本文主要是介绍数据仓库系列7:什么是概念模型、逻辑模型和物理模型,它们有什么区别?,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
你是否曾经困惑于数据仓库中的各种模型?概念模型、逻辑模型、物理模型 - 它们听起来很相似,但实际上各有千秋。

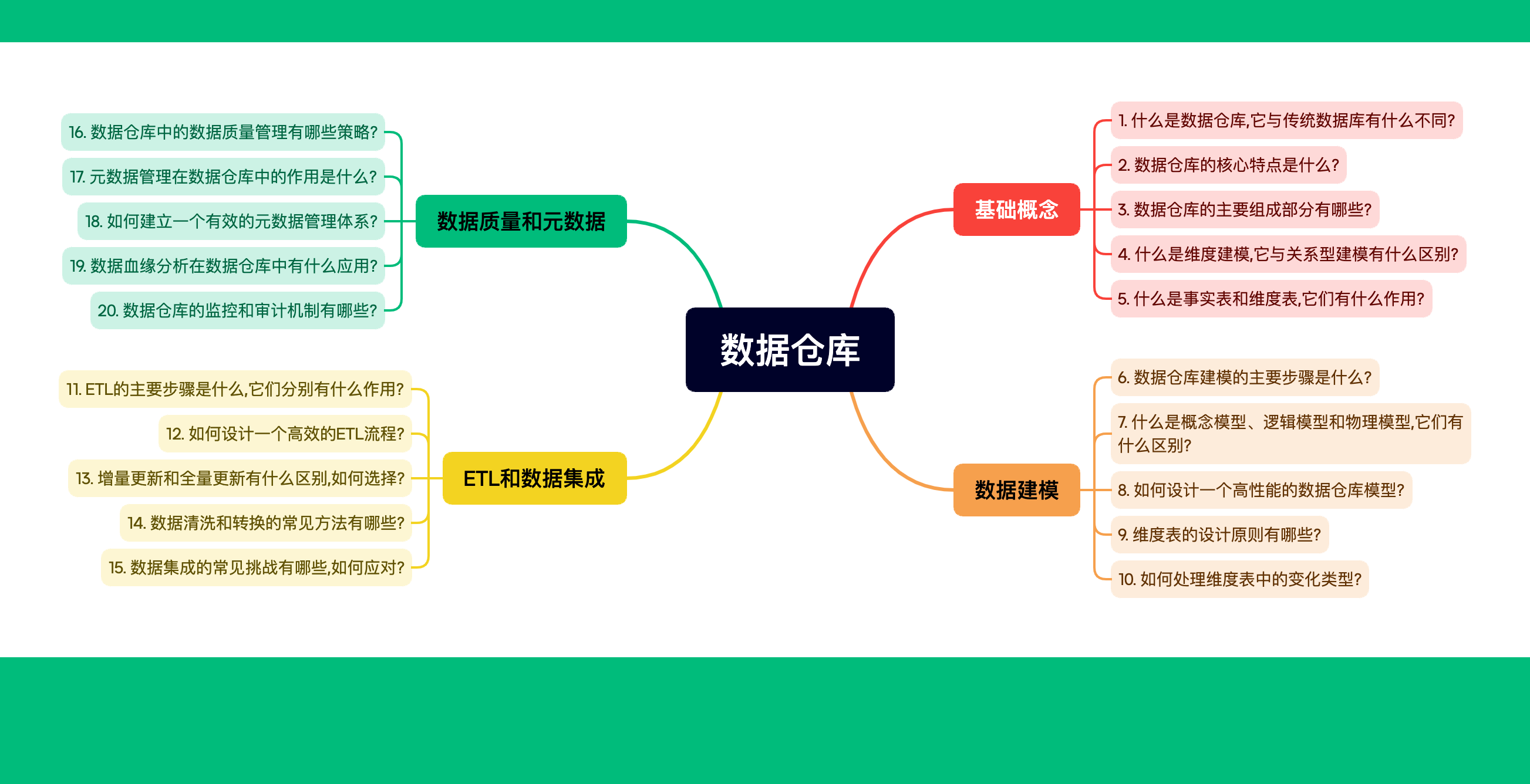
目录
- 引言:为什么模型如此重要?
