iceberg专题

数据湖解决方案关键一环,IceBerg会不会脱颖而出?
点击上方蓝色字体,选择“设为星标” 回复”资源“获取更多资源 小编在之前的详细讲解过关于数据湖的发展历程和现状,《我看好数据湖的未来,但不看好数据湖的现在》 ,在最后一部分中提到了当前数据湖的解决方案中,目前跳的最凶的三巨头包括:Delta、Apache Iceberg 和 Apache Hudi。 本文中将详细的介绍一下其中的IceBerg,看一下IceBerg会不会最终脱颖而出。 发展历

揭秘Iceberg:数据湖新版本的高级特性全面解析
目录 1前言 2 特性说明 2.1 Branch and Tag 2.2 Puffin format 2.3 Statistics 2.4View 创建物化视图 查询物化视图 3应用案例 3.1 CDC数据入湖 3.2 多流数据拼接 3.3 异步索引和Z-order聚簇优化 3.4 A/B测试 3.5 多租户访问控制 1 前言 以下的讨论都基于iceberg1

使用 Iceberg、Tabular 和 MinIO 构建现代数据架构
现代数据环境需要一种新型的基础架构,即无缝集成结构化和非结构化数据、轻松扩展并支持高效的 AI/ML 工作负载的基础架构。这就是现代数据湖的用武之地,它为您的所有数据需求提供了一个中心枢纽。然而,构建和管理有效的数据湖可能很复杂。 这篇博文深入探讨了三个强大的工具,它们可以优化您当前的方法:Apache Iceberg、Tabular 和 MinIO。以下步骤将引导您了解这些服务如何无缝组合,

iceberg gradle项目转maven
