本文主要是介绍解锁大模型高效推理:将 LlamaIndex 与抽象链集成,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
在语言理解领域,对忠实推理的追求促使研究人员探索各种途径。
大型语言模型(LLMs)在解释和执行指令方面取得了显著进展,但在准确回忆和组合现实世界知识方面仍然面临挑战。
为了解决这个问题,将外部工具集成到LLMs的推理过程中已经成为一种有前途的方法。
虽然工具可以通过提供对外部知识源的访问来促进这一过程,但有效地将它们整合到多步推理任务中仍然是一个挑战。相互连接的工具调用需要对工具的有效使用进行整体规划,促使探索新的方法论来增强LLMs的推理能力。
节前,我们组织了一场算法岗技术&面试讨论会,邀请了一些互联网大厂朋友、今年参加社招和校招面试的同学。
针对大模型技术趋势、大模型落地项目经验分享、新手如何入门算法岗、该如何准备面试攻略、面试常考点等热门话题进行了深入的讨论。
总结链接如下:
重磅消息!《大模型面试宝典》(2024版) 正式发布!
技术交流&资料
技术要学会分享、交流,不建议闭门造车。一个人可以走的很快、一堆人可以走的更远。
成立了大模型面试和技术交流群,相关资料、技术交流&答疑,均可加我们的交流群获取,群友已超过2000人,添加时最好的备注方式为:来源+兴趣方向,方便找到志同道合的朋友。
方式①、微信搜索公众号:机器学习社区,后台回复:加群
方式②、添加微信号:mlc2040,备注:来自CSDN + 技术交流
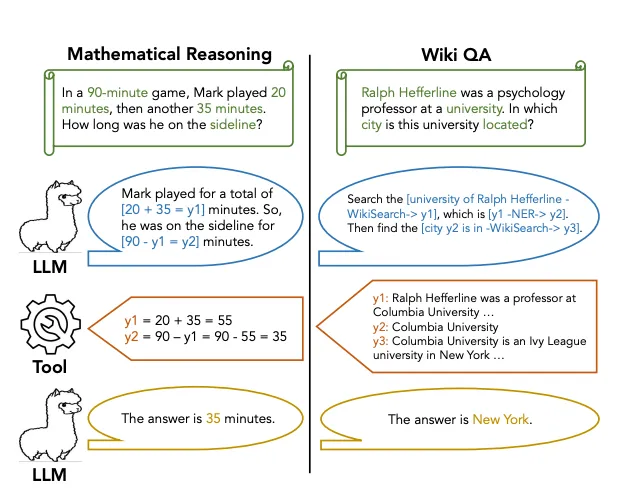
抽象链(CoA)
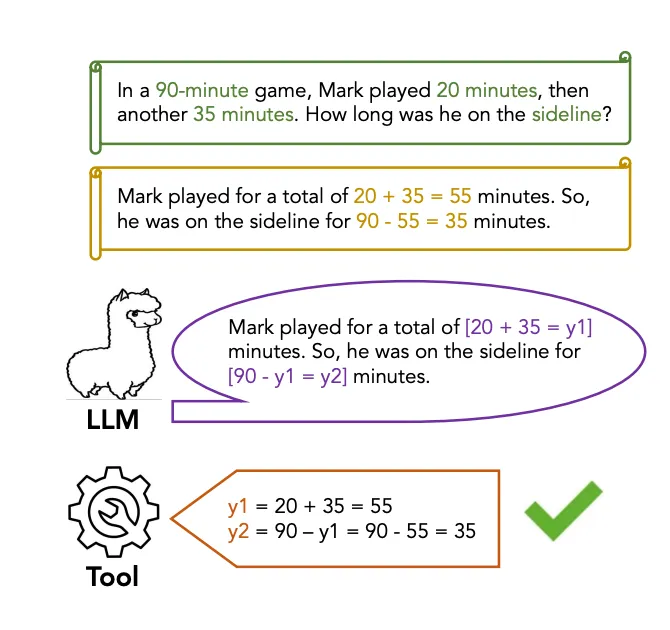
在这个背景下,我们介绍了抽象链(CoA)推理,这是一种旨在通过整合外部工具来增强LLMs多步推理的方法论。
CoA包括训练LLMs来解码带有抽象占位符的推理链,然后调用领域特定的工具来填充特定的知识,从而为最终答案生成提供基础。
LlamaIndex 是一个设计的综合知识索引系统,旨在为LLMs提供访问广泛的外部知识源的能力。它充当LLMs和现实世界知识之间的桥梁,使它们能够检索与推理任务相关的信息。通过利用LlamaIndex,LLMs可以访问领域特定的知识、事实数据和对准确和上下文相关推理所必需的上下文信息。
将LlamaIndex与抽象链集成的好处
-
泛化推理策略:通过解码带有抽象占位符的推理链,LLMs学习到更加泛化的推理策略,这些策略在不同领域中都具有稳健性,使它们能够轻松适应领域知识的变化。
-
高效的工具使用:CoA使LLMs能够并行进行解码和工具调用,消除了等待工具响应所带来的推理延迟。这导致工具的使用更加高效,推理速度更快,最终提升了LLMs的整体性能。
代码实现
CoA 的实现涉及两个关键阶段:
-
微调LLMs:LLMs被微调以生成带有抽象占位符的推理链,这些占位符不影响推理流程,但使得后续可以使用来自外部工具的具体知识进行填充。
-
推理链实例化:每个推理链都通过用来自外部工具检索到的领域特定知识替换抽象占位符来实例化。这种基于实际的方法确保了最终答案的准确性和上下文相关性。
第一步:安装库并初始化OpenAI
%pip install llama-index-core llama-index-llms-openai llama-index-embeddings-openai
%pip install llama-index-packs-agents-coa#初始化OpenAI
import osos.environ["OPENAI_API_KEY"] = "sk-..."import nest_asyncionest_asyncio.apply()
第二步:数据下载
!mkdir -p 'data/10k/'
!wget 'https://raw.githubusercontent.com/run-llama/llama_index/main/docs/docs/examples/data/10k/uber_2021.pdf' -O 'data/10k/uber_2021.pdf'
!wget 'https://raw.githubusercontent.com/run-llama/llama_index/main/docs/docs/examples/data/10k/lyft_2021.pdf' -O 'data/10k/lyft_2021.pdf'
