湖仓专题
针对 AI 优化数据湖仓一体:使用 MinIO 仔细了解 RisingWave
RisingWave 是现代数据湖仓一体处理层中的开源流数据库,专为性能和可扩展性而构建。RisingWave 旨在允许开发人员在流数据上运行 SQL。鉴于 SQL 是数据工程的通用语言,此功能非常重要。它具有强大的架构,包括计算节点、元节点和压缩器节点,所有这些都针对 AI 基础的高吞吐量和低延迟操作进行了优化:例如数据质量、数据探索和预处理。请记住,您的 AI 计划仅与您的数据一样好。
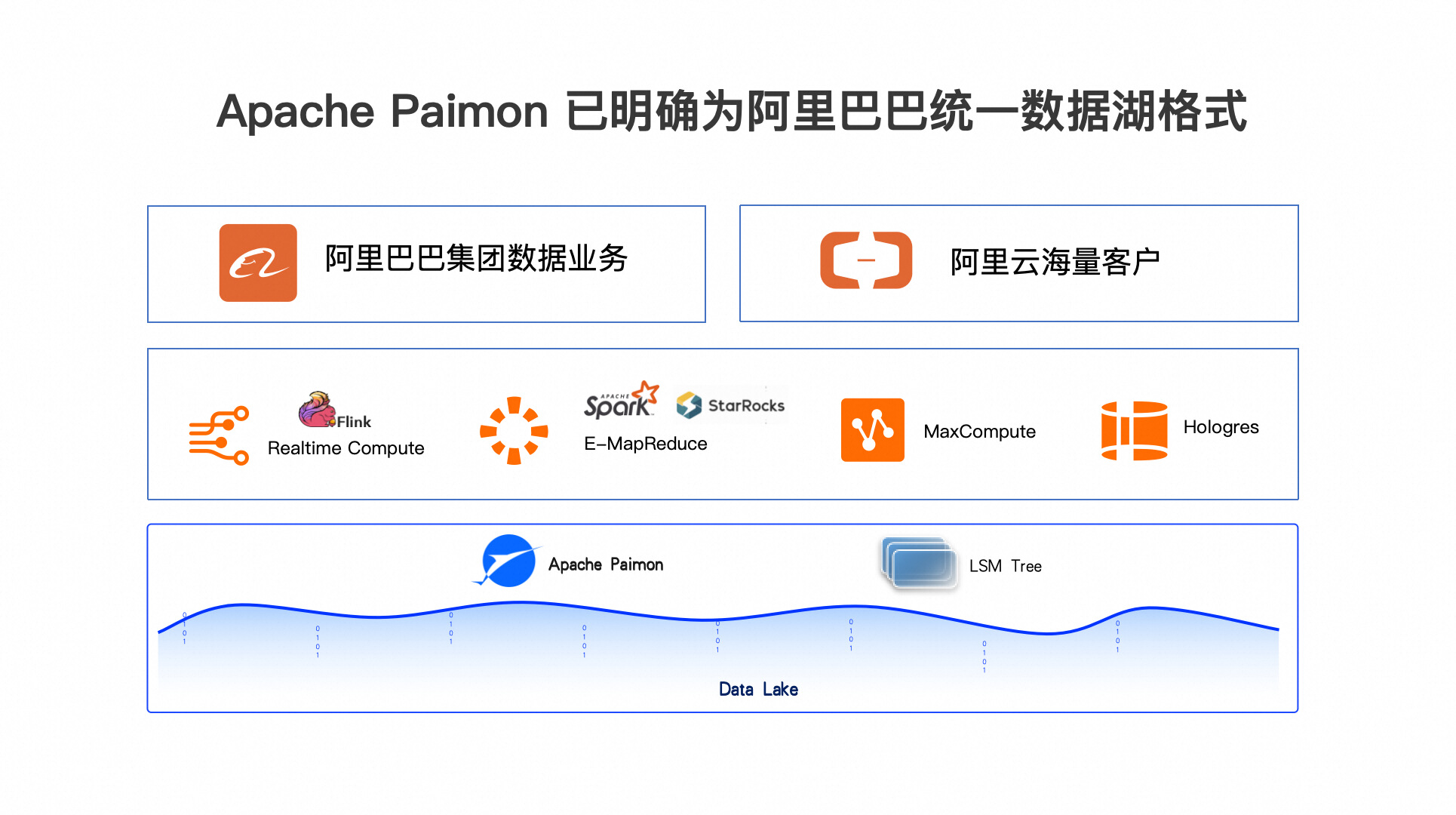
湖仓一体全面开启实时化时代
摘要:本文整理自阿里云开源大数据平台负责人王峰(莫问)老师在5月16日 Streaming Lakehouse Meetup · Online 上的分享,主要介绍在新一代湖仓架构上如何进行实时化大数据分析。内容主要分为以下五个部分: Data Lake + Data Warehouse = Data LakehouseApache Paimon–Unified Lake FormatThe Pa
AI 写 SQL 真的靠谱吗?腾讯游戏在 AI+ 湖仓一体的实践
作者:腾讯游戏数据技术负责人 刘岩 导读 腾讯游戏是全球领先的游戏开发和运营商,其数据团队拥有十余年、700+ 款大型游戏的数据工作沉淀。复杂的业务环境下,腾讯游戏数据团队每年需要处理超过 3 万个数据提取需求,SQL 编写需要耗费大量时间和精力,如何提升效率成为了一个关键问题。 本文介绍了腾讯游戏数据团队如何通过最新的大语言模型技术,基于StarRocks构建一个高效的湖仓一体 +AI 数据

数据仓库 vs 数据湖 vs 湖仓一体:如何基于自身数据策略,选择最合适的数据管理方案?
