本文主要是介绍Iceberg从入门到精通系列之二十三:Spark查询,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Iceberg从入门到精通系列之二十三:Spark查询
- 一、使用 SQL 查询
- 二、使用 DataFrame 进行查询
- 三、Time travel
- 四.Incremental read
- 五、检查表
- 六、History
- 七、元数据日志条目
- 八、Snapshots
- 九、Files
- 十、Manifests
- 十一、Partitions
- 十二、所有元数据表
- 十三、参考
- 十四、使用元数据表进行时间旅行
要在 Spark 中使用 Iceberg,请首先配置 Spark 目录。 Iceberg 使用 Apache Spark 的 DataSourceV2 API 来实现数据源和目录。
一、使用 SQL 查询
在 Spark 3 中,表使用包含目录名称的标识符。
SELECT * FROM prod.db.table; -- catalog: prod, namespace: db, table: table
元数据表(例如历史记录和快照)可以使用 Iceberg 表名称作为命名空间。
例如,要从文件元数据表中读取 prod.db.table:
SELECT * FROM prod.db.table.files;
二、使用 DataFrame 进行查询
使用DataFrame进行查询
val df = spark.table("prod.db.table")
使用 DataFrameReader 的目录
路径和表名可以使用 Spark 的 DataFrameReader 接口加载。如何加载表取决于如何指定标识符。当使用spark.read.format(“iceberg”).load(table)或spark.table(table)时,表变量可以采用多种形式,如下所示:
- file:///path/to/table:在给定路径加载 HadoopTable
- tablename:加载currentCatalog.currentNamespace.tablename
