lake专题

POJ 2386 Lake Counting(DFS)
题目: http://poj.org/problem?id=2386 题解: 遍历一次,遇到w,一次DFS后,与此w连接的所有w都被替换成‘ . ’,直到遍历完图中不再存在w为止,总共进行DFS的次数就是答案了。 代码: #include<stdio.h>int N,M;char map[110][110];void dfs(int x,int y){map[x][y]='

重磅 | Delta Lake正式加入Linux基金会,重塑数据湖存储标准
大数据技术与架构 点击右侧关注,大数据开发领域最强公众号! 暴走大数据 点击右侧关注,暴走大数据! 作者:wwwzw By 暴走大数据 场景描述:2019年10月16日,在荷兰阿姆斯特丹举行的 Spark+AI 欧洲峰会上,DataBricks 和 Linux

数据湖之Delta Lake
Delta Lake:数据湖存储层概述 Delta Lake 是一种开源的存储层技术,构建在 Apache Spark 的基础之上,旨在解决传统数据湖的可靠性、性能和数据一致性问题。它通过引入 ACID 事务、数据版本控制、时间旅行和统一的批处理与流处理等特性,显著提升了数据湖的可用性和数据管理能力。Delta Lake 由 Databricks 推出,现已成为现代数据湖架构的核心组件。

Ice Lake CPU RESET流程
1、 处理器支持3种reset,分别是cold reset和warm reset和PWRGD reset; a) cold reset是指在首次上电触发CPU的PWRGOOD和RESET_N,其中PWRGD的触发需要在Base Clock就绪并且power都已经稳定之后才可以,该reset将会复位处理器里的所有的状态,包括被其他reset阻止的sticky state。 b) warm res