- 1. 概念模型:勾勒数据的蓝图
- 什么是概念模型?
- 概念模型的特点
- 概念模型的例子
- 概念模型的作用
- 如何创建概念模型
- 2. 逻辑模型:细化你的数据结构
- 什么是逻辑模型?
- 逻辑模型的特点
- 逻辑模型的例子
- 逻辑模型的作用
- 如何创建逻辑模型
- 逻辑模型中的常见挑战
- 3. 物理模型:将设计落地为实际数据库
- 什么是物理模型?
- 物理模型的特点
- 物理模型的例子
- 物理模型的作用
- 如何创建物理模型
- 物理模型中的常见挑战
- 三种模型的比较
- 从概念到物理:模型转换的最佳实践
- 实际应用:电子商务数据仓库案例研究
- 阶段1:概念模型设计
- 阶段2:逻辑模型设计
- 阶段3:物理模型设计
- 从模型到实践:数据仓库实施的关键考虑因素
- 1. ETL流程设计
- 2. 数据质量管理
- 3. 性能优化
- 4. 安全性和访问控制
- 5. 元数据管理
- 结论:从概念到现实的数据仓库之旅
- 关键要点回顾
- 实践建议
- 结语
今天,让我们一起揭开这三大模型的神秘面纱,看看它们如何协同工作,为你的数据仓库搭建一个坚实的基础。

引言:为什么模型如此重要?
想象一下,你正在建造一座摩天大楼。你会直接开始浇筑混凝土吗?当然不会!你需要先有一个概念设计,然后是详细的蓝图,最后才是实际的建筑计划。数据仓库的建模过程也是如此 - 从抽象到具体,每一步都至关重要。

让我们深入了解这三种模型,看看它们如何帮助我们构建一个强大、灵活且高效的数据仓库。
1. 概念模型:勾勒数据的蓝图
什么是概念模型?
概念模型是数据建模过程中最高层次的抽象。它就像是你数据世界的"鸟瞰图"。这个模型主要关注的是业务概念以及它们之间的关系,而不涉及任何技术细节。

概念模型的特点
- 高度抽象: 只包含核心实体和它们之间的关系。
- 业务导向: 使用业务术语,易于非技术人员理解。
- 独立于技术: 不涉及任何特定的数据库技术。
- 稳定性: 相对于其他模型,变化较少。

概念模型的例子
让我们以一个电子商务平台为例,来创建一个简单的概念模型:
[客户] --- 下单 ---> [订单]
[订单] --- 包含 ---> [商品]
[商品] --- 属于 ---> [类别]
这个简单的图表展示了核心实体(客户、订单、商品、类别)以及它们之间的关系。它不包含任何属性或技术细节,但清晰地表达了业务概念。
概念模型的作用
- 沟通工具: 帮助业务人员和技术人员达成共识。
- 需求分析: 确保我们捕获了所有重要的业务概念。
- 范围界定: 明确项目的边界和重点。
如何创建概念模型
- 识别核心业务实体
- 定义实体之间的关系
- 验证模型是否符合业务需求
- 迭代优化,直到所有相关方达成一致
概念模型虽然简单,但它的重要性不容忽视。它为整个数据仓库项目奠定了基础,确保我们从一开始就走在正确的道路上。
2. 逻辑模型:细化你的数据结构
什么是逻辑模型?