iceberg gradle项目转maven 通过versions.props集中进行版本管理 iceberg github上源码是用gradle做依赖管理的,下面记录踩的一些坑: 通过versions.props集中进行版本管理 其各dependency的version是集中在versions.props文件中进行管理的,在build.gradle通过dependencyRe

分钟级延迟kafka和iceberg+hdfs方案成本对比
基于kafka的实时数仓可以达到秒级别延迟(多层,如果是单层可达到ms级别延迟),但是kafka的成本太高,如果要做到近实时的数仓,可用iceberg+hdfs替代kafka。 以上这段是很多公司用iceberg替换kafka的原因,通过下面两个问题问清楚成本高在哪 Q1:存放同样大小1pb的数据,kafka成本为什么比hdfs高? A1:kafka是按消息队列设计的,为了满足

Flink + Iceberg 如何解决数据入湖面临的挑战
本文来自4月17日 Apache Flink x Iceberg Meetup 上海站胡争老师的分享,文末有视频回顾和PPT资源下载~ 欢迎关注公众号,一起探讨交流! 【PPT下载】 https://files.alicdn.com/tpsservice/b201e20d578e1f3c7d
数据湖Iceberg | 实时数据仓库的发展、架构和趋势
数据处理现状:当前基于Hive的离线数据仓库已经非常成熟,数据中台体系也基本上是围绕离线数仓进行建设。但是随着实时计算引擎的不断发展以及业务对于实时报表的产出需求不断膨胀,业界最近几年就一直聚焦并探索于两个相关的热点问题:实时数仓建设和大数据架构的批流一体建设。 1 实时数仓建设:实时数仓1.0 传统意义上我们通常将数据处理分为离线数据处理和实时数据处理。对于实时处理场景,我们一般又可以分为两类

数据湖 CDC 数据实时读写方案及 Iceberg 原理