- Catalog.tablename:从指定目录加载表名。
- namespace.tablename:从当前目录加载namespace.tablename
- Catalog.namespace.tablename:从指定目录加载namespace.tablename。
- namespace1.namespace2.tablename:从当前目录加载namespace1.namespace2.tablename
上面的列表是按优先顺序排列的。例如:匹配的目录将优先于任何名称空间解析。
三、Time travel
1.SQL
Spark 3.3 及更高版本支持使用 TIMESTAMP AS OF 或 VERSION AS OF 子句在 SQL 查询中进行时间旅行。 VERSION AS OF 子句可以包含长快照 ID 或字符串分支或标记名称。
注意:如果分支或标签的名称与快照 ID 相同,则选择进行时间旅行的快照是具有给定快照 ID 的快照。例如,考虑这样的情况:有一个名为“1”的标签,它引用 ID 为 2 的快照。如果版本旅行子句是 VERSION AS OF“1”,则将对 ID 为 1 的快照进行时间旅行。如果如果不需要,请使用明确定义的前缀(例如“snapshot-1”)重命名标记或分支。
-- time travel to October 26, 1986 at 01:21:00
SELECT * FROM prod.db.table TIMESTAMP AS OF '1986-10-26 01:21:00';-- time travel to snapshot with id 10963874102873L
SELECT * FROM prod.db.table VERSION AS OF 10963874102873;-- time travel to the head snapshot of audit-branch
SELECT * FROM prod.db.table VERSION AS OF 'audit-branch';-- time travel to the snapshot referenced by the tag historical-snapshot
