llama]
model_name = internlm2
tensor_para_size = 1
head_num = 16
kv_head_num = 8
vocab_size = 92544
num_layer = 24
inter_size = 8192
norm_eps = 1e-05
attn_bias = 0
start_id = 1
end_id = 2
session_len = 32776
weight_type = bf16
rotary_embedding = 128
rope_theta = 1000000.0
size_per_head = 128
group_size = 0
max_batch_size = 128
max_context_token_num = 1
step_length = 1
cache_max_entry_count = 0.8
cache_block_seq_len = 64
cache_chunk_size = -1
num_tokens_per_iter = 0
max_prefill_iters = 1
extra_tokens_per_iter = 0
use_context_fmha = 1
quant_policy = 0
max_position_embeddings = 32768
rope_scaling_factor = 0.0
use_dynamic_ntk = 0
use_logn_attn = 02024-04-11 16:38:11,885 - lmdeploy - WARNING - get 195 model params
2024-04-11 16:38:30,314 - lmdeploy - WARNING - Input chat template with model_name is None. Forcing to use internlm2
[WARNING] gemm_config.in is not found; using default GEMM algo
session 1double enter to end input >>>此时显存占用为7816MB。
改变–cache-max-entry-count参数,设为0.5。
lmdeploy chat /root/internlm2-chat-1_8b --cache-max-entry-count 0.5
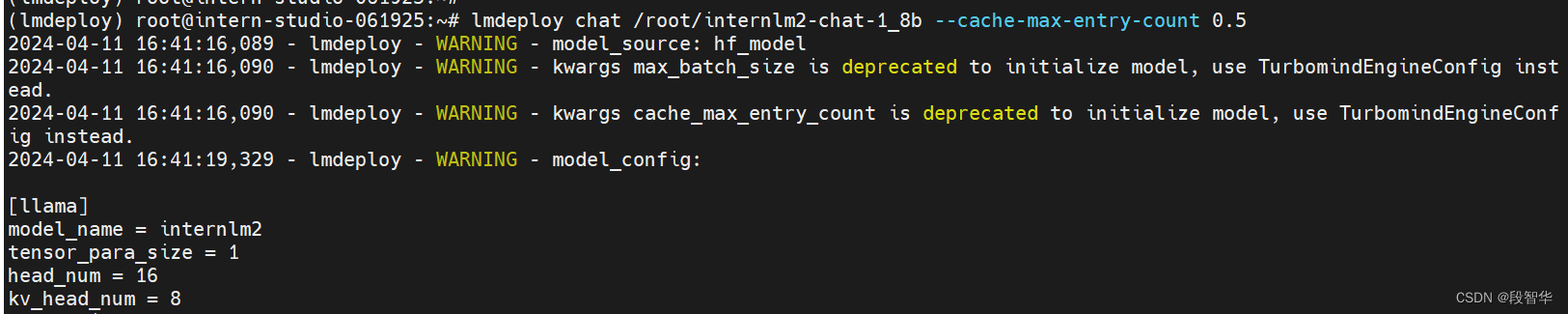
看到显存占用明显降低,变为6600M。
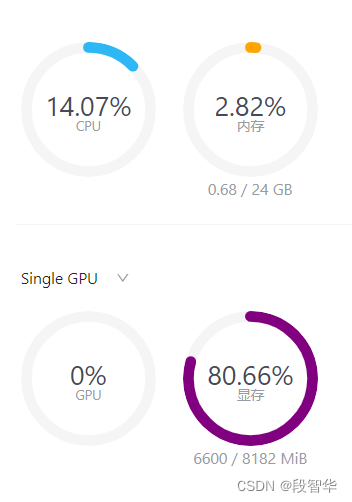
把–cache-max-entry-count参数设置为0.01,约等于禁止KV Cache占用显存。
lmdeploy chat /root/internlm2-chat-1_8b --cache-max-entry-count 0.01
(lmdeploy) root@intern-studio-061925:~# lmdeploy chat /root/internlm2-chat-1_8b --cache-max-entry-count 0.012024-04-11 16:45:14,771 - lmdeploy - WARNING - model_source: hf_model
2024-04-11 16:45:14,772 - lmdeploy - WARNING - kwargs max_batch_size is deprecated to initialize model, use TurbomindEngineConfig instead.
2024-04-11 16:45:14,772 - lmdeploy - WARNING - kwargs cache_max_entry_count is deprecated to initialize model, use TurbomindEngineConfig instead.
2024-04-11 16:45:18,016 - lmdeploy - WARNING - model_config:[llama]
model_name = internlm2
tensor_para_size = 1
head_num = 16
kv_head_num = 8
vocab_size = 92544
num_layer = 24
inter_size = 8192
norm_eps = 1e-05
attn_bias = 0
start_id = 1
end_id = 2
session_len = 32776
weight_type = bf16
rotary_embedding = 128
rope_theta = 1000000.0
size_per_head = 128
group_size = 0
max_batch_size = 128
max_context_token_num = 1
step_length = 1
cache_max_entry_count = 0.01
cache_block_seq_len = 64
cache_chunk_size = -1
num_tokens_per_iter = 0
max_prefill_iters = 1
extra_tokens_per_iter = 0
use_context_fmha = 1
quant_policy = 0
max_position_embeddings = 32768
rope_scaling_factor = 0.0
use_dynamic_ntk = 0
use_logn_attn = 02024-04-11 16:45:18,734 - lmdeploy - WARNING - get 195 model params
2024-04-11 16:45:38,126 - lmdeploy - WARNING - Input chat template with model_name is None. Forcing to use internlm2
[WARNING] gemm_config.in is not found; using default GEMM algo
session 1double enter to end input >>> <|im_start|>system
You are an AI assistant whose name is InternLM (书生·浦语).
- InternLM (书生·浦语) is a conversational language model that is developed by Shanghai AI Laboratory (上海人工智能实验室). It is designed to be helpful, honest, and harmless.
- InternLM (书生·浦语) can understand and communicate fluently in the language chosen by the user such as English and 中文.
<|im_end|>
<|im_start|>user
<|im_end|>
<|im_start|>assistant2024-04-11 16:45:38,612 - lmdeploy - WARNING - kwargs ignore_eos is deprecated for inference, use GenerationConfig instead.
2024-04-11 16:45:38,613 - lmdeploy - WARNING - kwargs random_seed is deprecated for inference, use GenerationConfig instead.
