本文主要是介绍Apache Spark3.0什么样?一文读懂Apache Spark最新技术发展与展望,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
简介: 阿里巴巴高级技术专家李呈祥带来了《Apache Spark 最新技术发展和3.0+ 展望》的全面解析,为大家介绍了Spark在整体IT基础设施上云背景下的新挑战和最新技术进展,同时预测了Spark 3.0即将重磅发布的新功能。
2019阿里云峰会·上海开发者大会于7月24日盛大开幕,在本次峰会的开源大数据专场上,阿里巴巴高级技术专家李呈祥带来了《Apache Spark 最新技术发展和3.0+ 展望》的全面解析,为大家介绍了Spark在整体IT基础设施上云背景下的新挑战和最新技术进展,同时预测了Spark 3.0即将重磅发布的新功能。
开源大数据专场——阿里云峰会(上海)开发者大会PPT下载:https://dwz.cn/auNXJC6V
以下内容根据演讲视频以及PPT整理而成。
自2009年伯克利的AMP LAB将 Spark开源以来,Spark在大数据处理领域获得了巨大的成功。Spark的定位是大数据处理的统一分析引擎,具有非常通用的分布式计算引擎,基于这个分布式计算引擎, Spark在不同领域方向提供了高层的DSL,比如针对关系型数据的Spark SQL,针对实时数据的Spark streaming,针对机器学习的MLlib, 以及针对图计算的GraphX。
Spark获得大数据领域的认可的原因有三点。
第一, 它提供了易用的API,支持Java、Scala、Python, R、SQL等多种语言,这使得数据工程师和数据科学家都能够使用他们最熟悉的语言访问Spark。此外,Spark也提供了声明式的DSL,在API的灵活性和应用性之间达到了平衡。
第二, Spark是目前大数据领域生态系统最丰富的组件,支持ORC、Parquet等数据存储格式,Kafka消息队列以及多种资源调度的框架,几乎所有与数据处理上下游相关的组件都可以在Spark上找到官方或者非官方的集成支持。
第三, Spark有非常高效的处理引擎,它的Catalyst和Tungsten项目支持了对于数据分析性能至关重要的两大特性。其一,内存管理,Spark通过自定义的内存管理,把所有在Spark上处理的数据转化为二进制数据再进行管理,Spark计算直接操作二进制数据而不是对象,这使得内存的使用高效和可控,也很大程度上避免了JVM进程的OOM或者GC问题。其二,代码生成。通过Runtime的CodeGen,Spark消除了传统数据分析中火山模型由于调用链过长而导致的调用代价问题。

一、Spark在数据仓库方向上的改进和增强
Delta Lake
2019年4月,Databricks开源了Delta Lake项目,引发了开源社区广泛的关注。Delta Lake是Spark计算框架和存储系统之间带有Schema信息数据的存储中间层。它给Spark带来了两个最主要的功能,第一,Delta Lake使得Spark能支持数据更新功能,以前Spark只支持添加数据,而无法删除或更新数据;第二,Delta Lake使得Spark能支持事务,而事务是功能完备的数据仓库必不可少的特性。Delta Lake使得 Spark streaming能实时地拉取数据,写入Delta Lake,再用SparkSQL进行数据分析。这意味着,Spark能用于构建实时数仓,更快地展现数据分析结构,从而更好地实现数据价值。在此之前,Spark通过时间分区表将数据按小时或天加载到Hive、Spark中,再对数据进行分析,持续性方面无法满足业务需求。另一方面,即使通过压缩分区来提高速度,它也会导致其他问题。譬如,分区过多意味着小文件过多,这会导致数据管理代价过大,后续的数据查询效率降低。而Delta Lake可以方便地把数据实时性提升到分钟级甚至是秒级。此外,它还保证了Spark Streaming读写数据的一致性。Delta Lake还能自动地定期Merge小文件,减少小文件带来的性能问题。
此外,Delta Lake也支持数据版本的管理,允许用户查询之前某个时间点的数据快照。事实上,Delta Lake并不是唯一开源的存储中间层,现有的其他存储中间层包括Uber的Hudi以及Netflix的Iceberg等。这反映了存储中间层对于用户而言是普遍而且迫切的需求。值得相信的是,Delta Lake项目的不断发展,能够帮助补充和完善Spark成为一个功能更完备的数据仓库。

Data Source V2
目前,Spark的Data Source实现非常优雅和通用,提供了几乎所有大数据领域相关的数据源Plugin。然而,随着项目的发展,Data Source也暴露出了许多不足之处,除了投影和过滤算子,Data Source很难支持其他算子下推。另外,当前的Data Source接口还很难实现事务写。因此,一个全新的Data Source API即Data Source V2被推出了,其主要目标包括三个。其一,统一批和流的Data Source API,以实现同一个API来支持批和流的数据源;其二,API的设计更灵活,提高基于Data Source的性能优化空间,比如将更多计算任务放到Data Source层,实现列式的数据扫描等等;其三,支持更灵活的元数据管理,允许用户选择元数据类型,目前Data Source支持In-memory Catalog和Hive Catalog两种元数据, Datasource V2可以支持用json文件描述catalog信息。

