本文主要是介绍第五节笔记:LMDeploy 大模型量化部署实践,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
大模型部署背景

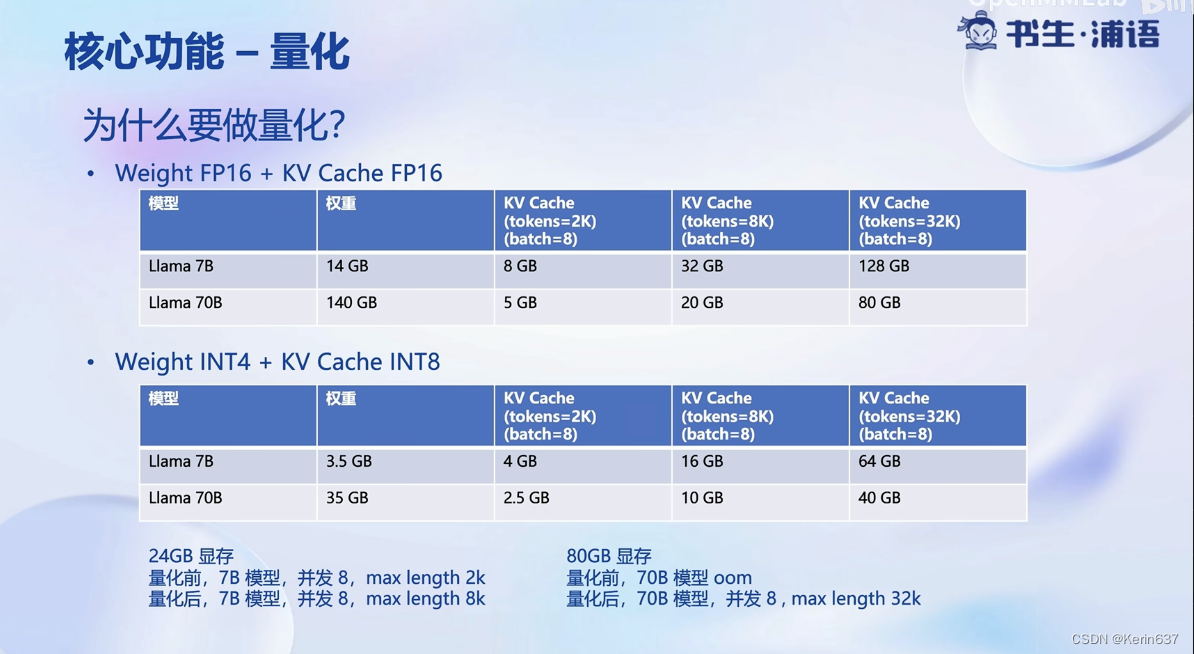
参数用FP16半精度也就是2字节,7B的模型就大约占14G

2.LMDeploy简介