您好!我可以帮助您解答任何问题,无论是关于生活、科学、技术还是其他任何您感兴趣的主题。请随时向我提问,我会尽力为您提供有用和准确的信息。double enter to end input >>>
<|im_start|>user
<|im_end|>
<|im_start|>assistant您好!我可以帮助您解决任何问题。如果您需要获取任何信息,请告诉我您需要了解什么,我将为您提供尽可能准确和有用的信息。无论是关于生活、科学、技术还是其他任何您感兴趣的主题,我都会尽我所能地为您提供帮助。double enter to end input >>> hello<|im_start|>user
hello<|im_end|>
<|im_start|>assistant好的,您好!有什么我可以帮助
您的吗?double enter to end input >>>
<|im_start|>user
<|im_end|>
<|im_start|>assistant您好!请问有什么我可以帮您的吗?double enter to end input >>>此时显存占用仅为4560MB,代价是会降低模型推理速度。
使用W4A16量化
LMDeploy使用AWQ算法,实现模型4bit权重量化。推理引擎TurboMind提供了非常高效的4bit推理cuda kernel,性能是FP16的2.4倍以上。它支持以下NVIDIA显卡:
图灵架构(sm75):20系列、T4
安培架构(sm80,sm86):30系列、A10、A16、A30、A100
Ada Lovelace架构(sm90):40 系列
运行前,首先安装一个依赖库
pip install einops==0.7.0

执行一条命令,就可以完成模型量化工作
lmdeploy lite auto_awq \/root/internlm2-chat-1_8b \--calib-dataset 'ptb' \--calib-samples 128 \--calib-seqlen 1024 \--w-bits 4 \--w-group-size 128 \--work-dir /root/internlm2-chat-1_8b-4bit
运行时间较长,请耐心等待。量化工作结束后,新的HF模型被保存到internlm2-chat-1_8b-4bit目录。
(lmdeploy) root@intern-studio-061925:~# lmdeploy lite auto_awq \
> /root/internlm2-chat-1_8b \
> --calib-dataset 'ptb' \
> --calib-samples 128 \
> --calib-seqlen 1024 \
> --w-bits 4 \
> --w-group-size 128 \
> --work-dir /root/internlm2-chat-1_8b-4bitLoading checkpoint shards: 100%|████████████████████████████████████████████████████████████████████████| 2/2 [00:33<00:00, 16.93s/it]
Move model.tok_embeddings to GPU.
Move model.layers.0 to CPU.
Move model.layers.1 to CPU.
Move model.layers.2 to CPU.
Move model.layers.3 to CPU.
Move model.layers.4 to CPU.
Move model.layers.5 to CPU.
Move model.layers.6 to CPU.
Move model.layers.7 to CPU.
Move model.layers.8 to CPU.
Move model.layers.9 to CPU.
Move model.layers.10 to CPU.
Move model.layers.11 to CPU.
Move model.layers.12 to CPU.
Move model.layers.13 to CPU.
Move model.layers.14 to CPU.
Move model.layers.15 to CPU.
Move model.layers.16 to CPU.
Move model.layers.17 to CPU.
Move model.layers.18 to CPU.
Move model.layers.19 to CPU.
Move model.layers.20 to CPU.
Move model.layers.21 to CPU.
Move model.layers.22 to CPU.
Move model.layers.23 to CPU.
Move model.norm to GPU.
Move output to CPU.
Loading calibrate dataset ...
/root/.conda/envs/lmdeploy/lib/python3.10/site-packages/datasets/load.py:1461: FutureWarning: The repository for ptb_text_only contains custom code which must be executed to correctly load the dataset. You can inspect the repository content at https://hf.co/datasets/ptb_text_only
You can avoid this message in future by passing the argument `trust_remote_code=True`.
Passing `trust_remote_code=True` will be mandatory to load this dataset from the next major release of `datasets`.warnings.warn(
Downloading builder script: 6.50kB [00:00, 23.2MB/s]
Downloading readme: 4.21kB [00:00, 16.3MB/s]
Downloading data: 5.10MB [00:00, 16.5MB/s]
Downloading data: 400kB [00:06, 57.5kB/s]
Downloading data: 450kB [00:00, 624kB/s]
Generating train split: 100%|█████████████████████████████████████████████████████████| 42068/42068 [00:00<00:00, 94649.96 examples/s]
Generating test split: 100%|███████████████████████████████████████████████████████████| 3761/3761 [00:00<00:00, 107928.88 examples/s]
Generating validation split: 100%|██████████████████████████████████████████████████████| 3370/3370 [00:00<00:00, 94977.28 examples/s]
model.layers.0, samples: 128, max gpu memory: 2.25 GB
model.layers.1, samples: 128, max gpu memory: 2.75 GB
model.layers.2, samples: 128, max gpu memory: 2.75 GB
model.layers.3, samples: 128, max gpu memory: 2.75 GB
model.layers.4, samples: 128, max gpu memory: 2.75 GB
model.layers.5, samples: 128, max gpu memory: 2.75 GB
model.layers.6, samples: 128, max gpu memory: 2.75 GB
model.layers.7, samples: 128, max gpu memory: 2.75 GB
model.layers.8, samples: 128, max gpu memory: 2.75 GB
model.layers.9, samples: 128, max gpu memory: 2.75 GB
model.layers.10, samples: 128, max gpu memory: 2.75 GB
model.layers.11, samples: 128, max gpu memory: 2.75 GB
model.layers.12, samples: 128, max gpu memory: 2.75 GB
model.layers.13, samples: 128, max gpu memory: 2.75 GB
model.layers.14, samples: 128, max gpu memory: 2.75 GB
model.layers.15, samples: 128, max gpu memory: 2.75 GB
model.layers.16, samples: 128, max gpu memory: 2.75 GB
model.layers.17, samples: 128, max gpu memory: 2.75 GB
model.layers.18, samples: 128, max gpu memory: 2.75 GB
model.layers.19, samples: 128, max gpu memory: 2.75 GB
model.layers.20, samples: 128, max gpu memory: 2.75 GB
model.layers.21, samples: 128, max gpu memory: 2.75 GB
model.layers.22, samples: 128, max gpu memory: 2.75 GB
model.layers.23, samples: 128, max gpu memory: 2.75 GB
model.layers.0 smooth weight done.
model.layers.1 smooth weight done.
model.layers.2 smooth weight done.
model.layers.3 smooth weight done.
model.layers.4 smooth weight done.
model.layers.5 smooth weight done.
model.layers.6 smooth weight done.
model.layers.7 smooth weight done.
model.layers.8 smooth weight done.
model.layers.9 smooth weight done.
model.layers.10 smooth weight done.
model.layers.11 smooth weight done.
model.layers.12 smooth weight done.
model.layers.13 smooth weight done.
model.layers.14 smooth weight done.
model.layers.15 smooth weight done.
model.layers.16 smooth weight done.
model.layers.17 smooth weight done.
model.layers.18 smooth weight done.
model.layers.19 smooth weight done.