逻辑模型是概念模型的下一步细化。它保持了技术中立性,但比概念模型更加详细。逻辑模型定义了数据结构,包括实体、属性、关系和主键。

逻辑模型的特点
- 更多细节: 包含实体的属性和关系的细节。
- 规范化: 通常遵循数据库规范化原则。
- 独立于特定数据库: 不涉及特定的数据库管理系统(DBMS)。
- 业务规则: 包含业务规则和约束。

逻辑模型的例子
继续我们的电子商务平台例子,让我们看看逻辑模型可能是什么样子:
客户 (客户ID, 姓名, 邮箱, 电话)主键: 客户ID订单 (订单ID, 客户ID, 订单日期, 总金额, 状态)主键: 订单ID外键: 客户ID 引用 客户(客户ID)订单项目 (订单ID, 商品ID, 数量, 单价)主键: (订单ID, 商品ID)外键: 订单ID 引用 订单(订单ID)外键: 商品ID 引用 商品(商品ID)商品 (商品ID, 名称, 描述, 当前价格, 类别ID)主键: 商品ID外键: 类别ID 引用 类别(类别ID)类别 (类别ID, 名称, 父类别ID)主键: 类别ID外键: 父类别ID 引用 类别(类别ID)
这个逻辑模型详细定义了每个实体的属性,以及实体之间的关系。注意我们如何使用主键和外键来表示关系。
逻辑模型的作用

- 详细设计: 为物理实现提供蓝图。
- 数据完整性: 通过定义关系和约束确保数据的一致性。
- 性能考虑: 可以在这一阶段进行初步的性能优化设计。
- 灵活性: 可以相对容易地适应不同的物理实现。
如何创建逻辑模型
- 从概念模型开始,详细化每个实体
- 定义属性,确定主键
- 建立实体之间的关系,定义外键
- 应用规范化原则
- 添加业务规则和约束
- 审查并优化模型

逻辑模型中的常见挑战
- 粒度选择: 决定数据的详细程度。
- 历史数据处理: 如何处理随时间变化的数据。
- 性能与规范化的平衡: 有时需要适度反规范化以提高查询性能。
逻辑模型是连接业务需求和技术实现的桥梁。它足够详细以指导实现,又足够抽象以适应不同的技术选择。

3. 物理模型:将设计落地为实际数据库
什么是物理模型?
物理模型是数据模型的最后一个阶段,它描述了数据在特定数据库管理系统中的实际存储方式。物理模型考虑了性能、存储和可访问性等实际因素。

物理模型的特点
- 特定于DBMS: 使用特定数据库系统的语法和特性。
- 性能优化: 包含索引、分区等性能优化策略。
- 存储考虑: 定义数据类型、存储参数等。
- 安全性: 包含访问控制和安全策略。
物理模型的例子
让我们将之前的逻辑模型转化为PostgreSQL的物理模型:
CREATE TABLE customers (customer_id SERIAL PRIMARY KEY,name VARCHAR(100) NOT NULL,email VARCHAR(100) UNIQUE NOT NULL,phone VARCHAR(20)
);CREATE TABLE orders (order_id BIGSERIAL PRIMARY KEY,customer_id INTEGER NOT NULL REFERENCES customers(customer_id),order_date TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP,total_amount DECIMAL(10, 2) NOT NULL,status VARCHAR(20) NOT NULL,CONSTRAINT chk_status CHECK (status IN ('pending', 'processing', 'shipped', 'delivered', 'cancelled'))
);CREATE TABLE products (product_id BIGSERIAL PRIMARY KEY,name VARCHAR(200) NOT NULL,description TEXT,current_price DECIMAL(10, 2) NOT NULL,category_id INTEGER NOT NULL
);CREATE TABLE order_items (order_id BIGINT NOT NULL REFERENCES orders(order_id),product_id BIGINT NOT NULL REFERENCES products(product_id),quantity INTEGER NOT NULL,unit_price DECIMAL(10, 2) NOT NULL,PRIMARY KEY (order_id, product_id)
);CREATE TABLE categories (category_id SERIAL PRIMARY KEY,name VARCHAR(100) NOT NULL,parent_category_id INTEGER REFERENCES categories(category_id)
);-- 创建索引以提高查询性能
CREATE INDEX idx_orders_customer ON orders(customer_id);