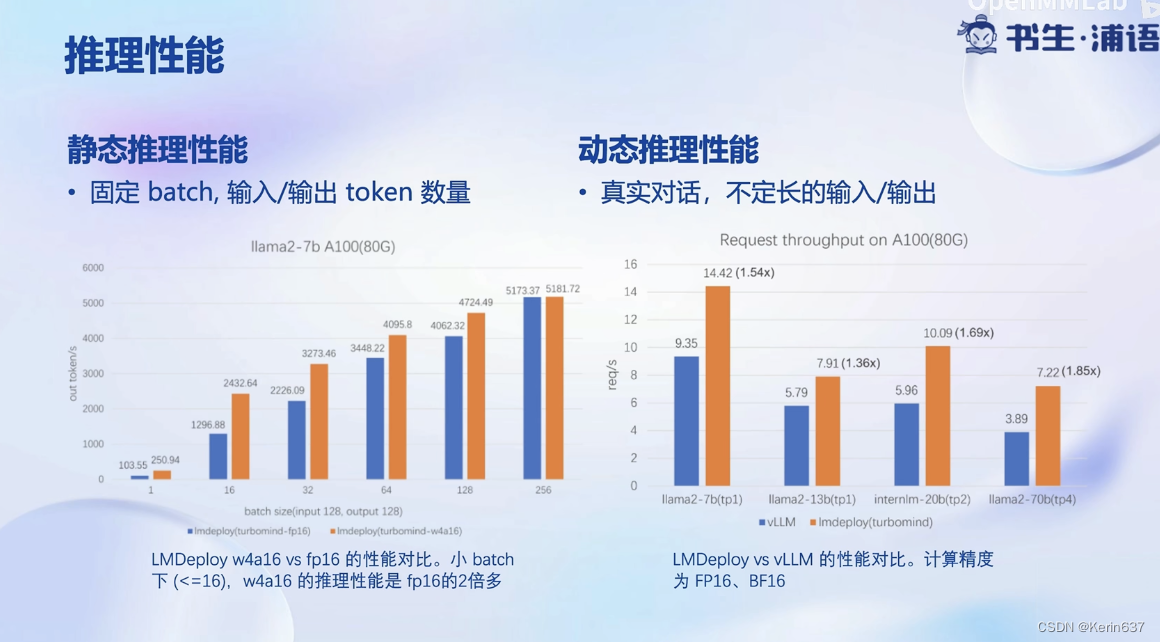
量化降低显存需求量,提高推理速度

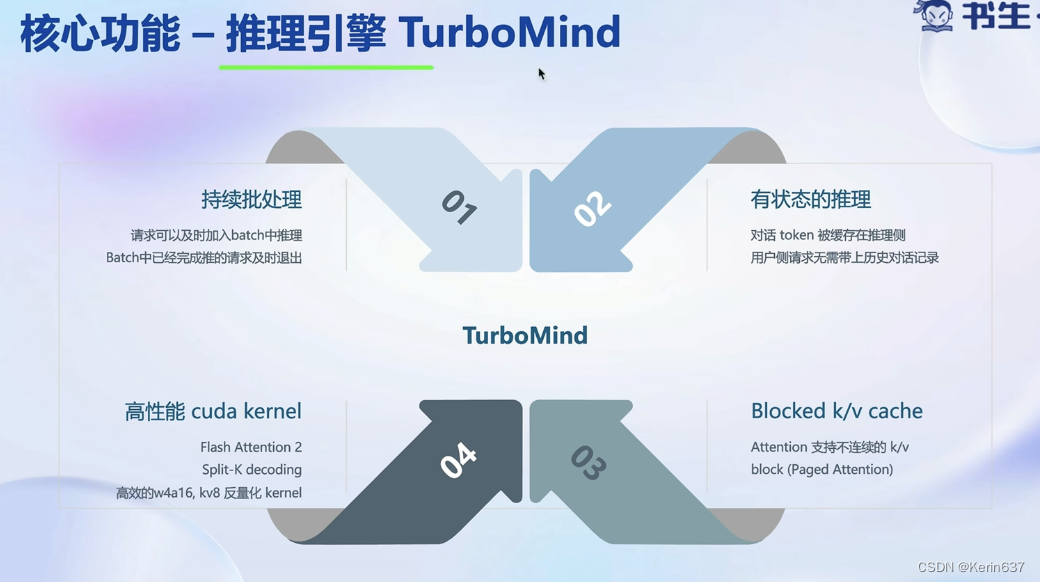
大语言模型推理是典型的访问密集型,因为是decoder only的架构,需要token by token的生成,因此需要频繁读取之前生成过的token。
这个量化只是在存储时做的, 在推理时还要反量化回FP16.