model.layers.20 smooth weight done.
model.layers.21 smooth weight done.
model.layers.22 smooth weight done.
model.layers.23 smooth weight done.
model.layers.0.attention.wqkv weight packed.
model.layers.0.attention.wo weight packed.
model.layers.0.feed_forward.w1 weight packed.
model.layers.0.feed_forward.w3 weight packed.
model.layers.0.feed_forward.w2 weight packed.
model.layers.1.attention.wqkv weight packed.
model.layers.1.attention.wo weight packed.
model.layers.1.feed_forward.w1 weight packed.
model.layers.1.feed_forward.w3 weight packed.
model.layers.1.feed_forward.w2 weight packed.
model.layers.2.attention.wqkv weight packed.
model.layers.2.attention.wo weight packed.
model.layers.2.feed_forward.w1 weight packed.
model.layers.2.feed_forward.w3 weight packed.
model.layers.2.feed_forward.w2 weight packed.
model.layers.3.attention.wqkv weight packed.
model.layers.3.attention.wo weight packed.
model.layers.3.feed_forward.w1 weight packed.
model.layers.3.feed_forward.w3 weight packed.
model.layers.3.feed_forward.w2 weight packed.
model.layers.4.attention.wqkv weight packed.
model.layers.4.attention.wo weight packed.
model.layers.4.feed_forward.w1 weight packed.
model.layers.4.feed_forward.w3 weight packed.
model.layers.4.feed_forward.w2 weight packed.
model.layers.5.attention.wqkv weight packed.
model.layers.5.attention.wo weight packed.
model.layers.5.feed_forward.w1 weight packed.
model.layers.5.feed_forward.w3 weight packed.
model.layers.5.feed_forward.w2 weight packed.
model.layers.6.attention.wqkv weight packed.
model.layers.6.attention.wo weight packed.
model.layers.6.feed_forward.w1 weight packed.
model.layers.6.feed_forward.w3 weight packed.
model.layers.6.feed_forward.w2 weight packed.
model.layers.7.attention.wqkv weight packed.
model.layers.7.attention.wo weight packed.
model.layers.7.feed_forward.w1 weight packed.
model.layers.7.feed_forward.w3 weight packed.
model.layers.7.feed_forward.w2 weight packed.
model.layers.8.attention.wqkv weight packed.
model.layers.8.attention.wo weight packed.
model.layers.8.feed_forward.w1 weight packed.
model.layers.8.feed_forward.w3 weight packed.
model.layers.8.feed_forward.w2 weight packed.
model.layers.9.attention.wqkv weight packed.
model.layers.9.attention.wo weight packed.
model.layers.9.feed_forward.w1 weight packed.
model.layers.9.feed_forward.w3 weight packed.
model.layers.9.feed_forward.w2 weight packed.
model.layers.10.attention.wqkv weight packed.
model.layers.10.attention.wo weight packed.
model.layers.10.feed_forward.w1 weight packed.
model.layers.10.feed_forward.w3 weight packed.
model.layers.10.feed_forward.w2 weight packed.
model.layers.11.attention.wqkv weight packed.
model.layers.11.attention.wo weight packed.
model.layers.11.feed_forward.w1 weight packed.
model.layers.11.feed_forward.w3 weight packed.
model.layers.11.feed_forward.w2 weight packed.
model.layers.12.attention.wqkv weight packed.
model.layers.12.attention.wo weight packed.
model.layers.12.feed_forward.w1 weight packed.
model.layers.12.feed_forward.w3 weight packed.
model.layers.12.feed_forward.w2 weight packed.
model.layers.13.attention.wqkv weight packed.
model.layers.13.attention.wo weight packed.
model.layers.13.feed_forward.w1 weight packed.
model.layers.13.feed_forward.w3 weight packed.
model.layers.13.feed_forward.w2 weight packed.
model.layers.14.attention.wqkv weight packed.
model.layers.14.attention.wo weight packed.
model.layers.14.feed_forward.w1 weight packed.
model.layers.14.feed_forward.w3 weight packed.
model.layers.14.feed_forward.w2 weight packed.
model.layers.15.attention.wqkv weight packed.
model.layers.15.attention.wo weight packed.
model.layers.15.feed_forward.w1 weight packed.
model.layers.15.feed_forward.w3 weight packed.
model.layers.15.feed_forward.w2 weight packed.
model.layers.16.attention.wqkv weight packed.
model.layers.16.attention.wo weight packed.
model.layers.16.feed_forward.w1 weight packed.
model.layers.16.feed_forward.w3 weight packed.
model.layers.16.feed_forward.w2 weight packed.
model.layers.17.attention.wqkv weight packed.
model.layers.17.attention.wo weight packed.
model.layers.17.feed_forward.w1 weight packed.
model.layers.17.feed_forward.w3 weight packed.
model.layers.17.feed_forward.w2 weight packed.
model.layers.18.attention.wqkv weight packed.
model.layers.18.attention.wo weight packed.
model.layers.18.feed_forward.w1 weight packed.
model.layers.18.feed_forward.w3 weight packed.
model.layers.18.feed_forward.w2 weight packed.
model.layers.19.attention.wqkv weight packed.
model.layers.19.attention.wo weight packed.
model.layers.19.feed_forward.w1 weight packed.
model.layers.19.feed_forward.w3 weight packed.
model.layers.19.feed_forward.w2 weight packed.
model.layers.20.attention.wqkv weight packed.
model.layers.20.attention.wo weight packed.
model.layers.20.feed_forward.w1 weight packed.
model.layers.20.feed_forward.w3 weight packed.
model.layers.20.feed_forward.w2 weight packed.
model.layers.21.attention.wqkv weight packed.
model.layers.21.attention.wo weight packed.
model.layers.21.feed_forward.w1 weight packed.
model.layers.21.feed_forward.w3 weight packed.
model.layers.21.feed_forward.w2 weight packed.
model.layers.22.attention.wqkv weight packed.
model.layers.22.attention.wo weight packed.
model.layers.22.feed_forward.w1 weight packed.
model.layers.22.feed_forward.w3 weight packed.
model.layers.22.feed_forward.w2 weight packed.
model.layers.23.attention.wqkv weight packed.
model.layers.23.attention.wo weight packed.
model.layers.23.feed_forward.w1 weight packed.
model.layers.23.feed_forward.w3 weight packed.
model.layers.23.feed_forward.w2 weight packed.
(lmdeploy) root@intern-studio-061925:~#
下面使用Chat功能运行W4A16量化后的模型。
(lmdeploy) root@intern-studio-061925:~# lmdeploy chat /root/internlm2-chat-1_8b-4bit --model-format awq2024-04-11 17:18:54,874 - lmdeploy - WARNING - model_source: hf_model
2024-04-11 17:18:54,874 - lmdeploy - WARNING - kwargs model_format is deprecated to initialize model, use TurbomindEngineConfig instead.
