本文主要是介绍Apache Doris 整合 FLINK CDC + Iceberg 构建实时湖仓一体的联邦查询,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1概况
本文展示如何使用 Flink CDC + Iceberg + Doris 构建实时湖仓一体的联邦查询分析,Doris 1.1版本提供了Iceberg的支持,本文主要展示Doris和Iceberg怎么使用,大家按照步骤可以一步步完成。完整体验整个搭建操作的过程。
2系统架构
我们整理架构图如下,
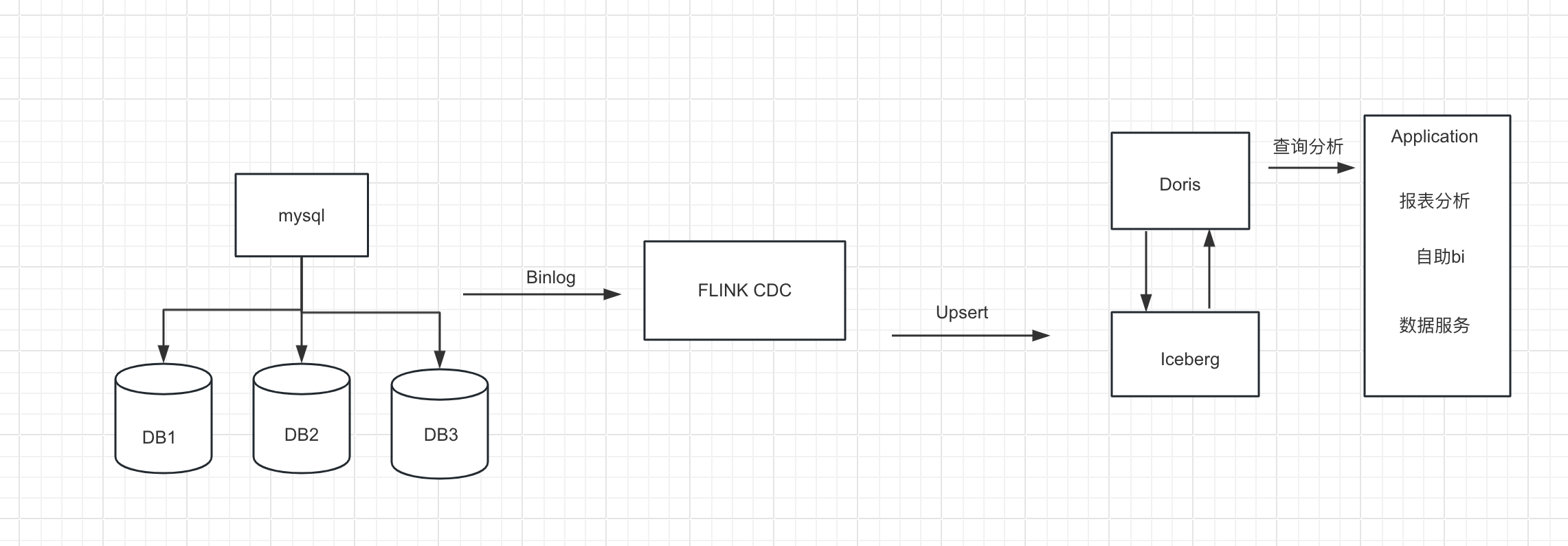
1.首先我们从Mysql数据中使用Flink 通过 Binlog完成数据的实时采集
2.然后再Flink 中创建 Iceberg 表,Iceberg的元数据保存在hive里
3.最后我们在Doris中创建Iceberg外表
4.在通过Doris 统一查询入口完成对Iceberg里的数据进行查询分析,供前端应用调用,这里iceberg外表的数据可以和Doris内部数据或者Doris其他外部数据源的数据进行关联查询分析
Doris湖仓一体的联邦查询架构如下:
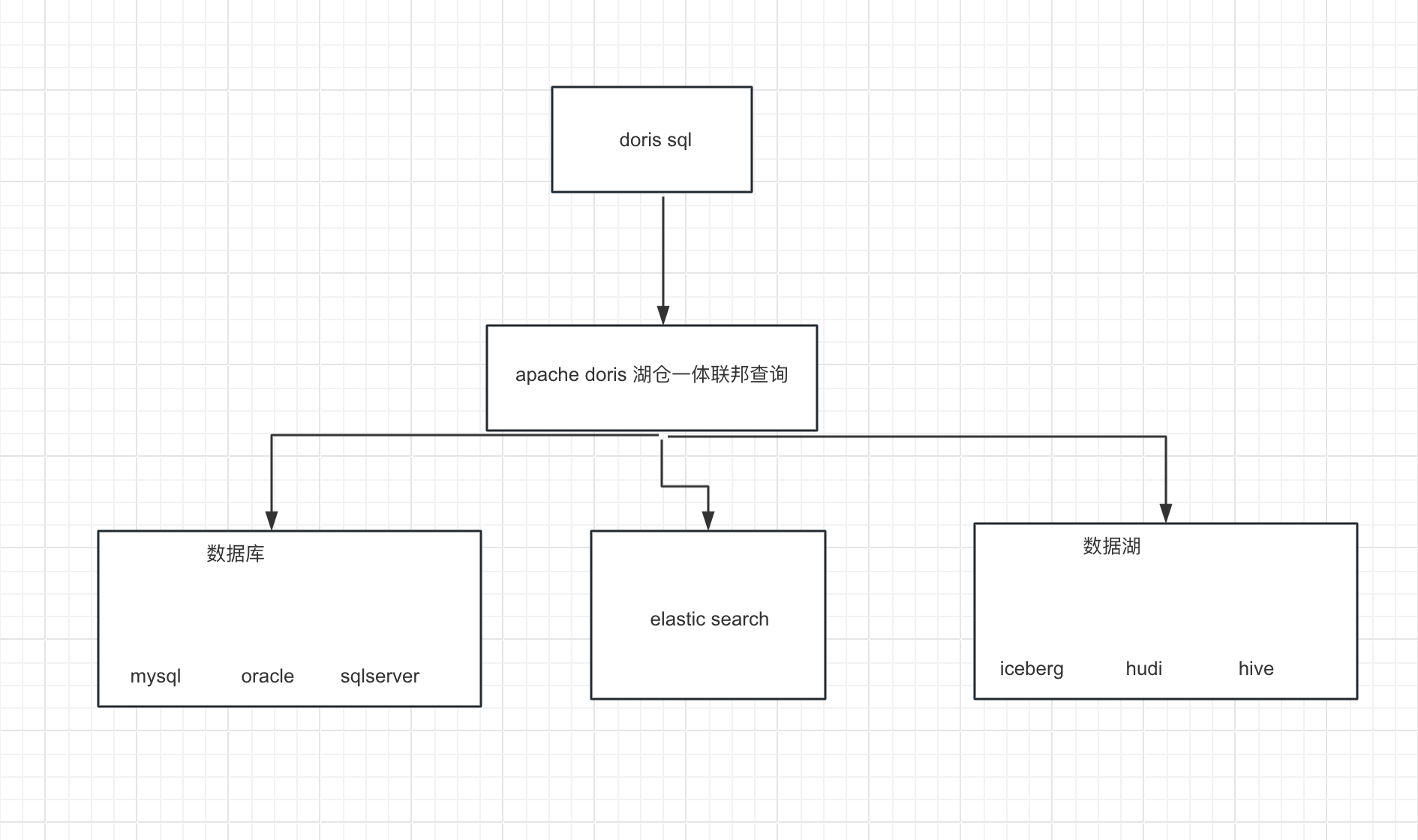
1.Doris 通过 ODBC 方式支持:MySQL,Postgresql,Oracle ,SQLServer
2.同时支持 Elasticsearch 外表
3.1.0版本支持Hive外表
4.1.1版本支持Iceberg外表
5.1.2版本支持Hudi 外表
3 创建MySQL数据库表并初始化数据
CREATE DATABASE demo;
USE demo;
CREATE TABLE userinfo (id int NOT NULL AUTO_INCREMENT,name VARCHAR(255) NOT NULL DEFAULT 'flink',address VARCHAR(1024),phone_number VARCHAR(512),email VARCHAR(255),PRIMARY KEY (`id`)
)ENGINE=InnoDB ;
INSERT INTO userinfo VALUES (10001,'user_110','Shanghai','13347420870', NULL);
INSERT INTO userinfo VALUES (10002,'user_111','xian','13347420870', NULL);
INSERT INTO userinfo VALUES (10003,'user_112','beijing','13347420870', NULL);
INSERT INTO userinfo VALUES (10004,'user_113','shenzheng','13347420870', NULL);
INSERT INTO userinfo VALUES (10005,'user_114','hangzhou','13347420870', NULL);
INSERT INTO userinfo VALUES (10006,'user_115','guizhou','13347420870', NULL);
INSERT INTO userinfo VALUES (10007,'user_116','chengdu','13347420870', NULL);
INSERT INTO userinfo VALUES (10008,'user_117','guangzhou','13347420870', NULL);
INSERT INTO userinfo VALUES (10009,'user_118','xian','13347420870', NULL);
4 创建Iceberg Catalog