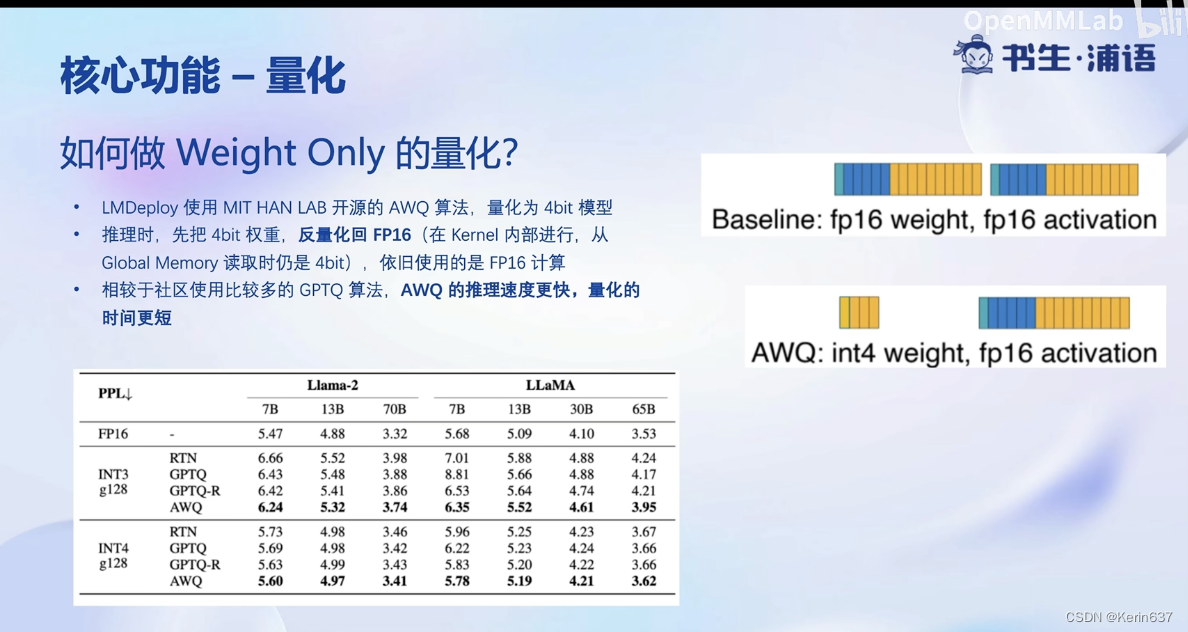
w4a16意思是参数4bit量化,激活时是16bit
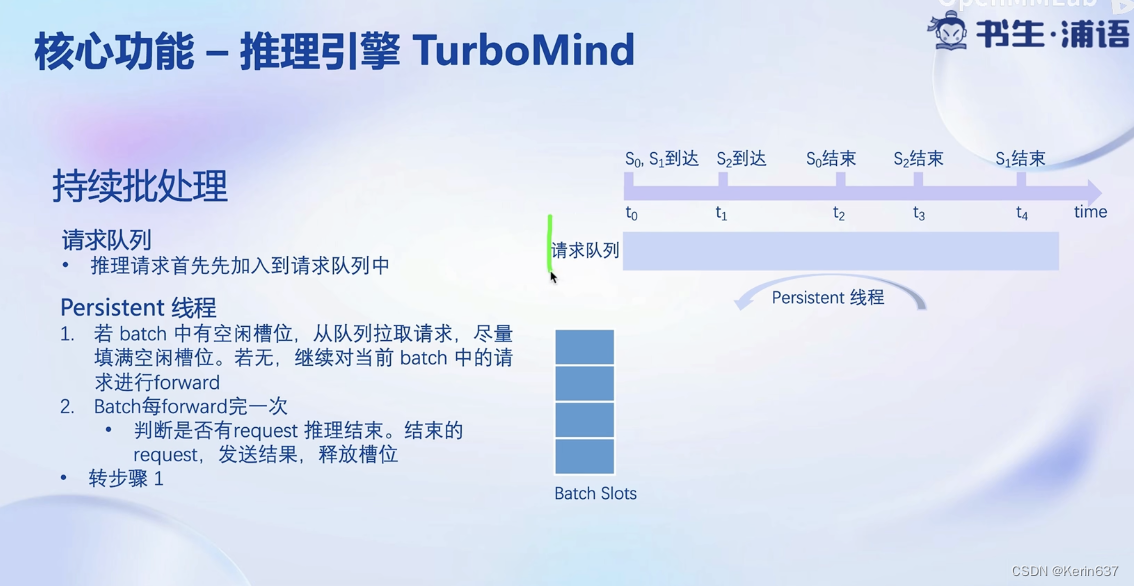
不用等一个batch的请求全部执行完才退出。