摘要:本文由李劲松、胡争分享,社区志愿者杨伟海、李培殿整理。主要介绍在数据湖的架构中,CDC 数据实时读写的方案和原理。文章主要分为 4 个部分内容: 常见的 CDC 分析方案为何选择 Flink + Iceberg如何实时写入读取未来规划 Tips:点击文末「阅读原文」即可回顾作者原版分享视频~ 一、常见的 CDC 分析方案 我们先看一下今天的 topic 需要设计的是什么?输入是一个 CDC

【kyuubi-spark】从0-1部署kyuubi集成spark执行spark sql到k8s读取iceberg的minio数据
一、背景 团队在升级大数据架构 前端使用trino查询,对trino也进行了很多优化,目前测试来看,运行还算稳定,但是不可避免的trino的任务总会出现失败的情况。原来的架构是trino失败后去跑hive,而hive是跑mapreduce依赖于hadoop,新架构摒弃了hadoop,当然也没法用hive跑了,因此目前看较好的办法是使用spark sql来替代。 在初次研究了spark sql

如何通过 AWS Managed Apache Flink 实现 Iceberg 的实时同步
AWS Managed Apache Flink (以下以 MAF 代指)是 AWS 提供的一款 Serverless 的 Flink 服务。 1. 问题 大家在使用 MAF 的时候,可能遇到最大的一个问题就是 MAF 的依赖管理,很多时候在 Flink 上运行的代码,托管到 MAF 上之后发现有很多依赖问题需要解决,大体上感觉就是 MAF 一定需要一个纯洁的环境,纯洁的 Flink 代码包。
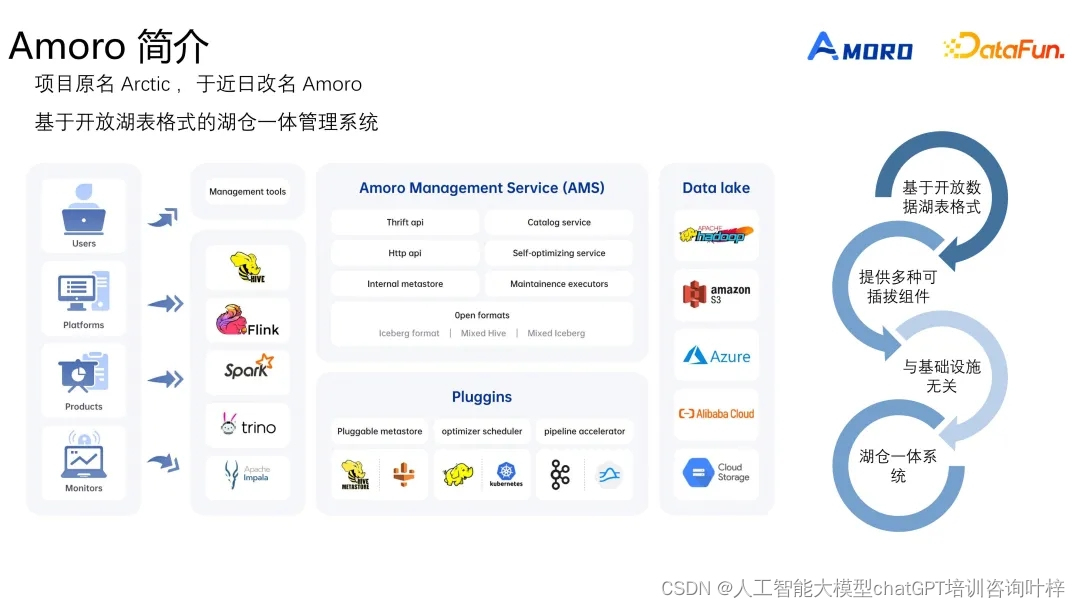
构建云原生湖仓:Apache Iceberg与Amoro的结合实践