SELECT * FROM prod.db.table VERSION AS OF 'historical-snapshot';
此外,还支持 FOR SYSTEM_TIME AS OF 和 FOR SYSTEM_VERSION AS OF 子句:
SELECT * FROM prod.db.table FOR SYSTEM_TIME AS OF '1986-10-26 01:21:00';
SELECT * FROM prod.db.table FOR SYSTEM_VERSION AS OF 10963874102873;
SELECT * FROM prod.db.table FOR SYSTEM_VERSION AS OF 'audit-branch';
SELECT * FROM prod.db.table FOR SYSTEM_VERSION AS OF 'historical-snapshot';
时间戳也可以作为 Unix 时间戳提供,以秒为单位:
-- timestamp in seconds
SELECT * FROM prod.db.table TIMESTAMP AS OF 499162860;
SELECT * FROM prod.db.table FOR SYSTEM_TIME AS OF 499162860;
2.DataFrame
要在 DataFrame API 中选择特定表快照或某个时间的快照,Iceberg 支持四种 Spark 读取选项:
- snapshot-id 选择特定的表快照
- as-of-timestamp 选择时间戳处的当前快照(以毫秒为单位)
- 分支选择指定分支的头快照。请注意,当前分支不能与 as-of 时间戳组合。
- tag 选择与指定标签关联的快照。标签不能与当前时间戳组合。
// time travel to October 26, 1986 at 01:21:00
spark.read.option("as-of-timestamp", "499162860000").format("iceberg").load("path/to/table")
// time travel to snapshot with ID 10963874102873L
