vlm专题

VLM视觉语言大模型在智能驾驶中的应用
VLM在自动驾驶中的任务 single or multiple Object Referring 即带条件的目标检测,用语言指示模型识别图像中特定目标。 Referred Object Tracking 和Object Referring相比,Object Referring Tracking会根据自然语言描述在连续帧中对目标进行跟踪。 Open-Vocabulary 3D Objec

VLM(视觉语言模型)综述
概述 大型语言模型的出现标志着人工智能领域转型的开始,它们在文本信息处理上的能力极大地推动了这一进程。尽管LLMs在文本处理上表现出色,但它们主要限于处理单一模态的数据,即文本。这限制了它们在理解和生成涉及图像和视频等多模态数据方面的能力。自然智能能够处理多种模态的信息,包括书面和口头语言、图像的视觉解释以及视频的理解。为了使人工智能系统具有类似人类的认知功能,它们必须也能够处理多模态数据。

VLM 系列——phi3.5-Vision——论文解读
一、概述 1、是什么 论文全称《Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone》 是一系列大型语言模型(LLM) & 多模态大型语言模型(MLLM)。其中LLM包括phi-3-mini 3.8B、phi-3-small 7B、phi-3-medium 14B,phi-3-mini

多模态vlm综述:An Introduction to Vision-Language Modeling 论文解读
目录 1、基于对比学习的VLMs 1.1 CLIP 2、基于mask的VLMs 2.1 FLAVA 2.2 MaskVLM 2.3 关于VLM目标的信息理论视角 3、基于生成的VLM 3.1 学习文本生成器的例子: 3.2 多模态生成模型的示例: 3.3 使用生成的文本到图像模型进行下游视觉语言任务 4、 基于预训练主干网络的视觉语言模型(VLM) 4.1 Frozen

MoonDream2微调指南【最小VLM】
在本指南中,我们将探讨如何使用计算机视觉数据集对完全开源的小型视觉语言模型 Moondream2 进行微调,以计数项目(这是 GPT-4V 一直表现不一致的任务),并以一种可以依赖输出用于生产应用程序的方式进行微调。 视觉语言模型 (VLM),有时也称为多模态模型,越来越受欢迎。随着 CLIP、GPT-4 with Vision 等技术的出现以及其他进步,从视觉输入中查询问题的能力变得比以往任何
Co-Driver:基于 VLM 的自动驾驶助手,具有类人行为并能理解复杂的道路场景
24年5月来自俄罗斯莫斯科研究机构的论文“Co-driver: VLM-based Autonomous Driving Assistant with Human-like Behavior and Understanding for Complex Road Scenes”。 关于基于大语言模型的自动驾驶解决方案的最新研究,显示了规划和控制领域的前景。 然而,大量的计算资源和大语言模型的幻觉继
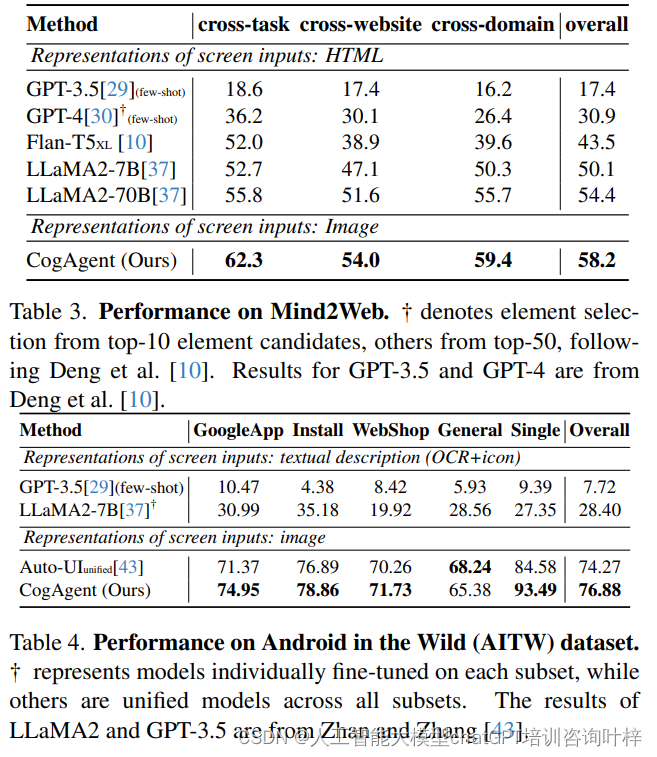
CogAgent:开创性的VLM在GUI理解和自动化任务中的突破
尽管LLMs如ChatGPT在撰写电子邮件等任务上能够提供帮助,它们在理解和与GUIs交互方面存在挑战,这限制了它们在提高自动化水平方面的潜力。数字世界中的自主代理是许多现代人梦寐以求的理想助手。这些代理能够根据用户输入的任务描述自动完成如在线预订票务、进行网络搜索、管理文件和创建PowerPoint演示文稿等任务。然而,目前基于纯语言的代理在真实场景中的潜力相当有限,因为大多数应用程序通过GUI

