llamaindex专题

LlamaIndex 使用 RouterOutputAgentWorkflow
LlamaIndex 中提供了一个 RouterOutputAgentWorkflow 功能,可以集成多个 QueryTool,根据用户的输入判断使用那个 QueryEngine,在做查询的时候,可以从不同的数据源进行查询,例如确定的数据从数据库查询,如果是语义查询可以从向量数据库进行查询。本文将实现两个搜索引擎,根据不同 Query 使用不同 QueryEngine。 安装 MySQL 依赖
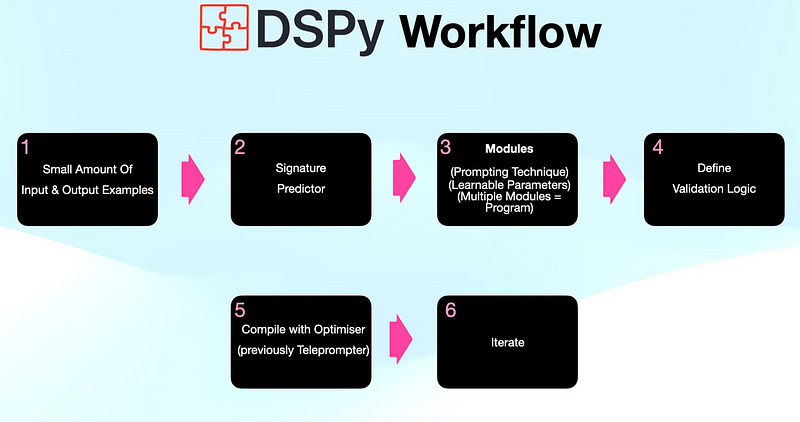
LlamaIndex结合DSPy,进一步优化RAG系统
大家好,本文将介绍如何运用LlamaIndex和DSPy这两个工具来构建和优化检索增强型生成(Retrieval-Augmented Generation, RAG)系统。通过这两个框架的无缝结合,不仅能够简化开发过程,还能显著提高RAG系统的整体性能。接下来,将详细解析LlamaIndex与DSPy如何高效协同,带来1+1>2的效果。 1.LlamaIndex LlamaIndex 是用于构

【LLM大模型深度解析】LlamaIndex的高阶概念详解
本篇内容为您快速介绍在构建基于大型语言模型(LLM)的应用程序时会频繁遇到的一些核心概念。 增强检索生成(RAG) LLM 是基于海量数据训练而成,但并未涵盖您的具体数据。增强检索生成(Retrieval-Augmented Generation, RAG)通过将您的数据添加至 LLM 已有的数据集中,解决了这一问题。在本文档中,您将频繁看到对 RAG 的引用。 在 RAG 中,您的数据被加

开源模型应用落地-LlamaIndex学习之旅-LLMs-集成vLLM(二)