spark.read.option("snapshot-id", 10963874102873L).format("iceberg").load("path/to/table")
// time travel to tag historical-snapshot
spark.read.option(SparkReadOptions.TAG, "historical-snapshot").format("iceberg").load("path/to/table")
// time travel to the head snapshot of audit-branch
spark.read.option(SparkReadOptions.BRANCH, "audit-branch").format("iceberg").load("path/to/table")
Spark 3.0及更早版本不支持在DataFrameReader命令中使用带表的选项。所有选项都将被默默忽略。尝试时间旅行或使用其他选项时请勿使用表格。请参阅 SPARK-32592。
四.Incremental read
要增量读取附加数据,请使用:
- start-snapshot-id 增量扫描中使用的启动快照 ID(独占)。
- end-snapshot-id 增量扫描(含)中使用的结束快照 ID。这是可选的。省略它将默认为当前快照。
// get the data added after start-snapshot-id (10963874102873L) until end-snapshot-id (63874143573109L)
spark.read().format("iceberg").option("start-snapshot-id", "10963874102873").option("end-snapshot-id", "63874143573109").load("path/to/table")目前仅获取追加操作的数据。不支持替换、覆盖、删除操作。增量读取适用于 V1 和 V2 格式版本。 Spark的SQL语法不支持增量读取。
五、检查表
要检查表的历史记录、快照和其他元数据,Iceberg 支持元数据表。