CREATE INDEX idx_order_items_product ON order_items(product_id);
CREATE INDEX idx_products_category ON products(category_id);-- 假设订单表会非常大,我们可以按年份分区
CREATE TABLE orders_2024 PARTITION OF ordersFOR VALUES FROM ('2024-01-01') TO ('2025-01-01');-- 创建一个物化视图来加速常用的聚合查询
CREATE MATERIALIZED VIEW monthly_sales AS
SELECT DATE_TRUNC('month', order_date) AS month,SUM(total_amount) AS total_sales
FROM orders
GROUP BY DATE_TRUNC('month', order_date);-- 创建一个存储过程来处理新订单
CREATE OR REPLACE PROCEDURE create_order(p_customer_id INTEGER,p_total_amount DECIMAL(10, 2)
)
LANGUAGE plpgsql
AS $$
BEGININSERT INTO orders (customer_id, total_amount, status)VALUES (p_customer_id, p_total_amount, 'pending');
END;
$$;
这个物理模型包含了具体的表结构、数据类型、约束、索引、分区和存储过程。它是针对PostgreSQL数据库的具体实现。
物理模型的作用
- 性能优化: 通过索引、分区等策略提高查询和写入性能。
- 存储效率: 选择合适的数据类型和存储参数,提高存储效率。
- 可维护性: 通过视图、存储过程等简化复杂操作。
- 安全性: 实现访问控制和数据保护策略。
如何创建物理模型
- 选择目标数据库系统
- 将逻辑模型转换为数据库特定的DDL语句
- 选择适当的数据类型和约束
- 设计索引策略
- 考虑分区和聚集
- 实现存储过程和触发器
- 设置访问控制和安全策略
- 进行性能测试和优化
物理模型中的常见挑战
- 性能调优: 需要不断监控和优化以适应变化的数据量和查询模式。
- 扩展性: 设计需要考虑未来数据增长。
- 维护复杂性: 随着时间推移,可能需要管理大量的对象(索引、视图等)。
- 版本管理: 需要谨慎管理数据库结构的变更。
物理模型是数据仓库设计的最后一步,也是最具技术性的一步。它直接影响着数据仓库的性能和可用性。
三种模型的比较
让我们通过一个表格来直观地比较这三种模型:
| 特征 | 概念模型 | 逻辑模型 | 物理模型 |
|---|---|---|---|
| 抽象级别 | 最高 | 中等 | 最低 |
| 目标受众 | 业务人员 | 数据架构师 | 数据库管理员 |
| 包含的细节 | 核心实体和关系 | 实体、属性、关系、键 | 表、列、索引、分区等 |
| 技术相关性 | 与技术无关 | 与技术无关 | 特定于DBMS |
| 主要用途 | 业务需求分析 | 数据结构设计 | 数据库实现 |
| 变更频率 | 低 | 中 | 高 |
| 工具 | ER图、UML | ER图、数据字典 | DDL、数据库设计工具 |
从概念到物理:模型转换的最佳实践
将概念模型转换为逻辑模型,再转换为物理模型是一个渐进的过程。以下是一些最佳实践:
-
保持一致性: 确保每个阶段的模型都与前一阶段保持一致。
-
文档化: 记录每个阶段的决策和变更理由。
-
迭代优化: 不要期望一次性得到完美的模型,要准备进行多次迭代。
-
验证: 在每个阶段都与相关stakeholder验证模型。
-
考虑未来: 设计时要考虑到未来的扩展性和灵活性。
-
性能与规范化平衡: 在逻辑模型阶段就开始考虑性能问题,必要时进行适度的反规范化。7. 技术选型: 在进行物理模型设计时,充分考虑目标数据库系统的特性和最佳实践。
-
数据质量: 在模型设计的每个阶段都要考虑数据质量问题,如何通过模型设计来确保数据的准确性、完整性和一致性。
-
安全性: 从逻辑模型阶段就开始考虑数据安全和访问控制问题,在物理模型中具体实现。
-
可追溯性: 确保可以从物理模型追溯到逻辑模型和概念模型,这对于后期的维护和变更管理非常重要。
实际应用:电子商务数据仓库案例研究
让我们通过一个电子商务数据仓库的案例,来看看如何在实际项目中应用这三种模型。
阶段1:概念模型设计
在项目启动阶段,我们与业务团队进行了深入的需求分析,识别了以下核心业务概念:
- 客户
- 订单
- 商品
- 类别
- 供应商
- 促销活动
我们使用简单的实体关系图来表示这些概念及其关系:
[客户] --- 下单 ---> [订单]
[订单] --- 包含 ---> [商品]
[商品] --- 属于 ---> [类别]
[供应商] --- 提供 ---> [商品]
[促销活动] --- 应用于 ---> [商品]
[促销活动] --- 针对 ---> [客户]
这个概念模型帮助我们确定了数据仓库的范围,并为后续的详细设计提供了框架。
阶段2:逻辑模型设计