一、前言 在这个充满创新与挑战的时代,人工智能正以前所未有的速度改变着我们的学习和生活方式。LlamaIndex 作为一款先进的人工智能技术,它以其卓越的性能和创新的功能,为学习者带来前所未有的机遇。我们将带你逐步探索 LlamaIndex 的强大功能,从快速整合海量知识资源,到智能生成个性化的学习路径;从精准分析复杂的文本内容,到与用户进行深度互动交流。通过丰富的实例展示和详细的操作指

LlamaIndex 工作流
LlamaIndex 内部提供了一个简单的工作流引擎,为什么要有工作流引擎?做过 OA 的同学都了解工作流引擎,工作流的优势在于模块化开发,把业务节点进行抽象,流程于业务逻辑分离,方便进行业务节点组装,也是很多低代码平台的底层工作原理。大语言模型的应用特别适合工作流, 模型可以理解一个万能的 API,传统的 API 都有固定的入参、出参、功能,而模型会根据提示词做推理,具体做什么,返回什么,需要用

LlamaIndex 实现 Agent
RAG 是在数据层面为大模型提供更多、更新的外部知识,而 Agent (智能体),为大模型扩展了推理业务的能力。数据是静态的,数据周期可能是天、小时甚至到秒,通过 RAG 实现时,需要调用对应系统的 API 去实时获取相关数据并组合发给 LLM,如果是一系列动作完成一个需求,前一个动作的输出是下一个动作的输入,使用 RAG 处理就相当复杂,也没有利用到大模型强大的推理能力。 Agent 的推出很

LlamaIndex 实现 RAG(四)- RAG 跟踪监控
RAG 整个流程不复杂,集成三大部分包括文档解析并生成向量、根据查询问题查找语意相似的数据文档块、把查询问题和召回文档作为上下文的数据传给模型进行解答。大语言模型的应用开发和传统的开发方式区别很大,以前开发完成,只要逻辑正确,结果肯定是固定的,但是由于模型的特性,结果是基于概率计算的,加上自然语言的特殊性,近义词很多,每次回答都是正确的,但是返回的内容确不一样,可能是有些词改为了近义词,也可能描述