元数据表通过在原表名后添加元数据表名来标识。例如,使用 db.table.history 读取 db.table 的历史记录。
对于 Spark 3(3.2 之前的版本),Spark 会话目录不支持具有多部分标识符的表名称,例如 Catalog.database.table.metadata。作为解决方法,请配置 org.apache.iceberg.spark.SparkCatalog,或使用 Spark DataFrameReader API。
六、History
显示表历史记录:
SELECT * FROM prod.db.table.history;

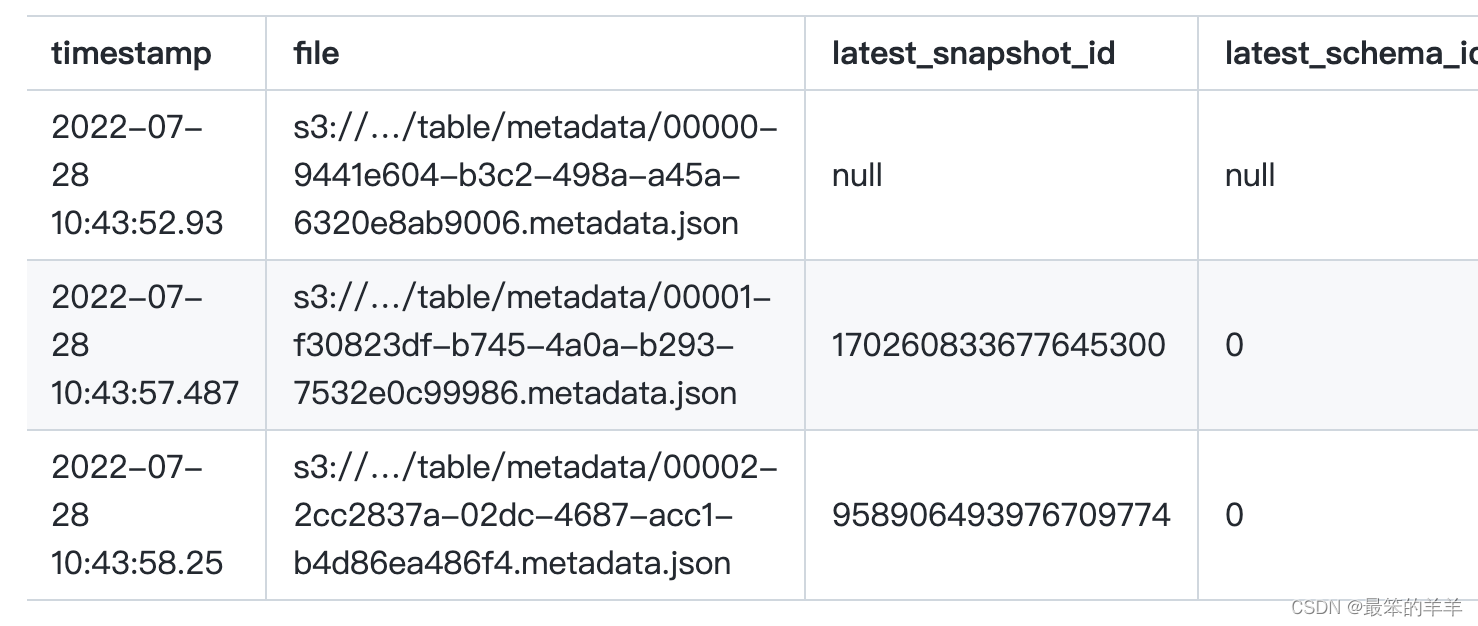
七、元数据日志条目
显示表元数据日志条目:
SELECT * from prod.db.table.metadata_log_entries;
八、Snapshots
显示表的有效快照:
SELECT * FROM prod.db.table.snapshots;

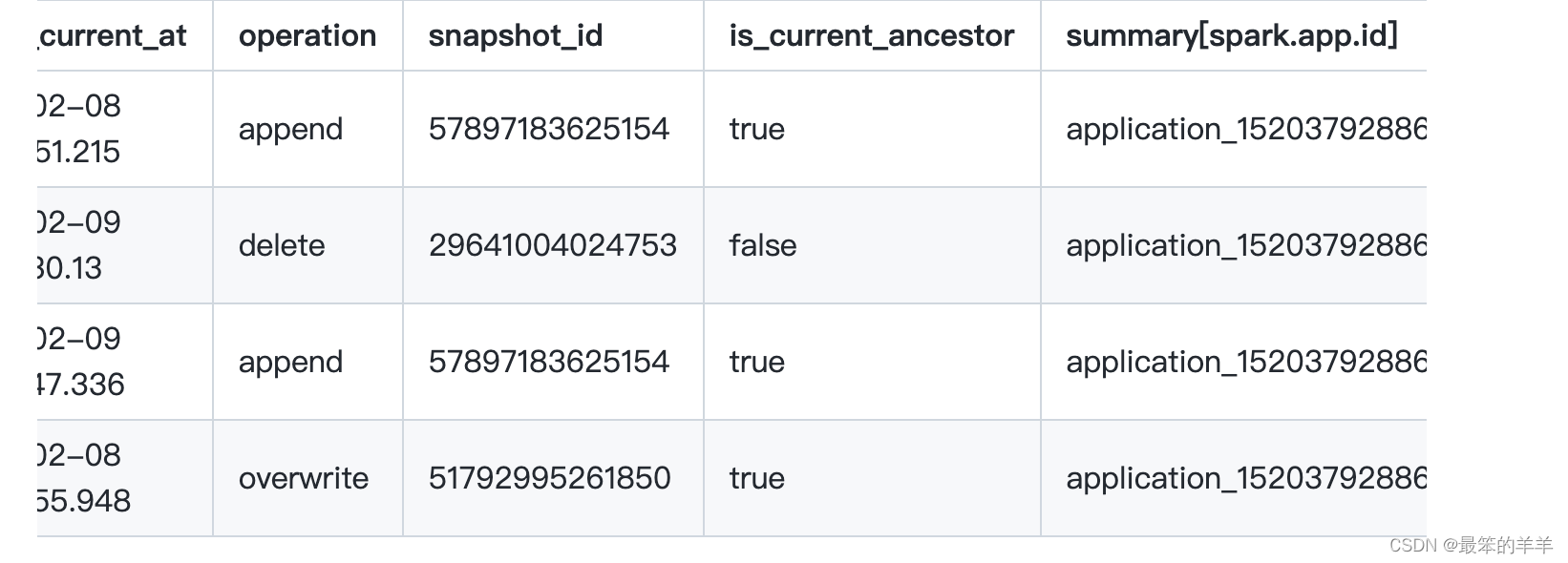
您还可以将快照加入表历史记录中。例如,此查询将显示表历史记录,以及写入每个快照的应用程序 ID:
selecth.made_current_at,s.operation,h.snapshot_id,h.is_current_ancestor,s.summary['spark.app.id']
from prod.db.table.history h
join prod.db.table.snapshots son h.snapshot_id = s.snapshot_id
order by made_current_at
九、Files
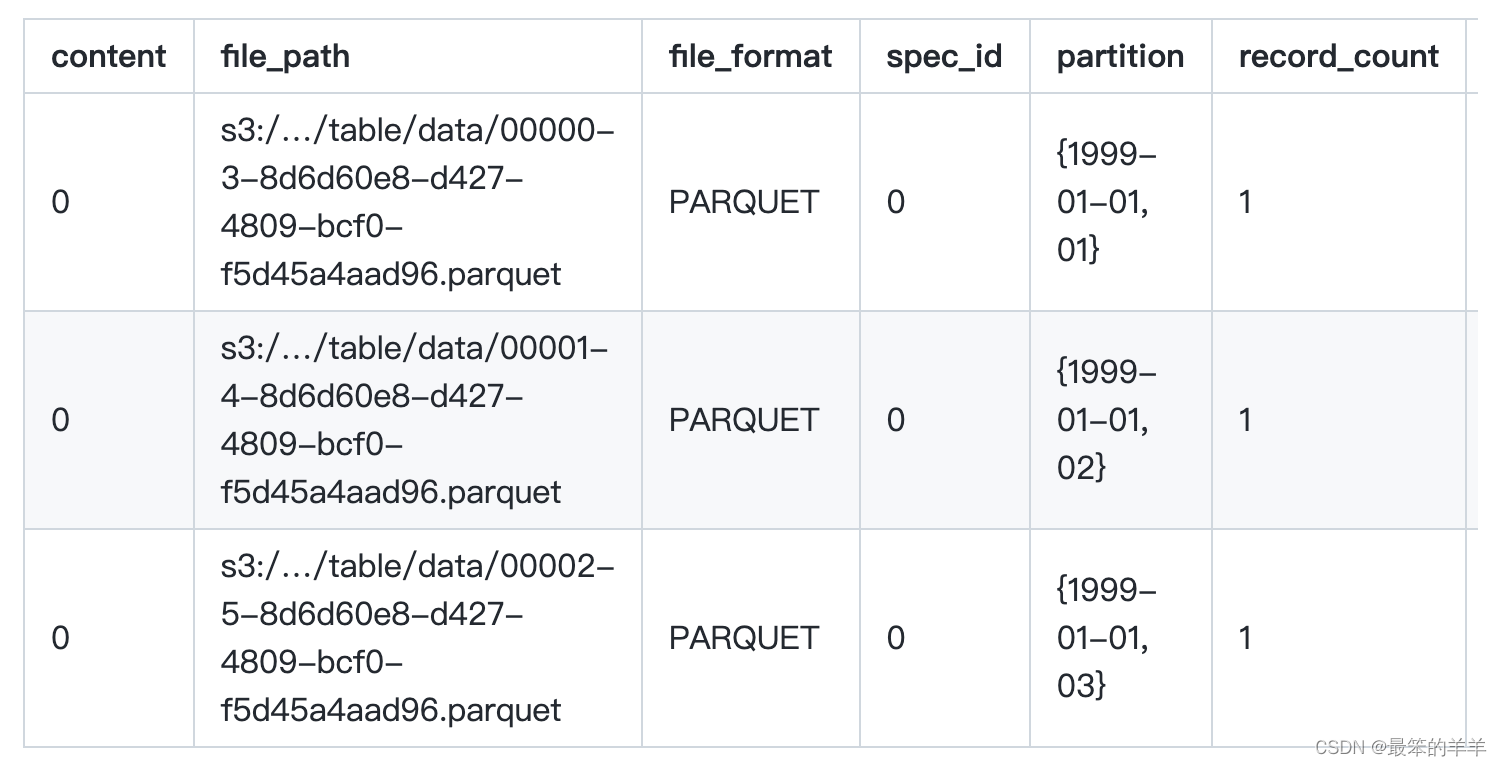
显示表的当前文件:
SELECT * FROM prod.db.table.files;
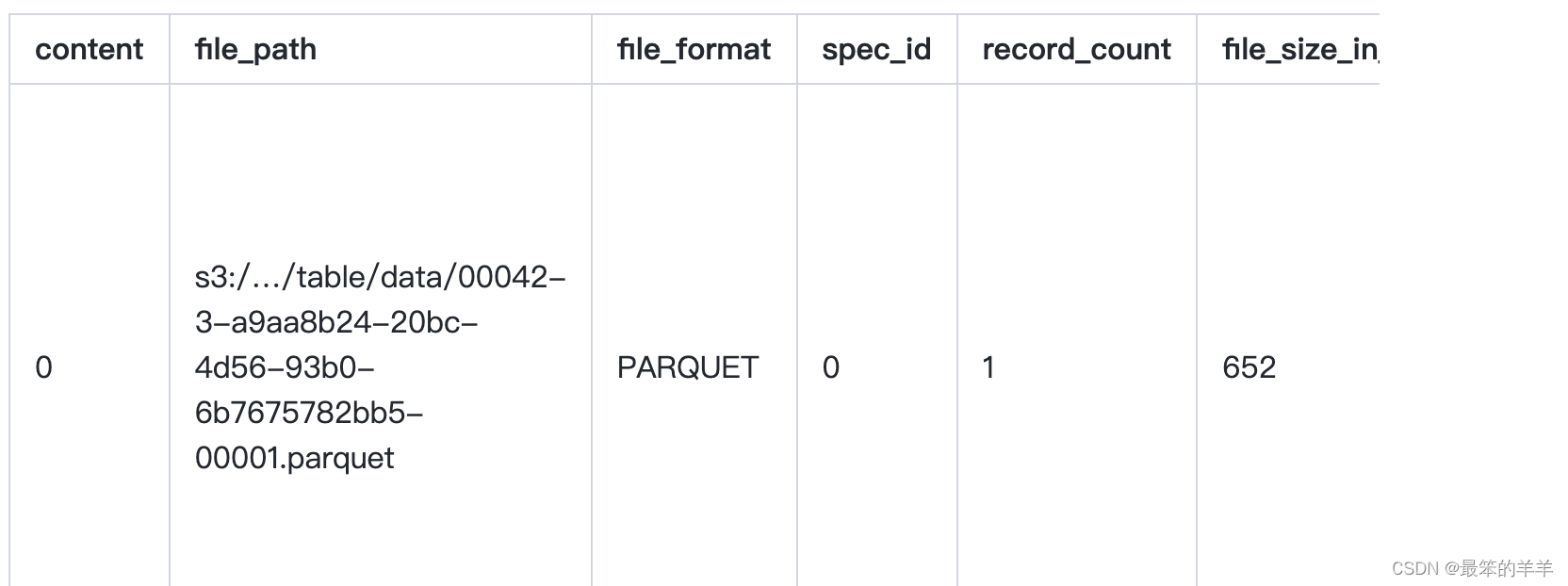
内容是指数据文件存储的内容类型: 0 数据 1 位置删除 2 相等删除
