数据仓库专题


数据仓库: 6- 数据仓库分层
目录 6- 数据仓库分层6.1 简介6.1.1 数据仓库分层的优势6.1.2 常见的数据仓库分层模型6.1.2.1 四层模型6.1.2.2 三层模型 6.1.3 数据仓库分层原则6.1.4 数据仓库分层示例6.1.5 总结 6.2 ODS(操作数据存储)层6.2.1 ODS 层的主要功能6.2.2 ODS 层的特点6.2.3 ODS 层的设计要点6.2.4 ODS 层的应用场景6.2.5 总

数据仓库系统的实现与使用(含OLAP重点讲解)
系列文章: 《一文了解数据库和数据仓库》 《DB数据同步到数据仓库的架构与实践》 《数据湖(Data Lake)-剑指下一代数据仓库》 《从0建设离线数据仓库》 《基于Flink构建实时数据仓库》 阅读目录 前言创建数据仓库ETL:抽取、转换、加载OLAP/BI工具数据立方体(Data Cube)OLAP的架构模式小结 前言 数据仓库是数据仓库开发中最核心的部分。然而完整的数据仓库系统还会涉及

【数据产品案例】有赞大数据实践- 敏捷型数据仓库的构建及其应用
案例来源:@洪斌 案例地址: https://tech.youzan.com/you-zan-big-data-practice/ 1. 数据仓库处理:近源数据层→数据宽表→基础指标表 1)近源数据层:封装中间层,实现: a. 合并不同业务数据,如pc和app的日志数据 b. 脏数据屏蔽 c. 冗余字段合并 2)数据宽表:提取足够
一文说清什么是数据仓库
01 数据仓库的概念 数据仓库的概念可以追溯到20世纪80年代,当时IBM的研究人员开发出了“商业数据仓库”。本质上,数据仓库试图提供一种从操作型系统到决策支持环境的数据流架构模型。 目前对数据仓库(Data Warehouse)的标准定义,业界普遍比较认可的是由数据仓库之父比尔·恩门(Bill Inmon)在1991年出版的“Building the Data Warehouse”(

计算机毕业设计Hadoop+PySpark共享单车预测系统 PyHive 共享单车数据分析可视化大屏 共享单车爬虫 共享单车数据仓库 机器学习 深度学习
《Hadoop共享单车分析与预测系统》开题报告 一、课题背景与意义 1.1 课题背景 随着共享经济的快速发展,共享单车作为一种新型绿色环保的共享经济模式,在全球范围内迅速普及。共享单车通过提供便捷的短途出行服务,有效解决了城市居民出行的“最后一公里”问题,同时促进了低碳环保和绿色出行理念的推广。然而,随着共享单车数量的急剧增加,如何高效管理和优化单车布局成为共享单车运营商面临的重要挑战。

计算机毕业设计PyHive+Hadoop深圳共享单车预测系统 共享单车数据分析可视化大屏 共享单车爬虫 共享单车数据仓库 机器学习 深度学习 PySpark
毕业设计题目基于 Hadoop 的共享单车布局规划 二、毕业设计背景 公共交通工具的“最后一公里”是城市居民出行采用公共交通出行的主要障碍,也是建设绿色城市、低碳城市过程中面临的主要挑战。 共享单车(自行车)企业通过在校园、地铁站点、公交站点、居民区、商业区、公共服务区等提供服务,完成交通行业最后一块“拼图”,带动居民使用其他公共交通工具的热情,也与其他公共交通方式产生协同效应。 共享单车是

数据仓库系列19:数据血缘分析在数据仓库中有什么应用?
你是否曾经在复杂的数据仓库中迷失方向,不知道某个数据是从哪里来的,又会流向何方?或者在处理数据质量问题时,无法快速定位根源?如果是这样,那么数据血缘分析将会成为你的得力助手,帮助你在数据的海洋中找到明确的航向。 目录 引言:数据血缘分析的魔力什么是数据血缘分析?数据血缘的核心概念 数据血缘分析在数据仓库中的应用1. 数据质量管理实际应用案例 2. 影响分析实际应用案例 3. 合规性和审计