随着大数据技术的快速发展,企业对数据的处理和分析需求日益增长。传统的数据仓库已逐渐无法满足现代业务对数据多样性和实时性的要求,这促使了数据湖和数据仓库的融合,即湖仓一体架构的诞生。在云原生技术的推动下,构建云原生湖仓成为企业提升数据处理能力的重要途径。本文将探讨如何利用Apache Iceberg和Amoro在云原生环境下构建高效的湖仓一体解决方案。 Apache Iceberg与云原生 Ap
第1章 Iceberg简介
1.1 概述 Iceberg是一个面向大型分析数据集的开放表格格式。它为多种计算引擎,如Spark、Trino、PrestoDB、Flink、Hive和Impala,增加了表格功能,使用一种高性能的表格格式,其工作方式就像一个SQL表一样。 在生产环境中,Iceberg被用于管理单个表格,这些表格可包含数十PB(千兆字节)的数据,即使是这样巨大的表格也能在没有分布式SQL引擎的情况下读取。
[数据湖iceberg]-hive集成数据湖读取数据的正确姿势
1 概述 Iceberg作为一种表格式管理规范,其数据分为元数据和表数据。元数据和表数据独立存储,元数据目前支持存储在本地文件系统、HMS、Hadoop、JDBC数据库、AWS Glue和自定义存储。表数据支持本地文件系统、HDFS、S3、MinIO、OBS、OSS等。元数据存储基于HMS比较广泛,在这篇文章中,表数据存储基于MinIO、元数据存储主要基于HMS。实际上,基于HMS存储的元数据也
Seatunnel系列之:Apache Iceberg sink connector和往Iceberg同步数据任务示例