2024-04-11 17:18:54,874 - lmdeploy - WARNING - kwargs max_batch_size is deprecated to initialize model, use TurbomindEngineConfig instead.
2024-04-11 17:18:54,874 - lmdeploy - WARNING - kwargs cache_max_entry_count is deprecated to initialize model, use TurbomindEngineConfig instead.
2024-04-11 17:19:03,771 - lmdeploy - WARNING - model_config:[llama]
model_name = internlm2
tensor_para_size = 1
head_num = 16
kv_head_num = 8
vocab_size = 92544
num_layer = 24
inter_size = 8192
norm_eps = 1e-05
attn_bias = 0
start_id = 1
end_id = 2
session_len = 32776
weight_type = int4
rotary_embedding = 128
rope_theta = 1000000.0
size_per_head = 128
group_size = 128
max_batch_size = 128
max_context_token_num = 1
step_length = 1
cache_max_entry_count = 0.8
cache_block_seq_len = 64
cache_chunk_size = -1
num_tokens_per_iter = 0
max_prefill_iters = 1
extra_tokens_per_iter = 0
use_context_fmha = 1
quant_policy = 0
max_position_embeddings = 32768
rope_scaling_factor = 0.0
use_dynamic_ntk = 0
use_logn_attn = 02024-04-11 17:19:04,497 - lmdeploy - WARNING - get 267 model params
2024-04-11 17:19:18,963 - lmdeploy - WARNING - Input chat template with model_name is None. Forcing to use internlm2
[WARNING] gemm_config.in is not found; using default GEMM algo
session 1double enter to end input >>> <|im_start|>system
You are an AI assistant whose name is InternLM (书生·浦语).
- InternLM (书生·浦语) is a conversational language model that is developed by Shanghai AI Laboratory (上海人工智能实验室). It is designed to be helpful, honest, and harmless.
- InternLM (书生·浦语) can understand and communicate fluently in the language chosen by the user such as English and 中文.
<|im_end|>
<|im_start|>user
<|im_end|>
<|im_start|>assistant2024-04-11 17:19:19,768 - lmdeploy - WARNING - kwargs ignore_eos is deprecated for inference, use GenerationConfig instead.
2024-04-11 17:19:19,768 - lmdeploy - WARNING - kwargs random_seed is deprecated for inference, use GenerationConfig instead.
好的,我可以帮您回答问题。请问您有什么问题需要我回答吗?double enter to end input >>>
<|im_start|>user
<|im_end|>
<|im_start|>assistant当然,我会尽我最大的努力来回答您的问题。有什么事情困扰着您吗?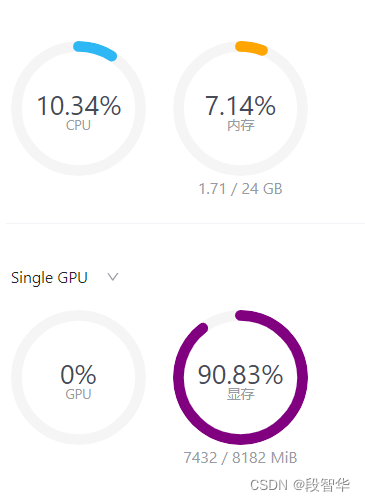
为了更加明显体会到W4A16的作用,我们将KV Cache比例再次调为0.01,查看显存占用情况。
lmdeploy chat /root/internlm2-chat-1_8b-4bit --model-format awq --cache-max-entry-count 0.01
(lmdeploy) root@intern-studio-061925:~# lmdeploy chat /root/internlm2-chat-1_8b-4bit --model-format awq --cache-max-entry-count 0.01
2024-04-11 17:22:12,505 - lmdeploy - WARNING - model_source: hf_model
2024-04-11 17:22:12,506 - lmdeploy - WARNING - kwargs model_format is deprecated to initialize model, use TurbomindEngineConfig instead.
2024-04-11 17:22:12,506 - lmdeploy - WARNING - kwargs max_batch_size is deprecated to initialize model, use TurbomindEngineConfig instead.
2024-04-11 17:22:12,506 - lmdeploy - WARNING - kwargs cache_max_entry_count is deprecated to initialize model, use TurbomindEngineConfig instead.