在逻辑模型阶段,我们进一步细化了每个实体的属性,并定义了它们之间的具体关系。以下是部分逻辑模型设计:
客户维度 (客户ID, 姓名, 邮箱, 电话, 注册日期, 客户等级)主键: 客户ID订单事实 (订单ID, 客户ID, 订单日期, 总金额, 折扣金额, 支付方式, 订单状态)主键: 订单ID外键: 客户ID 引用 客户维度(客户ID)商品维度 (商品ID, 商品名称, 描述, 当前价格, 类别ID, 供应商ID)主键: 商品ID外键: 类别ID 引用 类别维度(类别ID)外键: 供应商ID 引用 供应商维度(供应商ID)订单明细事实 (订单ID, 商品ID, 数量, 单价, 折扣)主键: (订单ID, 商品ID)外键: 订单ID 引用 订单事实(订单ID)外键: 商品ID 引用 商品维度(商品ID)类别维度 (类别ID, 类别名称, 父类别ID)主键: 类别ID外键: 父类别ID 引用 类别维度(类别ID)供应商维度 (供应商ID, 供应商名称, 联系人, 地址, 评级)主键: 供应商ID促销活动维度 (促销ID, 促销名称, 开始日期, 结束日期, 折扣类型, 折扣值)主键: 促销ID促销应用事实 (促销ID, 商品ID, 客户ID, 应用日期, 折扣金额)主键: (促销ID, 商品ID, 客户ID, 应用日期)外键: 促销ID 引用 促销活动维度(促销ID)外键: 商品ID 引用 商品维度(商品ID)外键: 客户ID 引用 客户维度(客户ID)
在这个逻辑模型中,我们采用了星型架构,将订单和订单明细作为事实表,其他实体作为维度表。这种设计有利于快速的多维分析和报表生成。
阶段3:物理模型设计
在物理模型阶段,我们需要考虑具体的数据库系统(假设我们使用PostgreSQL)和性能优化策略。以下是部分物理模型设计:
-- 客户维度表
CREATE TABLE dim_customer (customer_id SERIAL PRIMARY KEY,name VARCHAR(100) NOT NULL,email VARCHAR(100) UNIQUE NOT NULL,phone VARCHAR(20),registration_date DATE NOT NULL,customer_level VARCHAR(20) NOT NULL,create_date TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP,update_date TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP
);-- 订单事实表
CREATE TABLE fact_order (order_id BIGSERIAL PRIMARY KEY,customer_id INTEGER NOT NULL REFERENCES dim_customer(customer_id),order_date DATE NOT NULL,total_amount DECIMAL(10, 2) NOT NULL,discount_amount DECIMAL(10, 2) NOT NULL DEFAULT 0,payment_method VARCHAR(50) NOT NULL,order_status VARCHAR(20) NOT NULL,create_date TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP
);-- 创建分区表以提高查询性能
CREATE TABLE fact_order_2024 PARTITION OF fact_orderFOR VALUES FROM ('2024-01-01') TO ('2025-01-01');-- 创建索引以加速常见查询
CREATE INDEX idx_fact_order_customer ON fact_order(customer_id);
CREATE INDEX idx_fact_order_date ON fact_order(order_date);-- 创建物化视图以加速常用的聚合查询
CREATE MATERIALIZED VIEW mv_daily_sales AS
SELECT order_date,COUNT(*) AS order_count,SUM(total_amount) AS total_sales,AVG(total_amount) AS avg_order_value
FROM fact_order
GROUP BY order_date;-- 创建存储过程以简化复杂的数据操作
CREATE OR REPLACE PROCEDURE update_customer_level()
LANGUAGE plpgsql
AS $$
BEGINUPDATE dim_customer cSET customer_level = CASE WHEN total_spent >= 10000 THEN 'Platinum'WHEN total_spent >= 5000 THEN 'Gold'WHEN total_spent >= 1000 THEN 'Silver'ELSE 'Bronze'END,update_date = CURRENT_TIMESTAMPFROM (SELECT customer_id, SUM(total_amount) AS total_spentFROM fact_orderGROUP BY customer_id) oWHERE c.customer_id = o.customer_id;