Seatunnel系列之:Apache Iceberg sink connector和往Iceberg同步数据任务示例 一、支持的Iceberg版本二、支持的引擎三、描述四、支持的数据源信息五、数据库依赖六、数据类型映射七、Sink选项八、往Iceberg同步数据任务示例 一、支持的Iceberg版本 1.4.2 二、支持的引擎 SparkFlinkSeaTunnel Ze

HashData的湖仓一体思考:Iceberg、Hudi特性讲解与支持方案
湖仓一体作为一种新兴的开放式数据管理架构,能够充分发挥数据湖的灵活性、生态丰富以及数据仓库的企业级数据分析能力,已经成为企业建设现代数据平台的热门选择。 在此前的直播中,我们分享了HashData湖仓一体方案架构设计与Hive数据同步。本次直播,我们介绍了Iceberg、Hudi的特性与支持方案,并对HashData连接组件的原理和实现流程进行了详细的讲解和演示。以下内容根据直播文字整理。 H
Iceberg Changelog
01 Iceberg Changelog使用 0101 Flink使用 CREATE CATALOG hive_catalog WITH ('type'='iceberg','catalog-type'='hive','uri'='thrift://xxxx:19083','clientimecol'='5','property-version'='1','warehouse'='hdfs:/
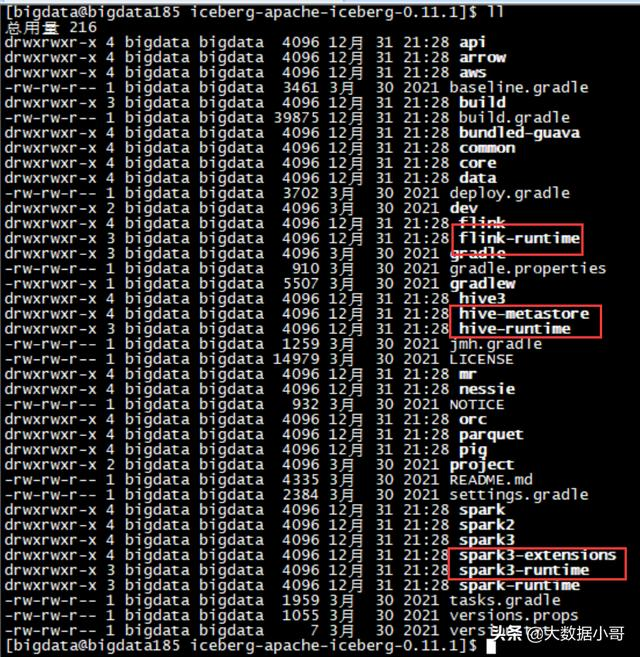
【大数据】Apache Iceberg 概述和源代码的构建
Apache Iceberg 概述和源代码的构建 1.数据湖的解决方案 - Iceberg1.1 Iceberg 是什么1.2 Iceberg 的 Table Format 介绍1.3 Iceberg 的核心思想1.4 Iceberg 的元数据管理1.5 Iceberg 的重要特性1.5.1 丰富的计算引擎1.5.2 灵活的文件组织形式1.5.3 优化数据入湖流程1.5.4 增量读取处理

