本文主要是介绍使用Azure AI Search和LlamaIndex构建高级RAG应用,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
RAG 是一种将公司信息合并到基于大型语言模型 (LLM) 的应用程序中的常用方法。借助 RAG,AI 应用程序可以近乎实时地访问最新信息,团队可以保持对其数据的控制。
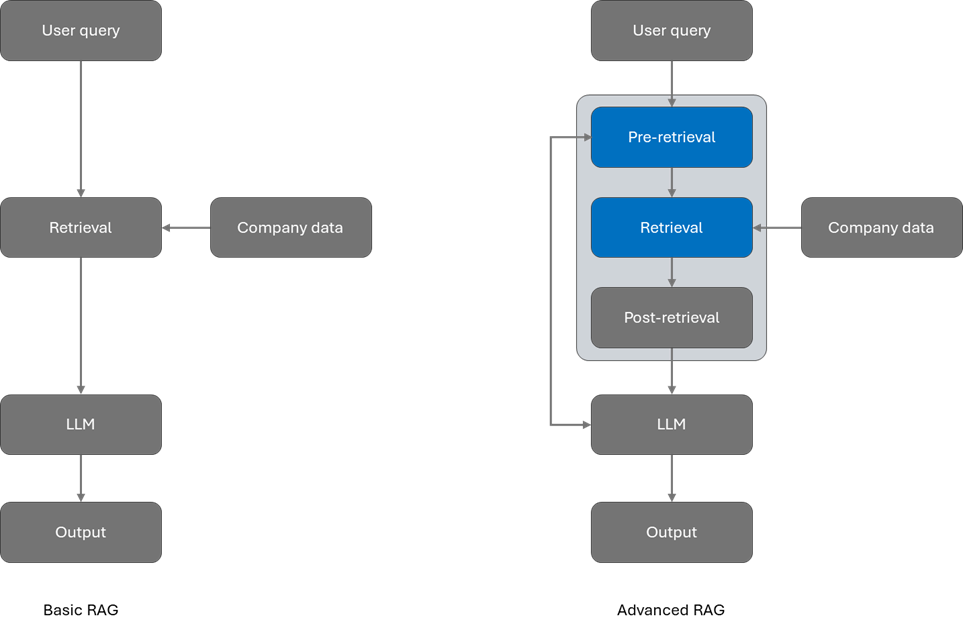
在 RAG 中,您可以评估和修改各个阶段以改进结果,它们分为三类:预检索、检索和检索后。
- 预检索可提高使用查询重写等技术检索的数据的质量。
- 检索使用混合搜索和语义排序等高级技术改进结果。
- 检索后侧重于优化检索信息和增强提示。
LlamaIndex 为初学者和有经验的开发人员提供了一个全面的框架和生态系统,以在其数据源上构建 LLM 应用程序。
Azure AI Search是一个信息检索平台,具有尖端的搜索技术和无缝的平台集成,专为任何规模的高性能生成式 AI 应用程序而构建。
我们在预检索中使用LlamaIndex 进行查询转换,并使用 Azure AI 搜索进行高级检索,可以生成构建更好的RAG应用程序。
预检索技术和优化查询编排
为了优化预检索,LlamaIndex 提供了查询转换,这是一项优化用户输入的强大功能。一些查询转换技术包括:
- 路由:保持查询不变,但标识查询应用到的相关工具子集。将这些工具输出为相关选项。
- 查询重写:保持工具不变,但以各种不同的方式重写查询,以针对相同的工具执行。
- 子问题:将查询分解为不同工具上的多个子问题,由其元数据标识。
- ReAct 代理工具选取:给定初始查询,确定 (1) 要选取的工具,以及 (2) 要在工具上执行的查询。
以查询重写为例:查询重写使用 LLM 将初始查询重新表述为多种形式。这使开发人员能够探索数据的不同方面,从而产生更细致和准确的响应。通过重写查询,开发人员可以生成多个查询,用于集成检索和融合检索,从而获得更高质量的检索结果。利用 Azure OpenAI,可以将初始查询分解为多个子查询。
请考虑以下初始查询:
“作者怎么了?”
如果问题过于宽泛,或者似乎不太可能在我们的语料库文本中找到直接的比较,建议将问题分解为多个子查询。
子查询:
- “作者最近写的一本书是什么?”
- “作者获得过什么文学奖吗?”
- “有没有即将举行的活动或对作者的采访?”
- “作者的背景和写作风格是什么?”
- “围绕作者有什么争议或丑闻吗?”
子问题查询引擎
LlamaIndex 的一大优点是,像这样的高级检索策略是内置在框架中的。例如,可以使用子问题查询引擎在一个步骤中处理上述子查询,该引擎将问题分解为更简单的问题,然后将答案组合成一个响应。
response = query_engine.query("What happened to the author?")
使用 Azure AI 搜索进行检索
为了增强检索功能,Azure AI 搜索提供混合搜索和语义排名。混合搜索同时执行关键字和向量检索,并应用融合步骤(倒数秩融合 (RRF))从每种技术中选择最佳结果。
语义排名器在初始 BM25 排名或 RRF 排名结果上添加辅助排名。该二级排名使用多语言深度学习模型来推广语义上最相关的结果。
通过将“query_type”参数更新为“semantic”,可以很容易地启用语义排名器。由于语义排名是在 Azure AI 搜索堆栈中完成的,因此我们的数据显示,语义排名器与混合搜索相结合是提高相关性的最有效方法。
此外,Azure AI 搜索还支持矢量查询中的筛选器。您可以设置筛选器模式,以便在矢量查询执行之前或之后应用筛选器:
- 预筛选模式:在查询执行前应用筛选,减少向量搜索算法查找相似内容的搜索表面积。预滤波通常比后滤波慢,但有利于召回率和精确度。
- 筛选后模式:在查询执行后应用筛选器,缩小搜索结果范围。后过滤比选择更注重速度。
总结
通过与 LlamaIndex 的协作,可以提供更简单的方法来优化预检索和检索,以实现高级 RAG应用。
这篇关于使用Azure AI Search和LlamaIndex构建高级RAG应用的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