浅谈维度建模、数据分析模型,何为数据仓库,与数据库的区别
往期推荐 大数据HBase图文简介-CSDN博客 数仓分层ODS、DWD、DWM、DWS、DIM、DM、ADS-CSDN博客 数仓常见名词解析和名词之间的关系-CSDN博客 数仓架构:离线数仓、实时数仓Lambda和Kappa、湖仓一体数据湖-CSDN博客 0. 前言 1991年,数据仓库之父 比尔·恩门 著书《Building the DataWarehouse》,要求构建数据仓

数据仓库系列17:元数据管理在数据仓库中的作用是什么?
想象一下,你正在管理一个巨大的图书馆,里面存放着数以万计的书籍。但是,这个图书馆没有任何目录、索引或分类系统。你能想象找到特定的一本书会有多困难吗?这就是没有元数据管理的数据仓库的真实写照。 目录 什么是元数据?元数据管理的重要性元数据在数据仓库中的类型1. 技术元数据2. 业务元数据3. 操作元数据 元数据管理的核心功能1. 数据目录2. 数据血缘分析3. 数据质量管理4. 数据版本控制

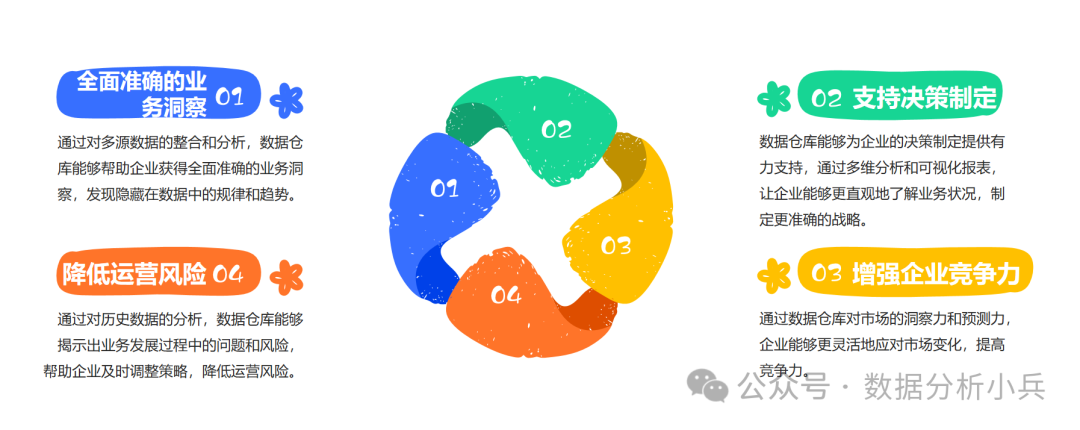
明白什么是数据仓库了,浅浅的了解一下数据仓库的目标,数据仓库的价值!
文章目录 存在的问题业务对数据仓库的需求数据仓库存在的价值 数据库相信在坐的各位耳熟能详,但数据仓库却一知半解,在日常工作中很多小伙伴都听过数据仓库这个部门和名词,但大部分的人对为什么会有数据仓库,以及数据仓库的作用是什么还一脸问号。那今天我们就日常遇到的话题中来浅浅的来理解下什么是数据仓库。 存在的问题 当在一定的体量企业工作后,总会遇到这样的话题: 我们需要从