Delta lake with Java--读《Delta Lake Up and Running》总结
利用5.1假期读完《Delta Lake Up and Running》,这本书非常适合入门,但不够深入,要想将Delta lake用于实际项目,还是需要从spark开始重新学习。学完一本书总结一下这本书的内容。 第一章 概念介绍,其中第21页的Medallio Architecture架构(金,银,铜)是数据湖架构基础,基本上数据湖的书籍都会提及。 第二章 Delta lake入门,需要掌握
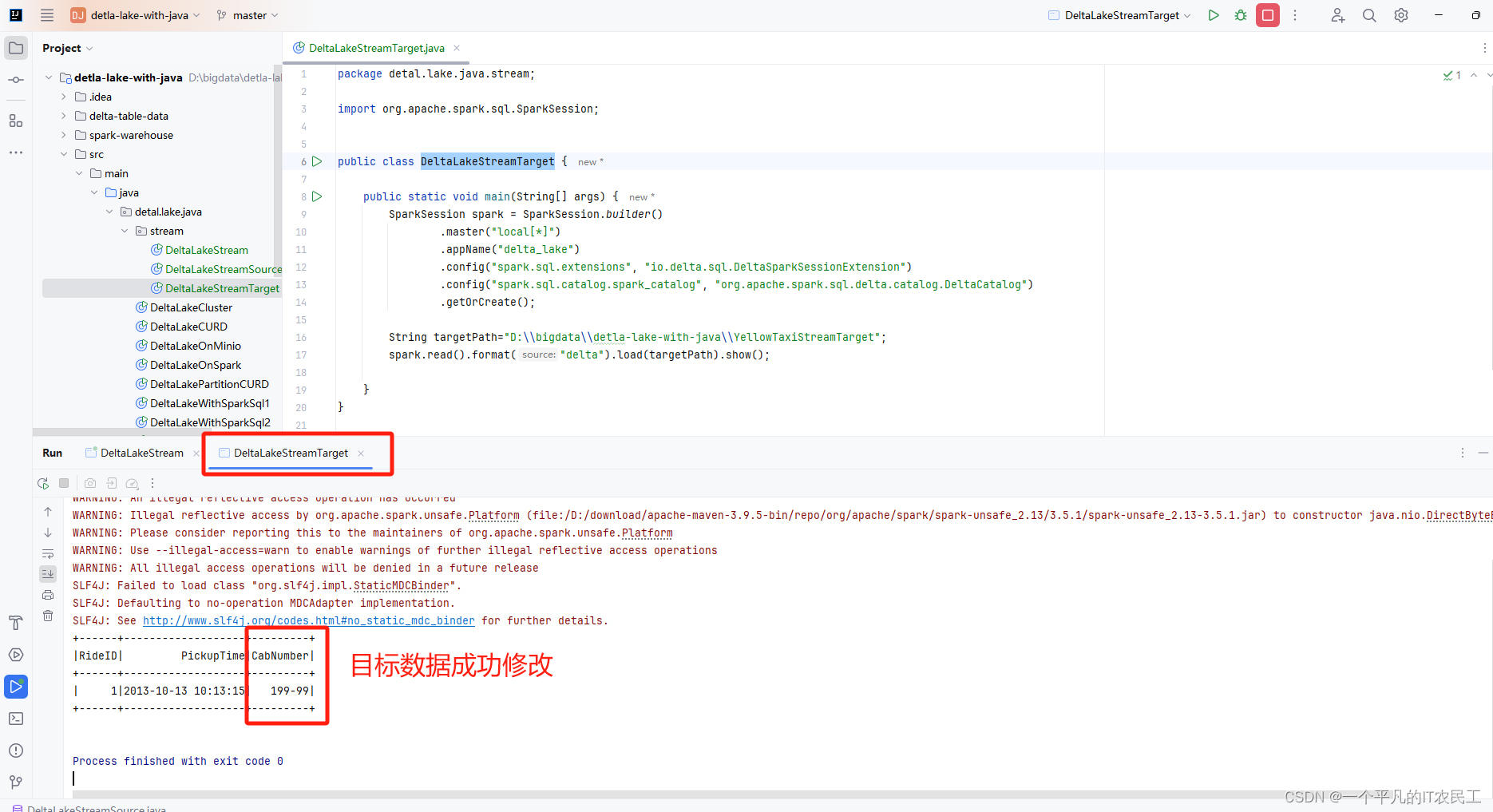
Delta lake with Java--使用stream同步数据
今天继续学习Delta lake Up and Running 的第8章,处理流数据,要实现的效果就是在一个delta表(名为:YellowTaxiStreamSource)插入一条数据,然后通过流的方式能同步到另外一个delta表 (名为:YellowTaxiStreamTarget)。接着在YellowTaxiStreamSource更新数据YellowTaxiStreamTarget也能更新
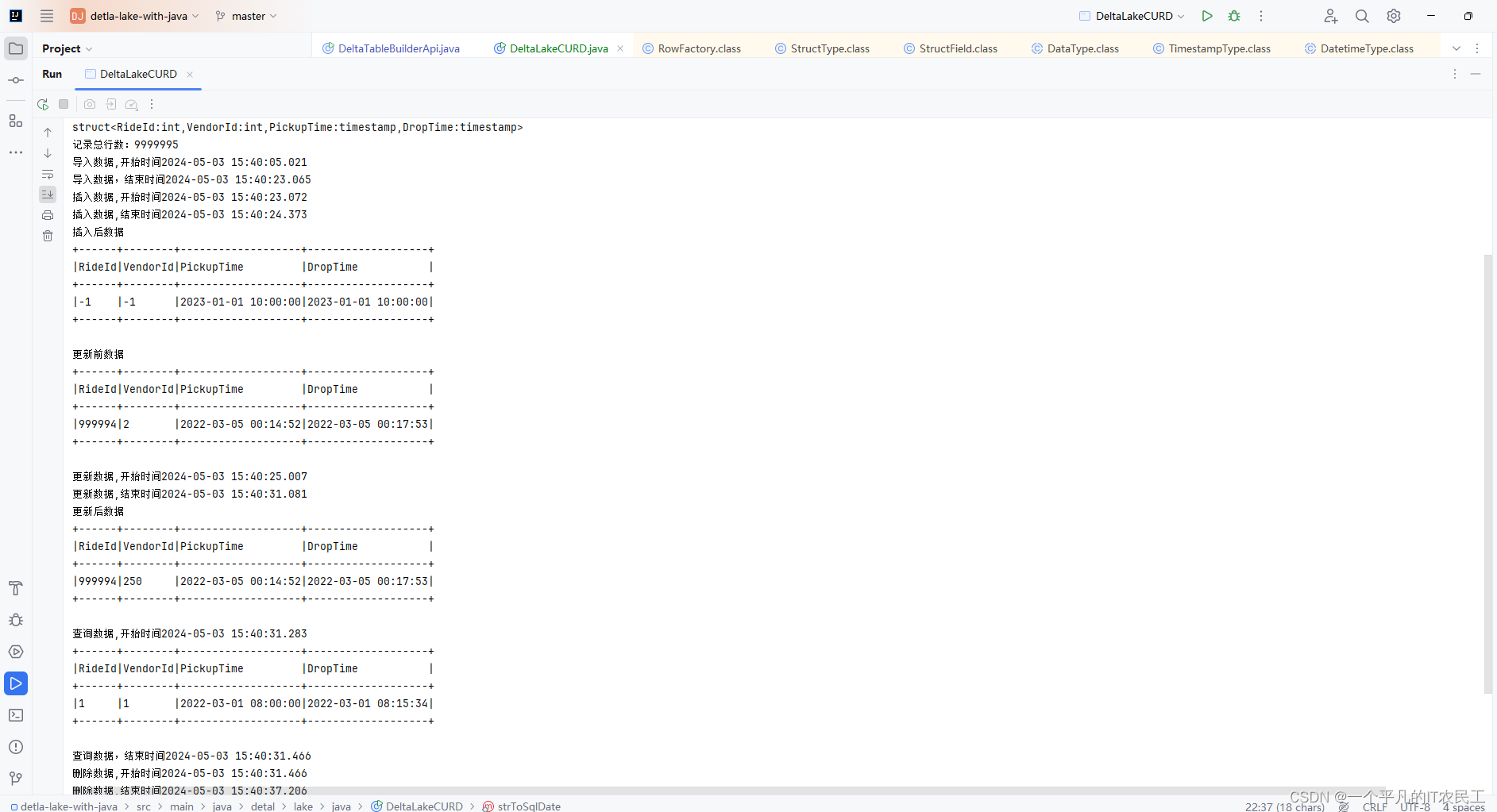
Delta lake with Java--数据增删改查
之前写的关于spark sql 操作delta lake表的,总觉得有点混乱,今天用Java结合真实的数据来进行一次数据的CRUD操作,所涉及的数据来源于Delta lake up and running配套的 GitGitHub - benniehaelen/delta-lake-up-and-running: Companion repository for the book 'Delta L