LlamaIndex 实现 RAG(三)- 向量数据
RAG 中使用向量存储知识和文档数据,召回时通过语意进行搜索。文档转为向量是个非常消耗时的操作,不同 Embedding Model 参数不同,结果维度也不同,消耗的算力也不同。所以通常的做法都会在索引阶段(Embedding)把向量保存到向量数据库中,在召回阶段,向量数据库会根据选择的算法计算向量相似度,最终将分数高的数据进行返回。本文将介绍向量数据库的使用方法,包括以下几部分 什么是 Emb

LlamaIndex 实现 RAG(二)- 文档解析
RAG 中最关键的就是知识库构建,知识库主要的作用就是为大模型提供内企业内部知识或者新的知识。在 RAG 中,知识存储通常是把文档进行拆分为块 (Chunk),并通过 Embedding 模型将文档块转为向量型数据,并将向量数据进行保存,为后续的搜索提供数据。文档通常分为多种类型,比较常见的文档类型包括 Work、PDF、Markdown,对于 Excel 这种表格型文档,也可以转为 Markdo

【3种 LangChain 替代品 LlamaIndex、FlowiseAI、Autochain】
3种 LangChain 替代品 LlamaIndex、FlowiseAI、Autochain 一、LangChain 发展背景解析 LangChain 是一款广受欢迎的开源框架,过度抽象化导致构建不受框架支持的用例困难、调试性能问题和错误变得更难、代码质量可能较低等。 二、基于 7 大维度全方位分析替换 LangChain 可行性分析 Prompt Engineering - 提示工程:

【大模型LLMs】RAG实战:基于LlamaIndex快速构建RAG链路(Qwen2-7B-Instruct+BGE Embedding)
【大模型LLMs】RAG实战:基于LlamaIndex快速构建RAG链路(Qwen2-7B-Instruct+BGE Embedding) 1. 环境准备2. 数据准备3. RAG框架构建3.1 数据读取 + 数据切块3.2 构建向量索引3.3 检索增强3.4 main函数 参考 基于LlamaIndex框架,以Qwen2-7B-Instruct作为大模型底座,bge-base-

构建基于 LlamaIndex 的RAG AI Agent
I built a custom AI agent that thinks and then acts. I didn't invent it though, these agents are known as ReAct Agents and I'll show you how to build one yourself using LlamaIndex in this tutorial. 我

如何选择合适的大模型框架:LangChain、LlamaIndex、Haystack 还是 Hugging Face
节前,我们星球组织了一场算法岗技术&面试讨论会,邀请了一些互联网大厂朋友、参加社招和校招面试的同学。 针对算法岗技术趋势、大模型落地项目经验分享、新手如何入门算法岗、该如何准备、面试常考点分享等热门话题进行了深入的讨论。 合集: 《大模型面试宝典》(2024版) 正式发布! 目前生成式大模型开发应用框架主要有四个:LangChain、LlamaIndex、Haystack 和 Hugg
LlamaIndex vs LangChain vs Haystack——为你的 LLM app 选择合适的一款
