本文主要是介绍Detla lake with Java--在spark集群上运行程序,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
昨天写了第一篇入门,今天看见有人收藏,继续努力学习下去。今天要实现的内容是如何将昨天的HelloDetlaLake 在spark集群上运行,。具体步骤如下
1、安装spark,我使用的是 spark-3.5.1-bin-hadoop3-scala2.13,去官网下载,然后放到电脑任何一个目录,然后添加环境变量,具体如下图: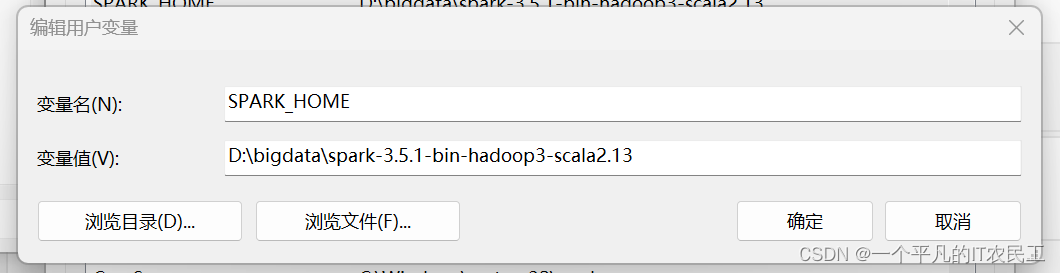
2、打开一个cmd窗口,运行如下命令:
spark-class org.apache.spark.deploy.master.Master
最终运行结果如下图: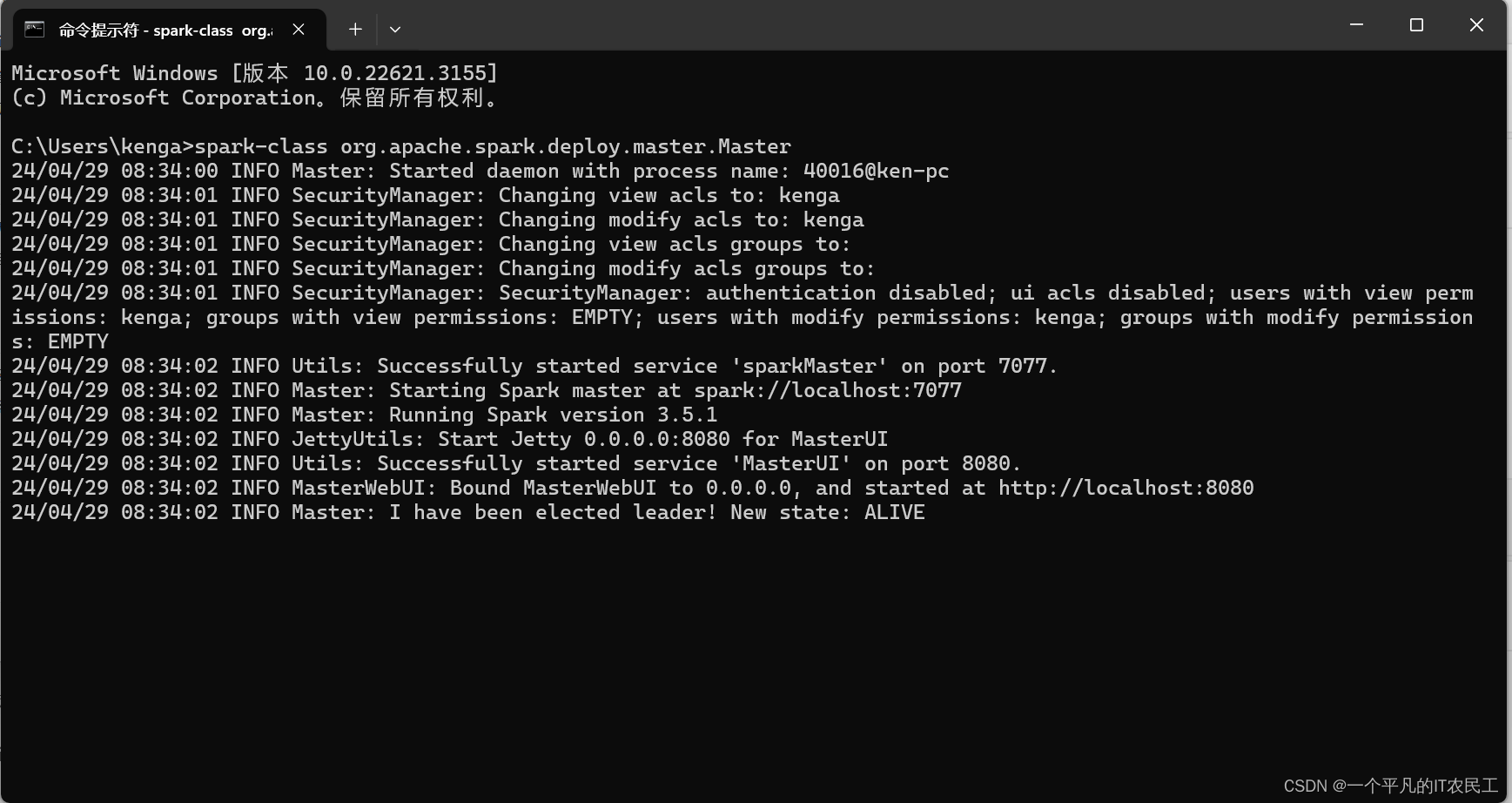
3、打开第二个cmd窗口,运行如下命令:
spark-class org.apache.spark.deploy.worker.Worker spark://localhost:7077
具体运行结果如下图:

此时在浏览器访问 http://localhost:8080/,能够看到有一个worker的spark集群已经成功启动,具体如下图:
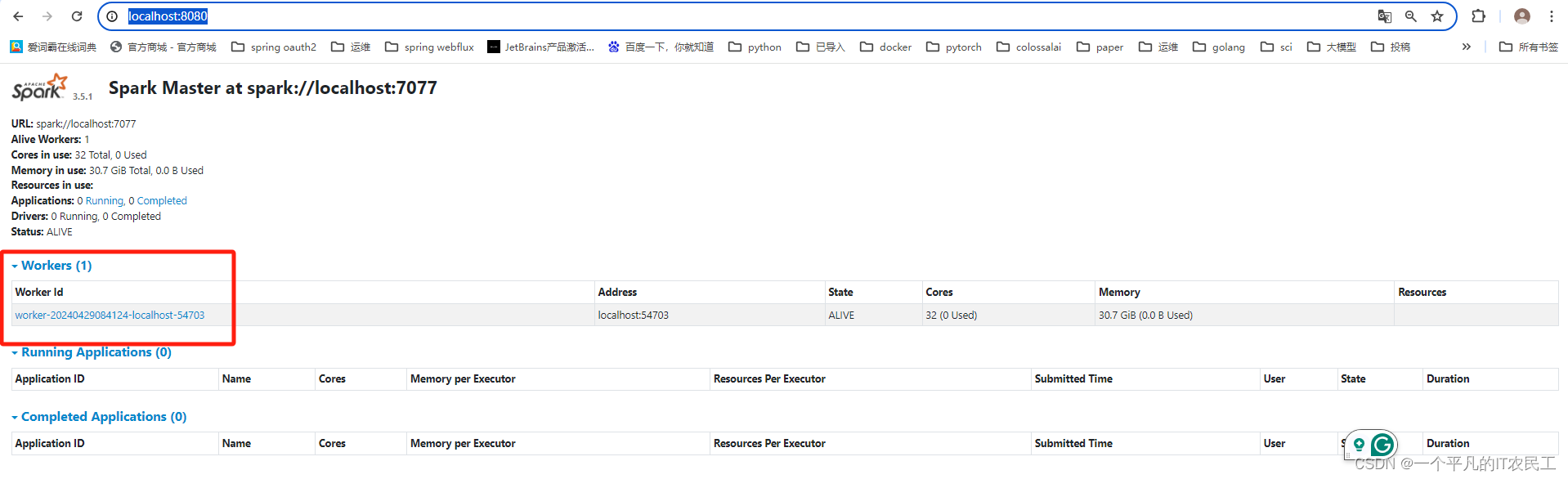
4、修改昨天的代码,新建一个DetlaLakeOnSpark,设定代码在 spark://localhost:7077上运行,具体修改master("spark://localhost:7077"),详细代码具体如下:
package detal.lake.java;import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SaveMode;
import org.apache.spark.sql.SparkSession;public class DetlaLakeOnSpark {public static void main(String[] args) {SparkSession spark = SparkSession.builder().master("spark://localhost:7077").appName("delta_lake").config("spark.sql.extensions", "io.delta.sql.DeltaSparkSessionExtension").config("spark.sql.catalog.spark_catalog", "org.apache.spark.sql.delta.catalog.DeltaCatalog").getOrCreate();Dataset<Row> data = spark.range(0,5).toDF();data.write().format("delta").mode(SaveMode.Overwrite).save("file:///D:\\bigdata\\detla-lake-with-java\\delta-table-data");Dataset<Row> df = spark.read().format("delta").load("file:///D:\\bigdata\\detla-lake-with-java\\delta-table-data");df.printSchema();df.show();spark.close();}
}
在IDEA上运行以上代码,结果报错,具体如下图:
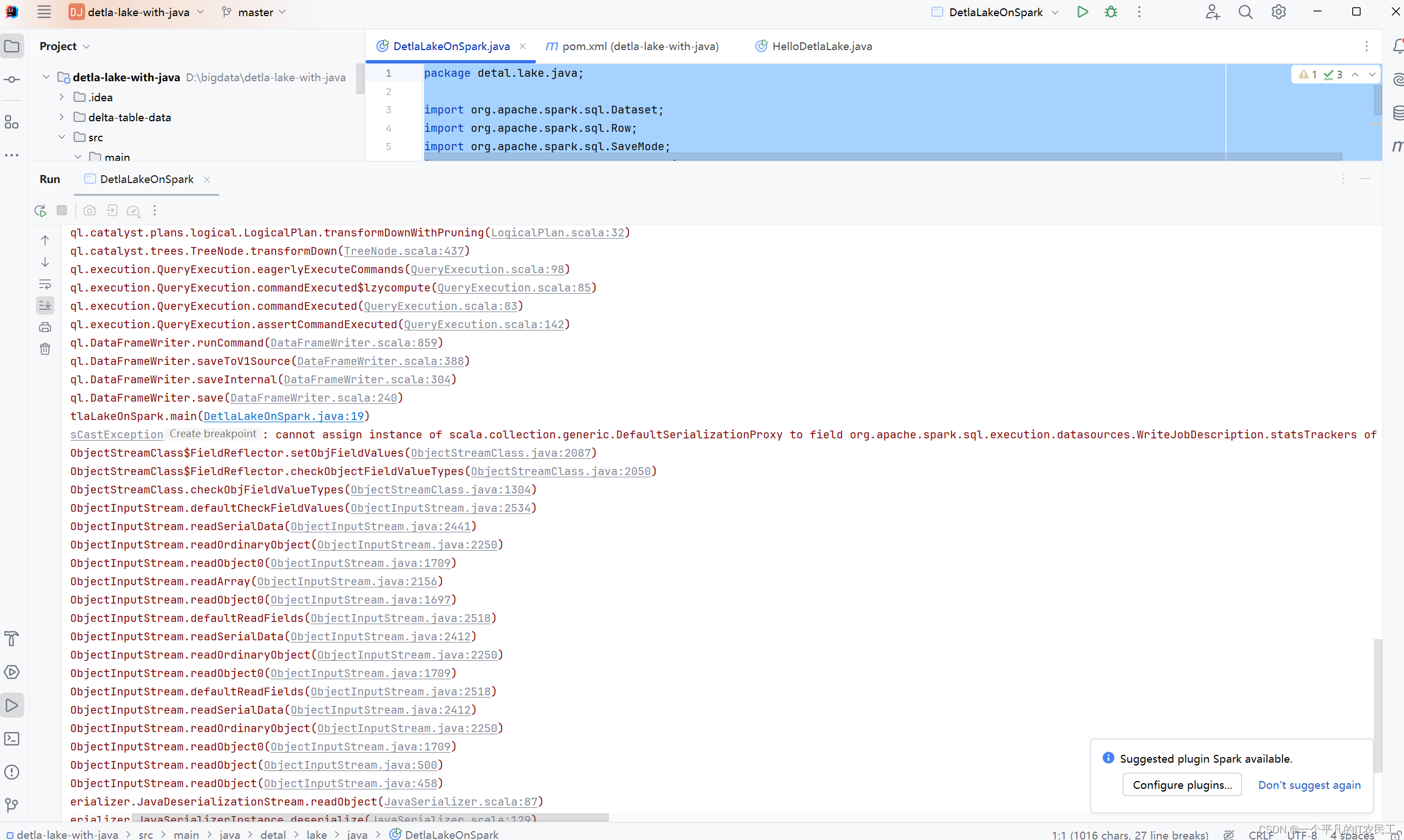
该问题又花了半天的时间到处找,最终找到一个类似的