CREATE CATALOG hive_catalog WITH ('type'='iceberg','catalog-type'='hive','uri'='thrift://localhost:9083','clients'='5','property-version'='1','warehouse'='hdfs://localhost:8020/user/hive/warehouse'
);
5 创建 Mysql CDC 表
CREATE TABLE user_source (database_name STRING METADATA VIRTUAL,table_name STRING METADATA VIRTUAL,`id` DECIMAL(20, 0) NOT NULL,name STRING,address STRING,phone_number STRING,email STRING,PRIMARY KEY (`id`) NOT ENFORCED) WITH ('connector' = 'mysql-cdc','hostname' = 'localhost','port' = '3306','username' = 'root','password' = 'MyNewPass4!','database-name' = 'demo','table-name' = 'userinfo');
6 创建Iceberg表
---查看catalog
show catalogs;
---使用catalog
use catalog hive_catalog;
--创建数据库
CREATE DATABASE iceberg_hive;
--使用数据库
use iceberg_hive;
7 创建表
CREATE TABLE all_users_info (database_name STRING,table_name STRING,`id` DECIMAL(20, 0) NOT NULL,name STRING,address STRING,phone_number STRING,email STRING,PRIMARY KEY (database_name, table_name, `id`) NOT ENFORCED) WITH ('catalog-type'='hive');
从CDC表里插入数据到Iceberg表里
use catalog default_catalog;
insert into hive_catalog.iceberg_hive.all_users_info select * from user_source;
我们去查询iceberg表
select * from hive_catalog.iceberg_hive.all_users_info
8 Doris 查询 Iceberg
8.1 创建Iceberg外表
CREATE TABLE `all_users_info`
ENGINE = ICEBERG
PROPERTIES (
"iceberg.database" = "iceberg_hive",
"iceberg.table" = "all_users_info",
"iceberg.hive.metastore.uris" = "thrift://localhost:9083",
"iceberg.catalog.type" = "HIVE_CATALOG"
);参数说明
•ENGINE 需要指定为 ICEBERG
•PROPERTIES 属性:
◦iceberg.hive.metastore.uris:Hive Metastore 服务地址
◦iceberg.database:挂载 Iceberg 对应的数据库名
◦iceberg.table:挂载 Iceberg 对应的表名,挂载 Iceberg database 时无需指定。
◦iceberg.catalog.type:Iceberg 中使用的 catalog 方式,默认为 HIVE_CATALOG,当前仅支持该方式,后续会支持更多的 Iceberg catalog 接入方式。