论文推荐:最新榜单评估VLM的富文本理解
1. 📌 元数据概览: 标题:这篇论文的标题是《SEED-Bench-2-Plus: Benchmarking Multimodal Large Language Models with Text-Rich Visual Comprehension》,从标题可以推测,论文可能讨论了如何评估多模态大型语言模型在理解富含文本的视觉内容方面的表现。作者:论文的作者包括Bohao Li, Yuying
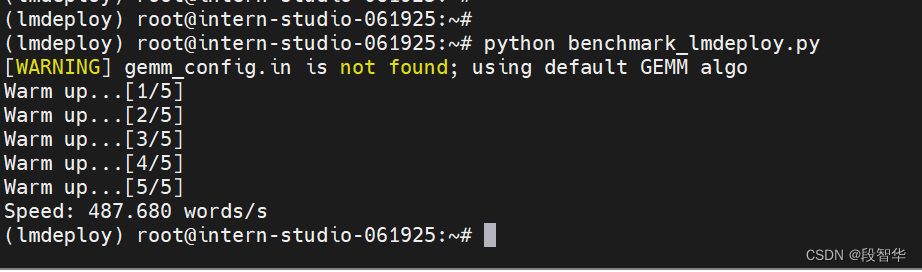
书生·浦语大模型实战营之LMDeploy 量化部署 LLM-VLM 实践
书生·浦语大模型实战营之LMDeploy 量化部署 LLM-VLM 实践 创建开发机 打开InternStudio平台,创建开发机。 填写开发机名称;选择镜像Cuda12.2-conda;选择10% A100*1GPU;点击“立即创建”。注意请不要选择Cuda11.7-conda的镜像,新版本的lmdeploy会出现兼容性问题。 studio-conda -t lmdepl
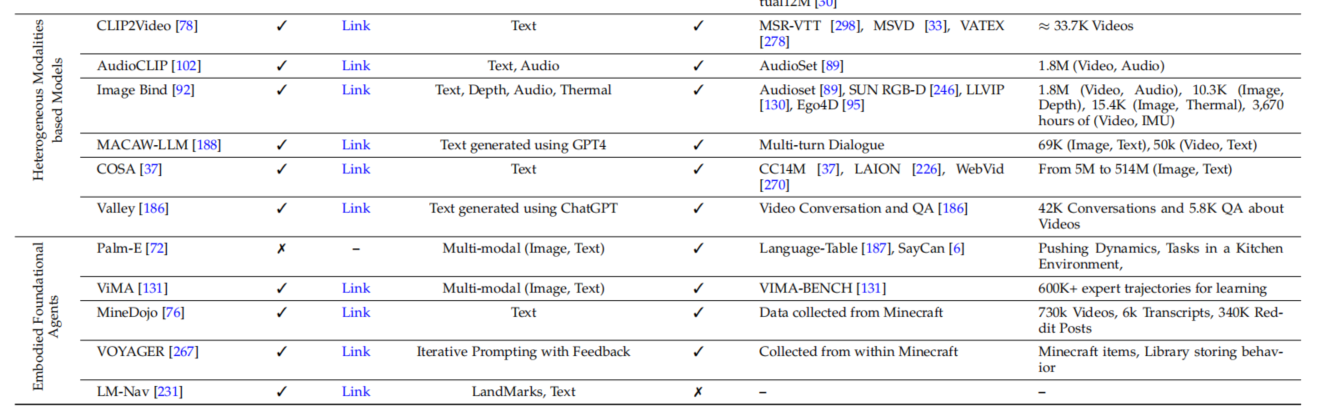
从视觉任务(识别/定位/分割/追踪..)出发,调研各种模态提示的视觉大模型CV-VLM综述论文详细阅读:Foundational Models Defining a New Era in Vision
本篇主要讲解了在视觉领域中视觉语言模型的发展历程,每种VLM基础模型提出的背景,设计方案,应用领域等,调查了关于图像识别,图像定位,图像分割,字幕生成,视频追踪等方向相关的模型。 Foundational Models Defining a New Era in Vision: A Survey and Outlook 定义视觉新时代的基本模型:调查与展望 paper: 2307.13