2024-04-11 17:22:18,574 - lmdeploy - WARNING - model_config:[llama]
model_name = internlm2
tensor_para_size = 1
head_num = 16
kv_head_num = 8
vocab_size = 92544
num_layer = 24
inter_size = 8192
norm_eps = 1e-05
attn_bias = 0
start_id = 1
end_id = 2
session_len = 32776
weight_type = int4
rotary_embedding = 128
rope_theta = 1000000.0
size_per_head = 128
group_size = 128
max_batch_size = 128
max_context_token_num = 1
step_length = 1
cache_max_entry_count = 0.01
cache_block_seq_len = 64
cache_chunk_size = -1
num_tokens_per_iter = 0
max_prefill_iters = 1
extra_tokens_per_iter = 0
use_context_fmha = 1
quant_policy = 0
max_position_embeddings = 32768
rope_scaling_factor = 0.0
use_dynamic_ntk = 0
use_logn_attn = 02024-04-11 17:22:19,471 - lmdeploy - WARNING - get 267 model params
2024-04-11 17:22:31,462 - lmdeploy - WARNING - Input chat template with model_name is None. Forcing to use internlm2
[WARNING] gemm_config.in is not found; using default GEMM algo
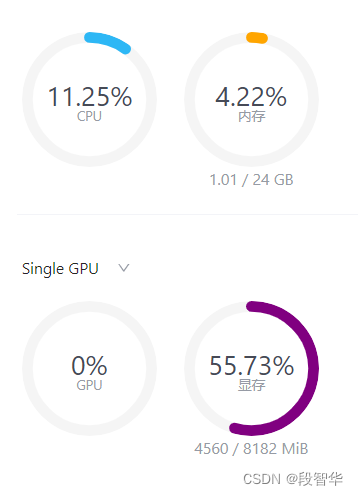
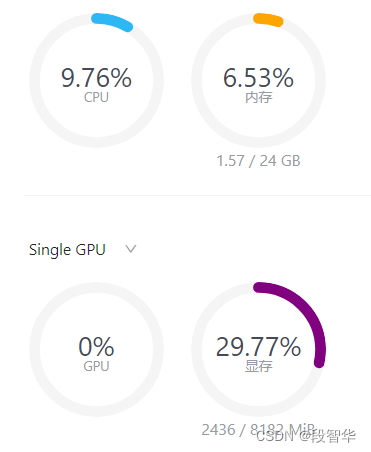
session 1double enter to end input >>> hello可以看到,显存占用变为2346MB,明显降低。
LMDeploy服务(serve)
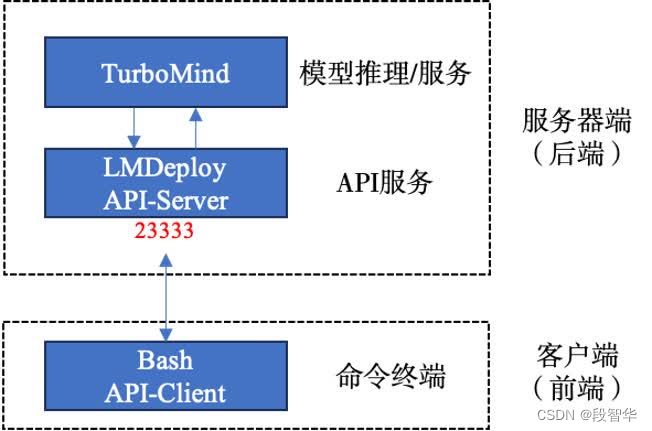
将大模型封装为API接口服务,供客户端访问。
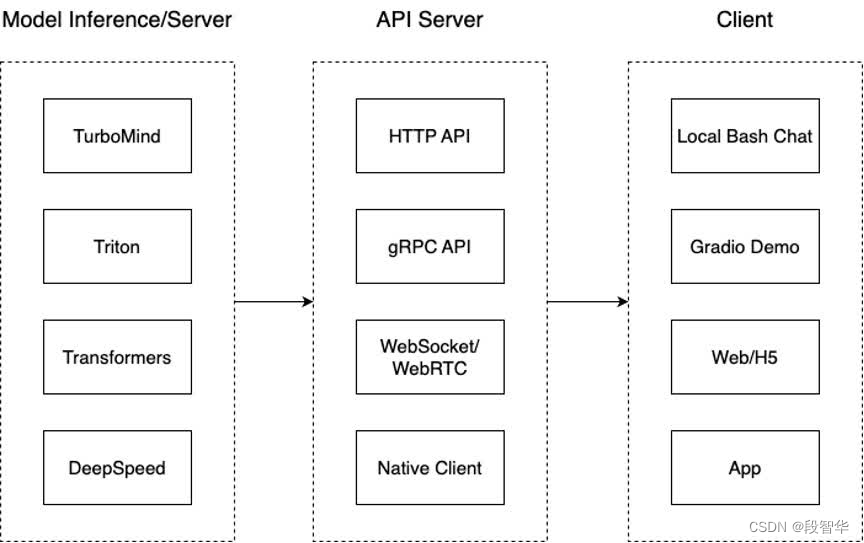
从架构上把整个服务流程分成下面几个模块。
- 模型推理/服务。主要提供模型本身的推理,一般来说可以和具体业务解耦,专注模型推理本身性能的优化。可以以模块、API等多种方式提供。
- API Server。中间协议层,把后端推理/服务通过HTTP,gRPC或其他形式的接口,供前端调用。
- Client。可以理解为前端,与用户交互的地方。通过通过网页端/命令行去调用API接口,获取模型推理/服务。
值得说明的是,以上的划分是一个相对完整的模型,但在实际中这并不是绝对的。比如可以把“模型推理”和“API Server”合并,有的甚至是三个流程打包在一起提供服务。
启动API服务器
通过以下命令启动API服务器,推理internlm2-chat-1_8b模型:
lmdeploy serve api_server \/root/internlm2-chat-1_8b \--model-format hf \--quant-policy 0 \--server-name 0.0.0.0 \--server-port 23333 \--tp 1
(lmdeploy) root@intern-studio-061925:~# lmdeploy serve api_server \
> /root/internlm2-chat-1_8b \
> --model-format hf \
> --quant-policy 0 \
> --server-name 0.0.0.0 \
> --server-port 23333 \
> --tp 1[WARNING] gemm_config.in is not found; using default GEMM algo
HINT: Please open http://0.0.0.0:23333 in a browser for detailed api usage!!!
HINT: Please open http://0.0.0.0:23333 in a browser for detailed api usage!!!
HINT: Please open http://0.0.0.0:23333 in a browser for detailed api usage!!!
INFO: Started server process [104788]
INFO: Waiting for application startup.
INFO: Application startup complete.
INFO: Uvicorn running on http://0.0.0.0:23333 (Press CTRL+C to quit)ssh -CNg -L 23333:127.0.0.1:23333 root@ssh.intern-ai.org.cn -p 42659

命令行客户端连接API服务器
运行命令行客户端
lmdeploy serve api_client http://localhost:23333
通过命令行窗口直接与模型对话
(lmdeploy) root@intern-studio-061925:~# lmdeploy serve api_client http://localhost:23333double enter to end input >>> 好的,我会尽力帮助您。请问您需要什么帮助?
double enter to end input >>> 请问您有什么问题需要我解答吗?
double enter to end input >>> hello您好,请问有什么需要帮助的吗?
