本文主要是介绍如何选择: 数据仓库(Data Warehouse),数据湖(Data Lake),数据湖仓(Data Lakehouse),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言
databricks公司推出delta lake后,又推出了Data Lakehouse。该产品结合了数据仓库和数据湖的优势。本文介绍了数据仓库,数据库,数据湖仓的特点和使用场景,避免在使用时产生混淆。
1.什么是数据仓库
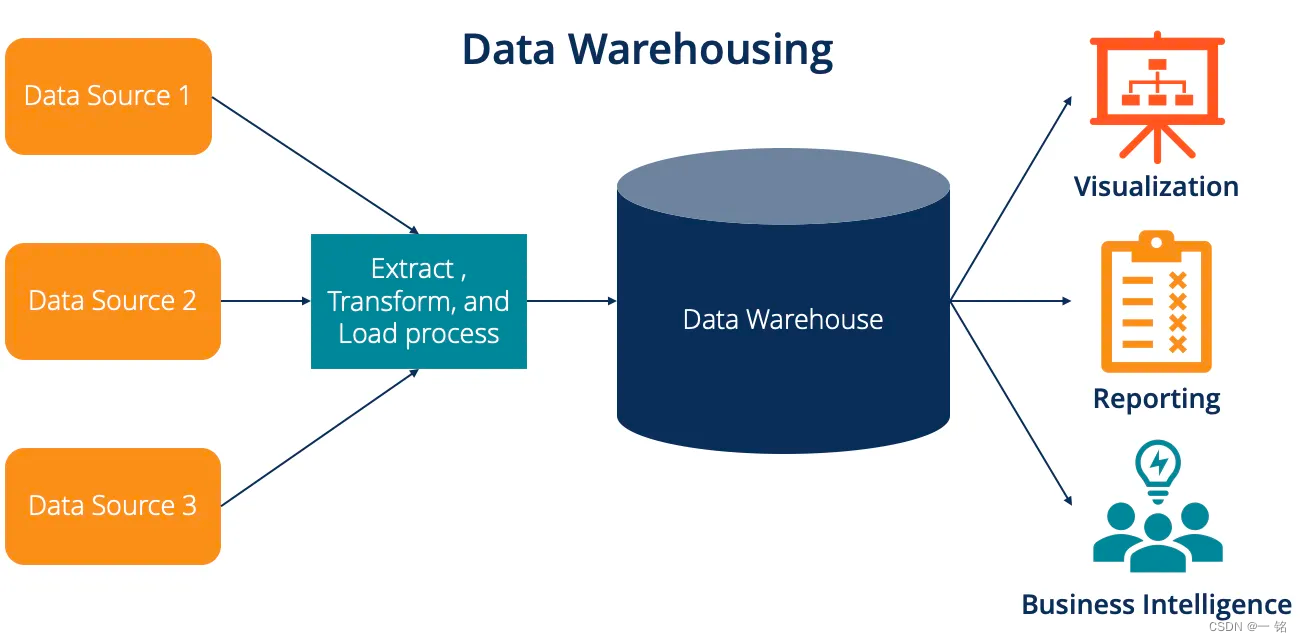
数据仓库是一个统一的数据存储库,用于存储一个组织内多个来源的大量信息。数据仓库代表了一个组织中 "数据真相 "的单一来源,并作为一个核心报告和业务分析组件。
通常,数据仓库通过组合来自多个来源(包括应用程序、业务和交易数据)的关系数据集来存储历史数据。数据仓库从多个来源提取数据,并在将数据加载到仓储系统之前对其进行转换和清理,以作为数据真实性的单一来源。组织投资数据仓库是因为它们能够快速提供来自整个组织的业务洞察力。
数据仓库使业务分析师、数据工程师和决策者能够通过 BI 工具、SQL 客户端和其他不太高级(即非数据科学)的分析应用程序访问数据。
1.1 数据仓库的优势
实施数据仓库后,可为组织提供巨大的优势。包括:
(1)提高数据标准化、质量和一致性:组织从各种来源生成数据,包括销售、用户和交易数据。数据仓库将企业数据整合为一致的标准化格式,可以作为数据真实性的单一来源,使组织有信心依靠数据来满足业务需求。
(2)提供增强的商业智能:数据仓库弥合了大量原始数据(通常作为实践自动收集)与提供洞察力的精选数据之间的差距。它们充当组织的数据存储骨干,使他们能够回答有关其数据的复杂问题,并使用这些答案做出明智的业务决策。
(3)提高数据分析和商业智能工作负载的能力和速度:数据仓库加快了准备和分析数据所需的时间。由于数据仓库的数据一致且准确,因此它们可以毫不费力地连接到数据分析和商业智能工具。数据仓库还减少了收集数据所需的时间,并使团队能够利用数据来满足报告、仪表板和其他分析需求。
(4)改进整体决策过程:数据仓库通过提供当前和历史数据的单一存储库来改进决策。决策者可以通过转换数据仓库中的数据以获得准确的洞察力来评估风险、了解客户的需求并改进产品和服务。
1.2 数据仓库的缺点
数据仓库为企业提供了高性能和可扩展的分析能力。然而,它们带来了具体的挑战,其中包括:
- 缺少数据灵活性。
尽管数据仓库在处理结构化数据时表现良好,但在处理半结构化和非结构化的数据格式时,如日志分析、流媒体和社交媒体数据时,它们会遇到困难。这使得我们很难推荐数据仓库用于机器学习和人工智能的场景。
- 实施和维护成本高。
数据仓库的实施和维护成本很高。Cooladata的这篇文章估计,一个拥有一兆字节存储和每月10万次查询的内部数据仓库的年度成本为468,000美元。此外,数据仓库通常不是静态的;它变得过时,需要定期维护,这可能是昂贵的。
2. 什么是数据湖(Data Lake)
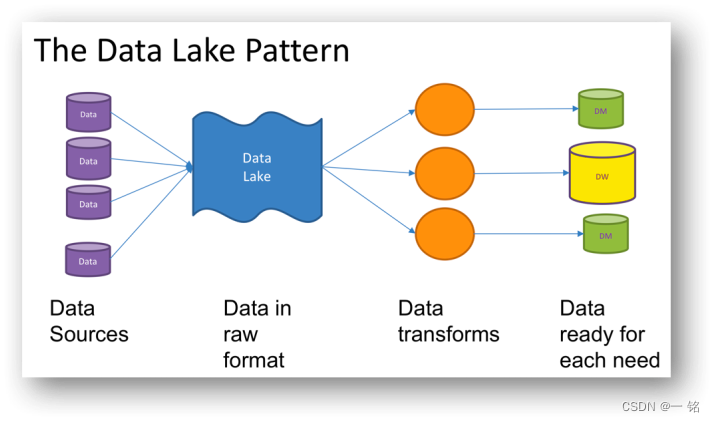
数据湖是一个集中的、高度灵活的存储库,它以原始的、原生态的、未格式化的形式存储大量的结构化和非结构化数据。与存储已经 "清理 "过的关系型数据的数据仓库相比,数据湖使用扁平架构和原始形式的对象存储来存储数据。数据湖是灵活的、持久的和具有成本效益的,使企业能够从非结构化的数据中获得先进的洞察力,而不像数据仓库那样在这种格式的数据中挣扎。