END;
$$;
在这个物理模型中,我们实现了以下优化策略:
- 使用适当的数据类型和约束
- 创建分区表以提高大表的查询性能
- 添加索引以加速常见查询
- 创建物化视图以提高聚合查询的性能
- 使用存储过程封装复杂的业务逻辑
从模型到实践:数据仓库实施的关键考虑因素
在完成三个层次的模型设计后,实施数据仓库还需要考虑以下几个关键因素:
1. ETL流程设计
抽取(Extract)、转换(Transform)和加载(Load)是数据仓库的核心流程。基于我们的模型,需要设计:
- 如何从源系统抽取数据
- 如何清洗和转换数据以符合我们的模型
- 如何高效地加载数据到仓库中
例如,对于订单数据,我们可能需要:
import pandas as pd
from sqlalchemy import create_enginedef etl_orders():# 从源系统抽取数据source_engine = create_engine('postgresql://user:pass@source_host/db')orders_df = pd.read_sql('SELECT * FROM orders WHERE date > last_etl_date', source_engine)# 数据转换orders_df['total_amount'] = orders_df['subtotal'] + orders_df['tax'] - orders_df['discount']orders_df['order_status'] = orders_df['status'].map({'P': 'Pending', 'S': 'Shipped', 'D': 'Delivered'})# 加载到数据仓库target_engine = create_engine('postgresql://user:pass@dw_host/db')orders_df.to_sql('fact_order', target_engine, if_exists='append', index=False)# 定期运行ETL作业
schedule.every().day.at("02:00").do(etl_orders)
2. 数据质量管理
确保数据质量是数据仓库成功的关键。我们需要在ETL过程中实施数据质量检查:
def check_data_quality(df):# 检查空值null_counts = df.isnull().sum()if null_counts.any():raise ValueError(f"发现空值: {null_counts[null_counts > 0]}")# 检查数据范围if df['total_amount'].min() < 0:raise ValueError("发现负数订单金额")# 检查唯一性约束if df['order_id'].duplicated().any():raise ValueError("发现重复的订单ID")# 在ETL过程中调用
check_data_quality(orders_df)
3. 性能优化
随着数据量的增长,性能优化变得越来越重要。除了前面提到的分区和索引策略,我们还可以:
- 使用并行处理来加速ETL
- 实施数据压缩
- 定期进行统计信息更新
- 使用查询优化器提示
-- 使用并行查询
SET max_parallel_workers_per_gather = 4;-- 压缩大表
ALTER TABLE fact_order SET (autovacuum_enabled = false);
ALTER TABLE fact_order SET (parallel_workers = 4);
VACUUM (VERBOSE, ANALYZE, FULL) fact_order;-- 更新统计信息
ANALYZE fact_order;-- 使用查询优化器提示
EXPLAIN (ANALYZE, BUFFERS)
SELECT /*+ BitmapScan(fact_order) */customer_id, SUM(total_amount)
FROM fact_order
WHERE order_date BETWEEN '2024-01-01' AND '2024-12-31'
GROUP BY customer_id;
4. 安全性和访问控制
数据安全是另一个关键考虑因素。我们需要实施:
- 行级安全性
- 列级加密
- 角色基础的访问控制
-- 创建角色
CREATE ROLE sales_analyst;
CREATE ROLE marketing_analyst;-- 授予权限
GRANT SELECT ON fact_order TO sales_analyst;