Runtime Optimization
Runtime优化也是数据仓库领域的高级特性,其基本思想是根据运行时的统计信息寻找最优的执行计划。相比于Spark现有的基于规则优化和基于代价的CPU优化,Runtime的信息最准确,针对这种信息进行调整能够得到理论上最优的执行计划。
一种Runtime优化是Adaptive Execution,包括三个部分。第一,动态调整Reduce Task的数量。系统可以在所有Map Task执行后获取它们的运行时统计信息,从而获取所有Reduce Task处理的Partition信息,包括它们的数据量大小和具体数量。在实际的场景中,不同Partition的数据量不同,数据量大的Partition对应的Task执行时间较长,数据量小的执行时间较短,这样某些资源就被浪费了。另外,如果每个Partition的数据量都比较小,那么对应Task的数量就比较多。通过Adaptive Execution可以将数据量较小的Partition组合起来分配给一个Reduce Task处理,使得每个Reduce Task处理的数据量都比较均衡而且大小合理。第二,Adaptive Join Strategy, 即根据运行时信息判断来选择具体的Join策略。第三,Adaptive Execution允许在Join操作发生数据倾斜时,对倾斜部分数据做并行处理,避免出现由于数据倾斜导致某个Reduce Task执行时间过长,从而影响整个任务进度的情况。
另一种Runtime优化是Spark支持的EMR Runtime Filter特性,同样根据运行时信息来优化和查询。其思想是,当数据量较大的表和数据量较小的表做Join时,如果小表的Join Key数量很少,则将小表的Key集合作为过滤条件,用于在访问大表时过滤大表数据。这样,访问大表数据时,分区表的很多分区就被过滤了,而非分区表可以通过其特性来过滤其文件或者Parquet的Page。

Spark Relational Cache
通常情况下,优化Spark Relational Cache时的优化目标通常是Ad hoc的,即不假定查询形式,而针对更通用的查询分析场景。但在实际使用场景中,某些场景下用户的查询模式是比较固定的,比如,用户的数据表不太可能和数据库当中的所有表都做关联查询,而只和一个或者几个和它有业务语义关联的表做关联查询。这种查询模式比较固定的场景有另一种性能优化思路,即让数据适配查询模式,从而提升查询性能。举个例子,假设针对某个表的查询经常过滤某个字段,如果这个字段较小,设计表时就可以将它作为表的分区字段,那么查询时这个过滤条件就可以过滤掉很多分区,这也就是通过数据的预组织来提升查询性能。
另外,数据库查询时如果需要两个表做Join,允许把两个表的Join结果缓存起来,之后再有相同查询时可以直接根据缓存结果修改执行计划,而不需要重新执行Join,这是数据领域中物化视图的概念。Spark中对这个概念做了延伸和扩展,命名为Relational Cache。

Relational Cache能够对关系型数据进行Cache,Spark支持的关系型数据包括表、View、Data Set等。通过Relational Cache可以将这些关系型数据以任意Spark支持的数据格式,数据源Cache起来,比如Cache到内存、HDFS、OSS等。Cache之后的数据还可以根据查询模式选择合理的数据组织方式,比如分区、分桶、排序以及File Index等。这种Cache对用户而言是完全透明且无需感知的,用户执行查询后,由Spark Optimizer发现合适的Cache,并用其替换用户查询执行计划从而提升效率。用户查询中最费时的那部分被Cache时带来的性能提升将非常明显,可能达到一两个数量级。
总而言之,Relational Cache为查询模式比较固定的查询场景提供了一种新的优化可能,从而实现TB甚至PB量级数据的秒级乃至亚秒级的交互式分析需求。

二、Spark如何应对整体IT基础设施上云背景下的挑战
云环境下,大数据体系中通常按照存储和计算分离的模式来设计架构。存储和计算分离的一个直接原因是提高性价比,用户只需要为其所花费的资源付费,比如使用Spark处理阿里云OSS数据时,用户只需要为使用的存储空间和计算节点付费。计算完成时,用户可以Release使用的Spark计算节点,保留OSS的数据存储空间,OSS以及Spark节点都可以独立地进行升缩。然而,这种模式也面临着一些挑战,Spark最初的设计是基于HDFS本地分布式文件系统,这与云上的OSS存储不同,这种不同导致了在某些场景下Spark存在一些性能问题。比如,文件的Rename操作在HDFS中只需要改变Name Node内存空间的映射,然而在OSS中却可能需要移动这个文件本身,带来的性能代价差距非常大。另外,尽管所有的云服务商都在不断提升网络硬件的配置,但相对于本地存储,云环境下存储和计算之间的网络带宽依然比较受限,经常成为整个数据分析的瓶颈。