在信息化浪潮席卷全球的今天,数据已经成为企业决策和发展的重要驱动力。无论是电商平台的用户行为分析,还是金融领域的风险预测,亦或是物联网设备的海量数据处理,都离不开高效、灵活的数据存储和处理方式。在这样的背景下,各种数据存储和处理技术应运而生,它们各自以其独特的方式在数据生态系统中发挥着不可或缺的作用。 本文主要阐述了数据仓库、数据湖和湖仓一体的概念、功能、优势及选择策略,并举出几个可能遇
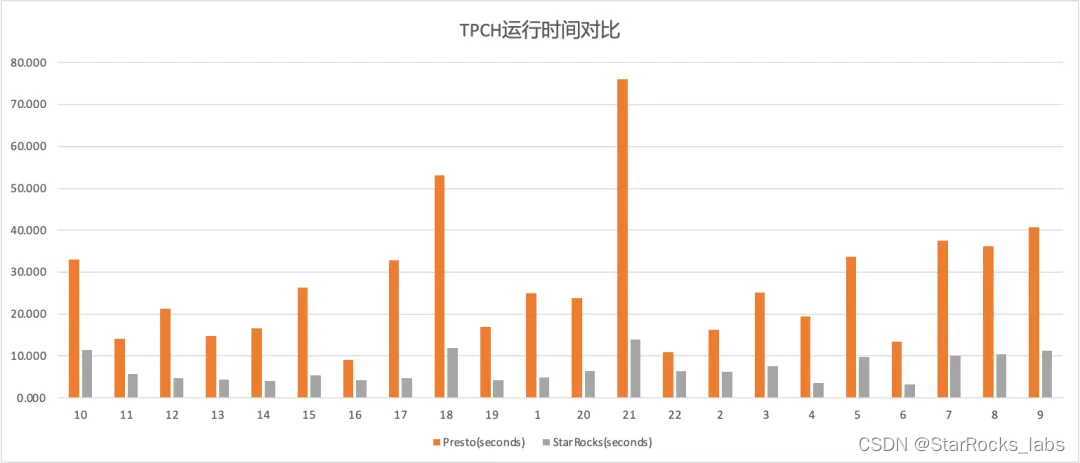
StarRocks x Paimon 构建极速实时湖仓分析架构实践
Paimon 介绍 Apache Paimon 是新一代的湖格式,可以使用 Flink 和 Spark 构建实时 Lakehouse 架构,以进行流式处理和批处理操作。Paimon 创新性地使用 LSM(日志结构合并树)结构,将实时流式更新引入 Lakehouse 架构中。 Paimon 提供以下核心功能: 高效实时更新:高吞吐和低延迟的数据摄入和更新 统一的批处理和流处理:同时支持批量读写
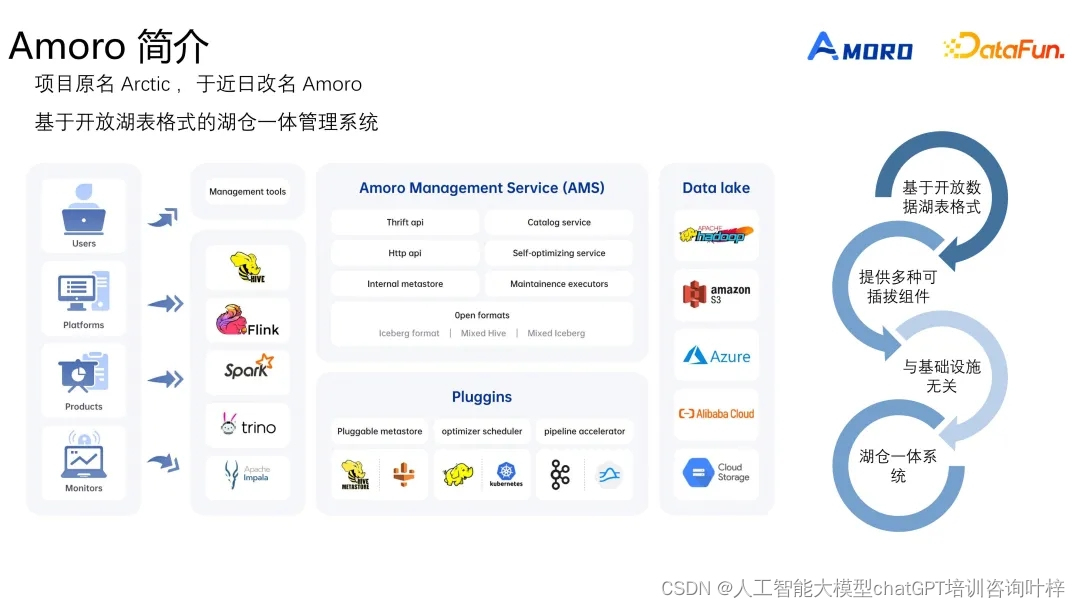
构建云原生湖仓:Apache Iceberg与Amoro的结合实践
随着大数据技术的快速发展,企业对数据的处理和分析需求日益增长。传统的数据仓库已逐渐无法满足现代业务对数据多样性和实时性的要求,这促使了数据湖和数据仓库的融合,即湖仓一体架构的诞生。在云原生技术的推动下,构建云原生湖仓成为企业提升数据处理能力的重要途径。本文将探讨如何利用Apache Iceberg和Amoro在云原生环境下构建高效的湖仓一体解决方案。 Apache Iceberg与云原生 Ap
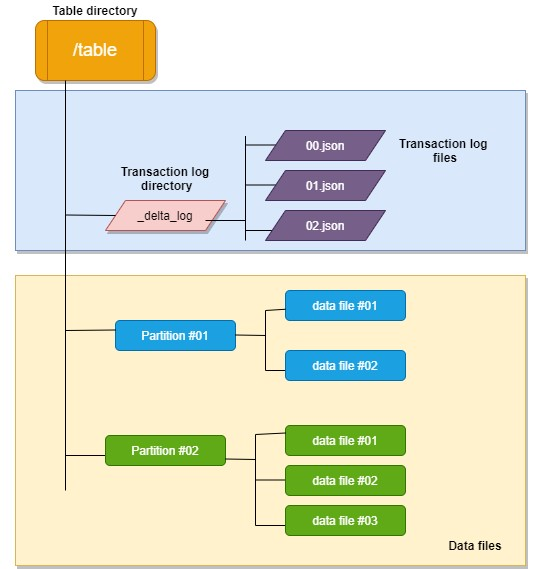