double enter to end input >>>网页客户端连接API服务器
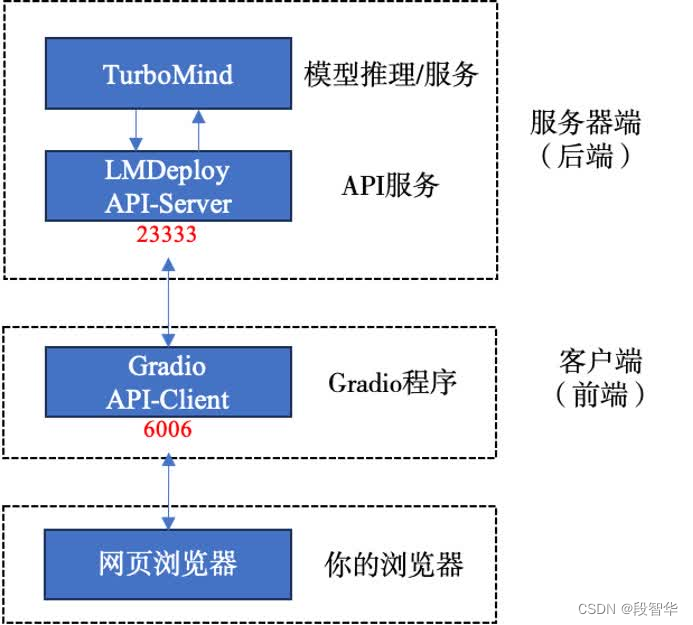
使用Gradio作为前端,启动网页客户端。
lmdeploy serve gradio http://localhost:23333 \--server-name 0.0.0.0 \--server-port 6006
ssh -CNg -L 6006:127.0.0.1:6006 root@ssh.intern-ai.org.cn -p 42659

打开浏览器,访问地址http://127.0.0.1:6006
Python代码集成
(lmdeploy) root@intern-studio-061925:~# python
Python 3.10.14 (main, Mar 21 2024, 16:24:04) [GCC 11.2.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
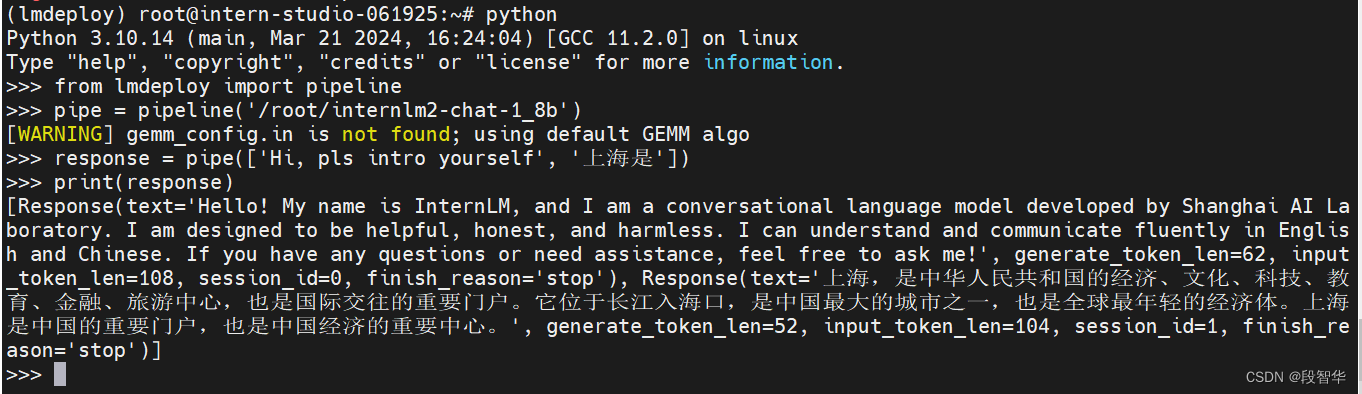
>>> from lmdeploy import pipeline
>>> pipe = pipeline('/root/internlm2-chat-1_8b')
[WARNING] gemm_config.in is not found; using default GEMM algo
>>> response = pipe(['Hi, pls intro yourself', '上海是'])
>>> print(response)
[Response(text='Hello! My name is InternLM, and I am a conversational language model developed by Shanghai AI Laboratory. I am designed to be helpful, honest, and harmless. I can understand and communicate fluently in English and Chinese. If you have any questions or need assistance, feel free to ask me!', generate_token_len=62, input_token_len=108, session_id=0, finish_reason='stop'), Response(text='上海,是中华人民共和国的经济、文化、科技、教育、金融、旅游中心,也是国际交往的重要门户。它位于长江入海口,是中国最大的城市之一,也是全球最年轻的经济体。上海是中国的重要门户,也是中国经济的重要中心。', generate_token_len=52, input_token_len=104, session_id=1, finish_reason='stop')]
>>>
向TurboMind后端传递参数
通过向lmdeploy传递附加参数,实现模型的量化推理,及设置KV Cache最大占用比例。在Python代码中,可以通过创建TurbomindEngineConfig,向lmdeploy传递参数。
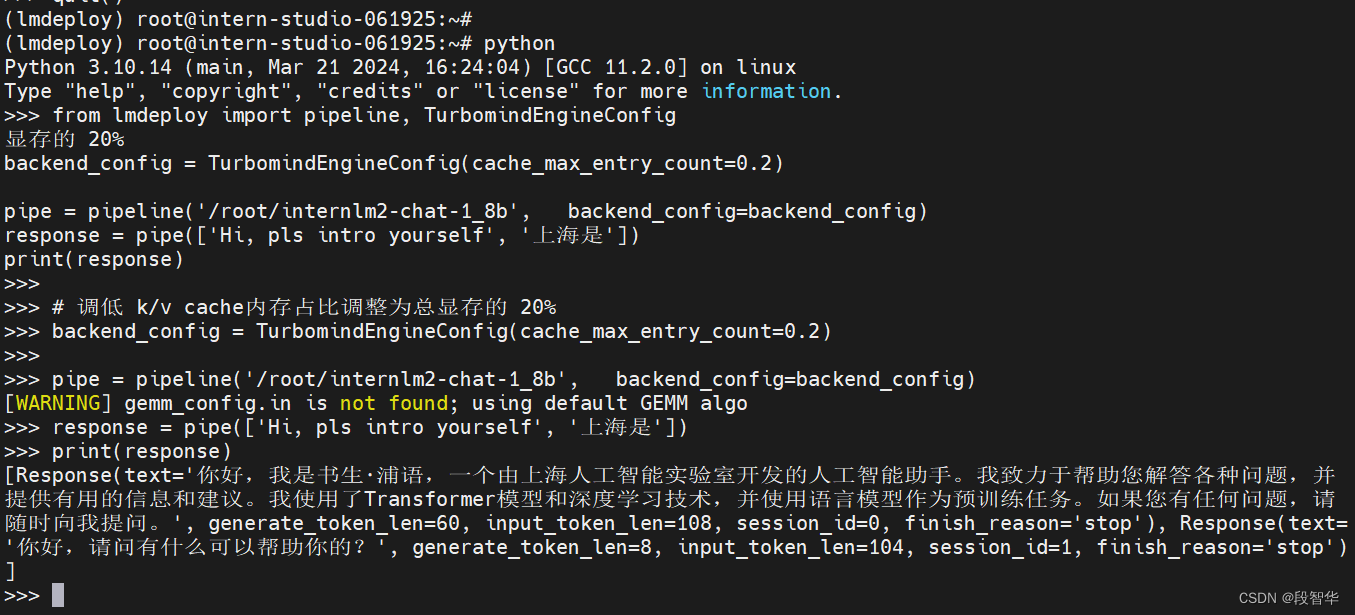
from lmdeploy import pipeline, TurbomindEngineConfig# 调低 k/v cache内存占比调整为总显存的 20%
backend_config = TurbomindEngineConfig(cache_max_entry_count=0.2)pipe = pipeline('/root/internlm2-chat-1_8b',backend_config=backend_config)
response = pipe(['Hi, pls intro yourself', '上海是'])
print(response)
(lmdeploy) root@intern-studio-061925:~# python
Python 3.10.14 (main, Mar 21 2024, 16:24:04) [GCC 11.2.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> from lmdeploy import pipeline, TurbomindEngineConfig
显存的 20%
backend_config = TurbomindEngineConfig(cache_max_entry_count=0.2)pipe = pipeline('/root/internlm2-chat-1_8b', backend_config=backend_config)
response = pipe(['Hi, pls intro yourself', '上海是'])
print(response)
>>>
>>> # 调低 k/v cache内存占比调整为总显存的 20%
>>> backend_config = TurbomindEngineConfig(cache_max_entry_count=0.2)
>>>
>>> pipe = pipeline('/root/internlm2-chat-1_8b', backend_config=backend_config)
[WARNING] gemm_config.in is not found; using default GEMM algo
>>> response = pipe(['Hi, pls intro yourself', '上海是'])
>>> print(response)
[Response(text='你好,我是书生·浦语,一个由上海人工智能实验室开发的人工智能助手。我致力于帮助您解答各种问题,并提供有用的信息和建议。我使用了Transformer模型和深度学习技术,并使用语言模型作为预训练任务。如果您有任何问题,请随时向我提问。', generate_token_len=60, input_token_len=108, session_id=0, finish_reason='stop'), Response(text='你好,请问有什么可以帮助你的?', generate_token_len=8, input_token_len=104, session_id=1, finish_reason='stop')]
>>>
使用LMDeploy运行视觉多模态大模型llava
运行本pipeline最低需要30%的InternStudio开发机
激活conda环境。
conda activate lmdeploy
安装llava依赖库。
pip install git+https://github.com/haotian-liu/LLaVA.git@4e2277a060da264c4f21b364c867cc622c945874
保存后运行pipeline
python /root/pipeline_llava.py
从github下载了一张关于老虎的图片

得到输出结果
(lmdeploy) root@intern-studio-061925:~# python /root/pipeline_llava.py
[WARNING] gemm_config.in is not found; using default GEMM algo
You are using a model of type llava to instantiate a model of type llava_llama. This is not supported for all configurations of models and can yield errors.