HIVE 数据仓库工具之第二部分(数据库相关操作)
HIVE 数据仓库工具之第二部分(数据库相关操作) 一、Hive 对数据库的操作1.1 创建数据库1.1.1 创建数据库语法1.1.3 示例 1.2 使用数据库1.2.1 使用数据库语法1.2.2 示例 1.3 修改数据库1.3.1 修改数据库的语法1.3.2 示例 1.4 删除数据库1.4.1 删除数据库的语法1.4.2 示例 二、Hive 对数据表的操作2.1 创建表2.1.1 第一种
数据仓库系列15:数据集成的常见挑战有哪些,如何应对?
在大数据时代,数据集成已成为数据仓库建设中不可或缺的一部分。无论是来自多个数据库、外部数据源,还是实时数据流的整合,数据集成都面临着诸多挑战。那么,这些挑战具体是什么,我们又该如何应对呢?本文将通过具体的案例与逻辑深入探讨这个问题。 目录 1. 什么是数据集成?2. 数据集成的常见挑战2.1 数据源的多样性2.2 数据质量问题2.3 数据延迟2.4 数据安全与隐私2.5 系统性能 3.

数据仓库系列13:增量更新和全量更新有什么区别,如何选择?
你是否曾经在深夜加班时,面对着庞大的数据仓库,思考过这样一个问题:“我应该选择增量更新还是全量更新?” 这个看似简单的选择,却可能影响整个数据处理的效率和准确性。今天,让我们深入探讨这个数据仓库领域的核心问题,揭示增量更新和全量更新的秘密,帮助你在实际工作中做出明智的选择。 目录 引言:数据更新的重要性增量更新vs全量更新:基本概念增量更新的优势与挑战优势挑战示例:增量更新实现 全量更新的

从 7000 余项目脱颖而出,飞轮科技《新一代实时分析数据仓库解决方案》荣获 HICOOL 2024 全球创业大赛二等奖
HICOOL 2024 全球创业者峰会于 2024 年 8 月 23 日 -25 日 在中国国际展览中心(顺义馆)成功举行,峰会以“新质引领 创新共融”为主题,聚焦技术创新、产业融合、新质共享与国际合作四大要素。 在 8 月 23 日晚的峰会开幕式上,举行 HICOOL 2024 全球创业大赛颁奖盛典,共颁发一等奖 12 个、二等奖 36 个、三等奖 68 个、优胜奖 84 个。北京飞轮数据科技

构建数据仓库的基本步骤
确定主题 确定数据分析的主题.eg:分析某年某月某地区的各种啤酒销售情况. 主题要体现出某一方面的各个分析维度和统计量度之间的关系.确定度量 度量是分析的技术指标,一般为数值型数据.eg:某地区某派出某粒度所发生的警情积分值确定分析粒度 采用”最小粒度原则”来满足度量的不同聚合程度.eg:将时间粒度精确到秒可以满足小时,天,周….等不同粒度的度量值确定维度表 分析主题的各个维度.eg:主

数据仓库中缓慢变化维的总结
此文转载地址 关于数据仓库中缓慢变化维的总结 首先说一下概念,缓慢变化维(Slowly Changing Dimensions)指的是:维度表里面的数据并非是始终不变的,总会随着时间发生变化: 假设我们有一张我们公司的销售员维度表如下,记录了每个销售员的一些基本信息,那么随着时间的变化销售员可能会在各省公司间调岗,如将周杰伦调入北京分公司,针对这种变化,业务系统会直接将业务数据库中周杰

【数据仓库/数据治理】探索数据处理的两大类:OLTP与OLAP及其核心技术
在现代数据处理的世界中,数据的管理和分析是商业和技术决策的关键。为满足不同的业务需求,数据处理大致分为两大类:联机事务处理(OLTP) 和 联机分析处理(OLAP)。这两者分别适用于日常事务处理和复杂的分析操作,在数据管理中扮演着不同但互补的角色。 联机事务处理(OLTP):日常事务的基石 OLTP系统主要用于处理基本的、日常的事务操作,典型的例子包括银行交易、订单处理和库存管理等。这类系