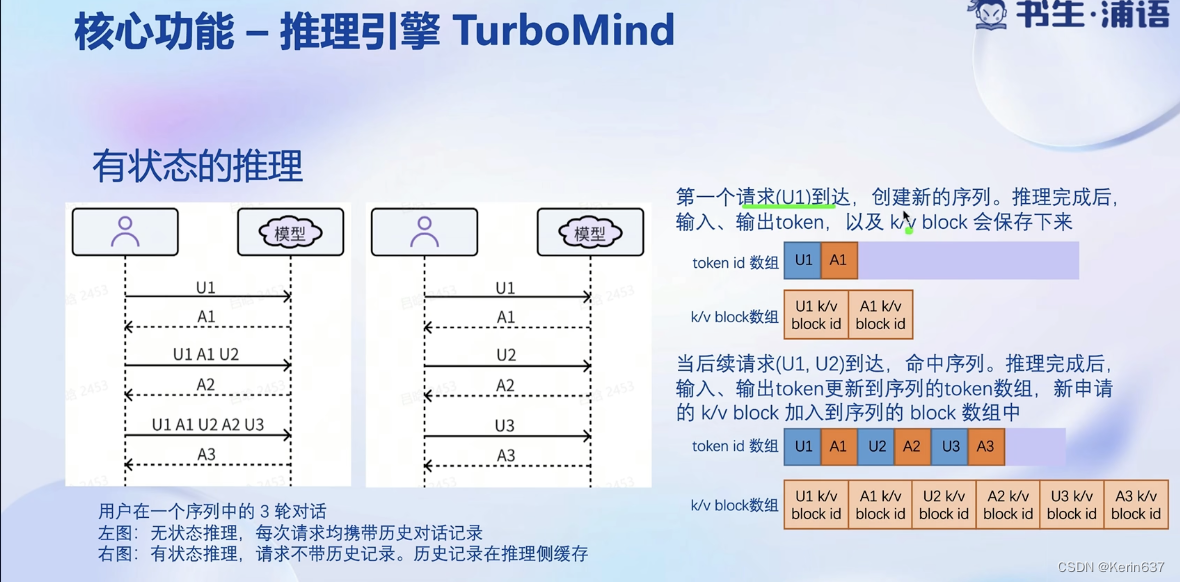
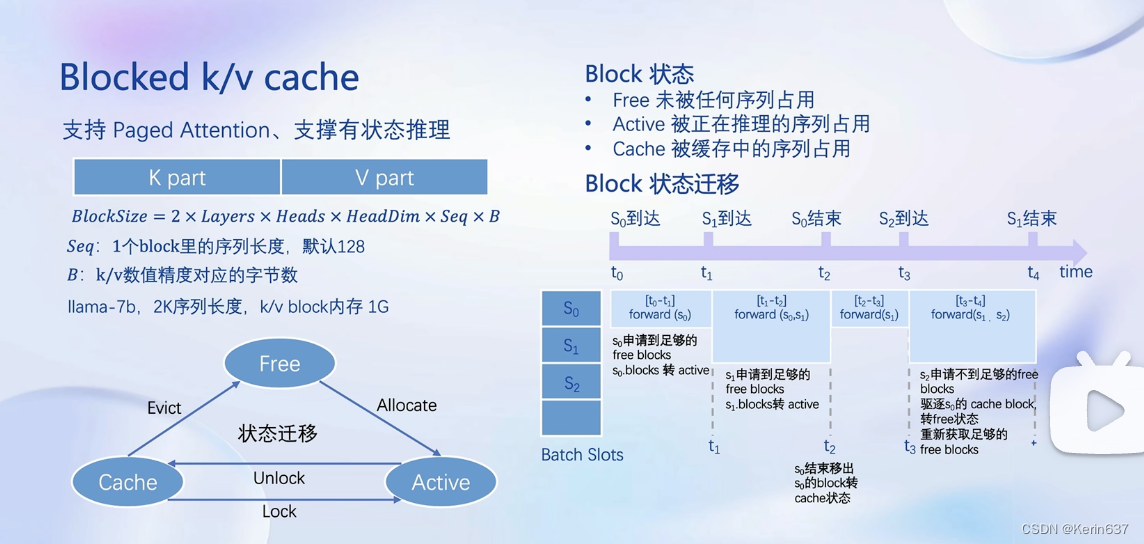
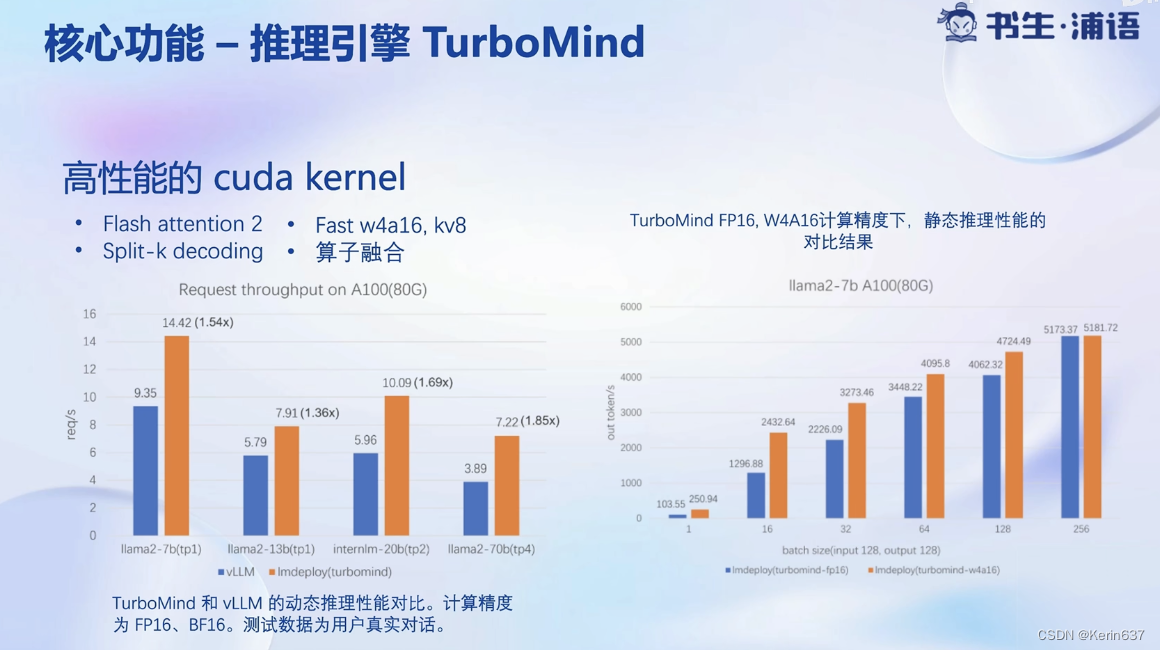