【AI+CAD】(二)LLM和VLM生成结构化数据结构(PPT/CAD/DXF)
当前LLM和VLM在PPT生成任务上已经小有成效,如ChatPPT。 @TOC 1. PPT-LLM LLM根据用户的instruction生成规范的绘制ppt的API语句:即使是最强的GPT-4 + CoT也只能达到20-30%的内容准确度。 LLM输入:User_instruction(当前+过去)、PPT_content、PPT_reader_API。其中 PPT_reader_

视觉和GPT再碰火花!CVPR`24 | RegionGPT:面向复杂区域理解的VLM(港大英伟达)
文章链接:https://arxiv.org/pdf/2403.02330 视觉语言模型(VLMs)通过将大语言模型(LLMs)与图像文本对集成,经历了快速的发展,但由于视觉编码器的空间意识有限以及使用缺乏详细的区域特定字幕的粗粒度训练数据,它们在详细的区域视觉理解方面存在困难。为了解决这个问题,引入了RegionGPT(简称RGPT),这是一个专门设计用于复杂区域级字幕和理解的新框架。
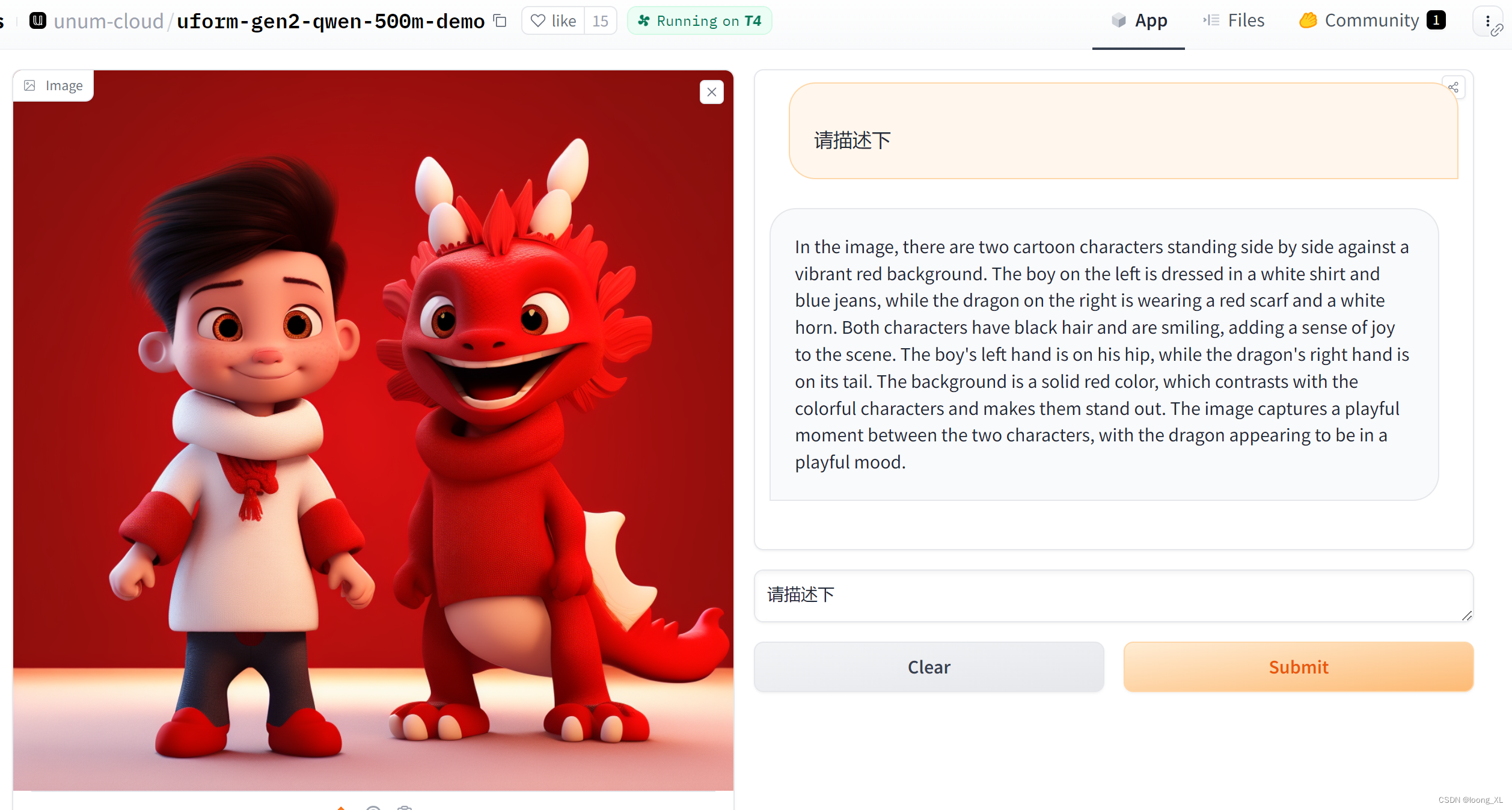
VLM多模态图像识别小模型UForm
参考:https://github.com/unum-cloud/uform https://huggingface.co/unum-cloud/uform-gen2-qwen-500m https://baijiahao.baidu.com/s?id=1787054120353641459&wfr=spider&for=pc demo:https://huggingface.co/space
VLM 系列——MoE-LLaVa——论文解读
一、概述 1、是什么 moe-Llava 是Llava1.5 的改进 全称《MoE-LLaVA: Mixture of Experts for Large Vision-Language Models》,是一个多模态视觉-文本大语言模型,可以完成:图像描述、视觉问答,潜在可以完成单个目标的视觉定位、名画名人等识别(问答、描述),未知是否能偶根据图片写代码(HTML、JS、CSS)。支
CodeFuse-VLM 开源,支持多模态多任务预训练/微调
CodeFuse-MFT-VLM 项目地址:https://github.com/codefuse-ai/CodeFuse-MFT-VLM CodeFuse-VLM-14B 模型地址:CodeFuse-VLM-14B CodeFuse-VLM框架简介 随着huggingface开源社区的不断更新,会有更多的vision encoder 和 LLM 底座发布,这些vision en
VLM 系列——Qwen-VL 千问—— 论文解读
一、概述 1、是什么 Qwen-VL全称《Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond》,是一个多模态的视觉-文本模型,当前 Qwen-VL(20231707)可以完成:图像字幕、视觉问答、OCR、文档理解和视觉定位功能,同时支持