随着 LLM 应用程序领域的不断发展,3 个著名的框架已成为首选:LlamaIndex、LangChain 和 Haystack 在本篇文章中,我将对这些框架进行全面比较,重点介绍它们各自的优缺点和使用案例: LlamaIndex LlamaIndex 是一个功能强大的框架,它简化了构建由 LLM 驱动的应用程序的过程。它擅长将文档、数据库和 API 等各种数据源与语言模型集成在一起,以实现
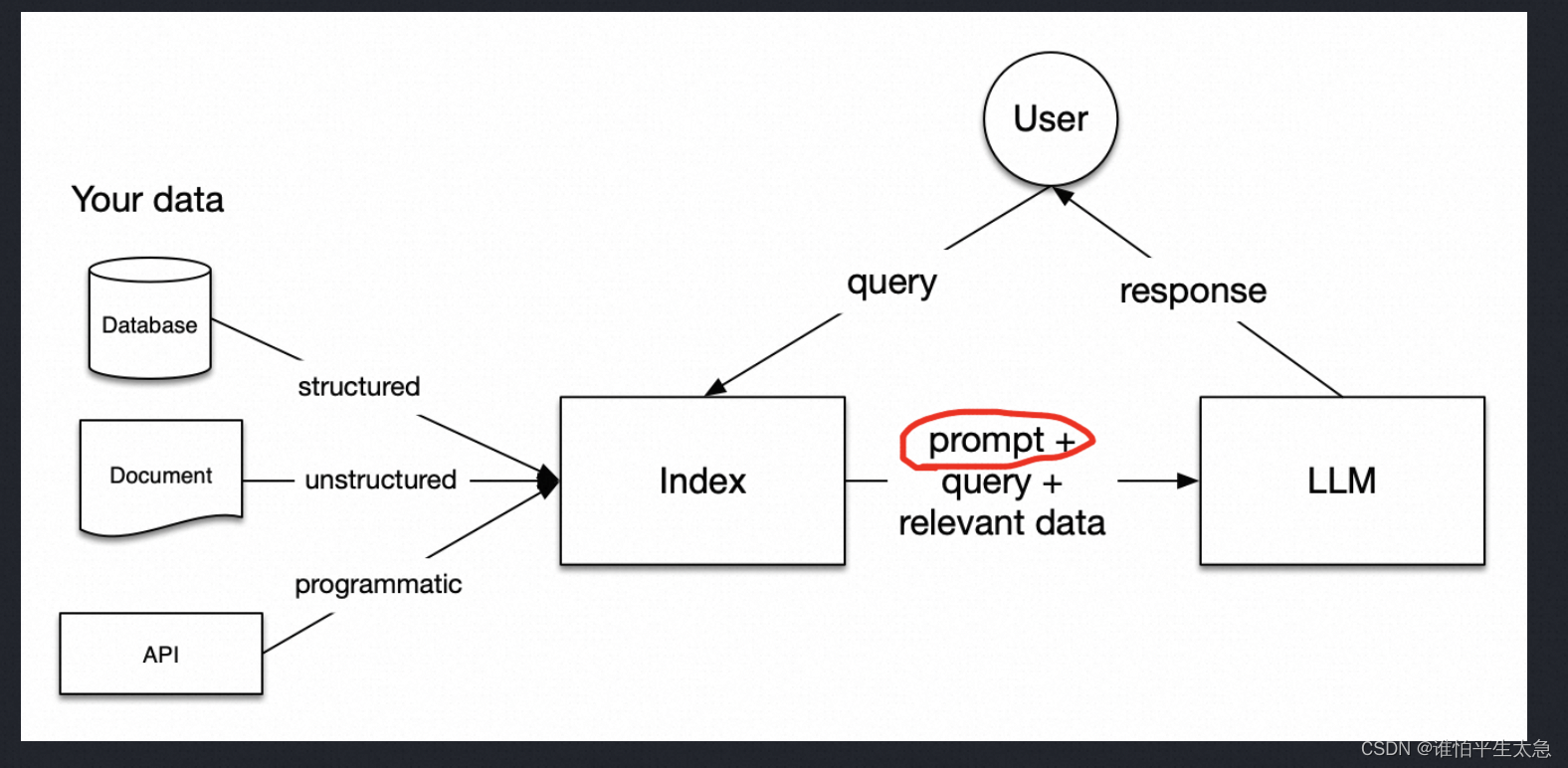
LlamaIndex介绍
LlamaIndex LangChain v0.2 教程分成以下部分: 1、入门 2、学习 3、用例 4、示例 5、高级 6、组件指南 RAG 用额外的信息来提高回答的质量。 分为 5个阶段: (1)loading 加载原始文件,LlamaHub 提供数百种连接器可供选择 node 节点和 document 文档:document 指的是 数据源的容器,比如PDF、A
LangChain llamaindex
LangChain 参考: 全流程 | Windows 系统本地部署开源模型阿里通义千问 QWEN 1.5,结合 LangChain-Chatchat 框架和向量数据库 FAISS、Milvus - 知乎
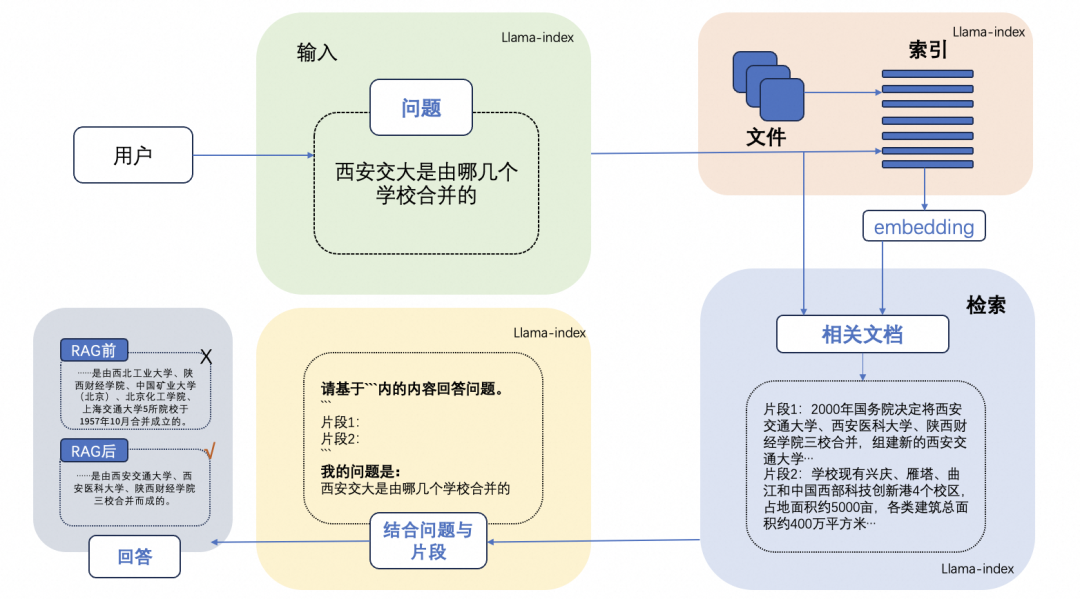
检索增强生成(RAG)实践:基于LlamaIndex和Qwen1.5搭建智能问答系统
检索增强生成(RAG)实践:基于LlamaIndex和Qwen1.5搭建智能问答系统 什么是 RAG LLM 会产生误导性的 “幻觉”,依赖的信息可能过时,处理特定知识时效率不高,缺乏专业领域的深度洞察,同时在推理能力上也有所欠缺。 正是在这样的背景下,检索增强生成技术(Retrieval-Augmented Generation,RAG)应时而生,成为 AI 时代的一大趋势。RAG 通过