数据湖的优点 Data Lake VS Data warehouse / 数据湖与数据仓库的区别
数据湖的优点 提供不限数据类型的存储 开发人员和数据科学家可以快速动态建立数据模型、构建应用、查询数据,非常灵活。 因为数据湖没有固定的结构,所以更易于访问 长期存储数据的成本低廉,数据湖可以安装在低成本的硬件在,例如: 在一般的X86机器上部署Hadoop 因为数据湖是非常灵活的,它允许使用多种不同的处理、分析方式来让数据发挥价值,例如:数据分析、实时分析、机器学习以及SQL查询都可
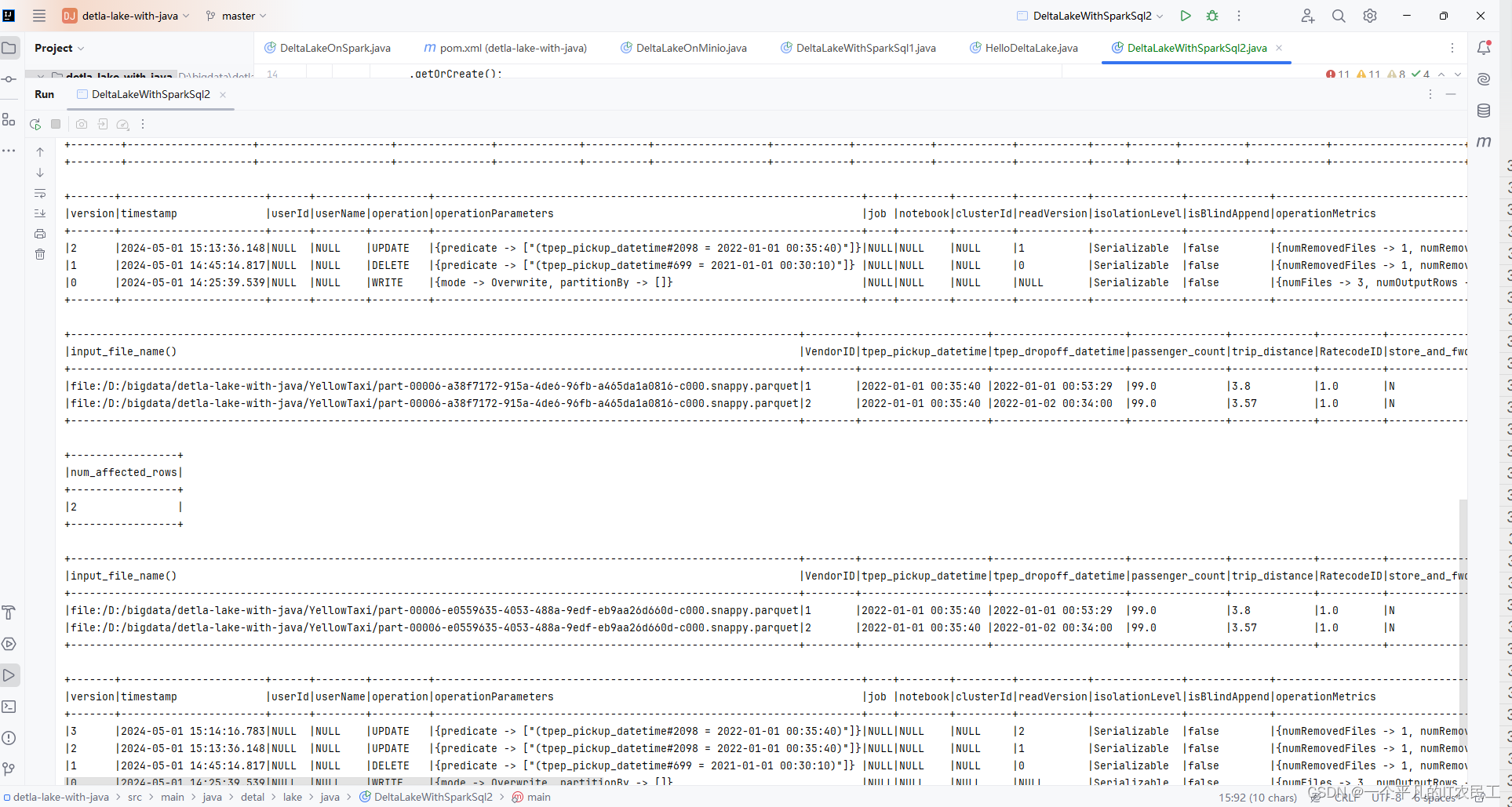
Delta lake with Java--利用spark sql操作数据2
上一篇文章尝试了建库,建表,插入数据,还差删除和更新,所以在这篇文章补充一下,代码很简单,具体如下: import org.apache.spark.sql.SaveMode;import org.apache.spark.sql.SparkSession;public class DeltaLakeWithSparkSql2 {public static void main(String[]
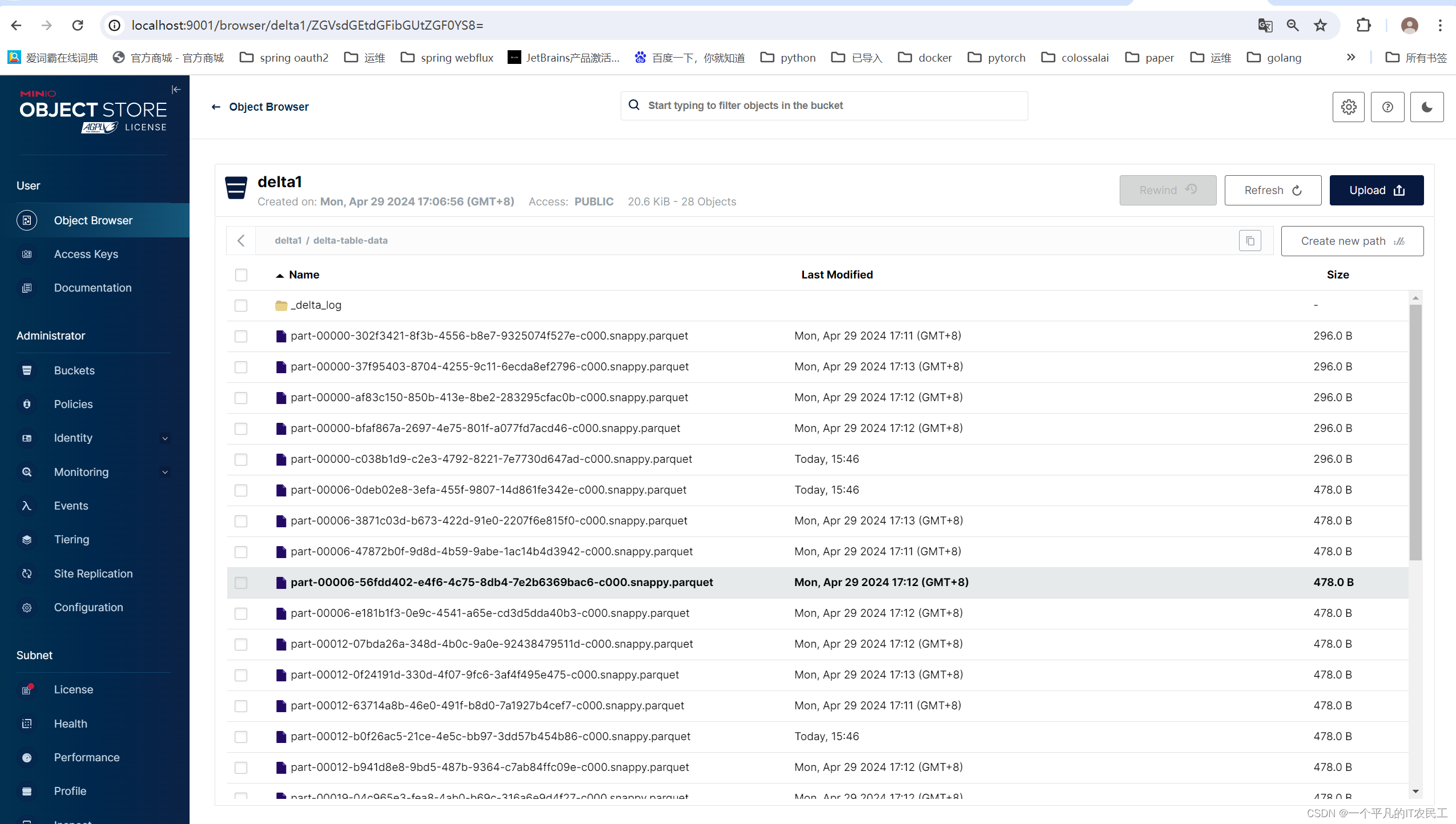
Delta lake with Java--将数据保存到Minio