在数据湖中,模式或数据在捕获数据时并没有被定义;相反,数据被提取、加载和转换(ELT)用于分析目的。数据湖允许使用来自物联网设备、社交媒体和流媒体数据的各种数据类型的工具进行机器学习和预测性分析。
2.1 数据湖的优势
因为数据湖可以存储结构化和非结构化的数据,所以它们有几个好处,例如。
- 数据整合:数据湖可以同时存储结构化和非结构化的数据,以消除在不同环境中存储两种数据格式的需要。它们提供了一个中央存储库来存储所有类型的组织数据。
- 数据的灵活性:数据湖的一个重要好处是其灵活性;你可以以任何格式或介质存储数据,而不需要有预定义的模式。允许数据保持其原始格式,可以为分析提供更多的数据,并迎合未来的数据使用情况。
- 节省成本:数据湖比传统的数据仓库更便宜;它们被设计为存储在低成本的商品硬件上,如对象存储,通常被优化为每GB存储成本更低。例如,Amazon S3标准对象存储提供了令人难以置信的低价,前50TB/月每GB为0.023美元。
- 支持各种各样的数据科学和机器学习用例:数据湖中的数据以开放的原始格式存储,使其更容易应用各种机器和深度学习算法来处理数据,以产生有意义的洞察力。
2.2 数据湖的缺点
虽然数据湖提供了相当多的好处,但它们也带来了挑战。
- 商业智能和数据分析用例的性能不佳:如果管理不善,数据湖会变得杂乱无章,难以与商业智能和分析工具连接。另外,如果缺乏一致的数据结构和ACID(原子性、一致性、隔离性和持久性)交易支持,在报告和分析用例需要时,会导致查询性能不理想。
- 缺少数据的可靠性和安全性:数据湖缺乏数据的一致性,因此很难执行数据的可靠性和安全性。由于数据湖可以容纳所有的数据格式,实施适当的数据安全和治理政策以满足敏感数据类型可能是一个挑战。
3. 什么是湖仓一体(Data Lakehouse)?一个合并的方案
数据湖仓是一种新的大数据存储架构,它结合了数据仓库和数据湖的最佳功能。数据湖库可以为你的所有数据(结构化、半结构化和非结构化)提供一个单一的存储库,同时实现一流的机器学习、商业智能和流媒体能力。
数据湖仓通常以包含所有数据类型的数据湖开始;然后将数据转换为Delta湖格式(一种开源的存储层,为数据湖带来可靠性)。Delta湖实现了传统数据仓库在数据湖上的ACID交易过程。
3.1 Data Lakehouse的优势
数据湖仓架构将数据仓库的数据结构和管理功能与数据湖的低成本存储和灵活性相结合。这种实施的好处是巨大的,包括。
- 减少了数据的冗余:数据湖库通过提供一个单一的多用途数据存储平台来满足所有业务数据的需求,从而减少数据的重复性。由于数据仓库和数据湖的优势,大多数公司选择了混合解决方案。然而,这种方法可能会导致数据的重复,这可能是昂贵的。
- 成本效益:数据湖库通过利用低成本的对象存储选项来实现数据湖的成本效益的存储功能。此外,数据湖馆通过提供一个单一的解决方案,消除了维护多个数据存储系统的成本和时间。
- 支持更多种类的工作负载:数据湖库提供对一些最广泛使用的商业智能工具(Tableau、PowerBI)的直接访问,以实现高级分析。此外,数据湖库使用开放的数据格式(如Parquet)与API和机器学习库,包括Python/R,使得数据科学家和机器学习工程师能够直接利用数据。
- 易于数据版本管理、治理和安全:数据湖库架构强制执行模式和数据完整性,使其更容易实施强大的数据安全和治理机制。
3.2 Data Lakehouse的缺点
数据湖仓的主要缺点是:它仍然是一个相对较新和不成熟的技术。因此,目前还不清楚它是否能实现其承诺的功能。在数据湖仓能够与成熟的大数据存储解决方案竞争之前,可能还需要几年时间。但以目前现代创新的速度,很难预测新的数据存储解决方案是否能最终取代它。