mysql> CREATE TABLE `all_users_info`-> ENGINE = ICEBERG-> PROPERTIES (-> "iceberg.database" = "iceberg_hive",-> "iceberg.table" = "all_users_info",-> "iceberg.hive.metastore.uris" = "thrift://localhost:9083",-> "iceberg.catalog.type" = "HIVE_CATALOG"-> );
Query OK, 0 rows affected (0.23 sec)
mysql> select * from all_users_info;
+---------------+------------+-------+----------+-----------+--------------+-------+
| database_name | table_name | id | name | address | phone_number | email |
+---------------+------------+-------+----------+-----------+--------------+-------+
| demo | userinfo | 10004 | user_113 | shenzheng | 13347420870 | NULL |
| demo | userinfo | 10005 | user_114 | hangzhou | 13347420870 | NULL |
| demo | userinfo | 10002 | user_111 | xian | 13347420870 | NULL |
| demo | userinfo | 10003 | user_112 | beijing | 13347420870 | NULL |
| demo | userinfo | 10001 | user_110 | Shanghai | 13347420870 | NULL |
| demo | userinfo | 10008 | user_117 | guangzhou | 13347420870 | NULL |
| demo | userinfo | 10009 | user_118 | xian | 13347420870 | NULL |
| demo | userinfo | 10006 | user_115 | guizhou | 13347420870 | NULL |
| demo | userinfo | 10007 | user_116 | chengdu | 13347420870 | NULL |
+---------------+------------+-------+----------+-----------+--------------+-------+
9 rows in set (0.18 sec)
上述Doris On Iceberg我们只演示了Iceberg单表的查询,你还可以联合Doris的表,或者其他的ODBC外表,Hive外表,ES外表等进行联合查询分析,通过Doris对外提供统一的查询分析入口。
自此我们完整从搭建Hadoop,hive、flink 、Mysql、Doris 及Doris On Iceberg的使用全部介绍完了,Doris朝着数据仓库和数据融合的架构演进,支持湖仓一体的联邦查询,给我们的开发带来更多的便利,更高效的开发,省去了很多数据同步的繁琐工作。
作者:京东零售 吴化斌
来源:京东云开发者社区 转载请注明来源
这篇关于Apache Doris 整合 FLINK CDC + Iceberg 构建实时湖仓一体的联邦查询的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