第三步:导入库
from llama_index.core import Settings
from llama_index.embeddings.openai import OpenAIEmbedding
from llama_index.llms.openai import OpenAIfrom llama_index.core import StorageContext, load_index_from_storagefrom llama_parse import LlamaParse
from llama_index.core import SimpleDirectoryReader, VectorStoreIndexfrom llama_index.core.tools import QueryEngineToolSettings.embed_model = OpenAIEmbedding(model="text-embedding-3-small", embed_batch_size=256
)
Settings.llm = OpenAI(model="gpt-4-turbo", temperature=0.1)try:storage_context = StorageContext.from_defaults(persist_dir="./storage/lyft")lyft_index = load_index_from_storage(storage_context)storage_context = StorageContext.from_defaults(persist_dir="./storage/uber")uber_index = load_index_from_storage(storage_context)index_loaded = True
except:index_loaded = False# LlamaParse用于加载PDF文档
file_extractor = {".pdf": LlamaParse(result_type="markdown",api_key="llx-...",)
}if not index_loaded:# 加载数据lyft_docs = SimpleDirectoryReader(input_files=["./data/10k/lyft_2021.pdf"],file_extractor=file_extractor,).load_data()uber_docs = SimpleDirectoryReader(input_files=["./data/10k/uber_2021.pdf"],file_extractor=file_extractor,).load_data()# 构建索引lyft_index = VectorStoreIndex.from_documents(lyft_docs)uber_index = VectorStoreIndex.from_documents(uber_docs)# 持久化索引lyft_index.storage_context.persist(persist_dir="./storage/lyft")uber_index.storage_context.persist(persist_dir="./storage/uber")lyft_engine = lyft_index.as_query_engine(similarity_top_k=2)
uber_engine = uber_index.as_query_engine(similarity_top_k=2)query_engine_tools = [QueryEngineTool.from_defaults(query_engine=lyft_engine,name="lyft_10k",description=("提供2021年Lyft的财务信息。""请使用详细的纯文本问题作为工具的输入。"),),QueryEngineTool.from_defaults(query_engine=uber_engine,name="uber_10k",description=("提供2021年Uber的财务信息。""请使用详细的纯文本问题作为工具的输入。"),),
]
第四步:运行CoAAgentPack