湖仓一体(Lakehouse)架构的核心组件之存储层——Lakehouse 架构(三)
文章目录 前言Lakehouse 存储关键概念行存储与列存储基于存储的查询性能优化 Lakehouse 存储组件云储存文件格式Apache ParquetApache ORCApache Avro相似点和差异点 表格格式Apache HiveIceberg特性和优点 Apache Hudi特性和优点 Delta Lake特性和优点 相似点和差异点 总结 前言 存储层是任何数据平
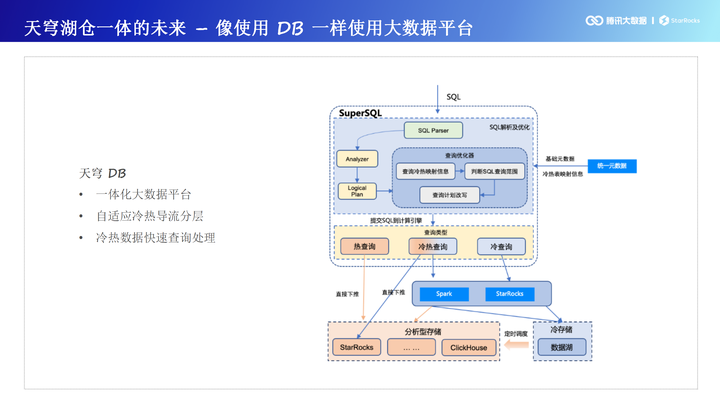
腾讯天穹 StarRocks 一站式湖仓融合平台架构揭秘
作者:腾讯大数据 高级工程师 陈九天 小编导读: 腾讯天穹是协同腾讯内各 BG 大数据能力而生的 Oteam,作为腾讯大数据领域的代名词,旨在拉通大数据各个技术组件,打造一个具有统一技术栈的公司级大数据平台体系。从底层数据接入、数据存储、资源管理、计算引擎、作业调度,到上层数据治理及数据应用等多个环节,支持腾讯内部近 EB 级数据的存储和计算,为业务提供海量、高效、稳定的大数据平台支撑和

HashData的湖仓一体思考:Iceberg、Hudi特性讲解与支持方案
湖仓一体作为一种新兴的开放式数据管理架构,能够充分发挥数据湖的灵活性、生态丰富以及数据仓库的企业级数据分析能力,已经成为企业建设现代数据平台的热门选择。 在此前的直播中,我们分享了HashData湖仓一体方案架构设计与Hive数据同步。本次直播,我们介绍了Iceberg、Hudi的特性与支持方案,并对HashData连接组件的原理和实现流程进行了详细的讲解和演示。以下内容根据直播文字整理。 H
数据平台:湖仓一体、流批一体、存算分离的核心问题