You are using a model of type llava to instantiate a model of type llava_llama. This is not supported for all configurations of models and can yield errors.
preprocessor_config.json: 100%|████████████████████████████████████████████████| 316/316 [00:00<00:00, 1.89MB/s]
config.json: 4.76kB [00:00, 17.6MB/s]
pytorch_model.bin: 100%|███████████████████████████████████████████████████| 1.71G/1.71G [01:22<00:00, 20.8MB/s]
Loading checkpoint shards: 100%|██████████████████████████████████████████████████| 3/3 [00:00<00:00, 3.24it/s]
Response(text="The image shows a tiger lying on the grass. The tiger is facing towards the camera, with its head slightly tilted to the left and its front paws extended outwards. Its fur is a mix of orange and black stripes, typical of a tiger's pattern. The background is a blurred green, suggesting a natural outdoor setting, possibly a grassy field or a forest. The lighting appears to be natural, indicating the photo was taken during the day. The focus is sharp on the tiger's face and front legs, while the background is slightly out of focus, which is a common technique in wildlife photography to draw attention to the subject.", generate_token_len=143, input_token_len=1023, session_id=0, finish_reason='stop')
(lmdeploy) root@intern-studio-061925:~#图片显示一只老虎躺在草地上。老虎面朝镜头,头微微向左倾斜,前爪向外伸出。它的皮毛是橙色和黑色条纹的混合体,这是老虎的典型图案。背景是模糊的绿色,暗示着一个自然的户外环境,可能是草地或森林。光线看起来很自然,表明这张照片是在白天拍摄的。焦点集中在老虎的脸和前腿上,而背景稍微失焦,这是野生动物摄影中吸引注意力的常用技巧
也可以通过Gradio来运行llava模型。新建python文件gradio_llava.py
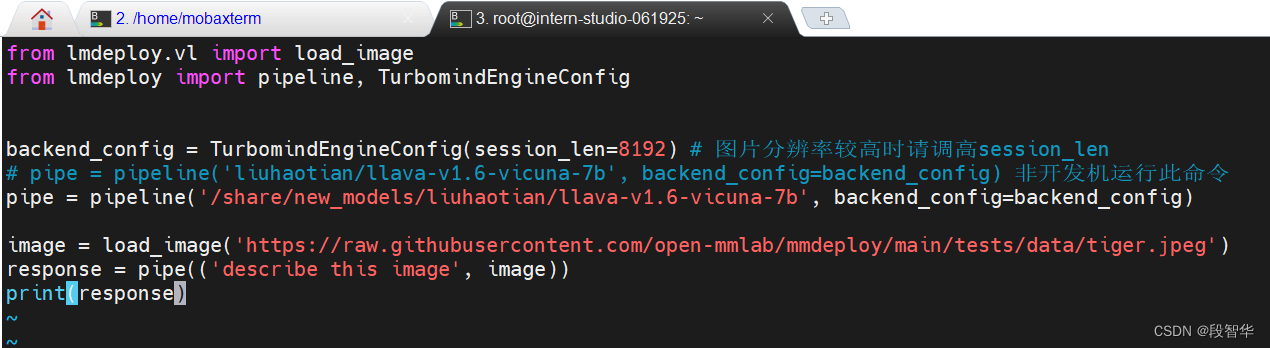
import gradio as gr
from lmdeploy import pipeline, TurbomindEngineConfigbackend_config = TurbomindEngineConfig(session_len=8192) # 图片分辨率较高时请调高session_len
# pipe = pipeline('liuhaotian/llava-v1.6-vicuna-7b', backend_config=backend_config) 非开发机运行此命令
pipe = pipeline('/share/new_models/liuhaotian/llava-v1.6-vicuna-7b', backend_config=backend_config)def model(image, text):if image is None:return [(text, "请上传一张图片。")]else:response = pipe((text, image)).textreturn [(text, response)]demo = gr.Interface(fn=model, inputs=[gr.Image(type="pil"), gr.Textbox()], outputs=gr.Chatbot())
demo.launch()
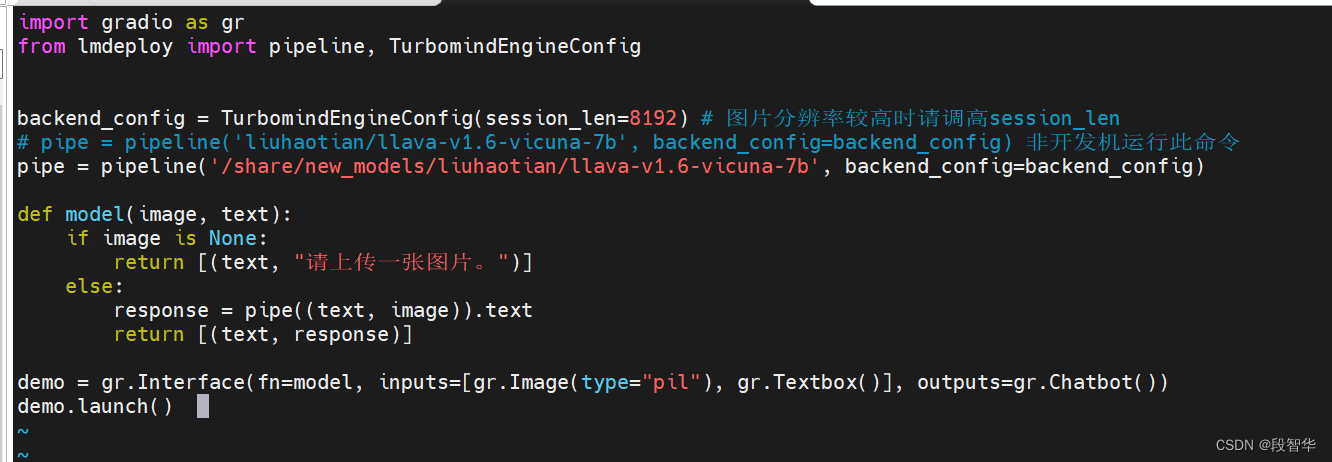
运行python程序。
python /root/gradio_llava.py
(lmdeploy) root@intern-studio-061925:~# python /root/gradio_llava.py
[WARNING] gemm_config.in is not found; using default GEMM algo
You are using a model of type llava to instantiate a model of type llava_llama. This is not supported for all configurations of models and can yield errors.