VLM 系列——BLIP2——论文解读
一、概述 1、是什么 BLIP2 全称《BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models 》, 是一个多模态视觉-文本大语言模型,隶属BLIP系列第二篇,可以完成:图像描述、视觉问答、名画名人等识别(问答、描述)。支持单幅图片输
VLM 系列——COGVLM—— 论文解读
一、概述 1、是什么 COGVLM 全称《VISUAL EXPERT FOR LARGE LANGUAGE》,是一个多模态的视觉-文本模型,当前CogVLM-17B(20231130)可以完成对一幅图片进行描述、图中物体或指定输出检测框、相关事物进行问答,但是这个版本只支持一个图片(为且必为首次输入),只支持英文,几乎不支持写代码(目前测试是的)。 2、亮点 论文认为:在不
VLM 系列——CLIP——论文解读
一、概述 1、是什么 论文全称《Learning Transferable Visual Models From Natural Language Supervision》,是使用图文对(将图像表征与语言联系起来)使用对比学习(有的文章称为自监督,有的文章称为无监督)训练的多模态模型。从互联网上大量文本的监督(自然语言监督)中学习,要比传统的分类数据要大得多。 可以用来图片z

【PaperReading- VLM】1. FERRET
CategoryContent论文题目FERRET: REFER AND GROUND ANYTHING ANYWHERE AT ANY GRANULARITY作者Haoxuan You (Columbia University), Haotian Zhang, Zhe Gan, Xianzhi Du, Bowen Zhang, Zirui Wang, Liangliang Cao (Apple

X-VLM:多粒度视觉语言预训练方法
原文:Zeng, Yan, Xinsong Zhang and Hang Li. “Multi-Grained Vision Language Pre-Training: Aligning Texts with Visual Concepts.” ArXiv abs/2111.08276 (2021). 源码:https://github.com/zengyan-97/x-vlm 现有的视

Talk | ACL‘23 杰出论文,MultiIntruct:通过多模态指令集微调提升VLM的零样本学习
本期为TechBeat人工智能社区第536期线上Talk! 北京时间10月11日(周三)20:00,弗吉尼亚理工大学博士生—徐智阳、沈莹的Talk已准时在TechBeat人工智能社区开播! 他们与大家分享的主题是: “通过多模态指令集微调提升VLM的零样本学习”, 介绍了由他们提出的MultiIntruct和第一个多模态指令集微调数据集。 Talk·信息 ▼ 主题:通过多模态指令集