一、为什么出现湖仓一体的技术架构 目前数据仓库存储的数据结构单一,只能存储结构化的数据,对于非结构化数据的存储需求,以及存储成本是数据仓库的主要问题,而非结构化数据存储在业务库,也造成数据不能相融和利用,为了解决非结构化数据的低成本的存储诞生了湖仓一体的技术架构。 湖仓一体的技术架构是指将数据湖(Data Lake)和数据仓库(Data Warehouse)结合在一起,实现对各
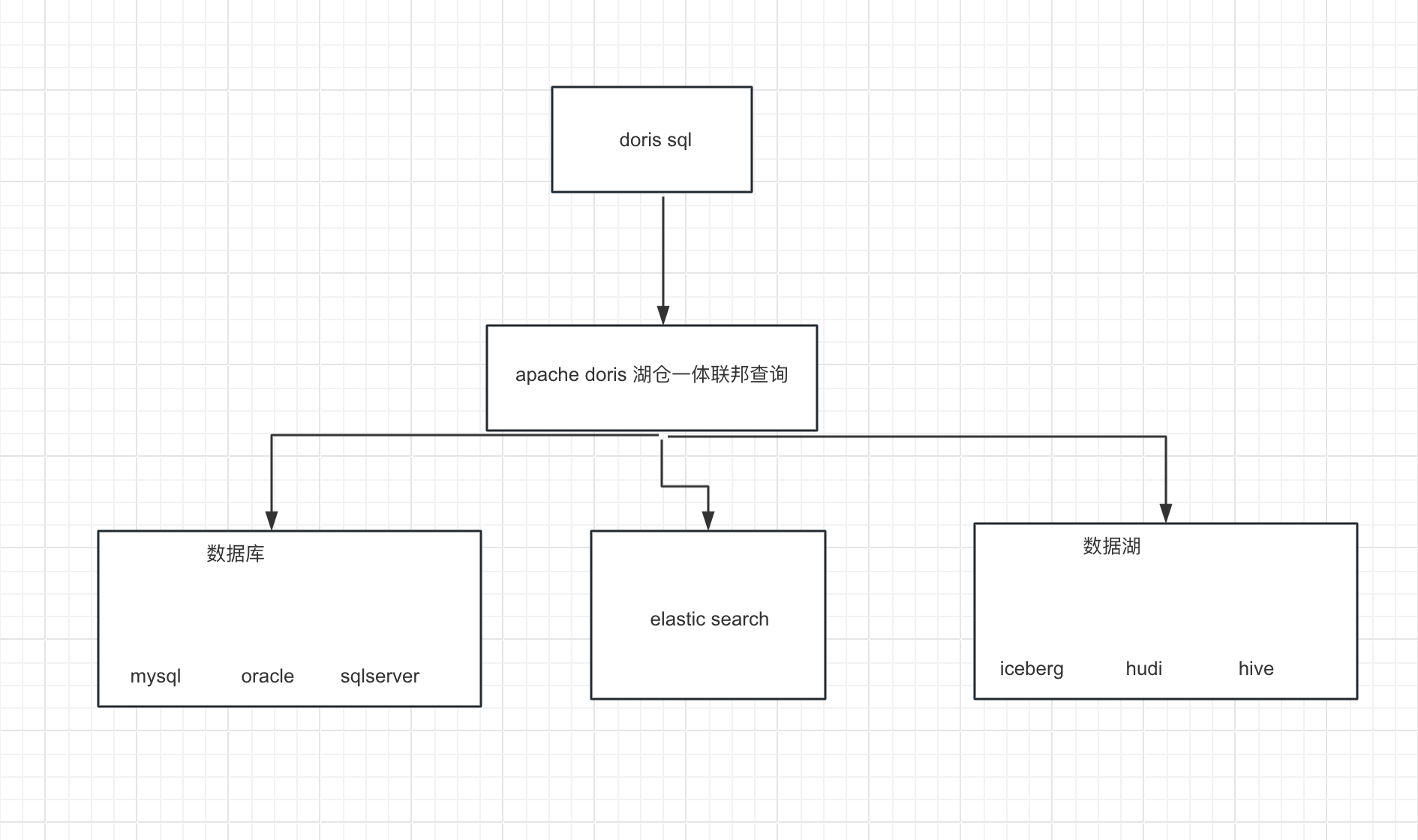
Apache Doris 整合 FLINK CDC + Iceberg 构建实时湖仓一体的联邦查询
1概况 本文展示如何使用 Flink CDC + Iceberg + Doris 构建实时湖仓一体的联邦查询分析,Doris 1.1版本提供了Iceberg的支持,本文主要展示Doris和Iceberg怎么使用,大家按照步骤可以一步步完成。完整体验整个搭建操作的过程。 2系统架构 我们整理架构图如下, 1.首先我们从Mysql数据中使用Flink 通过 Binlog完成数据的实时采集

使用 Paimon + StarRocks 极速批流一体湖仓分析
摘要:本文整理自阿里云智能高级开发工程师王日宇,在 Flink Forward Asia 2023 流式湖仓(二)专场的分享。本篇内容主要分为以下四部分: StarRocks+Paimon 湖仓分析的发展历程使用 StarRocks+Paimon 进行湖仓分析主要场景和技术原理StarRocks+Paimon 湖仓分析能力的性能测试StarRocks+Paimon 湖仓分析能力的未来规划
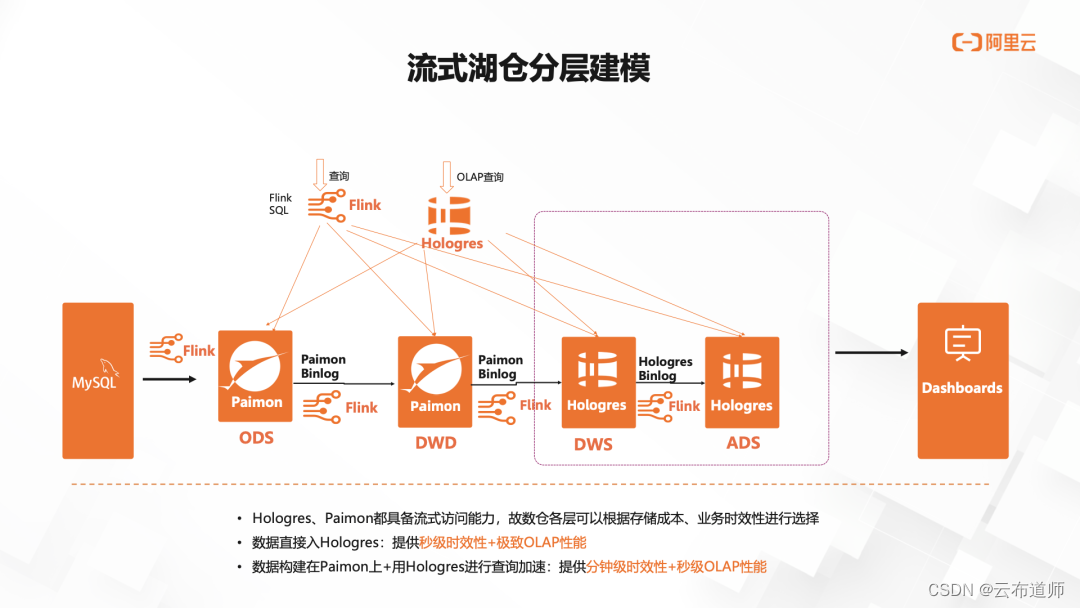
流式湖仓增强,Hologres + Flink构建企业级实时数仓