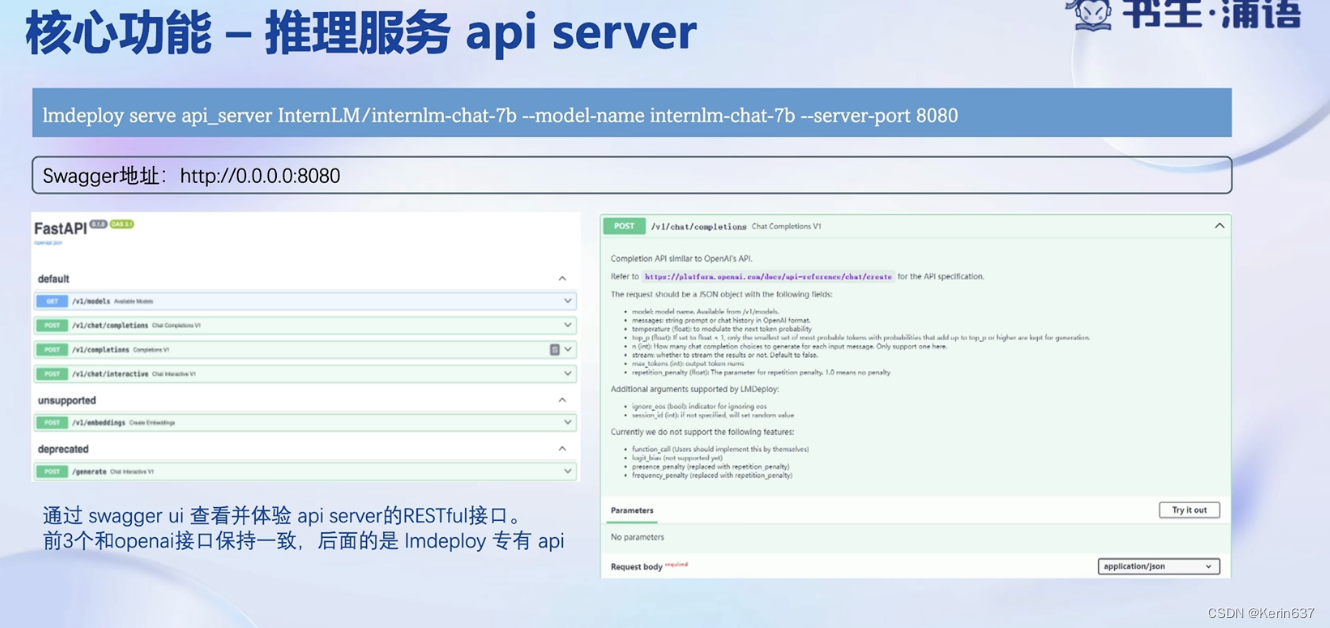
3.动手实践-安装、部署、量化
这篇关于第五节笔记:LMDeploy 大模型量化部署实践的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







