apache专题

深入理解Apache Kafka(分布式流处理平台)
《深入理解ApacheKafka(分布式流处理平台)》ApacheKafka作为现代分布式系统中的核心中间件,为构建高吞吐量、低延迟的数据管道提供了强大支持,本文将深入探讨Kafka的核心概念、架构... 目录引言一、Apache Kafka概述1.1 什么是Kafka?1.2 Kafka的核心概念二、Ka

使用Apache POI在Java中实现Excel单元格的合并
《使用ApachePOI在Java中实现Excel单元格的合并》在日常工作中,Excel是一个不可或缺的工具,尤其是在处理大量数据时,本文将介绍如何使用ApachePOI库在Java中实现Excel... 目录工具类介绍工具类代码调用示例依赖配置总结在日常工作中,Excel 是一个不可或缺的工http://

Apache伪静态(Rewrite).htaccess文件详解与配置技巧
《Apache伪静态(Rewrite).htaccess文件详解与配置技巧》Apache伪静态(Rewrite).htaccess是一个纯文本文件,它里面存放着Apache服务器配置相关的指令,主要的... 一、.htAccess的基本作用.htaccess是一个纯文本文件,它里面存放着Apache服务器

Debezium 与 Apache Kafka 的集成方式步骤详解
《Debezium与ApacheKafka的集成方式步骤详解》本文详细介绍了如何将Debezium与ApacheKafka集成,包括集成概述、步骤、注意事项等,通过KafkaConnect,D... 目录一、集成概述二、集成步骤1. 准备 Kafka 环境2. 配置 Kafka Connect3. 安装 D

深入理解Apache Airflow 调度器(最新推荐)
《深入理解ApacheAirflow调度器(最新推荐)》ApacheAirflow调度器是数据管道管理系统的关键组件,负责编排dag中任务的执行,通过理解调度器的角色和工作方式,正确配置调度器,并... 目录什么是Airflow 调度器?Airflow 调度器工作机制配置Airflow调度器调优及优化建议最
SpringBoot使用Apache Tika检测敏感信息
《SpringBoot使用ApacheTika检测敏感信息》ApacheTika是一个功能强大的内容分析工具,它能够从多种文件格式中提取文本、元数据以及其他结构化信息,下面我们来看看如何使用Ap... 目录Tika 主要特性1. 多格式支持2. 自动文件类型检测3. 文本和元数据提取4. 支持 OCR(光学

Apache Tomcat服务器版本号隐藏的几种方法
《ApacheTomcat服务器版本号隐藏的几种方法》本文主要介绍了ApacheTomcat服务器版本号隐藏的几种方法,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需... 目录1. 隐藏HTTP响应头中的Server信息编辑 server.XML 文件2. 修China编程改错误
SpringBoot使用Apache POI库读取Excel文件的操作详解
《SpringBoot使用ApachePOI库读取Excel文件的操作详解》在日常开发中,我们经常需要处理Excel文件中的数据,无论是从数据库导入数据、处理数据报表,还是批量生成数据,都可能会遇到... 目录项目背景依赖导入读取Excel模板的实现代码实现代码解析ExcelDemoInfoDTO 数据传输

Apache Tiles 布局管理器
陈科肇 =========== 1.简介 一个免费的开源模板框架现代Java应用程序。 基于该复合图案它是建立以简化的用户界面的开发。 对于复杂的网站,它仍然最简单,最优雅的方式来一起工作的任何MVC技术。 Tiles允许作者定义页面片段可被组装成在运行一个完整的网页。 这些片段,或Tiles,可以用于为了降低公共页面元素的重复,简单地包括或嵌入在其它瓦片,制定了一系列可重复使用

Apache HttpClient使用详解
转载地址:http://eksliang.iteye.com/blog/2191017 Http协议的重要性相信不用我多说了,HttpClient相比传统JDK自带的URLConnection,增加了易用性和灵活性(具体区别,日后我们再讨论),它不仅是客户端发送Http请求变得容易,而且也方便了开发人员测试接口(基于Http协议的),即提高了开发的效率,也方便提高代码的健壮性。因此熟
开源Apache服务器安全防护技术精要及实战
Apache 服务简介 Web服务器也称为WWW服务器或HTTP服务器(HTTPServer),它是Internet上最常见也是使用最频繁的服务器之一,Web服务器能够为用户提供网页浏览、论坛访问等等服务。 由于用户在通过Web浏览器访问信息资源的过程中,无须再关心一些技术性的细节,而且界面非常友好,因而Web在Internet上一推出就得到了爆炸性的发展。现在Web服务器已