云布道师 2023 年 12 月,由阿里云主办的实时计算闭门会在北京举行,阿里云实时数仓Hologres 研发负责人姜伟华现场分享 Hologres+Flink 构建的企业级实时数仓,实现全链路的数据实时计算、实时写入、实时更新、实时查询。同时,随着流式湖仓的兴起,Hologres 除了支持 Delta、Hudi 等通用湖格式,在今年新增了对 Paimon 的深度集成,不断拓展湖仓一体能力。
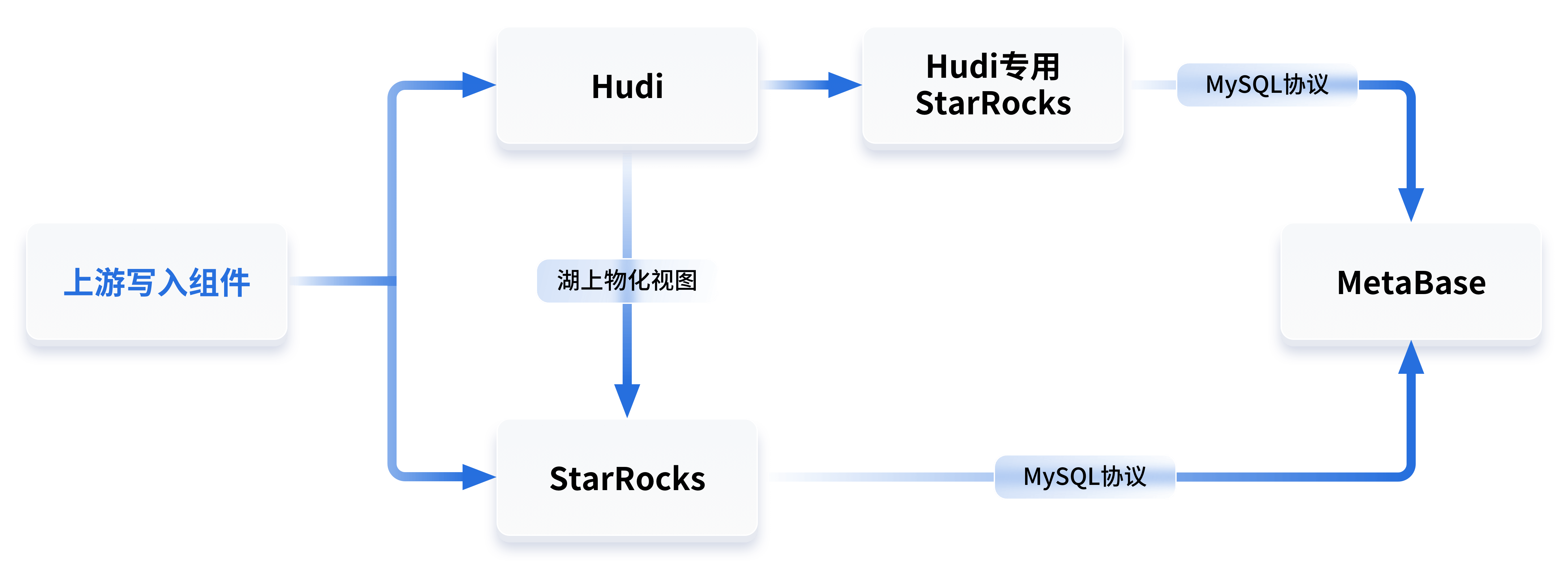
白山云基于StarRocks数据库构建湖仓一体数仓的实践
背景 随着每天万亿级别的业务数据流向数据湖,数据湖的弊端也逐渐凸显出来,例如: 数据入湖时效性差:数据湖主要依赖于离线批量计算,通常不支持实时数据更新,因此无法保证数据的强一致性,造成数据不及时、不准确;查询性能差:在传统架构下,数据湖的查询速度较差,小时粒度的数据查询往往需要数分钟才能得到响应,在多个业务方同时执行数据湖查询任务时,查询响应慢的劣势更加明显;查询体验差:数据存储在多个地方,在
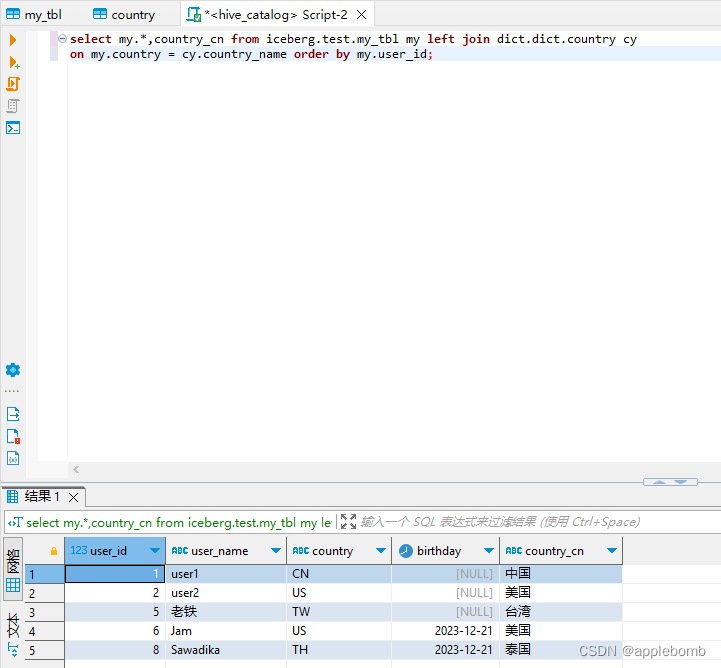
【湖仓一体尝试】MYSQL和HIVE数据联合查询
爬了两天大大小小的一堆坑,今天把一个简单的单机环境的流程走通了,记录一笔。 先来个完工环境照: mysql+hadoop+hive+flink+iceberg+trino 得益于IBM OPENJ9的优化,完全启动后的内存占用: 1)执行联合查询后的 2)其中trino由于必须使用ORACLE或OPENJDK,只能再安装多一个JDK21的环境 HIVE里ICEBERG的

数智金融技术峰会|数新网络受邀分享《金融信创湖仓一体数据平台架构实践》,敬请期待