GRANT SELECT ON dim_customer TO marketing_analyst;-- 实施行级安全性
ALTER TABLE fact_order ENABLE ROW LEVEL SECURITY;CREATE POLICY order_access_policy ON fact_orderUSING (current_user = 'sales_analyst' OR order_status = 'Completed');-- 列级加密
ALTER TABLE dim_customerALTER COLUMN email SET DATA TYPE bytea USING pgp_sym_encrypt(email::text, 'secret_key')::bytea;
5. 元数据管理
好的元数据管理可以提高数据仓库的可用性和可维护性。我们可以创建一个元数据仓库来存储:
- 数据字典
- 数据血缘关系
- ETL作业信息
- 数据质量检查结果
CREATE TABLE metadata_dictionary (table_name VARCHAR(100),column_name VARCHAR(100),data_type VARCHAR(50),description TEXT,source_system VARCHAR(100),last_updated TIMESTAMP
);INSERT INTO metadata_dictionary VALUES
('fact_order', 'order_id', 'BIGINT', '订单唯一标识符', 'ERP系统', CURRENT_TIMESTAMP),
('fact_order', 'customer_id', 'INTEGER', '客户ID', 'CRM系统', CURRENT_TIMESTAMP),
-- ... 其他元数据
结论:从概念到现实的数据仓库之旅
通过本文,我们详细探讨了数据仓库建模的三个关键阶段:概念模型、逻辑模型和物理模型。每个阶段都有其独特的作用和挑战:
- 概念模型帮助我们捕获核心业务概念,为整个项目定下基调。
- 逻辑模型将抽象概念转化为具体的数据结构,为实施提供蓝图。
- 物理模型考虑实际的技术约束和性能需求,将设计落地为可执行的数据库结构。
在实际项目中,这三个阶段并非孤立的步骤,而是一个迭代和反馈的过程。随着对业务的深入理解和技术的不断演进,我们可能需要多次调整和优化我们的模型。
记住,一个成功的数据仓库不仅仅是良好的模型设计,还需要考虑ETL流程、数据质量、性能优化、安全性和元数据管理等多个方面。只有将这些因素综合考虑,我们才能构建一个真正满足业务需求、高效可靠的数据仓库系统。
最最后,让我们回顾一下数据仓库建模的关键点,并为数据工程师和架构师提供一些实践建议:
关键要点回顾
- 概念模型是最抽象的层次,focus on 业务概念和关系,不涉及技术细节。
- 逻辑模型进一步细化数据结构,定义实体、属性和关系,但仍保持技术中立。
- 物理模型考虑具体的数据库系统,实现实际的表结构、索引和优化策略。
- 三种模型形成了一个从抽象到具体的连续体,每一步都对最终的数据仓库实现至关重要。
- 除了模型设计,成功的数据仓库还需要考虑ETL、数据质量、性能优化、安全性和元数据管理等方面。
实践建议
-
保持模型的一致性: 确保概念模型、逻辑模型和物理模型之间保持一致。任何一个层面的变更都应该考虑对其他层面的影响。
-
迭代优化: 数据仓库建模是一个迭代的过程。随着对业务的深入理解和需求的变化,不断优化和调整你的模型。
-
关注数据质量: 在模型设计的每个阶段都要考虑数据质量。定义清晰的数据规则和约束,并在ETL过程中实施严格的数据质量检查。
-
性能与可用性平衡: 在追求查询性能的同时,也要考虑模型的可理解性和可维护性。过度的性能优化可能会导致模型变得复杂难懂。
-
文档化: 详细记录你的设计决策、数据定义和业务规则。好的文档可以大大提高数据仓库的可用性和可维护性。
-
考虑未来扩展: 在设计时要考虑到未来可能的需求变化和数据增长。预留一些灵活性,以便未来能够更容易地进行扩展和调整。
-
重视安全性: 从一开始就将数据安全纳入考虑范围。实施适当的访问控制,保护敏感数据。
-
持续监控和优化: 数据仓库不是"一次性"工程。持续监控其性能和使用情况,并根据实际情况进行优化。
结语
数据仓库建模是一门艺术,也是一门科学。它需要我们既能够从高层次理解业务需求,又能深入技术细节解决实际问题。通过掌握概念模型、逻辑模型和物理模型这三个层次的设计,我们就拥有了构建强大、灵活、高效数据仓库的基础工具。
记住,最好的模型是那些能够有效支持业务决策,同时又易于理解和维护的模型。它应该是业务需求和技术可能性的完美平衡。作为数据工程师或架构师,我们的目标就是创造这样的平衡,为组织提供真正的数据价值。
希望这篇文章能够帮助你更好地理解数据仓库建模的过程,并在实践中创建出优秀的数据仓库解决方案。数据的世界永远充满挑战和机遇,让我们继续学习,不断探索,用数据为世界创造更多价值!
这篇关于数据仓库系列7:什么是概念模型、逻辑模型和物理模型,它们有什么区别?的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