Iceberg小文件合并
1.用法–Flink Iceberg提供了Actions来进行小文件合并,需要手动调用执行 import org.apache.iceberg.flink.actions.Actions;TableLoader tableLoader = TableLoader.fromHadoopTable("hdfs://nn:8020/warehouse/path");Table table =
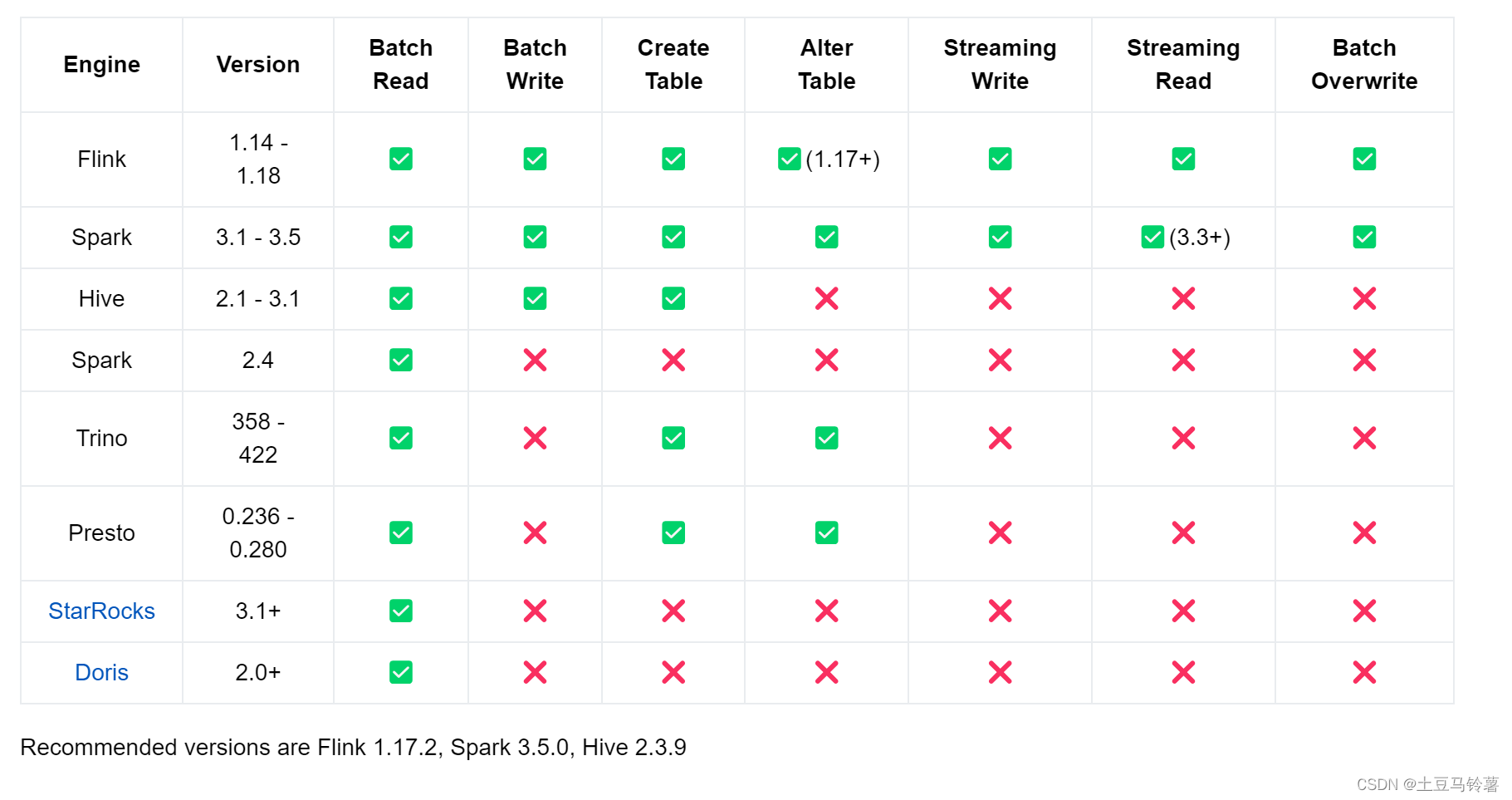
数据湖Iceberg、Hudi和Paimon比较
1.社区发展现状 项目Apache IcebergApache HudiApache Paimon开源时间2018/11/62019/1/172023/3/12LicenseApache-2.0Apache-2.0Apache-2.0Github Watch1481.2k70Github Star5.3k4.9k 1.7k Github Fork1.9k2.3k702Github issue(O

Apache Iceberg 在网易云音乐的实践
1 iceberg 详细设计 Apache iceberg 是Netflix开源的全新的存储格式,我们已经有了parquet、orc、arvo等非常优秀的存储格式以后,Netfix为什么还要设计出iceberg呢?和parquet、orc等文件格式不同, iceberg在业界被称之为Table Foramt,parquet、orc、avro等文件等格式帮助我们高效的修改、读取单个文件;同样Tab
火山引擎 Iceberg 数据湖的应用与实践