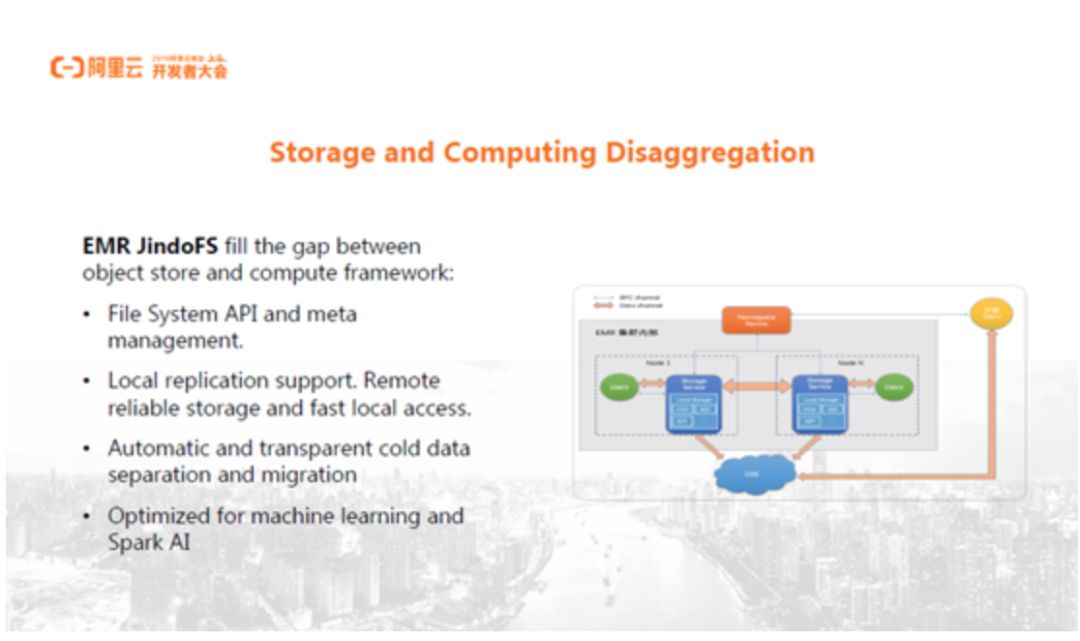
EMR JindoFS
阿里云EMR提供了JindoFS,用于对接阿里云的各种计算资源和存储系统。JindoFS部分的设计目标就是解决上面两个问题,其一,它提供File System API以及对Spark等计算框架非常友好的元数据管理系统。其二,JindoFS提供了本地的数据缓存,结合远程的OSS可靠存储和本地有限的高效存储,能够自动地将热数据缓存到本地的高效存储上,提供类似本地存储的性能,与此同时,大部分数据仍然存储在OSS,能够利用OSS的高性价比以及高可用性。
Remote Shuffle Service
此外,Spark社区正在实践Remote Shuffle Service特性。Spark所提倡的存储和计算分离通常是指读和写的数据源和计算资源的分离,但计算过程如果涉及到需要存储到本地磁盘的Shuffle,就会造成一定的资源浪费,因为用户很难准确预算需要Shuffle到本地磁盘的数据量,从而不得不在计算节点预留充足的本地磁盘空间以进行Shuffle。这就使得很难动态透明地伸缩本地存储空间。
Remote Shuffle Service的基本想法是,如果Map Task能将Shuffle数据写到独立的Shuffle服务,然后Reduce Task从这个Shuffle服务读Shuffle数据,这样计算节点就不再需要为Shuffle任务保留本地磁盘空间了。目前,Spark社区正在努力使得Shuffle数据落地到本地磁盘时,能够写到远程的存储系统中。然而,想要实践完整的Remote Shuffle Service还需要完成更多的工作。

Spark On Kubernetes
Spark 2.3提供了对Spark On Kubernetes特性的官方支持。目前,Spark 2.4中Spark On Kubernetes特性又新增了对Pyspark和R的支持,以及对Client模式的支持。Spark 3.0中对Spark On Kubernetes特性预计也将有重大改进。其一,Spark将利用Dynamic Allocation Support特性实现资源的动态调整,比如根据集群负载动态地调整和伸缩集群规模,这同样会依赖于Remote Shuffle Storage特性。其二,Spark将支持对Kerberos的身份认证。