Java中WebService接口的生成、打包成.exe、设置成Windows服务、及其调用、Apache CXF调用
一、Java中WebService接口的生成: 1、在eclipse工具中新建一个普通的JAVA项目,新建一个java类:JwsServiceHello.java package com.accord.ws;import javax.jws.WebMethod;import javax.jws.WebService;import javax.xml.ws.Endpoint;/*** Ti
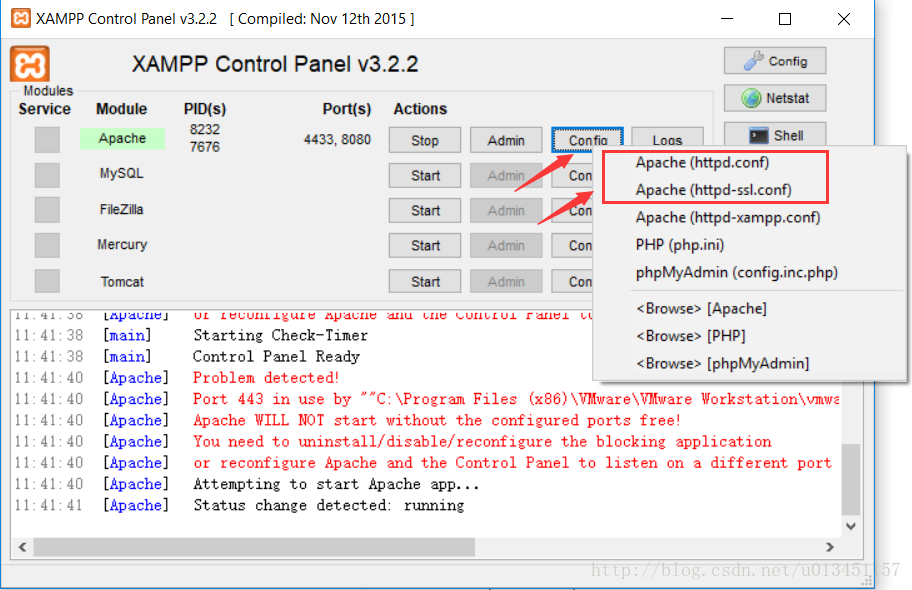
【虚拟机/服务器】XAMPP错误: Apache shutdown unexpectedly解决办法
XAMPP安装好之后启动,但有些用户在启动apache的时候会出现: 11:41:38 [Apache] Status change detected: running11:41:38 [Apache] Status change detected: stopped11:41:38 [Apache] Error: Apache shutdown unexpectedly.11:41:38

部署Apache网站
简易部署自己的apache网站 写在前面:先安装好mysql,再来搭建站点 1.安装php [root@localhost ~]# yum install php -y##安装了php,默认会和apache结合工作 2.创建文件编写php网页代码 [root@localhost ~]# vim /var/www/html/index.php ##创建php的代码,index.p
兔子-更改 Apache 默认网站根目录
1.到Apache的安装目录下找到conf文件夹,该文件夹内会httpd.conf这样一个文本文档,它是Apache的配置文件。2.Ctrl+F组合键,找到 DocumentRoot D:/Apache/htdocs 将D:/Apache/htdocs改为你自定义的网站目录; 3.找到 <Directory D:/Apache/htdocs 将D:/Apache/htdocs改为你自定义的网
POM文件第一行报错org.apache.maven.archiver.MavenArchiver.getManifest
前几天新建maven项目时,系统自动生成的POM文件第一行总是报错 org.apache.maven.archiver.MavenArchiver.getManifest(org.apache.maven.project.MavenProject, org.apache.maven.archiver.MavenArchiveConfiguration) 百思不得其解,明明是自动生成的怎么还会有