https://stackoverflow.com/questions/73982281/delta-lake-error-on-deltatable-forname-in-k8s-cluster-mode-cannot-assign-instanc里面的解决方法就是把Delta lake相关的jar包复制到spark安装目录下面的jar目录里面,于是决定尝试一下。
5、通过IDEA定位到Delta lake 相关jar包所在目录,具体如下图:
6、然后将找到的jar复制到spark安装目录下面的jar目录里面,需要复制2个jar包,分别是:delta-spark_2.13-3.1.0.jar和delta-storage-3.1.0.jar,具体如下图:
 复制完后,记得重新运行第2和第3步,重启spark。
复制完后,记得重新运行第2和第3步,重启spark。
7、还是在IDEA运行DetlaLakeOnSpark程序,结果成功运行,具体如下图:
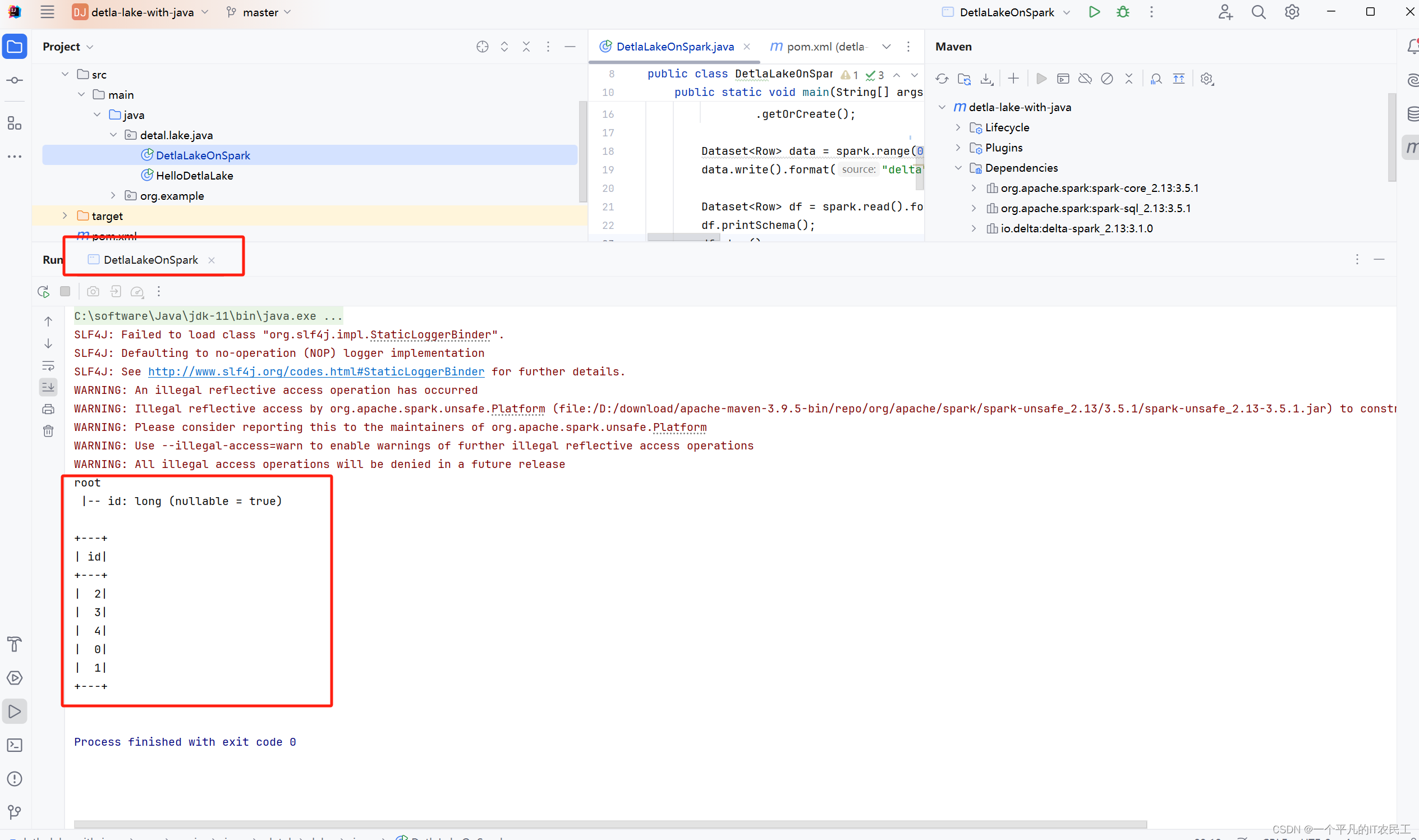
这篇关于Detla lake with Java--在spark集群上运行程序的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