HIVE 数据仓库工具之第一部分(讲解部署)
HIVE 数据仓库工具 一、Hive 概述1.1 Hive 是什么1.2 Hive 产生的背景1.3 Hive 优缺点1.3.1 Hive的优点1.3.2 Hive 的缺点 1.4 Hive在Hadoop生态系统中的位置1.5 Hive 和 Hadoop的关心 二、Hive 原理及架构2.1 Hive 的设计原理2.2 Hive 特点2.3 Hive的体现结构2.4 Hive的运行机制2.5

三个例子,让你看懂数据仓库多维数据模型的设计
一、概述 多维数据模型是最流行的数据仓库的数据模型,多维数据模型最典型的数据模式包括星型模式、雪花模式和事实星座模式,本文以实例方式展示三者的模式和区别。 二、星型模式(star schema) 星型模式的核心是一个大的中心表(事实表),一组小的附属表(维表)。星型模式示例如下所示: 三、雪花模式(snowflake schema) 雪花模式是星型模
数据仓库系列7:什么是概念模型、逻辑模型和物理模型,它们有什么区别?
你是否曾经困惑于数据仓库中的各种模型?概念模型、逻辑模型、物理模型 - 它们听起来很相似,但实际上各有千秋。 目录 引言:为什么模型如此重要?1. 概念模型:勾勒数据的蓝图什么是概念模型?概念模型的特点概念模型的例子概念模型的作用如何创建概念模型 2. 逻辑模型:细化你的数据结构什么是逻辑模型?逻辑模型的特点逻辑模型的例子逻辑模型的作用如何创建逻辑模型逻辑模型中的常见挑战 3. 物理模型

数据仓库系列6:数据仓库建模的主要步骤是什么?
你是否曾经面对海量的数据感到无所适从?你是否想知道那些运转良好的数据仓库背后究竟有什么秘密? 今天,让我们一起揭开数据仓库建模的神秘面纱,探索那些能够将杂乱无章的数据转化为有价值洞察的关键步骤! 目录 引言:数据仓库建模的重要性第一步:需求分析与规划为什么需求分析如此重要?如何进行有效的需求分析?需求分析文档示例 第二步:数据源识别与评估为什么数据源识别如此重要?数据源识别与评估的步骤数

数据仓库系列 2:数据仓库的核心特点是什么?
想象一下,你正站在一座巨大的数据金矿前。这座金矿蕴含着海量的商业洞察,可以帮助你的公司做出精准决策,提升效率,远超竞争对手。但是,如何高效地开采、提炼和利用这些数据黄金呢?答案就是:数据仓库。 目录 什么是数据仓库?数据仓库的核心特点面向主题的组织集成性非易失性时变性 数据仓库架构1. 数据源层2. 数据暂存区(Staging Area)3. ETL层4. 核心数据仓库5. 数据集市(Da
数据仓库: 4- 数据质量管理 5- 元数据管理
目录 4- 数据质量管理4.1 数据清洗4.1.1 数据清洗的重要性4.1.2 数据清洗常见的问题4.1.3 数据清洗的步骤4.1.3.1 数据质量评估:4.1.3.2 制定清洗规则:4.1.3.3 执行清洗操作:4.1.3.4 验证清洗结果:4.1.3.5 迭代优化: 4.1.4 数据清洗的常用方法4.1.5 数据清洗的最佳实践4.1.6 总结 4.2 数据一致性检查4.2.1 数据一致性

数据仓库建模的步骤-从需求分析到模型优化的全面指南
想象一下,你正站在一座巨大的图书馆前。这座图书馆里存放着你公司所有的数据。但是,书籍杂乱无章,没有分类,没有索引。你如何才能快速找到所需的信息?这就是数据仓库建模要解决的问题。本文将带你深入了解数据仓库建模的主要步骤,让你掌握如何将杂乱的数据转化为有序、高效、易用的信息宝库。 目录 什么是数据仓库建模?步骤一:需求分析关键活动:示例:电商公司需求分析需求分析的重要性 步骤二:数据源识别与分