兼容Trino Connector,扩展Apache Doris数据源接入能力|Lakehouse 使用手册(四)
Apache Doris 内置支持包括 Hive、Iceberg、Hudi、Paimon、LakeSoul、JDBC 在内的多种 Catalog,并为其提供原生高性能且稳定的访问能力,以满足与数据湖的集成需求。而随着 Apache Doris 用户的增加,新的数据源连接需求也随之增加。因此,从 3.0 版本开始,Apache Doris 引入了 Trino Connector 兼容框架。 Tri

Apache-Flink深度解析-State
来源:https://dwz.cn/xrMCqbk5 Flink系列精华文章合集入门篇: Flink入门Flink DataSet&DataSteam APIFlink集群部署Flink重启策略Flink分布式缓存Flink重启策略Flink中的TimeFlink中的窗口Flink的时间戳和水印Flink广播变量Flink-Kafka-connetorFlink-Table&SQLFlink
Apache-Flink深度解析-Temporal-Table-JOIN
在《JOIN LATERAL》中提到了Temporal Table JOIN,本篇就向大家详细介绍什么是Temporal Table JOIN。在ANSI-SQL 2011 中提出了Temporal 的概念,Oracle,SQLServer,DB2等大的数据库厂商也先后实现了这个标准。Temporal Table记录了历史上任何时间点所有的数据改动,Temporal Table的工作流程如下:
下一代分布式消息队列Apache Pulsar
Pulsar简介 Apache Pulsar是一个企业级的分布式消息系统,最初由Yahoo开发并在2016年开源,目前正在Apache基金会下孵化。Plusar已经在Yahoo的生产环境使用了三年多,主要服务于Mail、Finance、Sports、 Flickr、 the Gemini Ads platform、 Sherpa以及Yahoo的KV存储。Pulsar之所以能够称为下一代消息队列,
Apache Spark3.0什么样?一文读懂Apache Spark最新技术发展与展望
简介: 阿里巴巴高级技术专家李呈祥带来了《Apache Spark 最新技术发展和3.0+ 展望》的全面解析,为大家介绍了Spark在整体IT基础设施上云背景下的新挑战和最新技术进展,同时预测了Spark 3.0即将重磅发布的新功能。 2019阿里云峰会·上海开发者大会于7月24日盛大开幕,在本次峰会的开源大数据专场上,阿里巴巴高级技术专家李呈祥带来了《Apache Spark 最新技术发展和
Apache Flink:Keyed Window与Non-Keyed Window
Apache Flink中,Window操作在流式数据处理中是非常核心的一种抽象,它把一个无限流数据集分割成一个个有界的Window(或称为Bucket),然后就可以非常方便地定义作用于Window之上的各种计算操作。本文我们主要基于Apache Flink 1.4.0版本,说明Keyed Window与Non-Keyed Window的基本概念,然后分别对与其相关的WindowFunction
Apache Kylin VS Apache Doris全方位对比
1 系统架构 1.1 What is Kylin1.2 What is Doris2 数据模型 2.1 Kylin的聚合模型2.2 Doris的聚合模型2.3 Kylin Cuboid VS Doris RollUp2.4 Doris的明细模型3 存储引擎4 数据导入5 查询6 精确去重7 元数据8 高性能9 高可用10 可维护性 10.1 部署10.2 运维10.3 客服11 易用性 11.1
Apache Kylin 在美团数十亿数据 OLAP 场景下的实践
大数据技术与架构 点击右侧关注,大数据开发领域最强公众号! 暴走大数据 点击右侧关注,暴走大数据! By 大数据技术与架构 场景描述:美团各业务线存在大量的OLAP分析场景,需要基于Hadoop数十亿级别的数据进行分析,直接响应分析师和城市BD等数千人

使用 Apache Flink 开发实时ETL
来源:薄荷脑的博客 作者:薄荷脑 大数据技术与架构 点击右侧关注,大数据开发领域最强公众号! 暴走大数据 点击右侧关注,暴走大数据! By 大数据技术与架构 场景描述:本文将介绍如何使用 Flink 开发实时 ETL 程序,并介绍 Flink 是如何保证