# 导入CoAAgentPack类
from llama_index.packs.agents_coa import CoAAgentPack# 创建CoAAgentPack实例,传入查询引擎工具和LLM模型
pack = CoAAgentPack(tools=query_engine_tools, llm=Settings.llm)# 运行CoAAgentPack,输入问题
response = pack.run("2021年Uber的收入增长如何与Lyft相比?")# 来源# ==== 可用的解析函数 ====
def lyft_10k(input: string):"""提供2021年Lyft的财务信息。请使用详细的纯文本问题作为工具的输入。"""...def uber_10k(input: string):"""提供2021年Uber的财务信息。请使用详细的纯文本问题作为工具的输入。"""...# ==== 生成的抽象链 ====
# 要比较2021年Uber和Lyft的收入增长,我们需要获取这两家公司在该年的收入增长数据。# 1. 通过使用关于收入增长的具体问题查询Uber财务工具,获取2021年Uber的收入增长:
# - [FUNC uber_10k("What was Uber's revenue growth in 2021?") = y1]# 2. 通过使用类似的关于收入增长的问题查询Lyft财务工具,获取2021年Lyft的收入增长:
# - [FUNC lyft_10k("What was Lyft's revenue growth in 2021?") = y2]# 3. 比较获取的收入增长数据(y1和y2),以确定哪家公司在2021年的增长更高。这个比较将由读者在执行函数调用后进行。
# ==== 使用输入["What was Uber's revenue growth in 2021?"]执行 uber_10k ====
# ==== 使用输入["What was Lyft's revenue growth in 2021?"]执行 lyft_10k ====
结论
综上所述,将 LlamaIndex 与抽象链集成为增强LLMs的多步推理能力提供了有前途的途径。
通过系统和高效地利用外部工具,LLMs可以获得更准确和与上下文相关的响应,从而推动语言理解和推理技术的最新进展。
利用像 CoA 这样的创新方法,我们为释放 LLMs 的全部潜力铺平了道路,使它们能够轻松高效地处理复杂的推理任务。
通俗易懂讲解大模型系列
-
重磅消息!《大模型面试宝典》(2024版) 正式发布!
-
重磅消息!《大模型实战宝典》(2024版) 正式发布!
-
做大模型也有1年多了,聊聊这段时间的感悟!
-
用通俗易懂的方式讲解:大模型算法工程师最全面试题汇总
-
用通俗易懂的方式讲解:不要再苦苦寻觅了!AI 大模型面试指南(含答案)的最全总结来了!
-
用通俗易懂的方式讲解:我的大模型岗位面试总结:共24家,9个offer
-
用通俗易懂的方式讲解:大模型 RAG 在 LangChain 中的应用实战
-
用通俗易懂的方式讲解:ChatGPT 开放的多模态的DALL-E 3功能,好玩到停不下来!
-
用通俗易懂的方式讲解:基于扩散模型(Diffusion),文生图 AnyText 的效果太棒了
-
用通俗易懂的方式讲解:在 CPU 服务器上部署 ChatGLM3-6B 模型
-
用通俗易懂的方式讲解:ChatGLM3-6B 部署指南
-
用通俗易懂的方式讲解:使用 LangChain 封装自定义的 LLM,太棒了
-
用通俗易懂的方式讲解:基于 Langchain 和 ChatChat 部署本地知识库问答系统
-
用通俗易懂的方式讲解:Llama2 部署讲解及试用方式
-
用通俗易懂的方式讲解:一份保姆级的 Stable Diffusion 部署教程,开启你的炼丹之路
-
用通俗易懂的方式讲解:LlamaIndex 官方发布高清大图,纵览高级 RAG技术
-
用通俗易懂的方式讲解:为什么大模型 Advanced RAG 方法对于AI的未来至关重要?
-
用通俗易懂的方式讲解:基于 Langchain 框架,利用 MongoDB 矢量搜索实现大模型 RAG 高级检索方法
这篇关于解锁大模型高效推理:将 LlamaIndex 与抽象链集成的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