今天看了之前发的文章,居然有1条评论,看到我写的东西还是有点用。 今天要解决的问题是如何将 Delta产生的数据保存到Minio里面。 1、安装Minio,去官网下载最新版本的Minio,进入下载目录,运行如下命令,曾经尝试过用docker来安装,不过数据无法保存成功。 minio.exe server D:\bigdata\miniodata --console-address ":900
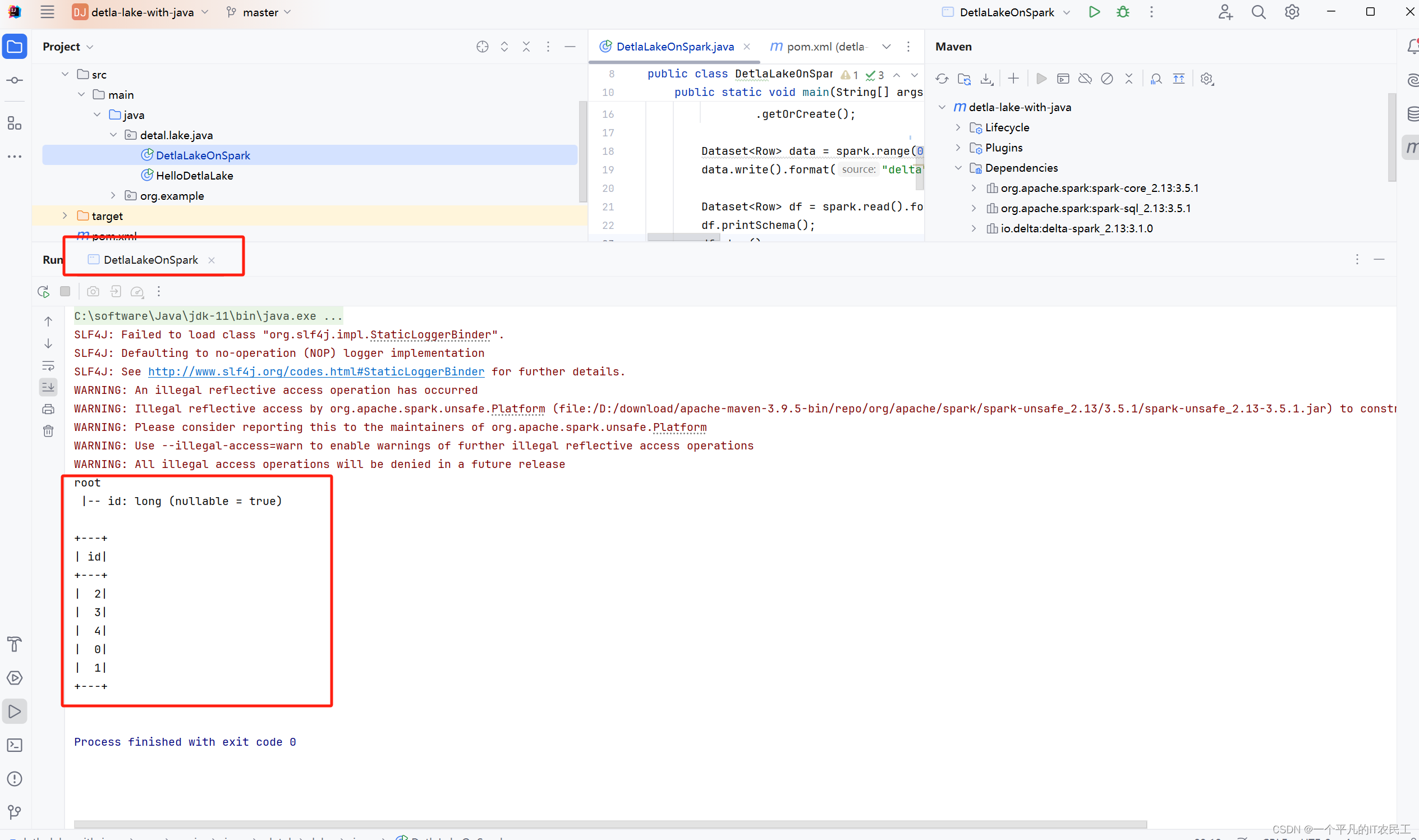
Detla lake with Java--在spark集群上运行程序
昨天写了第一篇入门,今天看见有人收藏,继续努力学习下去。今天要实现的内容是如何将昨天的HelloDetlaLake 在spark集群上运行,。具体步骤如下 1、安装spark,我使用的是 spark-3.5.1-bin-hadoop3-scala2.13,去官网下载,然后放到电脑任何一个目录,然后添加环境变量,具体如下图: 2、打开一个cmd窗口,运行如下命令: spark-class org

Detla lake with Java--入门
最近在研究数据湖,虽然不知道研究成果是否可以用于工作,但我相信机会总是留给有准备的人。 数据湖尤其是最近提出的湖仓一体化概念,很少有相关的资料,目前开源的项目就三个,分别是hudi, detla lake, iceberg。最终选择使用detla lake,因为国外有相关的书籍,国内一些关于spark书籍也有提到detla lake。花了一些钱把国内外相关的书籍都买了一遍,发现全部都是用sca

【CVPR2022】LAKe-Net:通过定位对齐关键点实现拓扑感知点云完成
来源:专知本文为论文,建议阅读5分钟团队提出了无监督的多尺度关键点检测器并从理论上证明了捕获到的子类别内对象的关键点的有序性。 LAKe-Net: Topology-Aware Point Cloud Completionby Localizing Aligned Keypoints 作者: 唐俊姝、龚致君、易冉、谢源、马利庄 工作简介:点云补全旨在通过局部观察到的点云形状来补全几何和拓扑