三、Spark与AI框架深度集成的最新进展
机器学习任务的完整链条非常长,包括数据的收集、落地、清理、准备,以及模型的训练、检验以及预测等。Spark比较擅长该链条比较靠前的部分,即数据的采集、落地、清理和准备。深度学习框架擅长链条靠后这部分,即模型的训练、验证和分析。用户在完成一个深度学习任务时,需要基于比如Spark和Tensorflow这两套系统,这就给用户带来了很多不便之处,比如两套系统的部署、运维、管理等。另外,这也使得整个任务的开发、Debug、Troubleshooting变得困难。
Spark社区通过集成成熟的机器学习框架来解决此问题。具体来说,Spark依赖于Project Hydrogen将所有从数据采集、清理、准备到模型训练、预测的Data Process Pipeline都完整地集成起来。Project Hydrogen主要包含三个子任务:
第一, 通过Barrier Execution Mode在Spark里Launch深度学习任务;
第二, Accelerator Aware Scheduling提供了对GPU加速器的感知能力,从而将深度学习任务调度到合适的节点上,因为大部分深度学习任务都在GPU加速器上运行;
第三, Optimized Data Exchange为Spark和深度学习框架提供了一个高速有效的数据交换方式。
1. Barrier Execution
实现Barrier Execution的直接原因,在于 Spark分布式计算框架的任务调度方式和深度学习框架区别非常大,比如,Spark分布式计算框架将数据切片给不同Task,由每个Task独立地处理自己的数据,允许用户在调度期内分批地调度Task。当某个Task挂掉时只需要重新将其拉起,并不会影响其他Task。然而,在深度学习框架里,Task之间往往存在数据交换,某个Task挂掉可能需要将所有Task都重新拉起。因此,Spark通过Barrier Execution来同时调度所有Task,当某个Task挂掉时将所有Task重新拉起。此外,它还提供了Barrier原语,允许用户在深度学习中基于此原语实现深度学习Task之间的同步。

2. Accelerator Aware Scheduling
Spark依赖Accelerator Aware Scheduling来感知GPU计算资源,从而调度深度学习任务。实际上,Spark本身并不直接管理GPU资源,而是通过YARN等资源管理框架在Application Level来申请并获得计算所需的GPU资源。用户可以在Context中获取GPU信息,从而实现GPU计算,完成深度学习任务。需要注意的是,Spark支持的计算加速器并不限于GPU,可以很容易扩展到FPGA等其他加速器类型。

3. Optimized Data Exchange
Project Hydrogen的第三个部分Optimized Data Exchange,关注如何高效地实现Spark和深度学习框架之间的数据交换。目前,Spark和深度学习框架之间的数据交换问题主要有两点。其一,没有数据交换的标准格式;其二,数据交互依赖于外部存储系统,需要涉及到数据的网络传输、序列化、反序列化、磁盘的读写等,效率比较低。
而Optimized Data Exchange解决了三个问题。第一,Spark能够读和写深度学习框架中的数据模型;第二和第三个问题涉及到在Spark中实现Spark 任务和深度学习任务数据交换的两种场景。一种场景是,由Spark任务处理好数据再交给深度学习任务实现模型训练。另一种场景是,由Spark任务获取数据再交给深度学习任务实现打分或预测。
目前,Spark社区实现Optimized Data Exchange的基本思路是,使用Apache Arrow数据格式将数据从Spark传到深度学习任务所在的Python进程。深度学习任务可以直接读取Arrow格式数据,也可以将Arrow数据转换为其他数据格式再读取。

四、Spark 3.0的新功能展望
Spark 3.0最重要的功能预计将是Project Hydrogen。它的第一个重要功能已在Spark 2.4中Release,Spark 3.0版本将提供它的其余两个重要功能:GPU-Aware Scheduling和Optimized Data Exchange。目前,EMR Spark已集成了这部分代码,同时添加了一些扩展和改进,并在客户生产环境中实际落地。关注结合Spark和AI以支持业务的用户可以持续关注这一块,在EMR Spark上做一些尝试工作。

Adaptive Execution功能非常重视性能和查询并发度,它的前两个功能点预计将包含在Spark 3.0中。目前,一些涉及到大量Join操作的超大规模数据查询由于需要大量Task,已无法在Spark上顺利执行,而Adaptive Execution所提供的自动性能优化将使得这种任务成功执行。
另外,Spark 3.0还可能包含Data Source V2,它能给开发人员提供更大的优化空间,以支持更多的重构和开发新Data Source Plug-in的可能。
Spark 3.0也可能包含对Spark On Kubernetes中Dynamic Resource Allocation的重要支持,允许用户将Spark和其他服务混布,从而动态调整Spark的集群任务规模,减轻集群的负载,提高集群资源的成本和性价比。
最后,Spark 3.0还可能包含一些小改进,比如Hadoop和Hive依赖版本的升级,更好地支持标准SQL的兼容等。总体来说,Apache Spark 3.0将会是Spark较大的一次版本升级,包含了许多重要特性,非常值得大家期待。

这篇关于Apache Spark3.0什么样?一文读懂Apache Spark最新技术发展与展望的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