You are using a model of type llava to instantiate a model of type llava_llama. This is not supported for all configurations of models and can yield errors.
Loading checkpoint shards: 100%|██████████████████████████████████████████████████| 3/3 [00:00<00:00, 3.24it/s]
Running on local URL: http://127.0.0.1:7860To create a public link, set `share=True` in `launch()`.通过ssh转发一下7860端口。
ssh -CNg -L 7860:127.0.0.1:7860 root@ssh.intern-ai.org.cn -p 42659

http://127.0.0.1:7860/
使用LMDeploy运行第三方大模型
LMDeploy不仅支持运行InternLM系列大模型,还支持其他第三方大模型。支持的模型列表如下:
Model Size
Llama 7B - 65B
Llama2 7B - 70B
InternLM 7B - 20B
InternLM2 7B - 20B
InternLM-XComposer 7B
QWen 7B - 72B
QWen-VL 7B
QWen1.5 0.5B - 72B
QWen1.5-MoE A2.7B
Baichuan 7B - 13B
Baichuan2 7B - 13B
Code Llama 7B - 34B
ChatGLM2 6B
Falcon 7B - 180B
YI 6B - 34B
Mistral 7B
DeepSeek-MoE 16B
DeepSeek-VL 7B
Mixtral 8x7B
Gemma 2B-7B
Dbrx 132B
可以从Modelscope,OpenXLab下载相应的HF模型
定量比较LMDeploy与Transformer库的推理速度差异
测试一波Transformer库推理Internlm2-chat-1.8b的速度,新建python文件,命名为benchmark_transformer.py,填入以下内容:
import torch
import datetime
from transformers import AutoTokenizer, AutoModelForCausalLMtokenizer = AutoTokenizer.from_pretrained("/root/internlm2-chat-1_8b", trust_remote_code=True)# Set `torch_dtype=torch.float16` to load model in float16, otherwise it will be loaded as float32 and cause OOM Error.
model = AutoModelForCausalLM.from_pretrained("/root/internlm2-chat-1_8b", torch_dtype=torch.float16, trust_remote_code=True).cuda()
model = model.eval()# warmup
inp = "hello"
for i in range(5):print("Warm up...[{}/5]".format(i+1))response, history = model.chat(tokenizer, inp, history=[])# test speed
inp = "请介绍一下你自己。"
times = 10
total_words = 0
start_time = datetime.datetime.now()
for i in range(times):response, history = model.chat(tokenizer, inp, history=history)total_words += len(response)
end_time = datetime.datetime.now()delta_time = end_time - start_time
delta_time = delta_time.seconds + delta_time.microseconds / 1000000.0
speed = total_words / delta_time
print("Speed: {:.3f} words/s".format(speed))
运行python脚本:
python benchmark_transformer.py
(lmdeploy) root@intern-studio-061925:~# python benchmark_transformer.py
Loading checkpoint shards: 100%|██████████████████████████████████████████████████| 2/2 [00:14<00:00, 7.44s/it]
Warm up...[1/5]
Warm up...[2/5]
Warm up...[3/5]
Warm up...[4/5]
Warm up...[5/5]
Speed: 53.092 words/s
Transformer库的推理速度约为53.092 words/s,注意单位是words/s,不是token/s,word和token在数量上可以近似认为成线性关系。
下面来测试一下LMDeploy的推理速度,新建python文件benchmark_lmdeploy.py,填入以下内容
import datetime
from lmdeploy import pipelinepipe = pipeline('/root/internlm2-chat-1_8b')# warmup
inp = "hello"
for i in range(5):print("Warm up...[{}/5]".format(i+1))response = pipe([inp])# test speed
inp = "请介绍一下你自己。"
times = 10
total_words = 0
start_time = datetime.datetime.now()
for i in range(times):response = pipe([inp])total_words += len(response[0].text)
end_time = datetime.datetime.now()delta_time = end_time - start_time
delta_time = delta_time.seconds + delta_time.microseconds / 1000000.0
speed = total_words / delta_time
print("Speed: {:.3f} words/s".format(speed))
运行脚本 python benchmark_lmdeploy.py
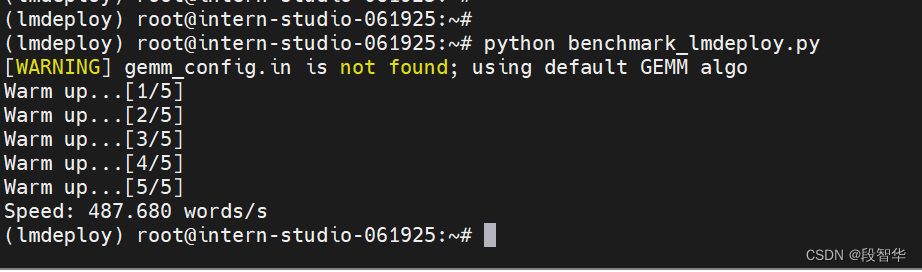
可以看到,LMDeploy的推理速度约为487.680 words/s,是Transformer库的6倍。
这篇关于书生·浦语大模型实战营之LMDeploy 量化部署 LLM-VLM 实践的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