![洛谷-P1596 [USACO10OCT] Lake Counting S](https://img-blog.csdnimg.cn/direct/11771c081d4a4d158d1423d38fc394bf.png)
洛谷-P1596 [USACO10OCT] Lake Counting S
P1596 [USACO10OCT] Lake Counting S - 洛谷 | 计算机科学教育新生态 (luogu.com.cn) #include<bits/stdc++.h>using namespace std;const int N=110;int m,n;char g[N][N];bool st[N][N]; //走/没走int dx[]= {-1,-1,-1,

Coffee Lake-S 處理器
Intel 的14nm++處理器系列又要擴大陣容了,在桌面、移動等市場普及之後,Coffee Lake 家族現在又打入了工作站市場。Intel 今天正式發布了 Xeon E-2100 系列處理器,最多6C12T,加速頻率4.7GHz,支援64GB ECC記憶體,採用 LGA1151 插槽,可以看作是 Coffee Lake-S 處理器的工作站版,不過並不相容於300系列晶片組,需要搭配C246晶片

Lake Counting S
Lake Counting S 洛谷P1596 一道典型深搜题 把字符存成数字就变成了种子填充的题 思路: 设置变量和flag输入 将字符变成数字用深搜判断输出结果 #include <iostream>using namespace std;int g[100][100];bool flag[100][100];int n,m,ans=0;char c=0;void dfs