使用 LlamaIndex 和 Llama 2-Chat 构建知识驱动的对话应用程序
文章目录 使用 LlamaIndex 和 Llama 2-Chat 构建知识驱动的对话应用程序Llama 2-70B-聊天LlamaIndex 解决方案概述先决条件使用 SageMaker JumpStart 部署 GPT-J 嵌入模型使用 SageMaker Python SDK 进行部署在 SageMaker Studio 中使用 SageMaker JumpStart 进行部署使用 S
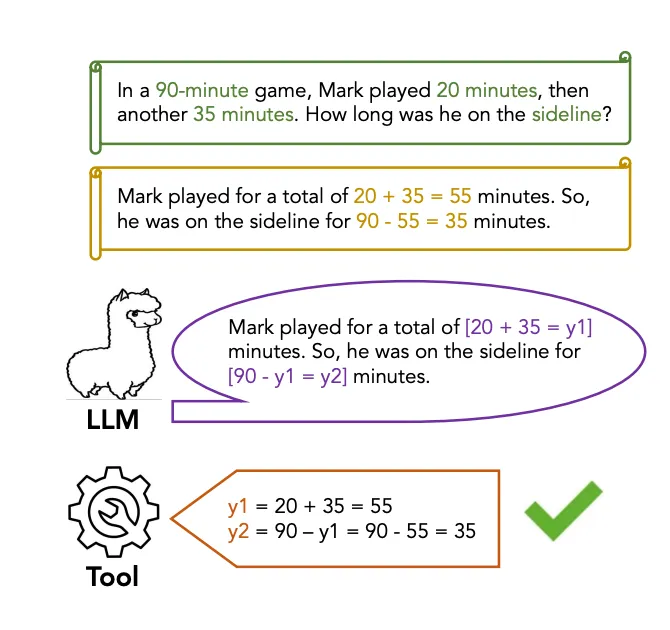
解锁大模型高效推理:将 LlamaIndex 与抽象链集成
在语言理解领域,对忠实推理的追求促使研究人员探索各种途径。 大型语言模型(LLMs)在解释和执行指令方面取得了显著进展,但在准确回忆和组合现实世界知识方面仍然面临挑战。 为了解决这个问题,将外部工具集成到LLMs的推理过程中已经成为一种有前途的方法。 虽然工具可以通过提供对外部知识源的访问来促进这一过程,但有效地将它们整合到多步推理任务中仍然是一个挑战。相互连接的工具调用需要对工具的有效使用
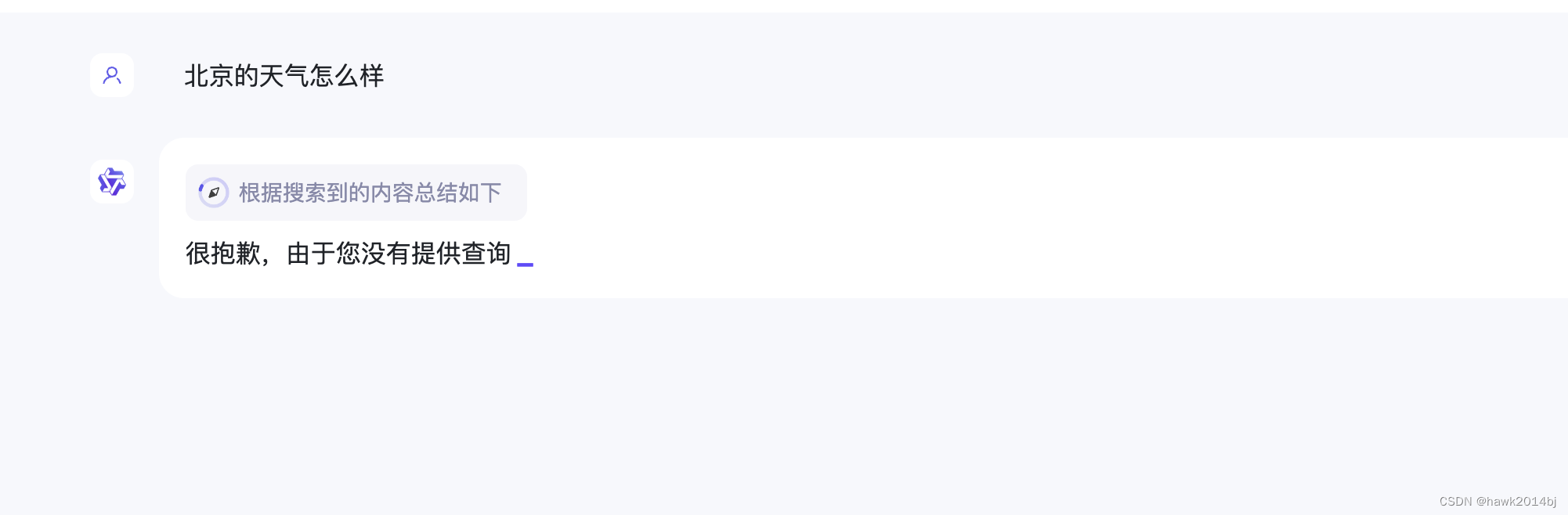
LlamaIndex 加 Ollama 实现 Agent
AI Agent 是 AIGC 落地实现的场景之一,与 RAG 不同,RAG 是对数据的扩充,是模型可以学习到新数据或者本地私有数据。AI Agent 是自己推理,自己做,例如你对 AI Agent 说我要知道今天上海的天气怎么样,由于 AI 是个模型,底层通过一套复杂的算法进行相似度的比较,最终选出相似最高的答案,所以模型本身是无法访问网络去获取数据的。如果AIGC 只能回答问题,复杂任务和与外