12月23日,数新网络参加DataFunSummit 2023:数智金融技术峰会。会上,数新CTO原攀峰将为大家带来《金融信创湖仓一体数据平台架构实践》 主题分享。 本次峰会由DataFun联合火山引擎、蓝驰等知名企业举办,将共同为大家带来一场数智金融盛会,一起探讨数智金融技术在金融领域的落地进展及最新技术应用,领略金融科技的别样风景,欢迎小伙伴们扫码免费报名收看~ 此次演讲,原攀峰将深入
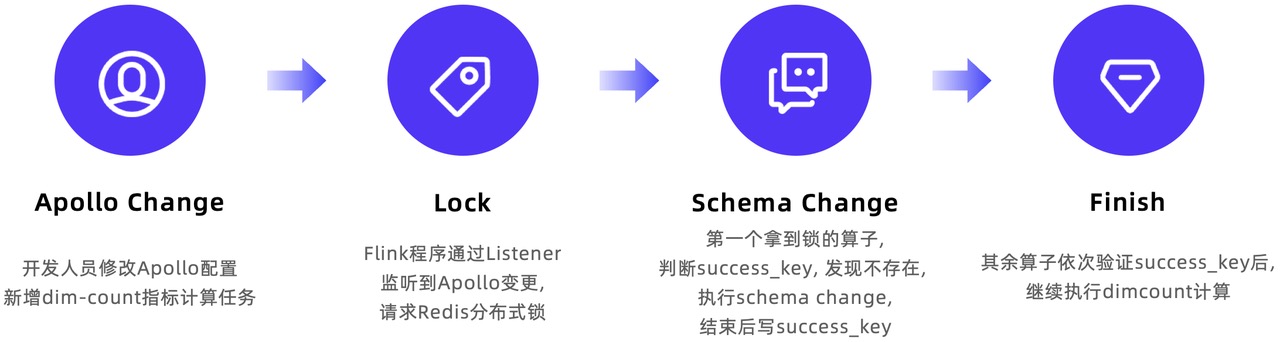
Apache Doris 在某工商信息商业查询平台的湖仓一体建设实践
本文导读: 信息服务行业可以提供多样化、便捷、高效、安全的信息化服务,为个人及商业决策提供了重要支撑与参考。本文以某工商信息商业查询平台为例,介绍其从传统 Lambda 架构到基于 Doris Multi-Catalog 的湖仓一体架构演进历程。同时通过一系列实践,展示了如何保证数据的准确性和实时性,以及如何高效地处理和分析大规模数据,为信息服务行业提供了有价值的参考思路,有助于推动整个行业的发
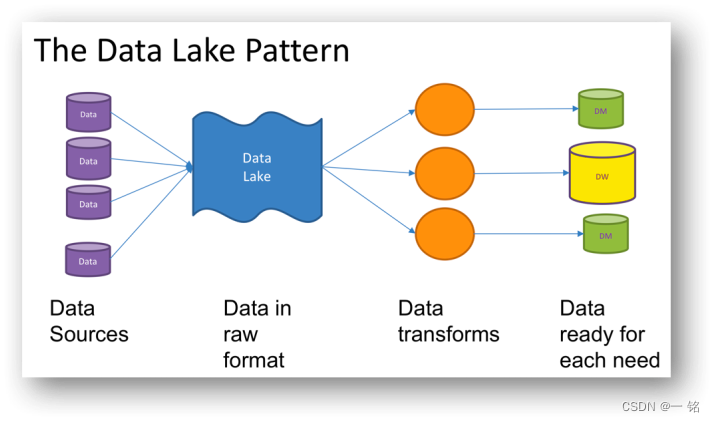
如何选择: 数据仓库(Data Warehouse),数据湖(Data Lake),数据湖仓(Data Lakehouse)
前言 databricks公司推出delta lake后,又推出了Data Lakehouse。该产品结合了数据仓库和数据湖的优势。本文介绍了数据仓库,数据库,数据湖仓的特点和使用场景,避免在使用时产生混淆。 1.什么是数据仓库 数据仓库是一个统一的数据存储库,用于存储一个组织内多个来源的大量信息。数据仓库代表了一个组织中 "数据真相 "的单一来源,并作为一个核心报告和业务分析组件。

湖仓一体平台构建实践 (基于 Iceberg )