OpenJ_Bailian - 2386 Lake Counting DFS深搜 经典连通块问题
以上截自参考资料:《挑战程序设计竞赛》 我的AC代码: #include<iostream>#include<string>using namespace std;int N,M,ans=0;string fields[100+10];void dfs(int line,int row){ fields[line][row]='.';for(int i=-1;i<=1;i
POJ2396 Lake Counting
暴力搜索经典题 挑战程序设计竞赛 题目链接 #include<cstdio>#include<algorithm>using namespace std;const int maxn = 110;char G[maxn][maxn];int n, m, cnt = 0;int dx[8] = {1, -1, 0, 0, -1, 1, 1, -1}; int dy[8] = {0,
在Meteor Lake平台上使用NPU进行AI推理加速
在Meteor Lake平台上,英特尔通过神经处理单元 (NPU) 将人工智能直接融入芯片中,实现桌面电脑平台的AI推理功能。神经处理单元 (NPU) 是一种专用人工智能引擎,专为运行持续的人工智能推理工作负载而设计。与即将推出的支持深度人工智能集成的 Windows 版本(预计将于 2024 年夏季推出)搭配,Meteor Lake 可能预示着人工智能 PC 时代的开始,计算机可以利用人工智

Mountain Lake - Forest Pack
从头开始构建的50个岩石森林资源集合,充分利用了HDRP。还支持Universal 和Built-In。 支持Unity 2020.3+、高清渲染管线、通用渲染管线、标准渲染管线。导入包后,按照README中的说明进行操作。 Mountain Lake - Rock & Tree Pack是一个由50个准备好的资源组成的集合,从头开始构建,以充分利用高清渲染管道。这些资源经过精心雕刻、纹理化和
1249:Lake Counting
【题目描述】 题意:有一块N×M的土地,雨后积起了水,有水标记为‘W’,干燥为‘.’。八连通的积水被认为是连接在一起的。请求出院子里共有多少水洼? 【输入】 第一行为N,M(1≤N,M≤110)。 下面为N*M的土地示意图。 【输出】 一行,共有的水洼数。 【输入样例】 10 12W........WW..WWW.....WWW....WW...WW....
重磅|Spark Delta Lake 现在由Linux基金会托管,将成为数据湖的开放标准
一年一度的 Spark + AI Summit Europe 峰会于2019年10月15-17日在欧洲的阿姆斯特丹举行。在10年16日 数砖和 Linux 基金会共同宣布 Delta Lake 和 将成为一个 Linux 基金会项目(参考:https://www.linuxfoundation.org/press-release/2019/10/the-delta-lake-project-tu

一文读懂Delta Lake:大数据时代的数据湖框架新选择!