在云原生计算时代,云存储使得海量数据能以低成本进行存储,但是这也给如何访问、管理和使用这些云上的数据提出了挑战。而 Iceberg 作为一种云原生的表格式,可以很好地应对这些挑战。本文将介绍火山引擎在云原生计算产品上使用 Iceberg 的实践,和大家分享高效查询、存储和治理 Iceberg 数据的方法。 Why Iceberg Iceberg 是一种适用于 HDFS 或者对象存
【Iceberg学习四】Evolution和Maintenance在Iceberg的实现
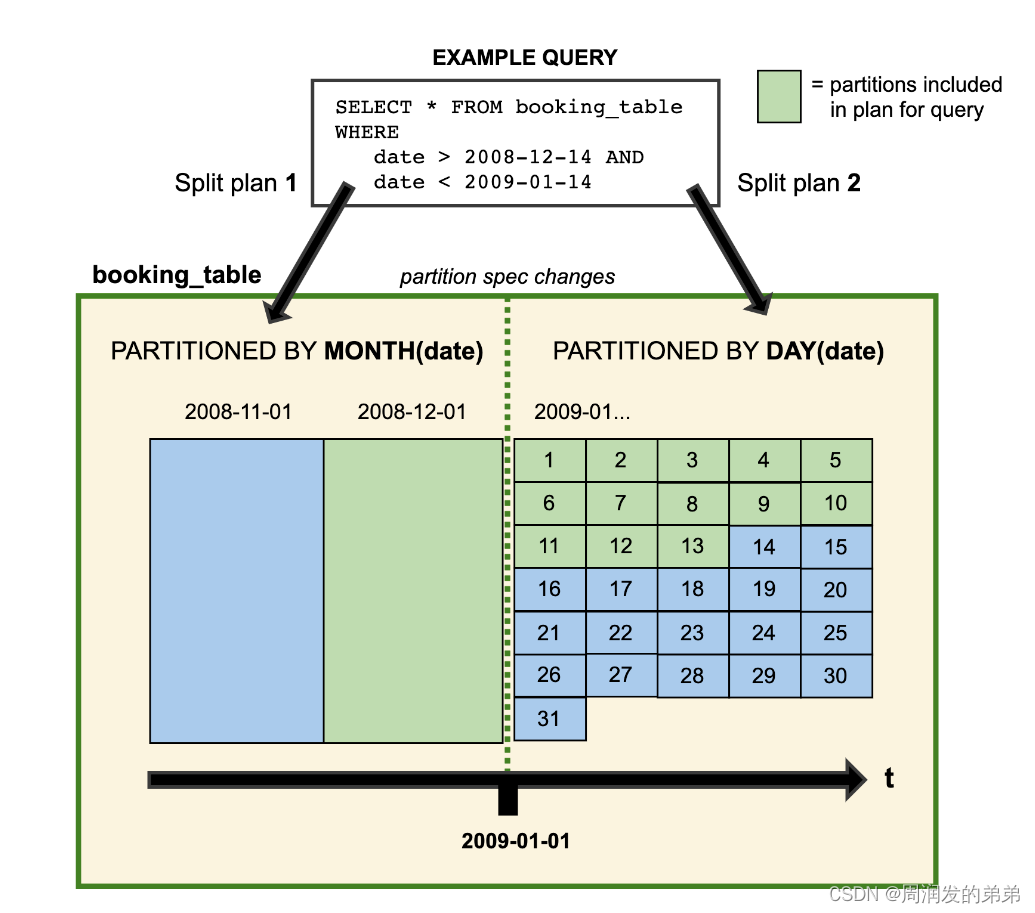
Evolution Iceberg 支持就底表演化。您可以像 SQL 一样演化表结构——即使是嵌套结构——或者当数据量变化时改变分区布局。Iceberg 不需要像重写表数据或迁移到新表这样耗费资源的操作。 例如,Hive 表的分区布局无法更改,因此从每日分区布局变更到每小时分区布局需要新建一个表。而且因为查询依赖于分区,所以必须为新表重写查询。在某些情况下,即使是像重命名一个列这样简单的变化要
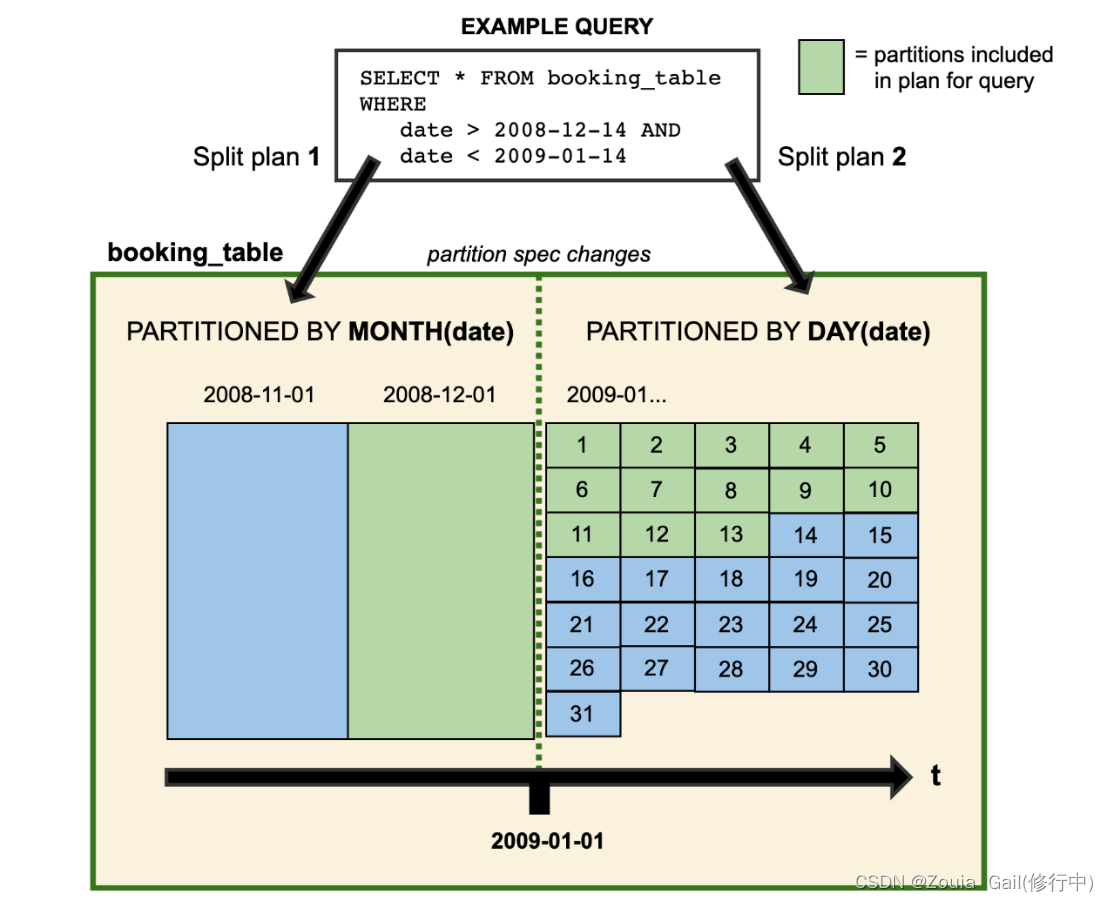
【Iceberg学习三】Reporting和Partitioning原理
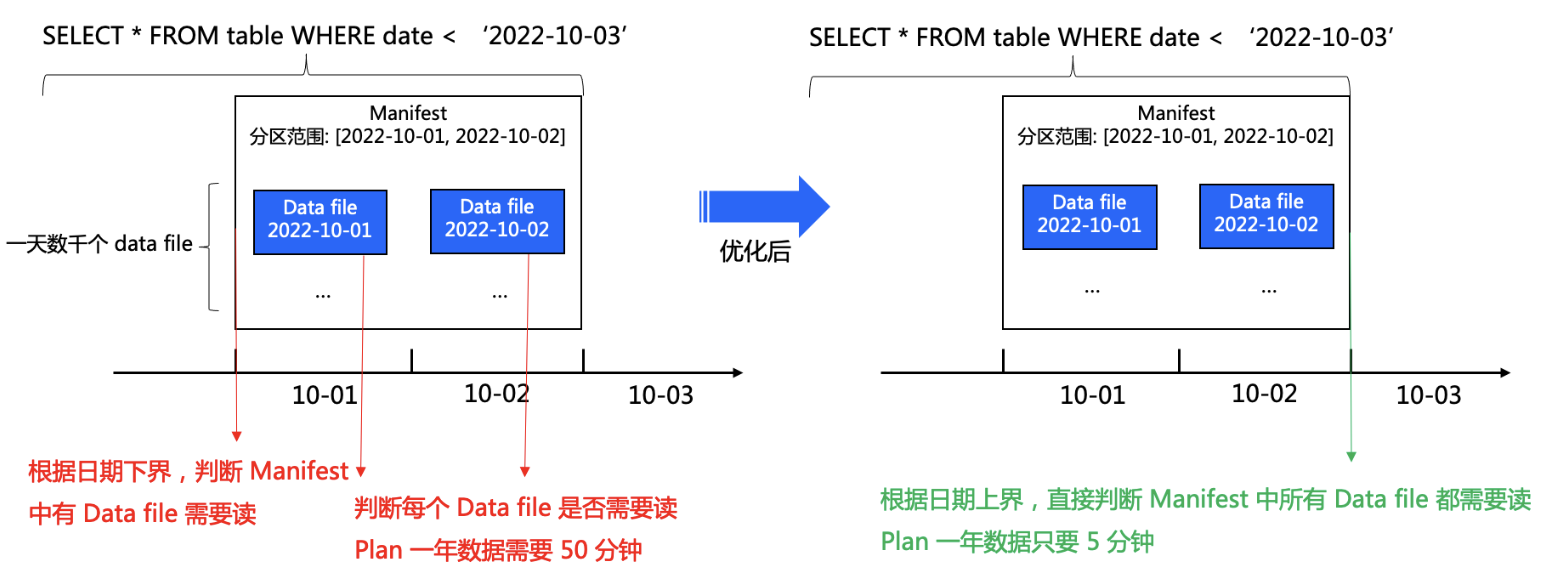
Metrics Reporting Type of Reports 从 1.1.0 版本开始,Iceberg 支持 MetricsReporter 和 MetricsReport API。这两个 API 允许表达不同的度量报告,并支持一种可插拔的方式来报告这些报告。 ScanReport(扫描报告) 扫描报告(ScanReport)记录了在对一个给定表进行扫描规划时收集的度量指标。除了包含