4. 数据仓库vs.数据湖vs.数据湖仓 对比
数据仓库是最古老的大数据存储技术,在商业智能、报告和分析应用中有着悠久的历史。然而,数据仓库是昂贵的,并且在处理非结构化数据(如流媒体和具有多样性的数据)时很困难。
数据湖的出现是为了在廉价的存储上处理各种格式的原始数据,用于机器学习和数据科学工作负载。虽然数据湖能很好地处理非结构化数据,但它们缺乏数据仓库的ACID交易功能,难以确保数据的一致性和可靠性。
数据湖是最新的数据存储架构,结合了数据湖的成本效益和灵活性以及数据仓库的可靠性和一致性。
本表总结了数据仓库与数据湖与数据湖室之间的区别。
| Data Warehouse | Data Lake | Data Lakehouse | |
| 存储数据类型 (Storage Data Type) | 结构化数据 | 半结构化,非结构化 | 结构化,半结构化,非结构化 |
| 用途 (Purpose) | 最适合数据分析和商业智能(BI)的使用情况 | 适用于机器学习(ML)和人工智能(AI) | 适用于数据分析和机器学习 |
| 消耗 (Cost) | 储存成本高,耗时长 | 存储具有成本效益,快速和灵活 | 存储具有成本效益,快速和灵活 |
| ACID兼容性 (ACID Compliance) | 以符合ACID标准的方式记录数据,以确保最高水平的完整性 | 不符合ACID标准:更新和删除是复杂的操作 | 符合ACID标准,在多方同时读取或写入数据时确保一致性 |
"数据湖仓与数据仓库与数据湖 "仍然是一个持续的对话。选择哪种大数据存储架构最终将取决于你所处理的数据类型、数据源以及利益相关者将如何使用这些数据。
尽管Data Lakehouse结合了数据仓库和数据湖的所有优点,但不建议为了数据湖仓而把现有的数据存储技术排除在外。
5. 如何选择:Data Warehouse vs. Data Lake vs. Data Lakehouse?
从头开始建立Data Lakehouse可能很复杂。而且你很可能会使用一个为支持开放Data Lakehouse架构而建立的平台。因此,确保你在购买之前研究每个平台的不同能力和实施工作。
对于寻求成熟的、结构化的数据解决方案的公司来说,数据仓库是一个不错的选择,它侧重于商业智能和数据分析用例。然而,数据湖适用于寻求灵活、低成本的大数据解决方案的组织,以驱动非结构化数据的机器学习和数据科学的场景。
假设数据仓库和数据湖的方法不能满足你公司的数据需求,或者你正在寻找在数据上同时实施高级分析和机器学习工作场景的方法。在这种情况下,Data Lakehouse是一个合理的选择。
6. 总结
- Data Lakehouse是数据仓库和数据湖的结合体,主要是为了解决结构化和半结构化数据的存储与处理的问题。
- Data Lakehouse为了让数据科学和机器学习的工作变得更加简单。
- 在具体选择哪种存储方案之前,需要仔细分析自己的应用场景,不要为了使用Data Lakehouse而使用。
- Data Lakehouse的架构相对比较复杂,从头开始建立的话代价可能比较高。
- Data Lakehouse目前还处在不太成熟的状态,还需要一些时间来进一步的发展。
参考文档:
- data-warehouse-vs-data-lake-vs-data-lakehouse-an-overview
这篇关于如何选择: 数据仓库(Data Warehouse),数据湖(Data Lake),数据湖仓(Data Lakehouse)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