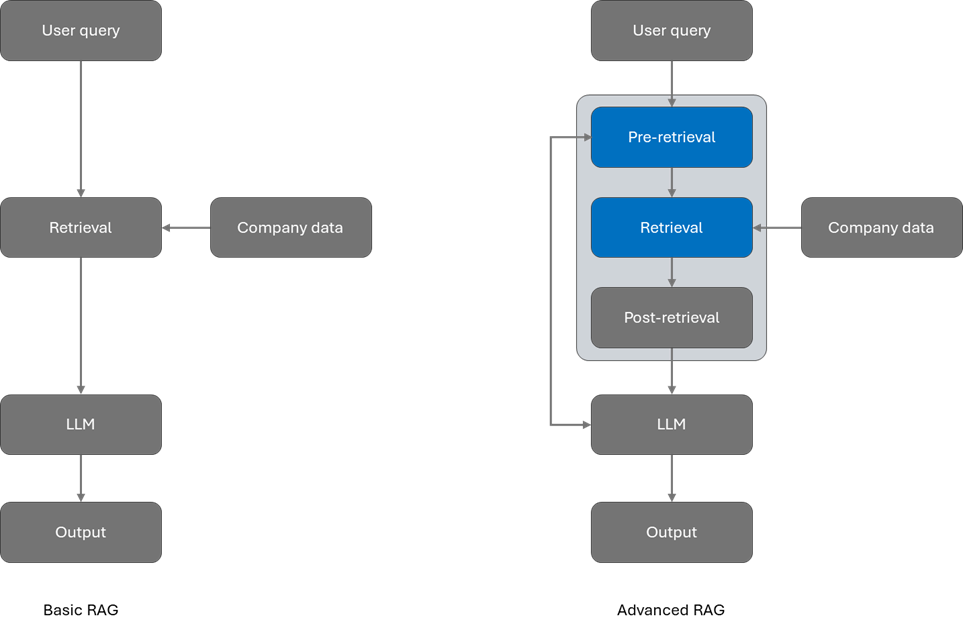
使用Azure AI Search和LlamaIndex构建高级RAG应用
RAG 是一种将公司信息合并到基于大型语言模型 (LLM) 的应用程序中的常用方法。借助 RAG,AI 应用程序可以近乎实时地访问最新信息,团队可以保持对其数据的控制。 在 RAG 中,您可以评估和修改各个阶段以改进结果,它们分为三类:预检索、检索和检索后。 预检索可提高使用查询重写等技术检索的数据的质量。检索使用混合搜索和语义排序等高级技术改进结果。检索后侧重于优化检索信息和增强提示。
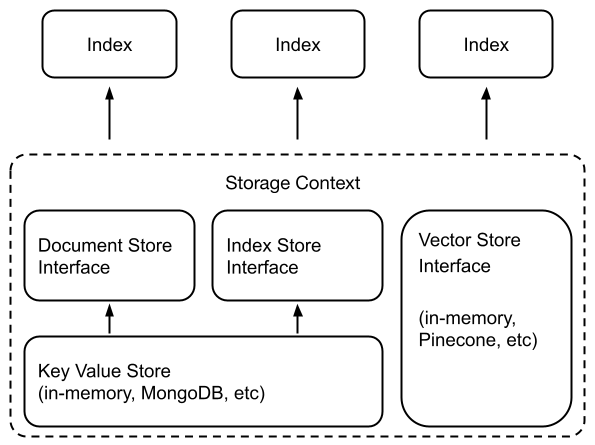
LlamaIndex 组件 - Storing
文章目录 一、储存概览1、概念2、使用模式3、模块 二、Vector Stores1、简单向量存储2、矢量存储选项和功能支持3、Example Notebooks 三、文件存储1、简单文档存储2、MongoDB 文档存储3、Redis 文档存储4、Firestore 文档存储 四、索引存储1、简单索引存储2、MongoDB 索引存储3、Redis索引存储 五、Chat Stores1、简单聊
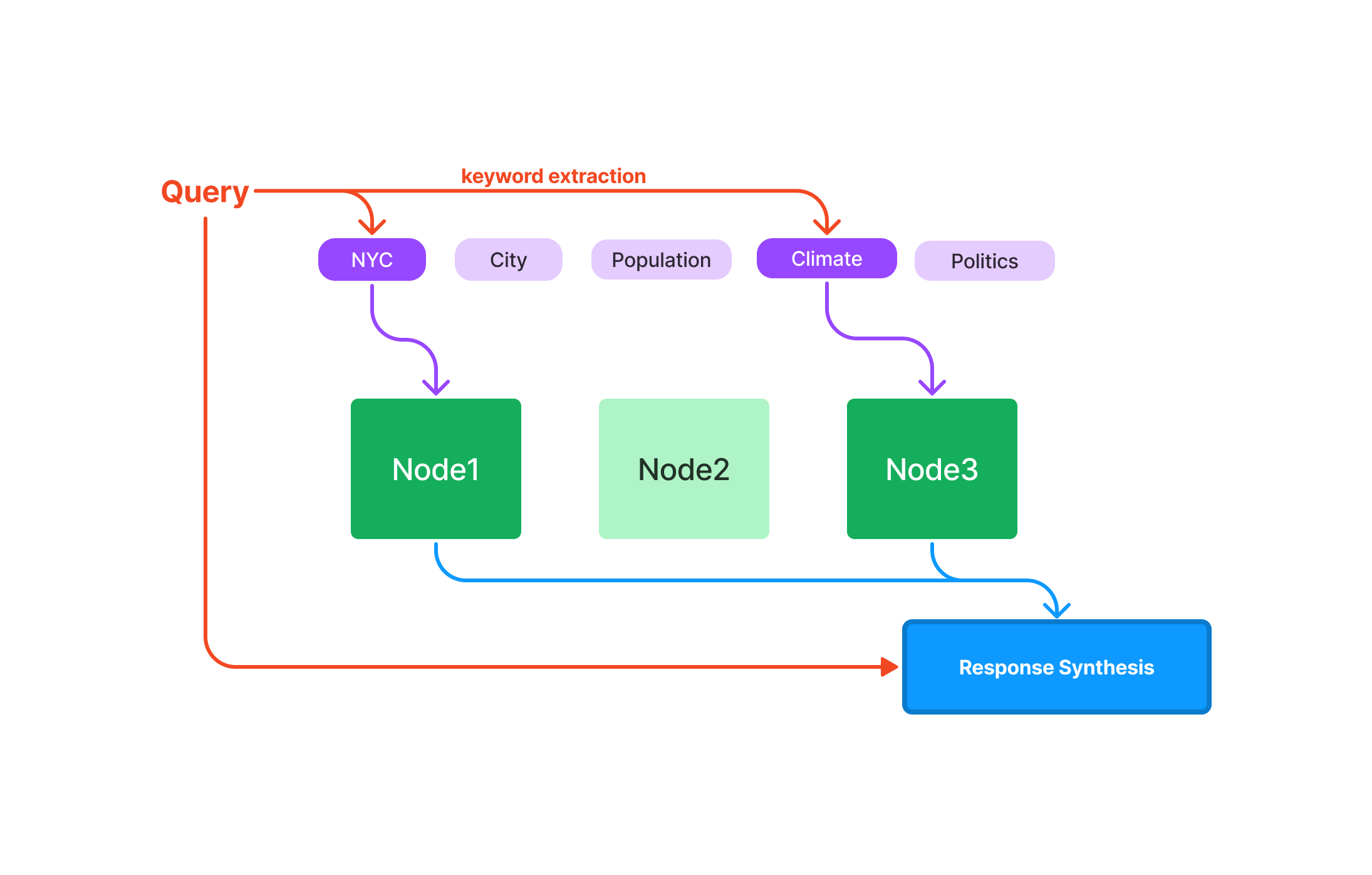
LlamaIndex 组件 - Indexing
文章目录 一、索引概览概念 二、每个指数如何运作1、摘要索引(以前称为列表索引)查询 2、向量存储索引查询 3、树索引查询 4、关键字表索引查询 三、使用VectorStoreIndex1、将数据加载到索引中1.1 基本用法1.2 使用摄取管道创建节点1.3 直接创建和管理节点处理文档更新 2、存储向量索引3、可组合检索 四、文件管理1、插入2、删除3、更新4、刷新5、文件追踪 五、Ll