【Iceberg学习二】Branch和Tag在Iceberg中的应用
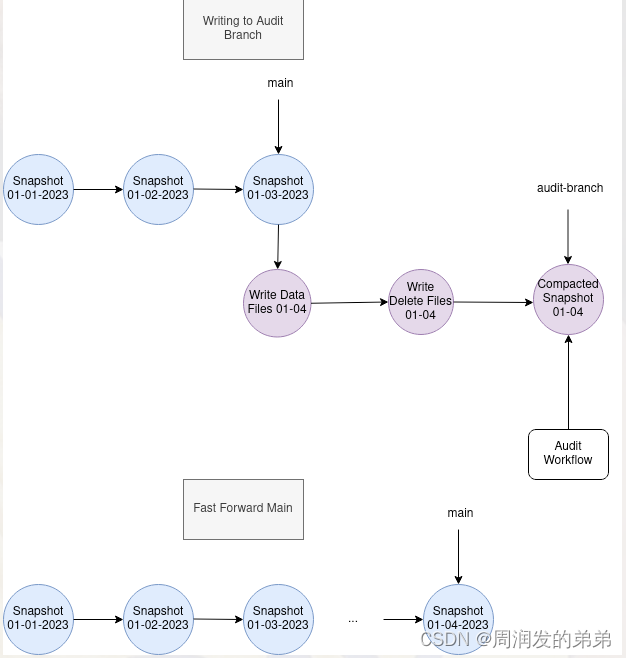
Iceberg 表元数据保持一个快照日志,记录了对表所做的更改。快照在 Iceberg 中至关重要,因为它们是读者隔离和时间旅行查询的基础。为了控制元数据大小和存储成本,Iceberg 提供了快照生命周期管理程序,如 expire_snapshots,用于删除基于表快照保留属性不再需要的快照和数据文件。 为了更精细的快照生命周期管理,Iceberg 支持分支和标签,这些是具有独立生命周期的快照的

Iceberg从入门到精通系列之二十三:Spark查询
Iceberg从入门到精通系列之二十三:Spark查询 一、使用 SQL 查询二、使用 DataFrame 进行查询三、Time travel四.Incremental read五、检查表六、History七、元数据日志条目八、Snapshots九、Files十、Manifests十一、Partitions十二、所有元数据表十三、参考十四、使用元数据表进行时间旅行 要在 Spark
Apache Doris 整合 FLINK CDC + Iceberg 构建实时湖仓一体的联邦查询
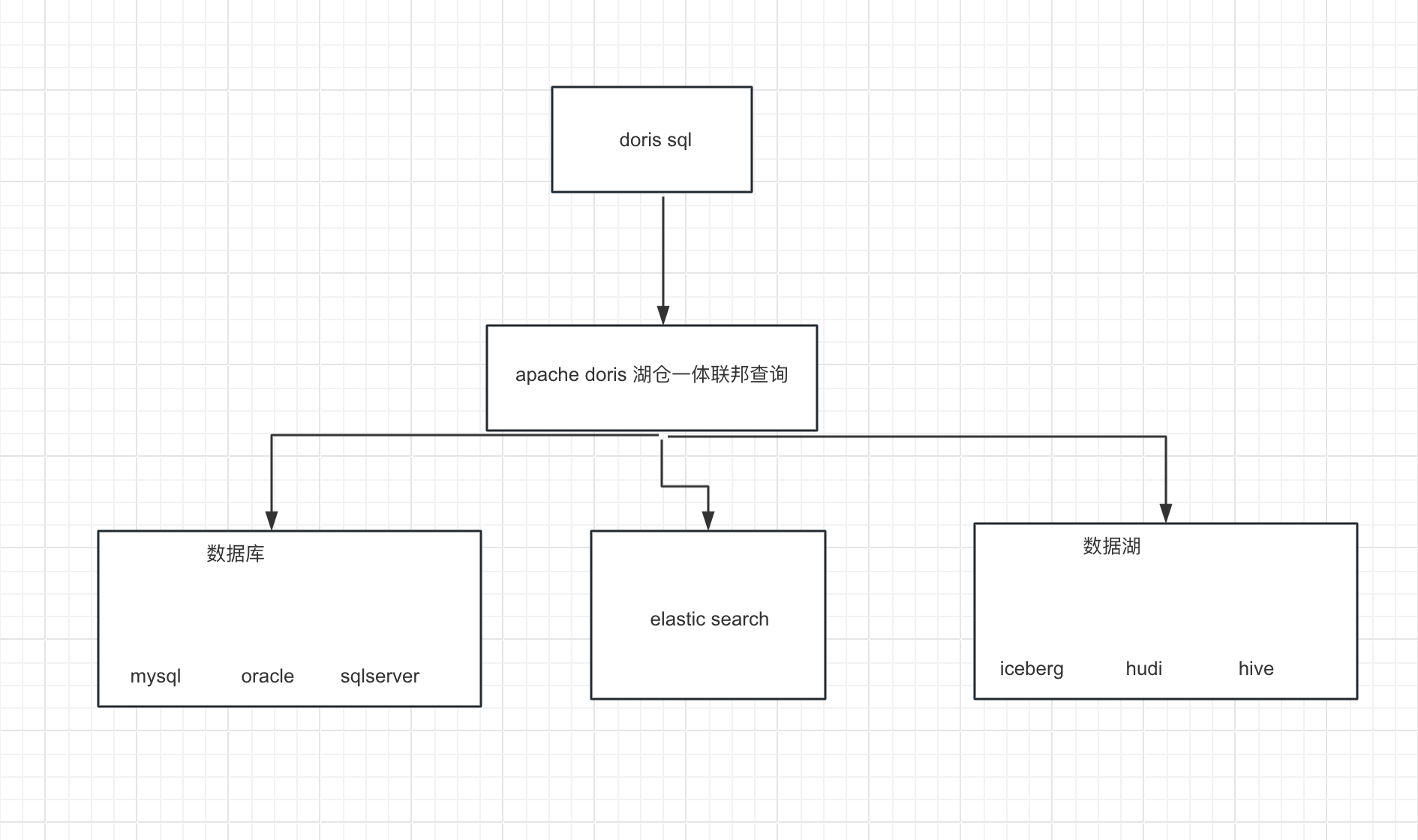
1概况 本文展示如何使用 Flink CDC + Iceberg + Doris 构建实时湖仓一体的联邦查询分析,Doris 1.1版本提供了Iceberg的支持,本文主要展示Doris和Iceberg怎么使用,大家按照步骤可以一步步完成。完整体验整个搭建操作的过程。 2系统架构 我们整理架构图如下, 1.首先我们从Mysql数据中使用Flink 通过 Binlog完成数据的实时采集