1 背景 0) 数据管理架构演进 1)数据仓库(1990) 从数据仓库架构图可以看出,数据仓库的主要功能,是将企业信息化管理系统中联机事务处理所积累的大量数据,通过数据仓库特有的信息存储架构,系统化分析整理,进而支持如决策支持系统、主管资讯系统的创建,帮助决策者快速有效的从大量数据中分析出有价值的信息,以利于后期决策拟定及对外在环境变化的快速回应,帮助其构建商业智能。

你一定爱读的极简数据平台史,从数据仓库、数据湖到湖仓一体
1. 写在前面 我们身处一个大数据时代,企业的数据量爆炸式增长。如何应对海量数据存储和处理的挑战,建设好数据平台,对一个企业来说是很关键的问题。从数据仓库、数据湖,到现在的湖仓一体,业界建设数据平台的新方法和新技术层出不穷。 理解这些方法和技术背后隐藏的演进脉路、关键问题、核心技术原理,可以帮助企业更好地建设数据平台。这也是百度智能云推出数据湖系列内容的初衷。 本系列文章将包含几个部分:

直播预约丨《实时湖仓实践五讲》第三讲:实时湖仓在袋鼠云的落地实践之路
如今,大规模、高时效、智能化数据处理已是“刚需”,企业需要更强大的数据平台,来应对数据查询、数据处理、数据挖掘、数据展示以及多种计算模型并行的挑战,湖仓一体方案应运而生。 《实时湖仓实践五讲》是袋鼠云打造的系列直播活动,将围绕实时湖仓的建设趋势和通用问题,邀请奋战于企业数字化一线的核心产品&技术专家,结合实践案例分析,和听众共同探讨实时湖仓领域的前沿技术。 《实时湖仓实践五讲》第三讲——《实时
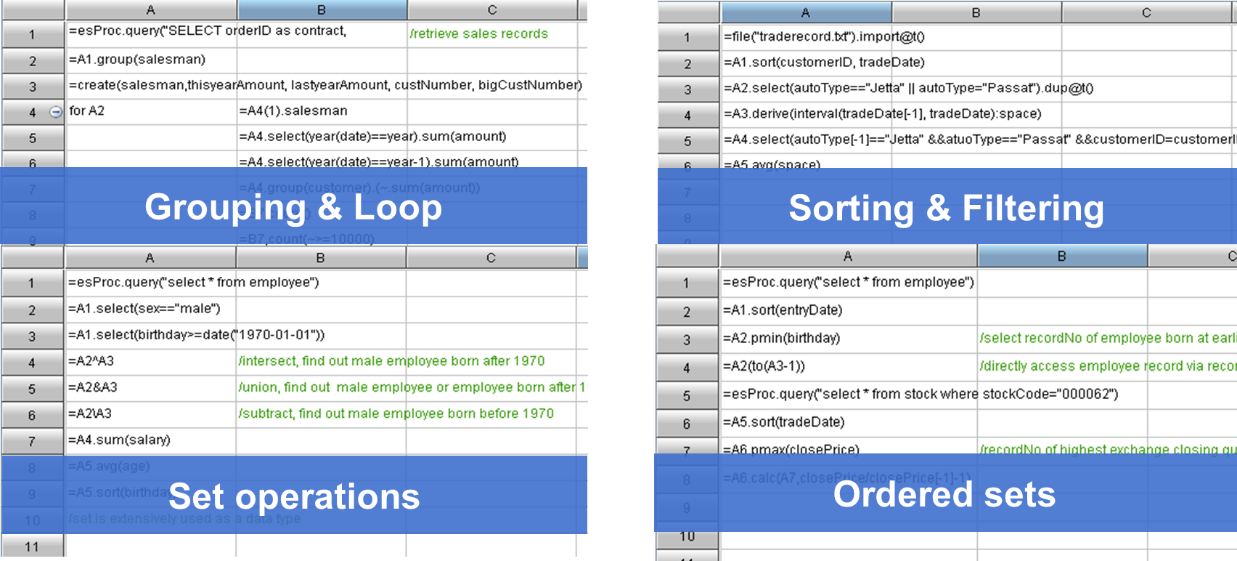
现在的湖仓一体像是个伪命题