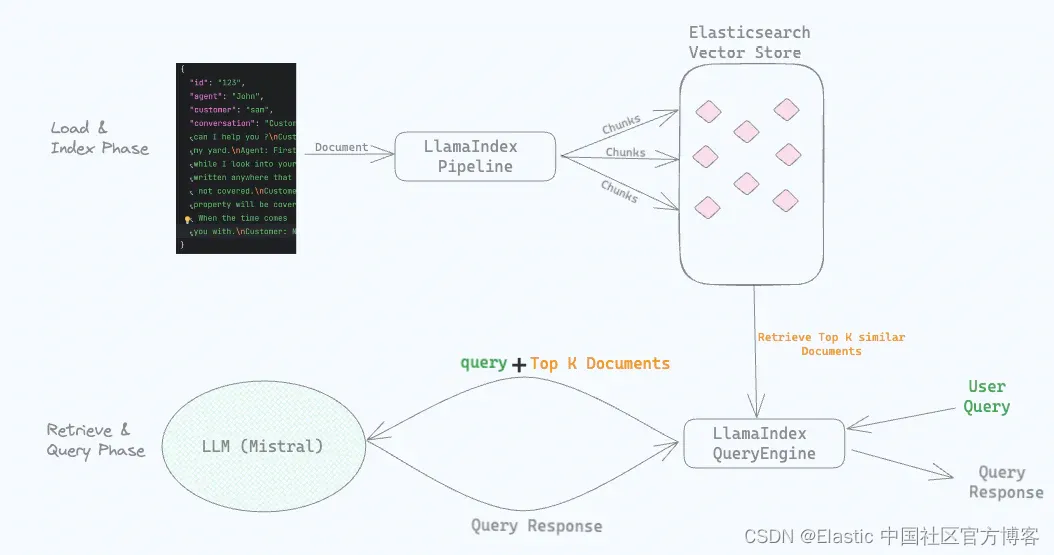
RAG (Retrieval Augmented Generation) 结合 LlamaIndex、Elasticsearch 和 Mistral
作者:Srikanth Manvi 在这篇文章中,我们将讨论如何使用 RAG 技术(检索增强生成)和 Elasticsearch 作为向量数据库来实现问答体验。我们将使用 LlamaIndex 和本地运行的 Mistral LLM。 在开始之前,我们将先了解一些术语。 术语解释: LlamaIndex 是一个领先的数据框架,用于构建 LLM(大型语言模型)应用程序。LlamaIndex
LlamaIndex 组件 - Prompts
文章目录 一、关于 Prompts1、概念2、使用模式概览3、示例指南 二、使用模式1、定义自定义提示2、获取和设置自定义提示2.1 常用提示2.2 访问提示2.3 更新提示2.4 修改查询引擎中使用的提示2.5 修改索引构建中使用的提示 3、[高级]高级提示功能3.1 部分格式化3.2 模板变量映射3.3 函数映射 一、关于 Prompts 1、概念 提示是赋予LL

LlamaIndex 文档 2
文章目录 一、构建 LLM 应用构建LLM 应用的关键步骤 二、使用LLM可用的LLM使用本地LLM Prompts 三、加载数据(提取)Loaders1、使用 SimpleDirectoryReader 加载2、使用 LlamaHub 的 Readers3、直接创建文档 转换 Transformations1、高级转换 API2、较低级别的转换 API将文档拆分为节点 3、添加元数据4、添