要仅显示数据文件或删除文件,请分别查询 prod.db.table.data_files 和 prod.db.table.delete_files。要显示所有跟踪快照中的所有文件、数据文件和删除文件,请分别查询 prod.db.table.all_files、prod.db.table.all_data_files 和 prod.db.table.all_delete_files。
十、Manifests
要显示表的当前文件清单:
SELECT * FROM prod.db.table.manifests;

- 清单表的partition_summaries列中的字段对应于清单列表中的field_summary结构,顺序如下:
- 包含空值
- 包含_nan
- 下界
- 上限
- contains_nan 可能返回 null,这表明该信息无法从文件的元数据中获得。当从 V1 表读取时,通常会发生这种情况,其中 contains_nan 未填充。
十一、Partitions
显示表的当前分区:
SELECT * FROM prod.db.table.partitions;
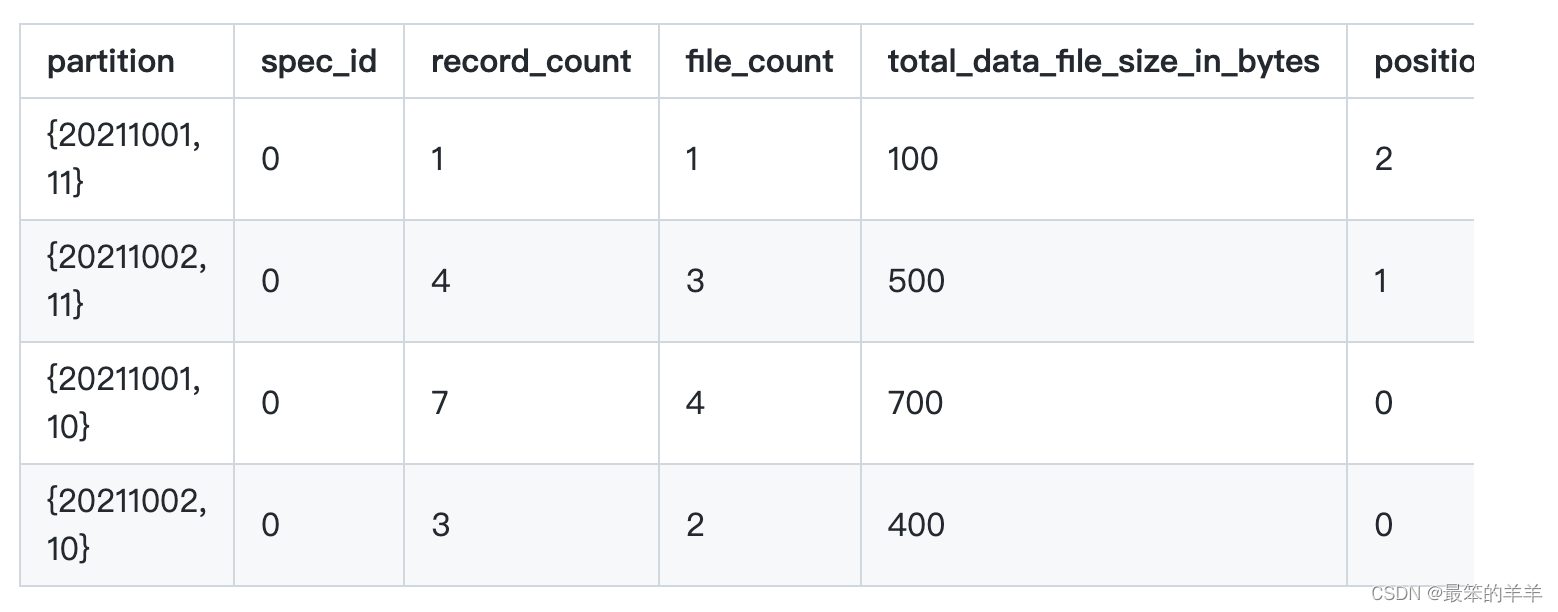
对于未分区表,分区表将不包含分区和spec_id字段。
分区元数据表显示当前快照中包含数据文件或删除文件的分区。但是,不应用删除文件,因此在某些情况下,即使分区的所有数据行都被删除文件标记为已删除,也可能会显示分区。
十二、所有元数据表
这些表是特定于当前快照的元数据表的并集,并返回所有快照的元数据。
“所有”元数据表可能会为每个数据文件或清单文件生成多于一行,因为元数据文件可能是多个表快照的一部分。
所有数据文件
要显示表的所有数据文件和每个文件的元数据:
SELECT * FROM prod.db.table.all_data_files;
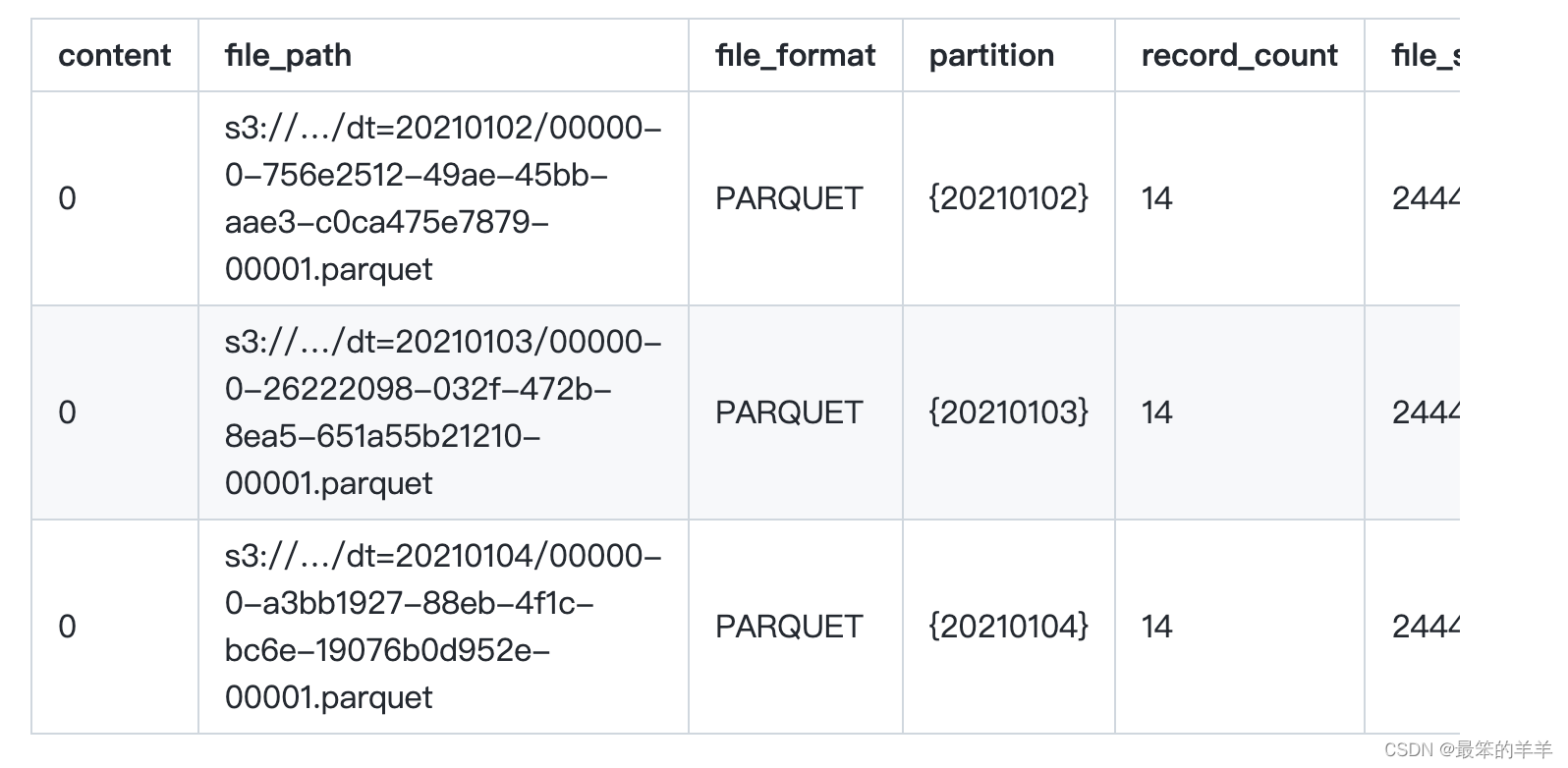
All Manifests
要显示表的所有清单文件:
SELECT * FROM prod.db.table.all_manifests;

清单表的partition_summaries列中的字段对应于清单列表中的field_summary结构,顺序如下:
- 包含空值
- 包含_nan
- 下界
- 上限
contains_nan 可能返回 null,这表明该信息无法从文件的元数据中获得。当从 V1 表读取时,通常会发生这种情况,其中 contains_nan 未填充。
十三、参考
要显示表的已知快照引用:
SELECT * FROM prod.db.table.refs;

使用 DataFrame 检查
可以使用 DataFrameReader API 加载元数据表:
// named metastore table
spark.read.format("iceberg").load("db.table.files")
// Hadoop path table
spark.read.format("iceberg").load("hdfs://nn:8020/path/to/table#files")十四、使用元数据表进行时间旅行
要使用时间旅行功能检查表的元数据:
-- get the table's file manifests at timestamp Sep 20, 2021 08:00:00
SELECT * FROM prod.db.table.manifests TIMESTAMP AS OF '2021-09-20 08:00:00';-- get the table's partitions with snapshot id 10963874102873L
SELECT * FROM prod.db.table.partitions VERSION AS OF 10963874102873;
还可以使用 DataFrameReader API 通过时间旅行来检查元数据表:
// load the table's file metadata at snapshot-id 10963874102873 as DataFrame
spark.read.format("iceberg").option("snapshot-id", 10963874102873L).load("db.table.files")
这篇关于Iceberg从入门到精通系列之二十三:Spark查询的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