文章目录 开放的计算引擎SPL助力湖仓一体开放且完善的计算能力多数据源混合计算文件计算支持完善的计算能力直接访问源数据 数据整理后的高性能计算 SPL资料 从一体机、超融合到云计算、HTAP,我们不断尝试将多种应用场景融合在一起并试图通过一种技术来解决一类问题,借以达到使用简单高效的目标。现在很热的湖仓一体(Lakehouse)也一样,如果能将数据湖和数据仓库融合在一起就可以同时发
MaxCompute湖仓一体介绍
正文: 本篇内容将通过两个部分来介绍MaxCompute湖仓一体。 一、什么是 MaxCompute 湖仓一体 二、湖仓一体成功案例介绍 一、什么是 MaxCompute 湖仓一体 湖仓一体的整体架构,主要面向数据分析师,数据科学家以及大数据工程师来使用。主要应用的业务有Machine,非结构化数据分析,Ad-hoc/BI,Reporting和Learning等等。在整体架构中,Dat

有湖有仓,如何升级到湖仓一体
很多企业在过去的 IT 基础建设过程中,都已经搭建了数据仓库或数据湖,或者两者都有。其中数据仓库一般使用的是传统 Oracle 或者传统 MPP 数据库,如 Teradata 和 Greenplum,数据湖使用 Hadoop 大数据平台。所以在考虑湖仓一体升级改造时,就会有一个疑问——假如企业既有数据湖又有数据仓库,该选择基于湖还是仓进行湖仓一体的升级改造呢? 讨论通过湖或者仓进行湖仓一体升级,
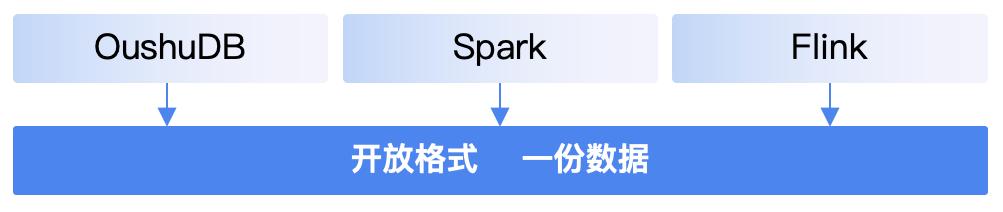
大模型、实时需求推动湖仓平台走向开放
大模型、实时需求高涨 AGI 时代,以 ChatGPT、Midjourney 等为代表的大模型迅速应用加速了 AI 普及,越来越多的企业选择搭建自己的 AI 基础设施,训练行业大模型。 另一方面,企业为了在瞬息万变的市场环境中更快的做出商业决策,正在将数据平台从离线转向实时数据平台。“双十一 ”和春晚直播实时大屏、银行和证券交易行为实时监控、电商和短视频的实时个性化推荐等只是全行业在线
