本文主要是介绍多模态vlm综述:An Introduction to Vision-Language Modeling 论文解读,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
1、基于对比学习的VLMs
1.1 CLIP
2、基于mask的VLMs
2.1 FLAVA
2.2 MaskVLM
2.3 关于VLM目标的信息理论视角
3、基于生成的VLM
3.1 学习文本生成器的例子:
3.2 多模态生成模型的示例:
3.3 使用生成的文本到图像模型进行下游视觉语言任务
4、 基于预训练主干网络的视觉语言模型(VLM)
4.1 Frozen
4.2 MiniGPT模型示例
MiniGPT-4的应用
MiniGPT-5的扩展
MiniGPT-v2的多任务应用
4.3 使用预训练主干的其他热门模型
Qwen模型
BLIP-2模型
论文: https://arxiv.org/pdf/2405.17247
这里主要整理了多模态的技术发展历程,没有一些实验对比的数据。
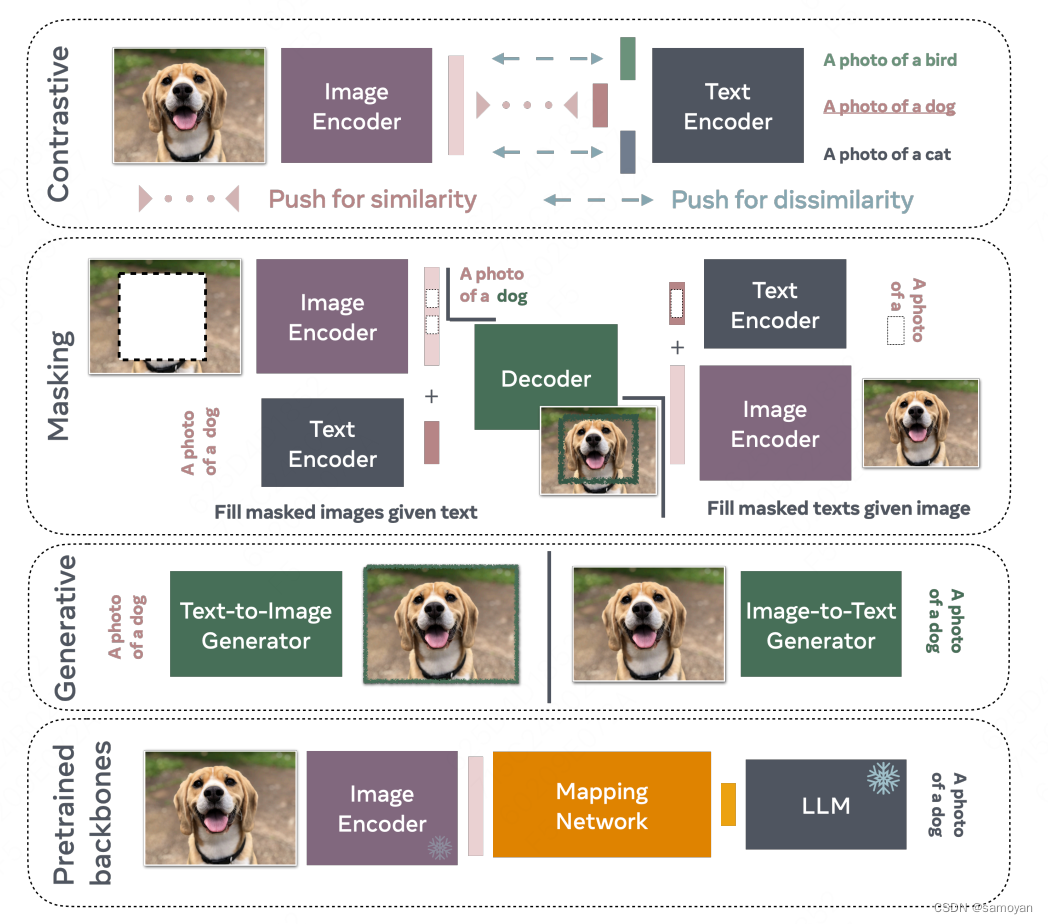
VLM家族:
1)对比训练是一种广泛应用的策略,它采用正面例子和负面例子的配对方式。视觉语言模型(VLM)通过这种方式被训练,以针对正面配对预测出相似的表示,同时对于负面配对则预测出不同的表示。
2)掩码技术是另一种训练VLM的策略,它通过重构给定的未掩码文本字幕中缺失的部分来实现。类似地,通过在字幕中掩码词语,也可以训练VLM来重构给定未掩码图像中的这些词语。
3)尽管大多数方法采用中间表示或部分重构技术,但生成式VLM经过特殊训练后,能够生成完整的图像或极长的字幕。考虑到这些模型的复杂性,它们通常需要较高的训练成本。
4)基于预训练主干网络的VLM经常利用像Llama这样的开源大型语言模型(LLM),学习图像编码器(也可能事先经过训练)与LLM之间的映射关系。重要的是,这些模型不是互斥的;许多方法依赖于对比、掩蔽和生成几种标准的结合。
1、基于对比学习的VLMs
基于对比的训练通常可以通过基于能量的模型(Energy-Based Models, EBM)的观点来更好地解释,如LeCun等人在2006年提出的,其中一个由参数θ定义的模型Eθ,被训练以赋予观察到的变量较低的能量,而未观察到的变量则赋予较高的能量。来自目标分布的数据应该具有较低的能量,而其他任何数据点则应具有较高的能量。为了训练这些模型,我们考虑输入数据x与一个能量函数Eθ(x),该能量函数由参数θ给出。相应的学习目标的玻尔兹曼分布密度函数可以写成:

其中归一化因子为 𝑍𝜃=∑𝑥𝑒−𝐸𝜃(𝑥)。为了估计输入数据抽取的目标分布PD,我们原则上可以使用传统的最大似然目标函数:
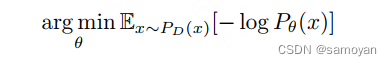
其梯度为:

然而,上述方法需要从模型分布 𝑃𝜃(𝑥) 中采样出样本 𝑥−,而这样的样本可能难以得到。目前有几种技术可以近似地模拟这种分布。一种方法依赖于马尔可夫链蒙特卡罗(MCMC)技术,通过迭代过程找出能够最小化预测能量的样本。第二种方法依赖于得分匹配[Hyvärinen, 2005]和去噪得分匹配[Vincent, 2011]的标准,它们通过只学习输入数据相对于概率密度的梯度来移除归一化因子。另一类方法,最近在自监督学习(SSL)和视觉语言模型(VLM)的研究中使用最多的,是噪声对比估计(NCE)[Gutmann和Hyvärinen, 2010]。
与其使用模型分布来采样负样本,NCE背后的直觉是,采样自噪声分布 𝑢′∼𝑝𝑛(𝑢′) 在某些情况下可能足够好地近似模型分布样本。尽管从理论上难以证明这种方法为何可行,但是广泛的实验证据表明,近期自监督学习文献中基于NCE的方法是成功的[Chen等人,2020]。原始的NCE框架可以描述为一个二元分类问题,模型应当为来自真实数据分布的样本预测标签 𝐶=1,而为来自噪声分布的样本预测 𝐶=0。通过这种方式,模型学会了区分真实数据点和噪声数据点。因此,损失函数可以定义为具有交叉熵的二元分类:
𝐿𝑁𝐶𝐸(𝜃):=−∑𝑖log𝑃(𝐶𝑖=1∣𝑥𝑖;𝜃)−∑𝑗log𝑃(𝐶𝑗=0∣𝑥𝑗;𝜃)
其中 𝑥𝑖 是从数据分布中采样的,而 𝑥𝑗∼𝑝𝑛(𝑥),𝑗≠𝑖 是从噪声分布中采样的。
Wu等人[2018]提出了一种无需正样本对的噪声对比估计(NCE)方法,该方法采用非参数化Softmax函数,通过显式归一化和一个温度参数τ实现。而Oord等人[2018, CPC]在使用正样本对的同时保留了非参数化Softmax,并将这种方法命名为InfoNCE,具体如下:

InfoNCE损失不是简单地预测一个二元值,而是利用如余弦相似度这样的距离度量,在模型的表示空间中进行计算。这就需要计算正样本对之间的距离,以及所有负样本对之间的距离。通过Softmax函数,模型学习预测在表示空间中最相近的一对样本,同时将较低的概率赋予其他所有的负样本对。在如SimCLR [Chen et al., 2020]这样的自监督学习(SSL)方法中,正样本对被定义为一张图片及其经过手工数据增强的版本(例如,对原始图片应用灰度转换),而负样本对则是用一张图片与小批量(mini-batch)中的所有其他图片构建。InfoNCE基方法的主要缺点是引入了对小批量内容的依赖性。这通常需要大的小批量来使得对比训练准则在正负样本之间更为有效。
1.1 CLIP
一个常用的使用InfoNCE损失的对比方法是对比语言-图像预训练(CLIP)[Radford et al., 2021]。正样本对被定义为一张图像及其对应的真实标注文字,而负样本则是相同的图像配上mini-batch中描述其他图片的所有其他标注文字。CLIP的一个创新之处在于训练一个模型来在共享的表示空间中结合视觉和语言。CLIP训练随机初始化的视觉和文本编码器,通过对比损失将图像和其标注的表示映射到相似的嵌入向量中。在网络上收集的4亿个标注-图像对上进行训练的原始CLIP模型显示出了显著的零样本分类迁移能力。具体来说,使用ResNet-101架构的CLIP达到了与受监督ResNet[He et al., 2015]模型相匹配的性能(实现了76.2%的零样本分类准确率),并在多个鲁棒性基准测试中超越了它。
SigLIP [Zhai et al., 2023b] 类似于CLIP,不同之处在于它使用基于二元交叉熵的原始NCE损失,而不是使用基于InfoNCE的CLIP的多类别目标。这一改变使得在比CLIP更小的batch大小上获得了更好的零样本表
这篇关于多模态vlm综述:An Introduction to Vision-Language Modeling 论文解读的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