介绍:Delta Lake是一个开源存储层,为Apache Spark和大数据工作负载提供了ACID事务能力。这个存储层由Databricks公司推出,并已成为数据湖方案的重要组成部分。 Delta Lake的核心特性包括: ACID事务:通过不同等级的隔离策略,Delta Lake支持多个pipeline的并发读写; 数据版本管理:Delta Lake通过Snapshot等来管理、审计数据及元数
Silver Lake将从L-GAM手中收购Grupo BC
与创始股东和管理团队共同投资,支持伊比利亚和拉丁美洲领先抵押贷款管理、法律和数字服务提供商的有机增长并加速并购路线图 马德里和伦敦--(美国商业资讯)--伊比利亚和拉丁美洲领先的抵押贷款管理、法律和数字服务提供商Grupo BC今天宣布,全球领先的技术投资公司Silver Lake与Grupo BC的创始股东和管理团队将从控股股东L-GAM手中收购Grupo BC 100%的股份,以促进Gr
Lake Shore低温配件之低温导线介绍
用于最大限度地减少热泄漏到传感器和低温系统中,低温线比铜线具有低得多的热导率(和更高的电阻率)。最常见的低温线材是磷青铜。该导线有单、二和四引线配置。四引线配置有 Quad-twist™(两条双绞线)或 Quad-lead™(带状)。线规为 32 或 36 AWG,使用聚酰亚胺或聚乙烯醇缩甲醛 (Formvar®) 来绝缘电线。其他常见的低温线包括锰、镍铬合金加热线和 HD-30 重

Lake Shore低温温度传感器综合介绍
硅二极管温度传感器 在业内任何硅二极管的最宽有用温度范围(1.4 K 至 500 K)内均具有最佳精度 迄今为止任何硅二极管的 30 K 至 500 K 应用的最严格公差 坚固、可靠的 Lake Shore SD 封装, 旨在承受重复的热循环并最大限度地减少传感器自热 符合标准曲线 DT-670 温度响应曲线